「分析ストリーム処理への控えめな紹介」
Introduction to Stream Processing for Analysis
信頼性のある分散システムの構築のためのアーキテクチャの基盤。

ストリーム処理の基礎
基礎は構造物が配置される揺るぎない基盤です。成功したデータアーキテクチャを構築する際には、データがシステム全体の中心的な要素であり、その基礎の主要なコンポーネントです。
Apache KafkaやApache Pulsarなどのストリーム処理プラットフォームを介してデータがデータプラットフォームに流れ込む一般的な方法を考えると、データがこれらの高速データネットワークに入った後のデータ品質に関連する問題領域を減らすために、私たち(ソフトウェアエンジニアとして)は衛生的な機能と摩擦のないガードレールを提供することが重要です。これは、データのスキーマ(型や構造)、フィールドの可用性(null可能など)、およびフィールドの型の妥当性(期待される範囲など)に関するAPIレベルの契約を確立することを意味します。特に、現代の分散ストリーミングデータシステムの分散化された性質を考慮すると、これらがデータの基礎の重要な基盤となります。
しかし、盲信または高信頼性のデータネットワークを確立するためには、まずインテリジェントなシステムレベルの設計パターンを確立する必要があります。
信頼性のあるストリーミングデータシステムの構築
ソフトウェアエンジニアやデータエンジニアとして、信頼性のあるデータシステムの構築は私たちの仕事そのものです。これは、データの停止時間がビジネスの他のコンポーネントと同じように測定されるべきことを意味します。おそらく、SLA(サービスレベル契約)、SLO(サービスレベル目標)およびSLI(サービスレベルインジケータ)という用語を聞いたことがあるかもしれません。要するに、これらの頭字語は、私たちのエンドツーエンドシステムを評価するために使用される「契約」、「約束」、「実際の指標」に関連しています。サービスの所有者として、私たちは成功と失敗に対して責任を負いますが、最初の努力が大きな効果をもたらし、運用の観点からのスムーズな動作を保証するためにキャプチャされたメタデータは、データの品質と信頼性に関する貴重な洞察を提供し、データの問題解決のための労力を減らすのに役立ちます。
オーナーのマインドセットを採用する
たとえば、チームや組織とお客様(内部および外部の両方)との間のサービスレベル契約(SLA)は、提供するサービスに関する拘束力のある契約を作成するために使用されます。データチームにとって、これはサービスレベル目標(SLO)に基づいてメトリクス(KPM:キーパフォーマンスメトリクス)を特定し、キャプチャすることを意味します。SLOは、SLAに基づいて守ることを意図している約束であり、これは99.999%のほぼ完璧なサービスの稼働時間(APIまたはJDBC)や、特定のデータセットの90日間のデータ保存など、様々な約束になります。最後に、サービスレベルインジケータ(SLI)は、サービスレベル契約に従って運用されていることの証拠であり、通常は運用分析(ダッシュボード)やレポートの形で提示されます。
目標を設定することで、そこにたどり着くための計画を立てることができます。この旅は、開始点(またはインジェストポイント)とデータで始まります。具体的には、各データポイントの形式と識別子です。 「Apache Kafkaなどのストリーム処理プラットフォームを介してますます多くのデータがデータプラットフォームに流れ込んでいる」という観察を考慮すると、これらのデータストリームに発信されるデータのコンパイル時の保証、後方互換性、および高速バイナリシリアル化は役に立ちます。データの責任はそれ自体が課題となることがあります。なぜならば、次に説明するように、データの問題が発生することがあるからです。
ストリーミングデータの責任の管理
ストリーミングシステムは1日24時間、週7日、年365日稼働します。これは、問題に十分な前向きな努力が適用されていない場合に複雑になる可能性があります。時間が経つにつれて、データの破損、つまり飛行中のデータの問題が時折起こる問題の一つです。
飛行中のデータの問題に対処する
データの問題を解決するために一般的な方法は2つあります。まず、データネットワークのエッジにゲートキーパーを導入し、従来のアプリケーションプログラミングインターフェース(API)を使用してデータを交渉および検証することができます。また、2番目のオプションとして、ヘルパーライブラリまたはソフトウェア開発キット(SDK)を作成およびコンパイルして、データプロトコルを強制し、ストリーミングデータインフラストラクチャに分散ライター(データプロデューサー)を可能にすることもできます。両方の戦略を併用することもできます。
データゲートキーパー
データネットワークのエッジにゲートウェイAPIを追加する利点は、データの生成時に認証(このシステムはこのAPIにアクセスできますか?)、承認(このシステムは特定のデータストリームにデータを公開できますか?)、および検証(このデータは受け入れ可能または有効ですか?)を強制できることです。以下の図1-1は、データゲートウェイのフローを示しています。
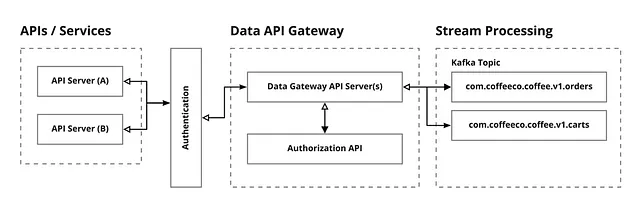
