「サポートベクトルマシンの優しい入門」
Introduction to Support Vector Machines

サポートベクターマシン(Support Vector Machines、SVM)は、分類および回帰の両方のタスクで使用される、単純かつ強力な機械学習アルゴリズムのクラスです。この議論では、分類のためのサポートベクターマシンの使用に焦点を当てます。
まず、クラス分類とクラスを分離するハイパープレーンの基礎について見ていきます。次に、最大マージン分類器について説明し、徐々にサポートベクターマシンとアルゴリズムのscikit-learn実装について説明します。
分類問題と分離ハイパープレーン
分類は、ラベル付きデータポイントがあり、機械学習アルゴリズムの目標は新しいデータポイントのラベルを予測することです。
簡単のため、2つのクラス、すなわちクラスAとクラスBを持つ2値分類問題を考えましょう。そして、これら2つのクラスを分離するハイパープレーンを見つける必要があります。
数学的には、ハイパープレーンは、アンビエント空間よりも1次元小さい部分空間です。つまり、アンビエント空間が1次元の場合、ハイパープレーンは点となります。2次元平面の場合、ハイパープレーンは直線となります。このように、N次元の場合、分離ハイパープレーンは(N-1)次元の部分空間になります。
より詳しく見てみると、2次元空間の例では、以下のいずれもクラスAとクラスBを分離する有効なハイパープレーンです:
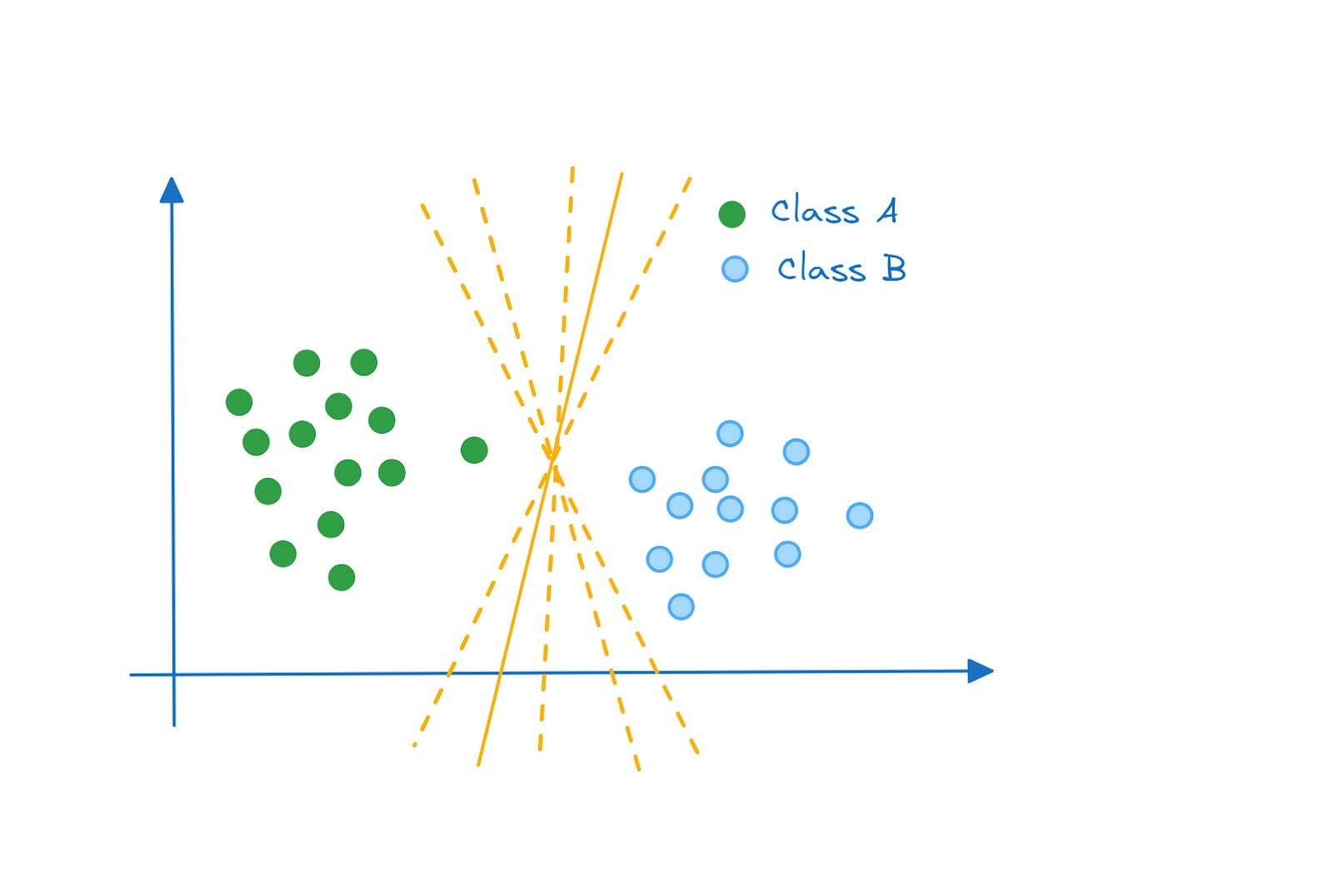
では、最適なハイパープレーンはどのように決定するのでしょうか?最大マージン分類器が登場します。
最大マージン分類器
最適なハイパープレーンは、2つのクラスを分離しながらその間のマージンを最大化するものです。このように機能する分類器は、最大マージン分類器と呼ばれます。
ハードマージンとソフトマージン
完全に分離可能なクラスの例を考慮して、最大マージン分類器は適切な選択肢でした。
