「NumPyとPandasの入門」
Introduction to NumPy and Pandas
Pythonは、データサイエンスの分野で最もよく使われる言語であり、そのシンプルさ、大きなコミュニティ、オープンソースのライブラリの豊富さから人気があります。
データサイエンスプロジェクトに取り組んでいる場合、Pythonパッケージはあなたの生活を簡単にします。複雑な操作、例えばデータの操作や機械学習/ディープラーニングモデルの適用には、わずか数行のコードだけで済みます。
データサイエンスの旅を始める際には、NumPyとPandasという2つの最も便利なPythonパッケージを学ぶことをおすすめします。この記事では、これらの2つのライブラリを紹介します。さあ始めましょう!
- 『チュートリアルを超えて LangChainのPandasエージェントでデータ分析を学ぶ』
- YOLOV8によるANPR
- 「データとテクノロジーのリーダーシップの現在の状況- チーフAIオフィサーがチーフデジタライゼーションオフィサーに置き換わるか?」
NumPyとは?
NumPyはNumerical Pythonの略であり、機械学習モデルの裏側で効率的な配列や行列の計算を行うために使用されます。NumPyの構築要素は配列であり、リストと非常に似たデータ構造ですが、数学関数が大量に提供されているという違いがあります。言い換えれば、NumPy配列は多次元配列オブジェクトです。
NumPy配列の作成
リストまたはリストのリストを使用してNumPy配列を定義することができます:
import numpy as np
l = [[1,2,3],[4,5,6],[7,8,9]]
numpy_array = np.array(l)
numpy_array
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
リストのリストとは異なり、各行の間にインデントを入れて3×3の行列を可視化することができます。さらに、NumPyは配列の作成に40以上の組み込み関数を提供しています。
ゼロで満たされた配列を作成するには、関数np.zerosを使用します。形状を指定するだけで良いです:
zeros_array = np.zeros((3,4))
zeros_array
array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
同様に、1で満たされた配列を作成することもできます:
ones_array = np.ones((3,4))
ones_array
array([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
さらに、単位行列を作成することも可能です。単位行列は、主対角線上に1があり、その他の要素が0である正方行列です:
identity_array = np.identity(3)
identity_array
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
さらに、NumPyはランダムな配列を作成するためのさまざまな関数を提供しています。[0,1]の一様分布からランダムなサンプルで配列を作成するには、関数np.random.randを使用するだけです:
random_array = np.random.rand(3,4)
random_array
array([[0.84449279, 0.71146992, 0.48159787, 0.04927379],
[0.03428534, 0.26851667, 0.65718662, 0.52284251],
[0.1380207 , 0.91146148, 0.74171469, 0.57325424]])
前の関数と同様に、ランダムな値で配列を定義することもできますが、この場合は標準正規分布からの値を取ります:
randn_array = np.random.randn(10)
randn_array
array([-0.68398432, -0.25466784, 0.27020797, 0.29632334, -0.20064897,
0.7988508 , 1.34759319, -0.41418478, -0.35223377, -0.10282884])
もし、区間[low,high)に属するランダムな整数の配列を作成したい場合は、関数np.random.randintを使用するだけです:
randint_array = np.random.randint(1,20,20)
randint_array
array([14, 3, 1, 2, 17, 15, 5, 17, 18, 9, 4, 19, 14, 14, 1, 10, 17,
19, 4, 6])
インデックスとスライス
配列の作成に加えて、NumPyのもう一つの利点は、角括弧を使用して配列から要素を選択できることです。例えば、行列の最初の行を取り出してみましょう:
a1 = np.array([[1,2,3],[4,5,6]])
a1[0]
array([1, 2, 3])
次に、最初の行の3番目の要素を選択したいとします。この場合、行のインデックスと列のインデックスを指定する必要があります:
print(a1[0,2]) #3
a1[0][2]を使用することもできますが、最初に最初の行を含む配列を作成し、その行から要素を選択するため、効率が悪いとされています。
さらに、ブラケット内のstart:stop:stepの構文を使用して、行列からスライスを取得することもできます。ここで、stopのインデックスは含まれません。例えば、再び最初の行を選択しますが、最初の2つの要素だけを取ります:
print(a1[0,0:2])
[1 2]
すべての行を選択したい場合は、各行の最初の要素を抽出することもできます:
print(a1[:,0])