データゲートウェイサービスは、保護された(内部)データネットワークへのデジタルゲートキーパー(バウンサー)として機能します。エッジ(図1-1のAPI / サービスを参照)での非認証アクセスの制御、制限、および制限(上流サービス(またはユーザー)がデータを公開することが許可されているかどうか)を、提供されたアイデンティティ(サービスアイデンティティとアクセスIAM、WebアイデンティティとアクセスJWT、および古い友達OAUTH)と組み合わせて承認することにあります。
ゲートウェイサービスの主な責任は、潜在的に破損したデータまたは一般的に悪いデータを公開する前に入力データを検証することです。ゲートウェイが正しく機能している場合、”良い”データのみがデータネットワークに沿って流れ、ストリーム処理を介して消化されるデータおよび操作データの導管に入ることになります。言い換えれば:
「これは、データを生成する上流システムがデータの生成中にすばやく失敗できることを意味します。これにより、データネットワークのエッジにあるストリーミングまたは静止データパイプラインに破損したデータが入らないようになり、エラーコードと便利なメッセージングを介して、なぜ、どのように問題が発生したのかについての対話を生じさせる自動的な方法です。」
エラーメッセージを使用してセルフサービスソリューションを提供する
良い経験と悪い経験の違いは、悪い経験から良い経験に切り替えるために必要な努力の量によって決まります。おそらく、ランダムな500をスローするヌルポインタ例外が発生するサービスに関与したり、それに取り組んだり、それについて聞いたことがあるかもしれません。
基本的な信頼を確立するためには、少しの努力でも十分です。たとえば、以下のメッセージボディを持つAPIエンドポイントからHTTP 400を取得すると:
{ "error": { "code": 400, "message": "イベントデータにはuserIdが欠落しており、タイムスタンプが無効です(ISO8601形式の文字列が必要です)。ペイロードの調整にはhttp://coffeeco.com/docs/apis/customer/order#required-fieldsでドキュメントを参照してください。" }}400の理由が示され、データを送信しているエンジニア(サービス所有者として)が会議を設定したり、ページャを爆発させたり、すべての人に連絡したりすることなく問題を修正できるようになります。できる限り、誰もが人間であり、クローズドループシステムが好きであることを覚えておいてください!
データ用APIの利点と欠点
このAPIアプローチには利点と欠点があります。
利点は、ほとんどのプログラミング言語がHTTP(またはHTTP / 2)トランスポートプロトコルで動作すること – または小さなライブラリの追加で動作すること – およびJSONデータが現在ほぼユニバーサルなデータ交換形式であることです。
一方で(欠点)、新しいデータドメインごとに別のサービスを作成および管理する必要があると主張できますし、API自動化の形式またはOpenAPIのようなオープン仕様への遵守がない場合、各新しいAPIルート(エンドポイント)は必要以上の時間を要することになります。
多くの場合、データ取り込みAPIへの更新の提供が「適時」に行われない、スケーリングやAPIのダウンタイム、ランダムな障害、またはコミュニケーションの不足などが重なることで、「ばかげた」APIを回避し、代わりに直接Kafkaにイベントデータを公開しようとする人々にとって、必要な理由となります。APIは邪魔に感じられるかもしれませんが、データ品質の問題(破損したイベントや誤って混在したイベントなど)がストリーミングの夢を不安定にするようになると、共通のゲートキーパーを保つことには強力な理由があります。
この問題を逆手に取り(そしてほぼ完全に解決するために)、良いドキュメンテーション、変更管理(CI/CD)および一般的なソフトウェア開発のハイジニー(実際の単体および統合テストを含む)は、信頼を低下させることなく迅速な機能とイテレーションのサイクルを実現します。
理想的には、データ自体(スキーマ/形式)がフィールドレベルのバリデーション(述語)を可能にし、役に立つエラーメッセージを生成し、自己利益を追求することにより、データレベルの契約のルールを自ら定義できるでしょう。ちょっとしたルートやデータレベルのメタデータと創造的な考え方によって、APIは自己定義のルートと動作を自動的に生成することもできます。
最後に、ゲートウェイAPIは集中的なトラブルメーカーと見なされることがあります。上流のシステムが有効なデータを送信しない(ゲートキーパーによってブロックされる)たびに、貴重な情報(イベントデータ、メトリクス)が失われます。ここでの問題は、ゲートキーパーの不良デプロイがゲートウェイのダウンタイムの場合に再試行を処理するように設定されていない上流のシステムを盲目化することもしばしばあります(たとえわずか数秒であっても)。
利点と欠点を置いておくと、データプラットフォームに入る前に壊れたデータの伝播を止めるためにゲートウェイAPIを使用すると、問題が発生した場合(いつもそうです)、問題の範囲が特定のサービスにまで縮小されます。これは、企業内の「誰か」が直接データを公開していることを解明するために、データパイプライン、サービス、および多数の最終データ送信先と上流システムの分散ネットワークのデバッグを行うよりも確かに優れています。
