「HaystackにおけるRAGパイプラインの拡張 DiversityRankerとLostInTheMiddleRankerの紹介」
Introduction to the extension of RAG pipeline in Haystack DiversityRanker and LostInTheMiddleRanker.
最新のランカーが検索補完生成(RAG)パイプラインにおいてLLMコンテキストウィンドウの最適化を行っています
自然言語処理(NLP)と長文質問応答(LFQA)の最近の進歩は、わずか数年前まではまるでSFの世界のようなものでした。膨大な情報源から複雑な質問に専門家のような精度で回答し、それらの回答を即座に合成するシステムが現在では存在するなんて、誰が想像できたでしょうか。LFQAは、最新の研究と私たちの経験に基づく具体的な例を用いて、大規模言語モデル(LLM)の最良の検索と生成能力を活用した検索補完生成(RAG)の一種です。
しかし、この設定をさらに洗練させることはできないでしょうか? RAGがパフォーマンスを向上させるために情報の選択と活用方法を最適化することはできないでしょうか? この記事では、最新の研究と私たちの経験に基づき、LFQAから抽出した具体的な例を用いて、RAGの能力を向上させるための2つの革新的なコンポーネント、「DiversityRanker」と「LostInTheMiddleRanker」を紹介します。
LLMのコンテキストウィンドウを、ユニークで風味豊かな食材が含まれる美食と考えてみましょう。料理の傑作には多様で高品質な食材が必要ですが、LFQAの質問回答には高品質で多様な関連性のある重複しないパラグラフが含まれたコンテキストウィンドウが必要です。
LFQAとRAGの複雑な世界では、LLMのコンテキストウィンドウを最大限に活用することが重要です。無駄なスペースや繰り返しコンテンツは、抽出および生成できる回答の深さと幅を制限します。コンテキストウィンドウの内容を適切に配置するためには繊細なバランスが必要です。この記事では、このバランスを習得するための新しいアプローチを紹介し、正確かつ包括的な回答を提供するRAGの能力を向上させます。
- 「NVIDIA H100 Tensor Core GPUを使用した新しいMicrosoft Azure仮想マシンシリーズが一般利用可能になりました」
- SIGGRAPH特別講演:NVIDIAのCEOがLAショーに生成AIをもたらす
- 「音のシンフォニーを解読する:音楽工学のためのオーディオ信号処理」
このエキサイティングな進歩とそれらがLFQAとRAGをどのように改善するかを探ってみましょう。
背景
Haystackは、実用的なNLPビルダー向けのエンドツーエンドのソリューションを提供するオープンソースのフレームワークです。質問回答や意味論的文書検索からLLMエージェントまで、幅広いユースケースをサポートしています。モジュール設計により、最新のNLPモデル、ドキュメントストア、および現在のNLPツールボックスで必要なさまざまなコンポーネントを統合することができます。
Haystackのキーコンセプトの1つは、パイプラインの考え方です。パイプラインは、特定のコンポーネントが実行する処理ステップのシーケンスを表します。これらのコンポーネントは、さまざまなタイプのテキスト処理を実行できるため、データがパイプラインを通過し、処理ステップを実行するノードの順序を定義することで、簡単に強力でカスタマイズ可能なシステムを作成できます。
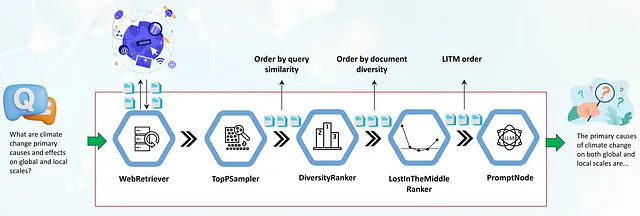
パイプラインは、Webベースの長文質問応答において重要な役割を果たします。WebRetrieverコンポーネントから始まり、クエリに関連するドキュメントを検索して取得し、自動的にHTMLコンテンツを生のテキストに変換します。しかし、クエリに関連するドキュメントを取得した後、それらを最大限に活用するにはどうすればよいでしょうか? 回答の品質を最大化するためにLLMのコンテキストウィンドウをどのように埋めることができるのでしょうか? また、これらのドキュメントは高度に関連しているにもかかわらず、繰り返しの多い場合やLLMのコンテキストウィンドウを溢れさせる場合があります。
ここで、本日紹介するコンポーネント、DiversityRankerとLostInTheMiddleRankerが登場します。これらのコンポーネントは、これらの課題に対処し、LFQA/RAGパイプラインによって生成される回答を改善することを目的としています。
DiversityRankerは、RAGパイプラインのコンテキストウィンドウに選択されたパラグラフの多様性を向上させるために設計された革新的なコンポーネントです。多様なドキュメントのセットは、LLMがより広範で深い回答を生成する能力を高めることができるという原則に基づいています。