[1 4]
整数配列インデックスに加えて、配列から要素を選択するためのブール配列インデックスも使用できます。以下の条件を満たす要素のみを選択したい場合を考えてみましょう:
a1>5
array([[False, False, False],
[False, False, True]])
この条件に基づいて配列をフィルタリングすると、Trueの要素のみが表示されます:
a1[a1>5]
array([6])
配列の操作
データサイエンスプロジェクトで作業する際に、データを変更せずに配列の形状を新しい形状に変更することがよくあります。
例えば、2X3の次元を持つ配列から始めます。配列の形状が確定していない場合、属性shapeを使用することができます:
a1 = np.array([[1,2,3],[4,5,6]])
print(a1)
print('配列の形状:',a1.shape)
[[1 2 3]
[4 5 6]]
配列の形状: (2, 3)
配列を次元3X2に変形するには、単純にreshape関数を使用するだけです:
a1 = a1.reshape(3,2)
print(a1)
print('配列の形状:', a1.shape)
[[1 2]
[3 4]
[5 6]]
配列の形状: (3, 2)
もう一つよくある状況は、多次元配列を一次元配列に変換することです。これは、shapeに-1を指定することで可能です:
a1 = a1.reshape(-1)
print(a1)
print('配列の形状:', a1.shape)
[1 2 3 4 5 6]
配列の形状: (6,)
また、転置行列を取得する必要がある場合もあります:
a1 = np.array([[1,2,3,4,5,6]])
print('変更前の配列の形状:', a1.shape)
a1 = a1.T
print(a1)
print('変更後の配列の形状:', a1.shape)
変更前の配列の形状: (1, 6)
[[1]
[2]
[3]
[4]
[5]
[6]]
変更後の配列の形状: (6, 1)
同様に、np.transpose(a1)を使用して同じ変換を適用することもできます。
配列の乗算
機械学習アルゴリズムをゼロから構築しようとする場合、2つの配列の行列積を計算する必要があります。これは、配列が1次元以上の場合にはnp.matmul関数を使用して可能です:
a1 = np.array([[1,2,3],[4,5,6]])
a2 = np.array([[1,2],[4,5],[7,8]])
print('配列a1の形状:', a1.shape)
print('配列a2の形状:', a2.shape)
a3 = np.matmul(a1,a2)
# a3 = a1 @ a2
print(a3)
print('配列a3の形状:', a3.shape)
配列a1の形状: (2, 3)
配列a2の形状: (3, 2)
[[30 36]
[66 81]]
配列a3の形状: (2, 2)
@はnp.matmulの短い代替方法です。
行列とスカラーの乗算を行う場合、np.dotが最適な選択肢です:
a1 = np.array([[1,2,3],[4,5,6]])
a3 = np.dot(a1,2)
# a3 = a1 * 2
print(a3)
print('配列a3の形状:', a3.shape)
[[ 2 4 6]
[ 8 10 12]]
配列a3の形状: (2, 3)
この場合、*はnp.dotの短い代替方法です。
数学関数
NumPyは、三角関数、丸め関数、指数関数、対数関数など、さまざまな数学関数を提供しています。フルリストはこちらで確認できます。ここでは、問題に適用できる最も重要な関数を紹介します。
指数関数と自然対数は、間違いなく最もポピュラーで知られている変換です:
a1 = np.array([[1,2,3],[4,5,6]])
print(np.exp(a1))
[[ 2.71828183 7.3890561 20.08553692]
[ 54.59815003 148.4131591 403.42879349]]
a1 = np.array([[1,2,3],[4,5,6]])
print(np.log(a1))
[[0. 0.69314718 1.09861229]
[1.38629436 1.60943791 1.79175947]]
1行のコードで最小値と最大値を抽出したい場合、次の関数を呼び出すだけです:
a1 = np.array([[1,2,3],[4,5,6]])
print(np.min(a1),np.max(a1)) # 1 6
配列の各要素の平方根も計算できます:
a1 = np.array([[1,2,3],[4,5,6]])
print(np.sqrt(a1))
[[1. 1.41421356 1.73205081]
[2. 2.23606798 2.44948974]]
Pandasとは何ですか?
PandasはNumpy上に構築され、データセットの操作に便利です。主なデータ構造はSeriesとDataframeです。Seriesは値のシーケンスであり、Dataframeは行と列からなるテーブルです。つまり、SeriesはDataframeの列です。
SeriesとDataframeの作成
Seriesを構築するには、値のリストをメソッドに渡すだけです:
import pandas as pd
type_house = pd.Series(['Loft','Villa'])
type_house
0 Loft
1 Villa
dtype: object
辞書オブジェクトを渡すことでDataframeを作成することもできます。キーは列名に対応し、値は列のエントリです:
df = pd.DataFrame({'Price': [100000, 300000], 'date_construction': [1960, 2010]})
df.head()