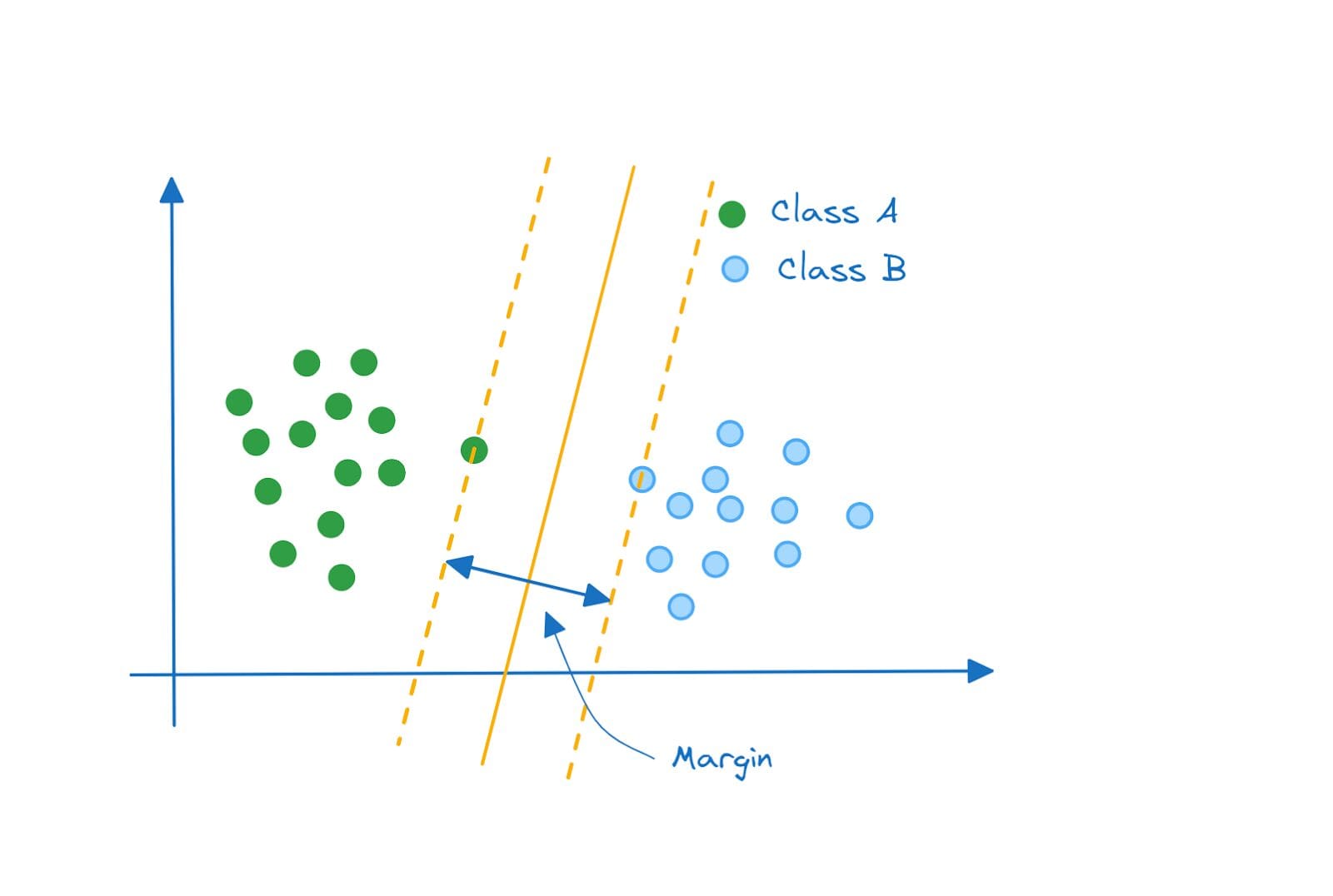
しかし、データポイントが次のように分布している場合はどうでしょう?クラスはまだハイパープレーンで完全に分離されており、マージンを最大化するハイパープレーンは次のようになります:

しかし、このアプローチに問題があることに気づきますか?まだクラスの分離は達成されていますが、これは高分散モデルであり、おそらくクラスAのポイントに適合しすぎている可能性があります。
ただし、マージンには誤分類されたデータポイントは存在しません。このような分類器はハードマージン分類器と呼ばれます。
代わりに、この分類器を見てみてください。このような分類器はより良いパフォーマンスを発揮するでしょう。これは、クラスAとクラスBの両方のポイントを適切に分類する低分散モデルです。
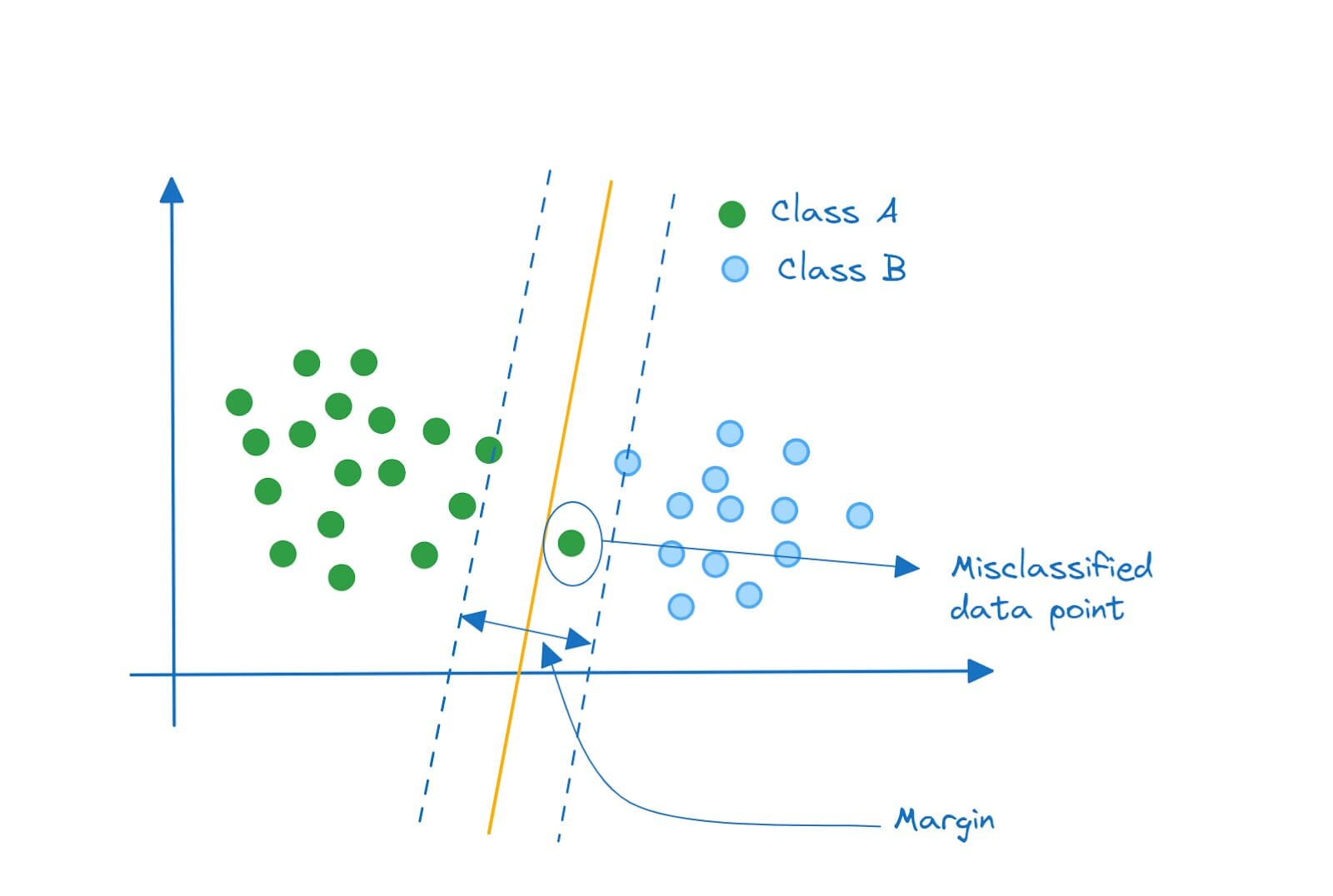 リニアサポートベクター分類器 | 著者による画像
リニアサポートベクター分類器 | 著者による画像
マージン内に誤分類されたデータポイントがあることに注意してください。最小の誤分類を許容する分類器は、ソフトマージン分類器と呼ばれます。
サポートベクター分類器
私たちが持っているソフトマージン分類器は、線形サポートベクター分類器です。データポイントは直線(または線形方程式)で分離できます。これまでに進めてきた方は、サポートベクターが何であり、なぜそう呼ばれるのかが明確になっているはずです。
各データポイントは特徴空間内のベクトルです。分離ハイパープレーンに最も近いデータポイントは、サポートベクターと呼ばれます。なぜなら、彼らは分類をサポートまたは助けるからです。
また、1つのデータポイントまたはサポートベクターではないデータポイントの部分集合を削除しても、分離ハイパープレーンは変わりません。しかし、1つ以上のサポートベクターを削除すると、ハイパープレーンが変わります。
これまでの例では、データポイントは線形に分離可能でした。したがって、最小のエラーでソフトマージン分類器を適合させることができました。しかし、データポイントが次のように分布していた場合はどうでしょうか?