もし中間者(ゲートウェイサービス)を省くと、「予想される」データの伝送を管理する機能は、「ライブラリ」の形で特化したSDKに委ねられることになります。
ソフトウェア開発キット(SDK)
SDKは、アクション、アクティビティ、またはその他の複雑な操作を効率化するためにコードベースにインポートされるライブラリ(またはマイクロフレームワーク)です。別名でクライアントとも呼ばれます。先ほどの例で述べたように、良いエラーメッセージとエラーコードを使用することが必要ですが、適切なガードレールをSDKに直接組み込むことで、潜在的な問題の範囲を減らすことができます。例えば、お客様のコーヒーに関連する行動をイベントトラッキングで追跡するAPIを設定しているとしましょう。
SDKガードレールによるユーザーエラーの削減
クライアントSDKには、APIサーバーとのやり取りを管理するために必要なすべてのツールが理論的に含まれます。これには、認証、承認、およびバリデーションも含まれます。SDKがその役割を果たせば、バリデーションの問題は解決されます。以下のコードスニペットは、信頼性のある顧客イベントの追跡に使用できる例のSDKを示しています。
import com.coffeeco.data.sdks.client._import com.coffeeco.data.sdks.client.protocol._Customer.fromToken(token) .track( eventType=Events.Customer.Order, status=Status.Order.Initalized, data=Order.toByteArray )さらなる作業(つまり、クライアントSDK)により、データのバリデーションやイベントの破損の問題はほぼ完全に解消されます。サーバーがオフラインの場合にリクエストの再送信をどのように行うかなど、追加の問題はSDK自体で管理できます。すべてのリクエストをすぐに再試行するか、ゲートウェイの負荷分散器を無期限に氾濫させるループで再試行するかという問題ではなく、SDKは指数関数的なバックオフなどのよりスマートなアクションを取ることができます。何かがうまくいかないときに何がうまくいかなくなるかについては、「サンダリングハード問題」をご覧ください!
サンダリングハード問題 たとえば、単一のゲートウェイAPIサーバーがあるとしましょう。素晴らしいAPIが作成され、会社全体の多くのチームがこのAPIにイベントデータを送信しています。すべて順調に進んでいましたが、ある日、新しい内部チームがサーバーに無効なデータを送信し始めました(そして、彼らはHTTPステータスコードを尊重せず、非200のHTTPコードを再試行の理由として扱います)。しかし、これらのチームは指数関数的なバックオフなどの再試行ヒューリスティックスを追加するのを忘れてしまいましたので、すべてのリクエストは無期限に再試行されることになります。前にこの新しいチームが参加する前には、APIサーバーの複数インスタンスを実行する理由もなく、サービスレベルのレートリミッターを使用する必要もありませんでした。すべてが合意されたSLA内でスムーズに実行されていました。

それは今日の前のことでした。今、サービスはオフラインです。データがバックアップされ、上流サービスはキューを埋め、人々はシングルポイントの障害のために問題に直面し始めているため、不満です…これらの問題はすべて、「サンダリング・ハード問題」と呼ばれるリソースの飢餓の形態から派生しています。この問題は、多くのプロセスがイベント(たとえば、システムリソースの利用可能性またはこの例ではAPIサーバーの再起動)を待っているときに発生します。今、すべてのプロセスがリソースを獲得しようと競い合っているため、スクランブルが発生し、多くの場合、単一のプロセス(APIサーバー)への負荷が十分に高くなり、サービスを再びオフラインにします。残念ながら、リソースの飢餓サイクルを再び開始します。もちろん、牛群を落ち着かせるか、作業中のプロセスの数を増やして負荷を分散することにより、ネットワーク全体の負荷を減らすことで、リソースに再び余裕が生まれるまでです。最初の例は、意図しない分散型サービス拒否(DDoS)攻撃のようなものですが、この種の問題はクライアント(指数関数的なバックオフや自己制御)とAPIエッジ(負荷分散とレート制限)で解決することができます。
結局のところ、正しい目と耳が、運用メトリクス、モニター、システムレベル(SLA / SLI / SLO)のアラート、データが消えることができるという挑戦を解決するために可能にする場合、データをデータネットワークのエッジに追加すること、上流の整合性と説明責任のためにカスタムSDKを使用すること、またはデータプラットフォームにデータを取り込むための代替手法を選択することはそれでも良いことです。データがデータストリームに排出される経路に関係なく、ストリーミングデータについてのこの紹介は、データフォーマット、プロトコル、およびバイナリシリアライズデータのトピックを適切に議論しない限り、完全ではありません。誰もが私たちのデータの説明責任の問題を扱うためのより良いアプローチを見つけるかもしれません!