Dataframeが作成されたら、各列のタイプを確認できます:
type(df.Price),type(df.date_construction)
(pandas.core.series.Series, pandas.core.series.Series)
明らかに、列はSeries型のデータ構造です。
概要関数
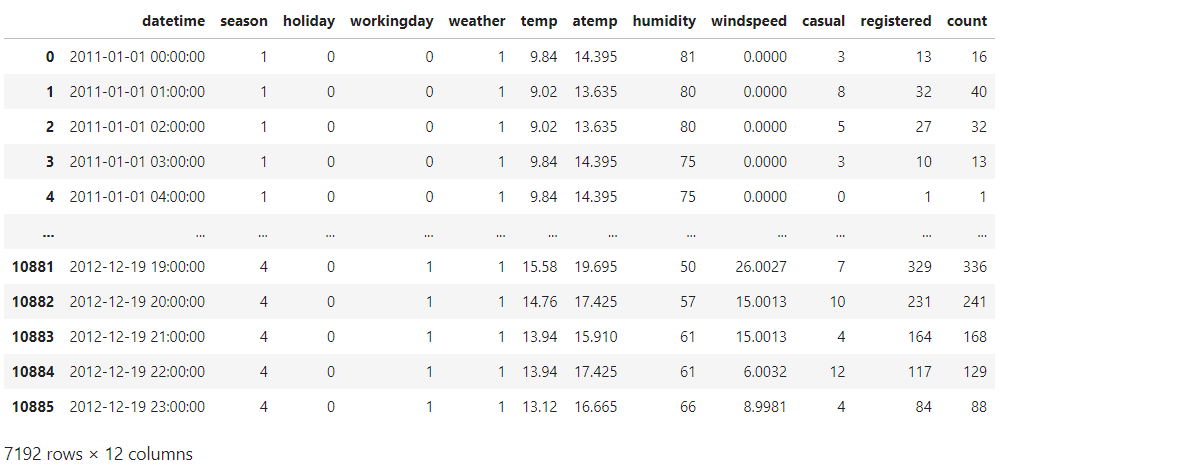
これ以降、Kaggleで利用可能な自転車シェアリングデータセットを使用して、Pandasの可能性を示します。CSVファイルを次の方法でインポートできます:
df = pd.read_csv('/kaggle/input/bike-sharing-demand/train.csv')
df.head()

