「マルチラベル分類:PythonのScikit-Learnを用いた入門」
Introduction to Multi-label Classification using Scikit-Learn in Python

機械学習のタスクでは、分類は入力データからラベルを予測するための教師あり学習の手法です。例えば、私たちは過去の特徴を使用して、誰かが販売オファーに興味があるかどうかを予測したいとします。利用可能なトレーニングデータを使用して機械学習モデルをトレーニングすることにより、入力データに対して分類タスクを実行することができます。
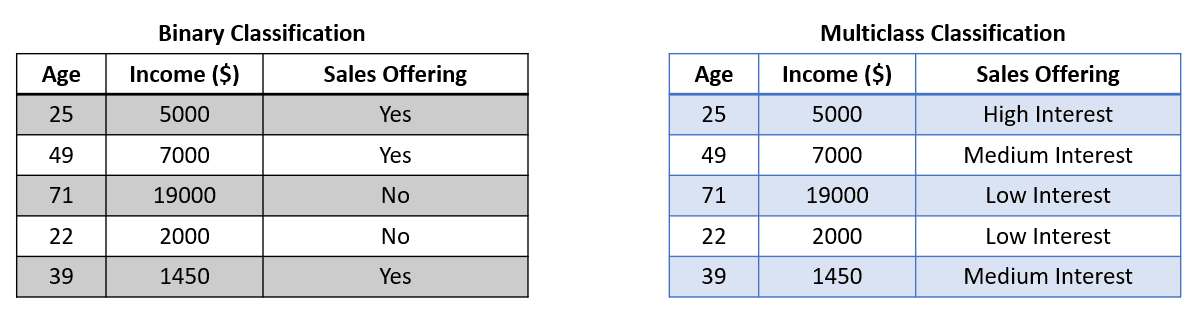
私たちはしばしば、バイナリ分類(2つのラベル)やマルチクラス分類(2つ以上のラベル)などのクラシックな分類タスクに遭遇します。この場合、私たちは分類器をトレーニングし、モデルが利用可能なすべてのラベルから1つのラベルを予測しようとします。分類に使用されるデータセットは以下の画像と似ています。
- 「BeLFusionに出会ってください:潜在的拡散を用いた現実的かつ多様な確率的人間の動作予測のための行動的潜在空間アプローチ」
- 「40以上のクールなAIツールをチェックアウトしましょう(2023年8月)」
- 大規模画像モデルのための最新のCNNカーネル
上記の画像は、ターゲット(販売オファー)がバイナリ分類では2つのラベル、マルチクラス分類では3つのラベルを含んでいることを示しています。モデルは利用可能な特徴からトレーニングされ、その後に1つのラベルのみを出力します。
マルチラベル分類は、バイナリ分類またはマルチクラス分類とは異なります。マルチラベル分類では、1つの出力ラベルだけで予測しようとはしません。代わりに、マルチラベル分類では、入力データに適用される可能性のあるラベルをできるだけ多く予測しようとします。出力は、ラベルがない場合から利用可能なラベルの最大数まで、さまざまな数のラベルになります。
マルチラベル分類は、テキストデータの分類タスクでよく使用されます。例えば、以下はマルチラベル分類のための例のデータセットです。
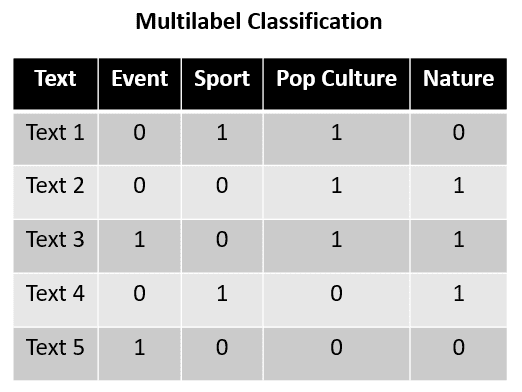
上記の例では、Text 1からText 5までのテキストが、Event、Sport、Pop Culture、Natureの4つのカテゴリに分類される文です。このデータセットを使用して、マルチラベル分類タスクでは、与えられた文にどのラベルが適用されるかを予測します。各カテゴリは他のカテゴリと対立するものではなく、相互排他的ではないため、各ラベルは独立して考えることができます。
詳細については、Text 1はSportとPop Cultureのラベルを持ち、Text 2はPop CultureとNatureのラベルを持つことがわかります。これは各ラベルが相互に排他的であり、マルチラベル分類ではラベルのいずれかを予測するだけでなく、すべてのラベルを同時に持つことができることを示しています。
その紹介の後、Scikit-Learnを使用してマルチクラス分類器を構築してみましょう。
Scikit-Learnを使ったマルチラベル分類
このチュートリアルでは、Kaggleから入手可能なバイオメディカルPubMedマルチラベル分類データセットを使用します。このデータセットにはさまざまな特徴が含まれていますが、abstractTextの特徴のみをMeSH分類(A:解剖学、B:生物、C:疾患など)と共に使用します。サンプルデータは以下の画像に示されています。
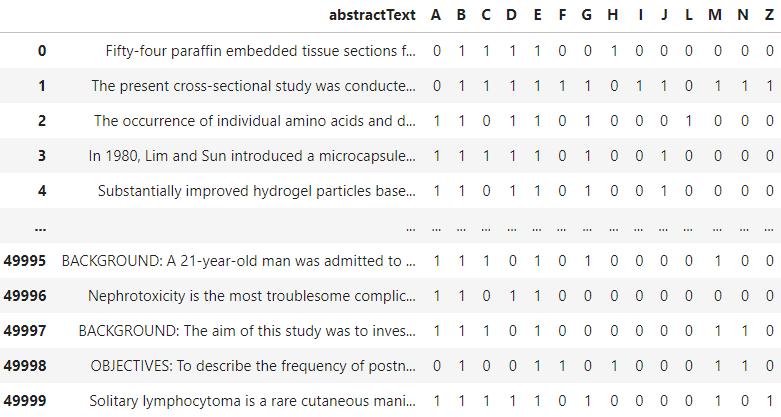
上記のデータセットは、各論文が1つ以上のカテゴリに分類されることを示しており、これはマルチラベル分類の場合です。このデータセットを使用して、Scikit-Learnを使ってマルチラベル分類器を構築することができます。モデルをトレーニングする前にデータセットを準備しましょう。
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
df = pd.read_csv('PubMed Multi Label Text Classification Dataset Processed.csv')
df = df.drop(['Title', 'meshMajor', 'pmid', 'meshid', 'meshroot'], axis =1)
X = df["abstractText"]
y = np.asarray(df[df.columns[1:]])
vectorizer = TfidfVectorizer(max_features=2500, max_df=0.9)
vectorizer.fit(X)