ジョブに適したデータプロトコルの選択
構造化データを考えると、最初に思い浮かぶのはJSONデータです。 JSONデータには構造があり、標準のウェブベースのデータプロトコルであり、それ以外の何よりも取り組みやすいです。これらはすべて、すばやく始めるための利点ですが、適切な保護策がないと、ストリーミングシステムにJSONを標準化する際に問題が発生する可能性があります。
JSONとの愛憎関係
最初の問題は、JSONデータが変更可能であるということです。これはデータ構造としては柔軟であり、したがって壊れやすいということを意味します。データは責任を持つために一貫している必要があり、ネットワーク上(ワイヤ上)でデータを転送する場合、シリアライズされた形式(バイナリ表現)は非常に圧縮可能である必要があります。 JSONデータでは、各オブジェクトのすべてのフィールドのキーをペイロード全体で送信する必要があります。必然的に、オブジェクトのシリーズの追加レコード(最初のレコード以降)ごとに大量の追加の重みを送信することになります。
幸いなことに、これは新しい問題ではなく、このようなことについてのベストプラクティスがあり、最適なデータシリアル化戦略についての複数の考え方があります。これはJSONに利点がないと言っているわけではありません。ただし、堅牢なデータ基盤を構築する際には、構造が多いほど良く、CPUサイクルを多く消費しない限り、より高い圧縮レベルが望ましいです。
シリアライズ可能な構造化データ
バイナリデータを効率的にエンコードおよび転送する場合、2つのシリアライゼーションフレームワークが常に話題に上がります:Apache AvroとGoogle Protocol Buffers(protobuf)。両方のライブラリは、行ベースのデータ構造をシリアライズするためのCPU効率の高い技術を提供し、両技術には独自のリモートプロシージャコール(RPC)フレームワークと機能も提供されています。avro、次にprotobuf、最後にリモートプロシージャコールについて見ていきましょう。
Avroメッセージフォーマット
Avroでは、レコードの概念を使用して、構造化データのための宣言的なスキーマを定義します。これらのレコードは、単にJSON形式のデータ定義ファイル(スキーマ)である.avscファイルの形式で保存されます。次の例は、Avroディスクリプタ形式でのCoffeeスキーマを示しています。
{ "namespace": "com.coffeeco.data", "type": "record", "name": "Coffee", "fields": [ {"name": "id", "type": "string"}, {"name": "name", "type": "string"}, {"name": "boldness", "type": "int", "doc": "軽から大胆まで。1〜10"}, {"name": "available", "type": "boolean"} ]}Avroデータを扱う際には、ランタイムでの作業方法に関連して分かれる2つのパスを取ることができます。コンパイル時のアプローチを取るか、ランタイムでのオンデマンドでの解決を選ぶことができます。これにより、インタラクティブなデータ探索セッションを強化する柔軟性が得られます。たとえば、Avroはもともと、Hadoopファイルシステム内で長期的にパーティション化されたファイルとして大規模なデータコレクションを格納するための効率的なデータシリアライゼーションプロトコルとして作成されました。データは通常、HDFS内の1か所から読み取り、別の場所に書き込まれたため、Avroは1つのファイルごとにスキーマ(書き込み時に使用される)を格納することができました。
Avroバイナリフォーマット
Avroレコードのコレクションをディスクに書き込むと、プロセスはAvroデータのスキーマを直接ファイル自体にエンコードします(1回)。Parquetファイルエンコーディングの場合も、スキーマは圧縮されバイナリファイルフッタとして書き込まれます。私たちは、第4章の最後で、StructTypeにStructFieldレベルのドキュメントを追加するプロセスを通じて、このプロセスを直接目にしました。このスキーマは私たちのDataFrameをエンコードするために使用され、ディスクに書き込むと、次の読み取り時にインラインのドキュメントが保持されます。
後方互換性の有効化とデータの破損防止
複数のファイルを単一のコレクションとして読み取る場合、レコード間のスキーマの変更によって問題が発生する場合があります。Avroはバイナリレコードをバイト配列としてエンコードし、デシリアライズ時(バイト配列からオブジェクトへの変換時)にデータにスキーマを適用します。