DiversityRankerは、文書間の類似性を計算するためにセンテンス変換器を使用します。センテンス変換器ライブラリは、文、段落、さらには全文書の意味のある表現を作成するための強力な埋め込みモデルを提供します。これらの表現、または埋め込みは、テキストの意味的な内容を捉えており、2つのテキストの類似性を測定することができます。
DiversityRankerは、次のアルゴリズムを使用して文書を処理します:
1. センテンス変換器モデルを使用して、各文書とクエリの埋め込みを計算します。
2. 次に、クエリに意味的に最も近い文書を最初に選択します。
3. 残りの各文書について、既に選択された文書との平均類似性を計算します。
4. 次に、既に選択された文書と平均的に最も類似性の低い文書を選択します。
5. この選択プロセスは、すべての文書が選択されるまで続き、最も多様性に寄与する文書から最も少ない寄与をする文書までの順に並んだ文書のリストが得られます。
注意事項: DiversityRankerは、文書の順序について最適な全体的な順序を見つけられない場合がある、貪欲な局所的なアプローチを使用して次の文書を選択します。DiversityRankerは、関連性よりも多様性に重点を置いているため、関連性により焦点を当てたTopPSamplerや他の類似性ランカーなどのコンポーネントの後にパイプラインに配置する必要があります。最も関連性の高い文書を選択するコンポーネントの後に使用することで、既に関連性のある文書のプールから多様な文書を選択することができます。
LostInTheMiddleRanker
LostInTheMiddleRankerは、LLM(Long Language Model)のコンテキストウィンドウ内で選択された文書のレイアウトを最適化します。このコンポーネントは、最近の研究[1]で特定された問題に対処する方法です。この研究では、LLMが長いコンテキストの中間の関連するパッセージに集中するのに苦労していることが示されています。LostInTheMiddleRankerは、最良の文書をコンテキストウィンドウの先頭と末尾に交互に配置することで、LLMの注意メカニズムがこれらの文書にアクセスして使用しやすくします。与えられた文書の順序を理解するための単純な例として、文書が1から10までの数字のみで構成される場合を考えてみましょう。LostInTheMiddleRankerは、これらの10の文書を次の順序で並べます: [1 3 5 7 9 10 8 6 4 2]。
この研究の著者は質問応答のタスクに焦点を当てていますが、私たちは、回答を生成する際にLLMの注意メカニズムがコンテキストウィンドウの先頭と末尾の段落にも簡単に集中できると考えています。
LostInTheMiddleRankerは、与えられた文書が関連性に基づいて選択され、多様性によって順序付けられているため、RAGパイプラインの最後のランカーとして最適です。
パイプラインで新しいランカーを使用する
このセクションでは、LFQA/RAGパイプラインの実際の使用例を見て、DiversityRankerとLostInTheMiddleRankerを統合する方法に焦点を当てます。また、これらのコンポーネントがパイプライン内で他のコンポーネントとどのように相互作用するかについても説明します。
パイプラインの最初のコンポーネントはWebRetrieverであり、プログラムで検索エンジンAPI(SerperDev、Google、Bingなど)を使用してウェブからクエリに関連するドキュメントを取得します。取得した文書はまずHTMLタグが取り除かれ、生のテキストに変換され、必要に応じて短い段落に前処理されます。次に、TopPSamplerコンポーネントに渡され、クエリとの類似性に基づいて最も関連性の高い段落が選択されます。
TopPSamplerが選択した関連性のある段落は、DiversityRankerに渡されます。DiversityRankerは、これらの段落を多様性に基づいて順序付けし、TopPSamplerによって順序付けられた文書の繰り返しを減らします。
選択された文書は、LostInTheMiddleRankerに渡されます。先に述べたように、LostInTheMiddleRankerは、最も関連性の高い段落をコンテキストウィンドウの先頭と末尾に配置し、最も低い順位の文書を中央に配置します。
最後に、マージされた段落はPromptNodeに渡され、これらの選択された段落に基づいて質問に答えるためのLLMが条件付けられます。
新しいランカーはすでにHaystackのメインブランチにマージされ、8月末の2023年のリリースで利用できるようになります。プロジェクトのexamplesフォルダには、新しいLFQA/RAGパイプラインのデモも含まれています。
このデモでは、DiversityRankerとLostInTheMiddleRankerが簡単にRAGパイプラインに統合され、生成された回答の品質を向上させる方法を示しています。
事例研究