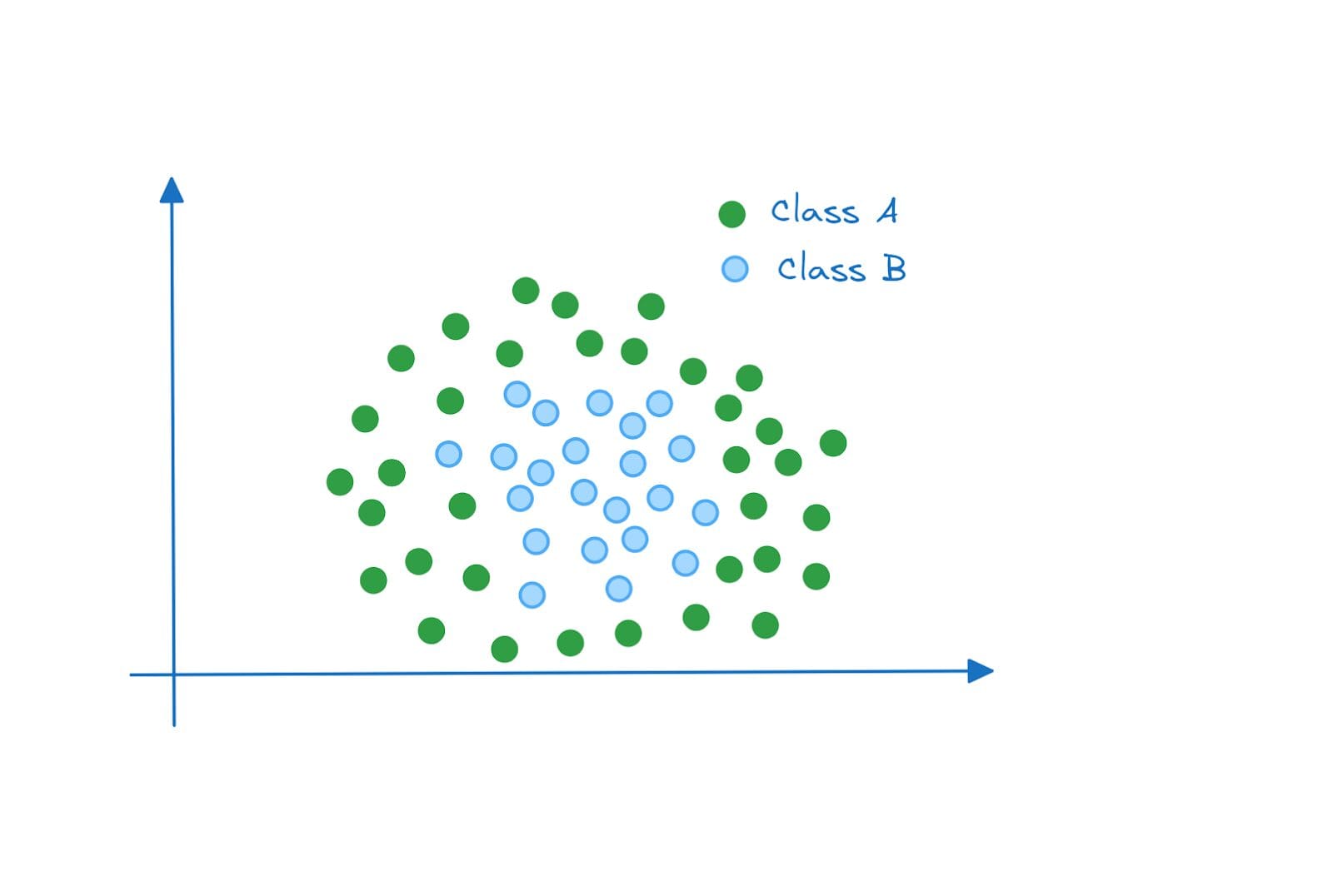 線形分離不可能なデータ | 作者による画像
線形分離不可能なデータ | 作者による画像
この例では、データポイントは線形に分離できません。誤分類を許容するソフトマージン分類器を持っていても、これらの2つのクラスに対して良好なパフォーマンスを達成する直線(分離ハイパープレーン)を見つけることはできません。
では、どうすればいいのでしょうか?
サポートベクターマシンとカーネルトリック
次のようにすることの要約です:
- 問題:データポイントは元の特徴空間で線形に分離できません。
- 解決策:データポイントを線形に分離できるように、より高次元の空間に射影します。
しかし、ポイントをより高次元の特徴空間に射影するには、元の特徴空間からデータポイントをマッピングする必要があります。
この再計算には、特に射影先の空間が元の特徴空間よりもはるかに高次元である場合、無視できないオーバーヘッドが伴います。ここでカーネルトリックが重要な役割を果たします。
数学的には、サポートベクター分類器は次の式で表すことができます[1]:

ここで、は定数であり、
はサポートポイントに対応するインデックスの集合に対して合計を取ることを示します。
は、ポイント
と
の内積です。2つのベクトルaとbの内積は次のように与えられます:

カーネル関数K(.)は線形サポートベクター分類器を非線形のケースに一般化するために使用されます。内積をカーネル関数で置き換えます:

カーネル関数は非線形性を考慮し、また、高次元空間での再計算をせずに元の特徴空間のデータポイント上で計算を行うことを可能にします。
線形サポートベクトル分類器において、カーネル関数は単純に内積を表し、以下の形式を取ります:

Scikit-Learnにおけるサポートベクトルマシン
サポートベクトルマシンの直感が理解できたので、scikit-learnライブラリを使用して簡単な例をコーディングしてみましょう。