これは、後方互換性を保持するために追加の注意が必要であり、そうでない場合はArrayIndexOutOfBounds例外の問題に直面する可能性があります。
これは、スキーマの微妙な変更によって起こる可能性があります。たとえば、特定のフィールドの整数値を長整数値に変更する必要がある場合、それを行わないでください。これは、intからlongへのバイトサイズの増加により、後方互換性が破壊されるからです。これは、レコードの各フィールドのバイト配列内の開始位置と終了位置を定義するためにスキーマ定義の使用によるものです。後方互換性を維持するためには、整数フィールドの使用を廃止し(avro定義で保持する)、前方に向けて新しいフィールドをスキーマに追加(追記)する必要があります。
ストリーミングAvroデータのベストプラクティス
静的なAvroファイルから、埋め込まれた有用なスキーマを持つデータの無限ストリームに移行する際の主な違いは、自分自身のスキーマを持参する必要があることです。これは、スキーマの変更前および変更後のデータを巻き戻して再処理する必要がある場合に後方互換性をサポートする必要があると同時に、既存のリーダーがすでにストリームから読み取りを行っている場合に前方互換性をサポートする必要があるということを意味します。
ここでの課題は、Avroが未知のフィールドを無視する能力を持っていないことで、これは前方互換性をサポートするための要件です。Avroをサポートするためには、ConfluenceのチームがKafkaで使用するためにスキーマレジストリをオープンソース化しました。これにより、Kafkaトピック(データストリーム)レベルでスキーマのバージョニングを可能にします。
スキーマレジストリなしでAvroをサポートする場合、スキーマライブラリのバージョンを更新する前に、アクティブなリーダー(Sparkアプリケーションなど)を新しいバージョンのスキーマを使用するように更新する必要があります。それ以外の場合、スイッチを切り替える瞬間にインシデントの始まりに直面する可能性があります。
Protobufメッセージフォーマット
Protobufでは、メッセージの概念を使用して構造化データの定義を行います。メッセージは、Cのstructを定義するような形式で記述されます。これらのメッセージファイルは、proto拡張子のファイルに書き込まれます。プロトコルバッファはimportの使用を可能にする利点があります。これにより、大規模なプロジェクト内で使用される共通のメッセージタイプや列挙型を定義し、さらには外部プロジェクトにインポートすることで広範な再利用が可能になります。Protobufを使用してCoffeeレコード(メッセージタイプ)を作成する単純な例です。
syntax = "proto3";
option java_package="com.coffeeco.protocol";
option java_outer_classname="Common";
message Coffee {
string id = 1;
string name = 2;
uint32 boldness = 3;
bool available = 4;
}プロトバフでは、メッセージを一度定義し、その後選択したプログラミング言語にコンパイルダウンすることができます。たとえば、ScalaPBプロジェクト(Nadav Sametが作成およびメンテナンスしている)のスタンドアロンコンパイラを使用して、coffee.protoファイルからScala用のコードを生成することができます。または、protobufとgrpcの周りに貴重なツールとユーティリティを作成したBufの素晴らしさを利用することもできます。
コード生成
プロトバフのコンパイルにより、簡単なコード生成が可能になります。以下の例は、/ch-09/data/protobufディレクトリから取得されています。チャプターのREADMEには、ScalaPBのインストール方法と、コマンドを実行するための正しい環境変数の設定手順が記載されています。
$SCALAPBC/bin/scalapbc -v3.11.1 \ --scala_out=/Users/`whoami`/Desktop/coffee_protos \ --proto_path=$SPARK_MDE_HOME/ch-09/data/protobuf/ \ coffee.protoこのプロセスにより、データオブジェクトのシリアライズとデシリアライズのための追加のコードを書く手間を省くことができます(言語間や異なるコードベース間でのシリアライズとデシリアライズ)。
Protobufバイナリフォーマット