PandasはCSVファイルだけでなく、Excelファイル、JSON、Parquetなど、他の種類のファイルも読み込むことができます。完全なリストはこちらでご確認いただけます。
出力からデータフレームの最初の5行を表示できます。データセットの最後の4行を表示したい場合は、tail()メソッドを使用します:
df.tail(4)

数行ではデータの全体像を把握するのに十分ではありません。データセットの形状を確認する良い方法は、shape属性を使用することです:
df.shape #(10886, 12)
行数が10886で列数が12です。列名を表示したいですか?非常に直感的に行うことができます:
df.columns

この情報を一度に表示するためのメソッドもあります:
df.info()

各列の統計情報を表示するには、describeメソッドを使用できます:
df.describe()
カテゴリカルなフィールドから情報を抽出することも重要です。season列のユニークな値とユニークな値の数を見つけることができます:
df.season.unique(),df.season.nunique()
出力:
(array([1, 2, 3, 4]), 4)
値は1, 2, 3, 4であり、4つの可能な値があります。この検証は、カテゴリカル変数を理解し、列に含まれる可能性のあるノイズを防ぐために重要です。
各レベルの頻度を表示するには、value_counts()メソッドを使用できます:
df.season.value_counts()

最後のステップは、各列の欠損値の調査です:
df.isnull().sum()

幸いにも、これらのフィールドには欠損値はありません。
インデックスとスライシング
Numpyのように、データ構造からデータを選択するためのインデックスベースの選択があります。データフレームからエントリを取得するための2つの主要なメソッドがあります:
- ilocは整数位置に基づいて要素を選択します
- locはラベルまたはブール配列に基づいてアイテムを取得します。
最初の行を選択する場合、ilocが最適な選択肢です:
df.iloc[0]

代わりに、すべての行と2番目の列のみを選択したい場合、次のようにします:
df.iloc[:,1]

同時に複数の列を選択することも可能です:
df.iloc[0:3,[0,1,2,5]]

インデックスに基づいて列を選択することは複雑になります。列名を指定する方が良いでしょう。これはlocを使用することで可能です:
df.loc[0:3,['datetime','season','holiday','temp']]

Numpyと同様に、条件に基づいてデータフレームをフィルタリングすることも可能です。たとえば、weatherが1と等しいすべての行を返す場合:
df[df.weather==1]
特定の列で出力を返す場合は、locを使用できます:
df.loc[df.weather==1,['season','holiday']] 
新しい変数の作成
新しい変数の作成は、データからより多くの情報を抽出し、解釈性を向上させる上で非常に重要です。workingdayの値に基づいて新しいカテゴリ変数を作成することができます:
df['workingday_c'] = df['workingday'].apply(lambda x: '仕事' if x==1 else 'リラックス')
df[['workingday','workingday_c']].head()

複数の条件がある場合は、値を辞書とmapメソッドを使用してマッピングする方が良いです:
diz_season = {1:'冬',2:'春',3:'夏',4:'秋'}
df['season_c'] = df['season'].map(lambda x: diz_season[x])
df[['season','season_c']].head() 
グループ化とソート
カテゴリ列を基準にデータをグループ化したい場合があります。これはgroupbyを使用して可能です:
df.groupby('season_c').agg({'count':['median','max']})

各シーズンのレベルごとに、借りられた自転車の中央値と最大値を観察することができます。この出力は、列に基づいて順序付けされていないと混乱する可能性があります。sort_values()メソッドを使用して順序付けすることができます:
df.groupby('season_c').agg({'count':['median','max']}).reset_index().sort_values(by=('count', 'median'),ascending=False)

これで、出力がより意味を持つようになりました。夏に最も多くの自転車が借りられていることがわかりますが、冬は自転車を借りるのには適していない月です。
最後の考察
以上です!NumPyとPandasの基礎を学ぶためのこのガイドが役立つことを願っています。これらは通常別々に学習されますが、NumPyを先に理解し、その上に構築されたPandasを理解することは洞察になるかもしれません。
チュートリアルではカバーしていないメソッドが間違いなくありますが、これら2つのライブラリの最も重要で人気のあるメソッドをカバーすることを目標としました。コードはKaggleで見つけることができます。読んでいただきありがとうございます!良い一日をお過ごしください! Eugenia Anello は現在、イタリアのパドヴァ大学情報工学部の研究員です。彼女の研究プロジェクトは、継続的学習と異常検知の組み合わせに焦点を当てています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
