「統計学習入門、Pythonエディション:無料の書籍」
Introduction to Statistical Learning, Python Edition Free Book

長年にわたり、統計学習入門(Rを使った応用)として知られるISLRは、機械学習初心者や実践者の間で最高の機械学習の教科書の一つとして愛されてきました。
そして、そのPython版である「Pythonを使った統計学習入門」、またはISL with Pythonが登場し、コミュニティはますます興奮しています。
- 「LangChainを使用したLLMアプリケーションのためのプロンプトエンジニアリングのマスタリング」
- メディアでのアルコール摂取の検出:CLIPのゼロショット学習とABIDLA2ディープラーニングの画像解析のパワーを評価する
- このAI論文では、「ステーブルシグネチャ:画像透かしと潜在的な拡散モデルを組み合わせたアクティブ戦略」が紹介されています
ISL with Pythonが登場しました。素晴らしい!でも、なぜ?
お答えしてうれしいです。😀
機械学習の分野に長くいた方なら、おそらく以前にISLRのR版を聞いたり読んだり、使ったりしたことがあるかもしれません。そして、お気に入りの部分もわかっているでしょう。しかし、私の話を聞いてください。
大学院に進学する前の夏、自分自身で機械学習を学ぶことにしました。私は幸運にも、機械学習の旅の初期にISLRに出会いました。ISLRの著者は、複雑な機械学習アルゴリズムを理解しやすい方法で分かりやすく解説してくれます。そして、必要な数学的な基礎も教えてくれますが、学習者を圧倒することはありません。これは、私がこの本の一つの側面を楽しんだ理由です。
しかしながら、ISLRのコード例やラボはRで書かれています。残念ながら、当時私はRを知りませんでしたが、Pythonでのプログラミングは得意でした。したがって、私には2つの選択肢がありました。 
Rを自習するか、Pythonでモデルを構築するための他のリソース(チュートリアルやドキュメントなど)を使用するかです。ほとんどのPythonistaと同じように、私は2番目の選択肢を選びました(はい、より馴染みのあるルートです、わかります)。
Rは統計分析には素晴らしいですが、データの旅の初めにいるのであれば、Pythonは最初の言語として適しています。
しかしこれはもう問題ではありません!なぜなら、この新しいPython版ではPythonで機械学習モデルをコーディングできるからです。新しいプログラミング言語を学ぶ必要がなくなったので、心配する必要はありません。
話はここまでにしましょう!本の内容をもう少し詳しく見てみましょう。
Python版ISLの内容
コンテンツの面では、Python版はR版と非常に似ています。ただし、Pythonに適した適切な適応をしています。この本には、基本を学ぶためのPythonプログラミングのクラッシュコースセクションも含まれています。
この本は広範な領域をカバーしています。統計学習の基礎、教師ありおよび教師なし学習アルゴリズム、ディープラーニングなど、以下の章にまとめられています。
- 統計学習
- 線形回帰
- 分類
- リサンプリング手法
- 線形モデルの選択と正則化
- 非線形なモデル
- 木ベースの手法
- サポートベクターマシン
- ディープラーニング(バニラニューラルネットワークからConvNets、再帰型ニューラルネットワークまで)
- サバイバル分析と検閲データ
- 教師なし学習
- 多重検定(仮説検定についての詳細な説明)
ISLP Pythonパッケージ
この本では、UCI Machine Learningリポジトリや他の類似のリソースなど、公開されているデータセットを使用しています。いくつかの例として、自転車の共有、クレジットカードの不払い、ファンド管理、犯罪率などのデータセットがあります。
データ収集のプロセスを通じてさまざまなソースからデータを収集し、ソースからデータをインポートすることを学ぶことは、データサイエンスプロジェクトにとって非常に重要です。
しかし、データ収集のステップに慣れていない学習者にとっては、理論と実践の両方を学ぶためにこの本を使用する場合に学習プロセスに摩擦を生じる可能性があります。