シリアライズされた(バイナリワイヤーフォーマット)は、バイナリフィールドレベルセパレータの概念を使用してエンコードされます。これらのセパレータは、シリアライズされたプロトバフメッセージ内にカプセル化されたデータ型を識別するためのマーカーとして使用されます。例えば、coffee.protoでは、各フィールドタイプの横にインデックスマーカーがあることに気付いたかもしれません(string id = 1;)。これは、ワイヤー上のメッセージのエンコード/デコードを補助するために使用されます。これは、avroバイナリと比較してわずかな追加オーバーヘッドがあることを意味しますが、エンコーディング仕様を読むと、ビットパッキング、数値データ型の効率的な処理、および各メッセージの最初の15インデックスの特殊エンコーディングなど、他の効率性がより多くあることがわかります。ストリーミングデータのバイナリプロトコルとしてprotobufを使用する場合、プロとコンのバランスを考えると、プロトバフの利点は大きいです。その中でも、バックワード互換性と前方互換性の両方をサポートする点が特に優れています。
バックワード互換性の有効化とデータの破損防止
avroと同様に、protobufスキーマを変更する際には同様のルールを心に留めておく必要があります。一般的な原則として、フィールドの名前を変更することはできますが、型や位置(インデックス)を変更することはできません。これにより、バックワード互換性が破壊されることがあります。これらのルールは、長期的に任意のデータをサポートする場合に見逃すことができ、protobufの使用に慣れたチームほど特に困難になることがあります。注意が必要な再配置や最適化が必要になる場合があります(詳細については、後述の「時間の経過によるデータ品質の維持」のヒントを参照してください)。
ストリーミングプロトバフデータのベストプラクティス
protobufは、バックワードおよび前方互換性の両方をサポートしているため、新しいライターをデプロイする際に最初にリーダーを更新する必要がないことを意味します。同様に、リーダーを更新する際にも、新しいバージョンのprotobuf定義を使用して更新することができ、すべてのライターを複雑にデプロイする必要はありません。protobufは、未知のフィールドの概念を使用して前方互換性をサポートしています。これは、avro仕様には存在しない追加の概念であり、ローカルバージョンのprotobufと現在読み取っているバージョンとの間の差異によって解析できなかったインデックスと関連するバイトを追跡するために使用されます。ここでの利点は、いつでも新しい変更にprotobuf定義をオプトインできることです。
例えば、ストリーミングアプリケーション(a)と(b)があるとします。アプリケーション(a)は、上流のKafkaトピック(x)からのストリーミングデータを処理し、各レコードに追加情報を付加して新しいKafkaトピック(y)に書き込みます。次に、アプリケーション(b)が(y)から読み取り、処理を行います。protobuf定義の新しいバージョンがあり、アプリケーション(a)がまだ最新バージョンに更新されていない場合でも、上流のKafkaトピック(x)とアプリケーション(b)はすでに更新されており、アップグレードで利用可能な新しいフィールドを使用することを期待しています。素晴らしいことは、存在することさえ知らなくても、未知のフィールドをアプリケーション(a)からアプリケーション(b)に渡すことができるということです。
「データ品質を維持するためのヒント」を参照して、追加の詳細を確認してください。
ヒント:時間をかけたデータ品質の維持
AvroまたはProtocol Buffersを使用する場合、スキーマを本番環境にプッシュしたいコードと同じように扱う必要があります。つまり、企業のGitHub(または使用しているバージョン管理システム)にコミットできるプロジェクトを作成すること、またスキーマに対してユニットテストを書くことです。これは、各メッセージタイプの使用方法の具体的な例を提供するだけでなく、データ形式の変更が後方互換性を壊さないことを確認するためのものです。さらに、スキーマのユニットテストを実行するためには、(.avscまたは.proto)ファイルをコンパイルし、対応するライブラリのコード生成を使用する必要があります。これにより、リリース可能なライブラリコードを作成しやすくなり、スキーマの各変更をカタログ化するためにリリースバージョニング(バージョン1.0.0)を使用できます。
このプロセスを有効にするための1つのシンプルな方法は、プロジェクトライフサイクルの一部として、スキーマの変更を含むすべてのメッセージのバイナリコピーをシリアライズして保存することです。私は、テストスイートを使用して、これらのレコードをプロジェクトのテストリソースディレクトリに直接作成、読み取り、書き込むというステップを直接ユニットテストに追加することで成功を収めました。この方法で、すべてのスキーマの変更を含む各バイナリバージョンがコードベース自体で利用できるようになります。