新しいランカーを含むLFQA/RAGパイプラインの効果を示すために、詳細な回答を必要とする数問のサンプルを使用します。質問には「ロシアとポーランドの長年の敵意の主な原因は何ですか?」、「地球規模と地域規模の気候変動の主な原因は何ですか?」などが含まれます。これらの質問に適切に答えるためには、LLMは歴史、政治、科学、文化のさまざまな情報源が必要とされます。そのため、LLMは私たちのユースケースに理想的です。
新しいランカーを含むパイプラインと含まないパイプラインの生成された回答を比較するためには、人間の専門家の判断を必要とする複雑な評価が必要です。評価を簡素化し、主にDiversityRankerの効果を評価するために、LLMのコンテキストウィンドウに注入されるコンテキストドキュメントの平均ペアワイズコサイン距離を計算しました。両方のパイプラインでコンテキストウィンドウのサイズを1024単語に制限しました。これらのサンプルPythonスクリプト[2]を実行することで、最適化されたパイプラインでは、LLMのコンテキストに注入されるドキュメントのペアワイズコサイン距離が平均20〜30%増加することがわかりました[3]。このペアワイズコサイン距離の増加は、使用されるドキュメントがより多様で(繰り返しが少ない)、LLMが回答のために利用できる段落の幅広い範囲を提供することを意味します。LostInTheMiddleRankerの評価および生成された回答への影響の評価については、近日中の記事の1つで行います。
結論
Haystackのユーザーは、DiversityRankerとLostInTheMiddleRankerという2つの革新的なランカーを使用することで、RAGパイプラインを強化することができます。
DiversityRankerは、LLMのコンテキストウィンドウに多様で繰り返しのないドキュメントを埋めることで、LLMが回答を合成するためのより広範な段落を提供します。同時に、LostInTheMiddleRankerは、コンテキストウィンドウ内で最も関連性の高い段落の配置を最適化し、モデルが最もサポートされるドキュメントに簡単にアクセスして利用できるようにします。
小規模な事例研究により、DiversityRankerの有効性を確認しました。最適化されたRAGパイプライン(新しいランカーを2つ使用)と非最適化パイプライン(ランカーなし)のLLMのコンテキストウィンドウに注入されるドキュメントの平均ペアワイズコサイン距離を計算しました。その結果、最適化されたRAGパイプラインでは、平均ペアワイズコサイン距離が約20〜30%増加しました。
これらの新しいランカーは、Long-Form Question-Answeringおよび他のRAGパイプラインの機能を向上させる可能性があります。これらや類似のアイデアに投資し、拡大することで、HaystackのRAGパイプラインの能力をさらに向上させ、魔法のような現実を超えたNLPソリューションの構築に近づけることができます。
参考文献:
[1] “Lost in the Middle: How Language Models Use Long Contexts” at https://arxiv.org/abs/2307.03172
[2] スクリプト: https://gist.github.com/vblagoje/430def6cda347c0b65f5f244bc0f2ede
[3] スクリプトの出力(回答): https://gist.github.com/vblagoje/738253f87b7590b1c014e3d598c8300b
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「データリテラシーのあるワークフォースを構築するための4つの重要なポイント」 1. データリテラシーの重要性を理解する:データリテラシーの重要性を従業員に説明し、データの価値とビジネスへの影響を強調します 2. データスキルの獲得を促進する:従業員にデータスキルを獲得するためのトレーニングやリソースを提供し、データの分析や解釈能力を向上させます 3. データ文化を醸成する:データに基づいた意思決定やデータの共有を奨励し、従業員がデータを活用する習慣を養成します 4. データセキュリティに対する意識を高める:データセキュリティの重要性を従業員に啓発し、データの保護とプライバシーの確保についての最善の方法を教育します
- データサイエンスのインタビューのためのA/Bテストのマスタリング:A/Bテストの概要
- データオブザーバビリティの先駆け:データ、コード、インフラストラクチャ、AI
- 「BFS、DFS、ダイクストラ、A*アルゴリズムの普遍的な実装」
- このAI研究は、近くの電話によって記録されたキーストロークを聞くことで、95%の正確さでデータを盗むことができるディープラーニングモデルを紹介しています
- 「フィル・ザ・ギャップス:フィリピンの2022年貿易ネットワークの隠されたつながりを解明する」
- 「生データから洗練されたデータへ:データの前処理を通じた旅 – パート2:欠損値」