scikit-learnライブラリのsvmモジュールには、Linear SVC、SVC、NuSVCなどのクラスの実装が付属しています。これらのクラスは、バイナリおよびマルチクラスの分類に使用することができます。Scikit-learnの拡張ドキュメントには、サポートされているカーネルがリストされています。
組み込みのワインデータセットを使用します。これは、ワインの特徴を使用して、出力ラベル(0、1、または2のいずれか)を予測する分類問題です。約178のレコードと13の特徴を持つ小さなデータセットです。
ここでは、次のことに焦点を当てます:
- データの読み込みと前処理
- データセットに分類器を適合させる
ステップ1 – 必要なライブラリをインポートし、データセットをロードする
まず、scikit-learnのdatasetsモジュールにあるワインデータセットを読み込みましょう:
from sklearn.datasets import load_wine
# ワインデータセットを読み込む
wine = load_wine()
X = wine.data
y = wine.target
ステップ2 – データセットをトレーニングセットとテストセットに分割する
データセットをトレーニングセットとテストセットに分割しましょう。ここでは、データポイントの80%と20%がそれぞれトレーニングセットとテストセットに入ります:
from sklearn.model_selection import train_test_split
# データセットをトレーニングセットとテストセットに分割する
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=10)
ステップ3 – データセットの前処理
次に、データセットを前処理します。データポイントを、平均が0で分散が1の分布に従うように変換するためにStandardScalerを使用します:
# データの前処理
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