少しの前向きな取り組みで、大局的な観点で多くの苦痛を回避し、データが安全であることを確認できます(少なくともテーブルの生成および消費の側面では)。
Buf ToolingとSparkでのProtobufの使用
2021年にこの章を執筆して以来、Buf Build(https://buf.build/)は、Protocol Buffersに関する全てを担当する企業になりました。彼らのツールは使いやすく、無料でオープンソースであり、Sparkコミュニティのいくつかのイニシアチブをパワー提供するための正しいタイミングで登場しました。Apache Sparkプロジェクトは、spark-connectをサポートするためにSpark 3.4でProtocol Buffersのネイティブサポートを導入し、GRPCサービスとメッセージのコンパイルにBufを使用しています。Spark Connectは、JVM以外の場所にSparkアプリケーションを埋め込むためのGRPCネイティブコネクタです。
従来のApache Sparkアプリケーションは、ドライバーアプリケーションとして実行する必要がありましたが、これまではpysparkまたはネイティブSparkを使用する必要がありました。どちらの場合も、依然としてJVMプロセスの上で実行されます。
結局のところ、Buf Buildはビルドプロセスでの安心感を提供します。コードを生成するためには、単純なコマンドbuf generateを実行する必要があります。シンプルなリンティングと一貫したフォーマットのためには、buf lint && buf format -wを使用します。しかし、最も重要なのは、破壊的な変更の検出です。新しいメッセージ定義の変更が現在本番環境で実行中のものに負の影響を与えないことを確認するには、buf breaking --against .git#branch=origin/mainを実行するだけです。*将来的には、企業の分析にbufを使用する方法について詳しく説明しますが、今はこの章を終了する時です。
では、どこまで進んだのでしょうか。AvroまたはProtobufを使用することで、長期的なデータの説明責任戦略にメリットがあることを知っています。これらの言語に依存しない、行ベースの構造化データ形式を使用することで、将来のプログラミング言語に対するロックインの問題を軽減し、古いライブラリやコードベースのサポート作業が厳しいタスクになることを避けることができます。さらに、シリアライズされた形式は、大量のデータの送受信に関連するネットワーク帯域幅のコストと混雑を削減するのに役立ちます。これにより、データの長期的な保持にかかるストレージオーバーヘッドコストも削減されます。
最後に、リモートプロシージャコールを使用したネットワークを介したデータの送受信において、これらの構造化データプロトコルがどのように追加の効率性をもたらすかを見てみましょう。
リモートプロシージャコール
RPCフレームワークは、要するに、クライアントアプリケーションがシリアル化されたメッセージをやり取りしながら、ローカルの関数呼び出しを介してリモート(サーバーサイド)メソッド(手続き)を透過的に呼び出すことを可能にします。クライアントとサーバーサイドの実装は、利用可能な機能的なRPCメソッドとサービスを定義するために同じ公開インターフェース定義を使用します。インターフェース定義言語(IDL)は、プロトコルとメッセージの定義を定義し、クライアントとサーバーサイドの間の契約として機能します。人気のオープンソースRPCフレームワークであるgRPCを見てみましょう。
gRPC
Googleで最初に概念化され、作成されたgRPCは、「一般的な」リモート手続き呼び出しを意味し、CockroachDBのような分散データベース調整からMicrosoftのAzureビデオアナリティクスのようなリアルタイムアナリティクスまで、高性能サービスに使用される堅牢なオープンソースフレームワークです。
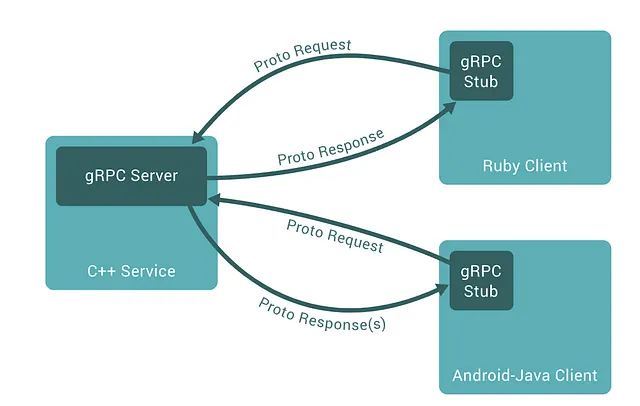
図9–3に示されているダイアグラムは、gRPCの動作例を示しています。サーバーサイドのコードは速度のためにC++で書かれており、rubyとjavaのクライアントはprotobufメッセージを使用してサービスとやり取りすることができます。
メッセージ定義、シリアル化、およびサービスの宣言と定義にプロトコルバッファを使用することで、gRPCはデータのキャプチャとサービスの構築を簡素化することができます。例えば、顧客のコーヒーオーダーの追跡APIを作成する演習を続けたいとします。API契約は単純なサービスファイルで定義され、そこからサーバーサイドの実装と任意の数のクライアントサイドの実装が、同じサービス定義とメッセージタイプを使用して構築されることができます。
gRPCサービスの定義