スムーズな学習体験を促進するために、本には付属のISLPパッケージが付属しています。
- ISLPパッケージはすべての主要なプラットフォーム(Linux、Windows、MacOS)で利用可能です。
- ISLPはpipを使用してインストールできます:
pip install islp、できれば仮想環境内でマシン上にインストールします。
ISLPパッケージには包括的なドキュメンテーションがあります。ISLPパッケージにはデータの読み込みユーティリティが付属しています。特定のデータセットで作業する際には、ドキュメントページでデータセットのさまざまな特徴、レコード数、データをpandasのデータフレームに読み込むためのスターターコードなどの情報を簡単に取得することができます。
また、多項式やスプライン特徴量などの高次の特徴を作成するためのヘルパー関数や機能もあります。
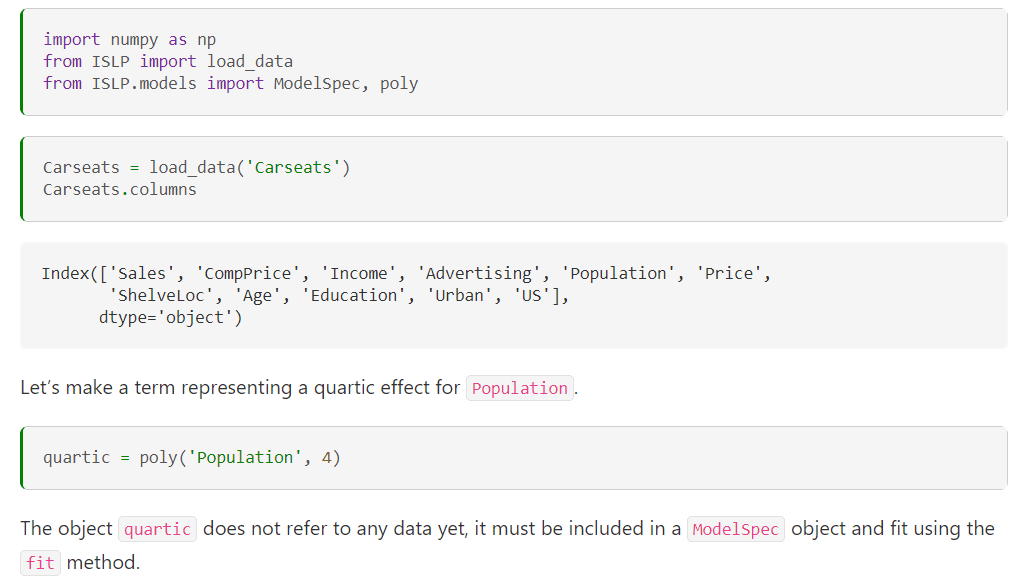
より充実した学習体験のために、ISLPパッケージを使わずにデータを元のソースから読み込み、特徴エンジニアリングを行うこともできます。
モデルを構築する際には、scikit-learnのみを使った実装や、ディープラーニングセクションにはPyTorchやKerasを試すこともできます。
この本は誰のためのものですか?
データサイエンスと機械学習の初心者: 機械学習を学ぶための自己学習のルートを選ぶ初心者の方にとって、この本は素晴らしい学習資源です。
機械学習の実践者: 機械学習の実践者として、機械学習モデルの構築に経験があります。しかし、仮説検定や他のアルゴリズムなどの基礎に戻ることは役立つことがあります。
教育者: 理論と実習が一緒になったこの本は、機械学習の初めてのコースの教材として最適です。現在、ほとんどの大学やデータサイエンスのブートキャンプでは機械学習を教えています。機械学習のコースを教えている、または教える予定の教育者の方にとって、この教材は考慮に値する素晴らしい教科書です。
まとめ
以上です。Pythonによる統計的学習入門は、今年の夏の最も注目すべきリリースのひとつです。
statlearning.comにアクセスしてPython版を読み始めることができます。ソフトコピーは無料で読むことができますが、Amazonでのペーパーバック版は初日に完売しました。ですので、本を最大限に活用していただけることを楽しみにしています。今日から読んで学んでください。幸せな学びの時間を! Bala Priya Cは、インド出身の開発者兼技術ライターです。彼女は数学、プログラミング、データサイエンス、コンテンツ作成の交差点での仕事が好きです。彼女の関心と専門知識の範囲にはDevOps、データサイエンス、自然言語処理が含まれます。彼女は読書、執筆、コーディング、そしてコーヒーが好きです!現在、彼女はチュートリアル、ハウツーガイド、オピニオン記事などを執筆することで、開発者コミュニティとの知識共有と学習に取り組んでいます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- OpenAIのLLMの支配を覆すことを目指す挑戦者:XLSTM
- 「AIと産業のデジタル化の時代に、開かれたUSDに開発者が注目」 Note OpenUSD refers to an open-source software library called USD (Universal Scene Description), which is commonly used in computer graphics and animation.
- 「AIがクリーンエネルギーの未来を支える方法」
- 「REPLUG」をご紹介しますこれは、凍結された言語モデルと凍結/調整可能なリトリーバを組み合わせた、検索増強型言語モデリング(LM)フレームワークですこれにより、GPT-3(175B)の言語モデリングの性能が6.3%向上します
- 「深層学習を用いた深層オブジェクト:ZoeDepthはマルチドメインの深度推定のためのAIモデルです」
- FedMLとThetaが分散型AIスーパークラスターを発表:生成AIとコンテンツ推薦を強化
- 「パフォーマンスと使いやすさを向上させるための機械学習システムにおけるデザインパターンの探求」