テストデータセットにfit_transformを使用しないように注意してください。これは、データ漏洩の微妙な問題を引き起こす可能性があります。
ステップ4 – SVM分類器をインスタンス化し、トレーニングデータに適合させる
この例ではSVCを使用します。SVCオブジェクトであるsvmをインスタンス化し、トレーニングデータに適合させます:
from sklearn.svm import SVC
# SVM分類器を作成する
svm = SVC()
# SVM分類器をトレーニングデータに適合させる
svm.fit(X_train_scaled, y_train)
ステップ5 – テストサンプルのラベルを予測する
テストデータのクラスラベルを予測するには、svmオブジェクトのpredictメソッドを呼び出すことができます:
# テストセットのラベルを予測する
y_pred = svm.predict(X_test_scaled)
ステップ6 – モデルの正確性を評価する
話をまとめるために、正確性スコアのみを計算します。しかし、より詳細な分類レポートや混同行列も取得することができます。
from sklearn.metrics import accuracy_score
# モデルの正確性を計算する
accuracy = accuracy_score(y_test, y_pred)
print(f"{accuracy=:.2f}")
出力 >>> accuracy=0.97
以下に完全なコードを示します:
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# ワインのデータセットをロードする
wine = load_wine()
X = wine.data
y = wine.target
# データセットをトレーニングセットとテストセットに分割する
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=10)