サービスインターフェース、リクエストおよびレスポンスオブジェクト、およびクライアントとサーバー間で渡す必要があるメッセージタイプを、1–2–3のように簡単に定義できます。
syntax = "proto3";service CustomerService { rpc TrackOrder (Order) returns (Response) {} rpc TrackOrderStatus (OrderStatusTracker) returns (Response) {}}message Order { uint64 timestamp = 1; string orderId = 2; string userId = 3; Status status = 4;}enum Status { unknown_status = 0; initalized = 1; started = 2; progress = 3; completed = 4; failed = 5; canceled = 6;}message OrderStatusTracker { uint64 timestamp = 1; Status status = 2; string orderId = 3;}message Response { uint32 statusCode = 1; string message = 2;}gRPCの追加により、データインフラストラクチャ内で使用されるサーバーサイドおよびクライアントサイドのコードの実装とメンテナンスがはるかに簡単になります。protobufが逆方向および順方向の互換性をサポートしていることから、これは古いgRPCクライアントでも新しいgRPCサービスに有効なメッセージを送信でき、一般的な問題や痛み点(前述の「データの問題」)に直面することなく処理できることを意味します。
gRPCはHTTP/2を使用します
モダンなサービススタックに関連して、gRPCはトランスポート層としてHTTP/2を使用することができます。これは、Envoyのようなモダンなデータメッシュを利用してプロキシサポート、ルーティング、およびサービスレベルの認証を利用できることを意味します。また、標準のHTTP over TCPで見られるTCPパケットの混雑問題も解決することができます。
データの問題を軽減し、データの説明責任を達成するためには、データから中心点に広がるプロセスを実施することが重要です。データがデータネットワークに入る方法に関してプロセスを確立することは、ストリーミングデータの洪水に飛び込む前にチェックすべき前提条件と考えるべきです。
概要
この記事の目的は、従来の(静的な)バッチベースの考え方から、リアルタイムのストリーミングデータとの作業のリスクと報酬を理解するために必要な移動部品、コンセプト、および背景情報を提示することです。
リアルタイムでデータを活用することは、迅速な実用的な洞察をもたらし、最先端の機械学習や人工知能の扉を開くことができます。
ただし、分散データ管理は、適切な手順が事前に考慮されない場合にデータ危機にもなり得ます。強力で信頼できるデータ上に構築された堅固なデータ基盤がなければ、リアルタイムへの道は単純な試みではなく、途中でいくつかの問題や迂回路が存在することを忘れないでください。
第9章の後半をお楽しみいただけたら幸いです。このシリーズの第1部を読むには、「解析ストリーム処理への優しい入門」にアクセスしてください。
解析ストリーム処理への優しい入門
エンジニアとその間の人々のためのメンタルモデルの構築
towardsdatascience.com
さらに詳しく知りたい場合は、私の本をチェックするか、高い評価をしてサポートしてください。
Apache Sparkを使用したモダンデータエンジニアリング:ミッションクリティカルなストリーミングを構築するための実践的なガイド
Amazon.com:Apache Sparkを使用したモダンデータエンジニアリング:ミッションクリティカルなストリーミングを構築するための実践的なガイド
www.amazon.com
O’Reilly Mediaへのアクセス権がある場合は、本を完全に無料で読むこともできます(あなたにとっては良いことですが、私にとってはあまり良くありません)。ただし、機会があればどこかで無料で本を入手するか、電子書籍を購入して送料を節約するか(または600ページ以上の本の場所を見つける必要がないようにするか)してください。
Apache Sparkを使用したモダンデータエンジニアリング:ミッションクリティカルなストリーミングを構築するための実践的なガイド
モダンなデータエンジニアリングエコシステム内でApache Sparkを活用します。この実践的なガイドは、完全な形で書き方を教えます…
learning.oreilly.com
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