# データの前処理
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# SVM分類器を作成する
svm = SVC()
# SVM分類器をトレーニングデータに適合させる
svm.fit(X_train_scaled, y_train)
# テストセットのラベルを予測する
y_pred = svm.predict(X_test_scaled)
# モデルの正確性を計算する
accuracy = accuracy_score(y_test, y_pred)
print(f"{accuracy=:.2f}")
シンプルなサポートベクター分類器を使用しています。サポートベクター分類器のパフォーマンスを改善するために調整できるハイパーパラメータがあります。一般的に調整されるハイパーパラメータには、正則化定数Cとガンマ値があります。
結論
このサポートベクターマシンの入門ガイドが役立つことを願っています。サポートベクターマシンの動作原理を理解するために、十分な直感と概念をカバーしました。もっと深く掘り下げることに興味がある場合は、以下の参考文献を参照してください。学習を続けてください!
参考文献と学習リソース
[1] サポートベクターマシンの章、統計的学習のためのイントロダクション(ISLR)
[2] カーネルマシンの章、機械学習入門
[3] サポートベクターマシン、scikit-learnドキュメントバラ・プリヤCは、インド出身の開発者兼技術ライターです。彼女は数学、プログラミング、データサイエンス、コンテンツ作成の交差点での仕事が好きです。彼女の関心と専門知識の範囲には、DevOps、データサイエンス、自然言語処理が含まれます。彼女は読書、執筆、コーディング、そしてコーヒーが好きです! 現在、チュートリアル、ハウツーガイド、意見記事などを執筆することで、開発者コミュニティとの知識を共有することに取り組んでいます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