上記のコードでは、テキストデータをTF-IDF表現に変換して、Scikit-Learnモデルがトレーニングデータを受け入れるようにしています。また、チュートリアルを簡素化するために、ストップワードの除去などの前処理データのステップは省略しています。
データ変換後、データセットをトレーニング用とテスト用に分割します。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=101)
X_train_tfidf = vectorizer.transform(X_train)
X_test_tfidf = vectorizer.transform(X_test)
準備が完了したら、マルチラベル分類器のトレーニングを開始します。Scikit-Learnでは、MultiOutputClassifierオブジェクトを使用してマルチラベル分類器モデルをトレーニングします。このモデルの戦略は、各ラベルごとに1つの分類器をトレーニングすることです。基本的に、各ラベルには独自の分類器があります。
このサンプルではロジスティック回帰を使用し、MultiOutputClassifierがすべてのラベルに拡張されます。
from sklearn.multioutput import MultiOutputClassifier
from sklearn.linear_model import LogisticRegression
clf = MultiOutputClassifier(LogisticRegression()).fit(X_train_tfidf, y_train)
モデルやMultiOutputClasiffierに渡されるモデルパラメータを変更して、要件に応じて管理することができます。トレーニング後、モデルを使用してテストデータを予測しましょう。
prediction = clf.predict(X_test_tfidf)
prediction
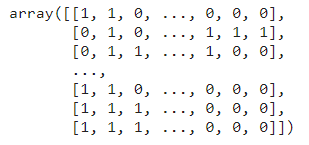
予測結果は、各MeSHカテゴリのラベルの配列です。各行は文を表し、各列はラベルを表します。
最後に、マルチラベル分類器を評価する必要があります。モデルを評価するために正確度メトリックを使用できます。
from sklearn.metrics import accuracy_score
print('Accuracy Score: ', accuracy_score(y_test, prediction))
Accuracy Score: 0.145
正確度スコアの結果は0.145であり、モデルが正確なラベルの組み合わせを予測できるのは14.5%以下の場合に限られることを示しています。ただし、正確度スコアはマルチラベル予測の評価には弱点があります。正確度スコアは各文が正確な位置にすべてのラベルを持っている必要があり、そうでなければ間違いとみなされます。
たとえば、最初の行の予測は予測とテストデータの間で1つのラベルのみが異なります。
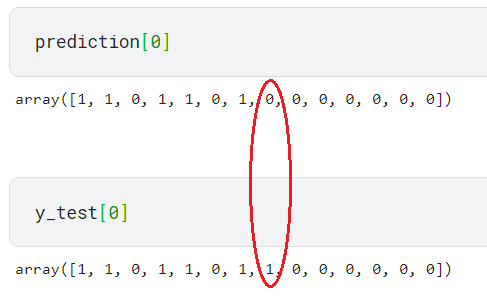
ラベルの組み合わせが異なるため、正確度スコアにおいては誤った予測とみなされます。そのため、モデルのメトリックスコアが低いです。
この問題を緩和するために、ラベルの予測を評価する必要があります。この場合、Hamming Loss評価メトリックに頼ることができます。Hamming Lossは、間違った予測の割合を全体のラベル数で割ることで計算されます。Hamming Lossは損失関数のため、スコアが低いほど良いです(0は間違った予測がなく、1はすべての予測が間違っていることを示します)。
from sklearn.metrics import hamming_loss
print('Hamming Loss: ', round(hamming_loss(y_test, prediction),2))
Hamming Loss: 0.13
マルチラベル分類器のHamming Lossモデルは0.13であり、モデルの予測が独立して13%の間違いがあることを意味します。つまり、各ラベルの予測は13%の確率で誤る可能性があります。
結論
マルチラベル分類は、入力データに対してラベルがない場合またはすべての可能なラベルがある場合に出力される機械学習のタスクです。これは、ラベルの出力が相互に排他的でないバイナリまたはマルチクラスの分類と異なります。
Scikit-LearnのMultiOutputClassifierを使用すると、各ラベルに対して分類器をトレーニングするマルチラベル分類器を開発することができます。モデルの評価には、AccuracyスコアではなくHamming Lossメトリックを使用する方が良いです。
Cornellius Yudha Wijayaはデータサイエンスアシスタントマネージャー兼データライターです。Allianz Indonesiaでフルタイムで働きながら、ソーシャルメディアや執筆メディアを通じてPythonとデータのヒントを共有することが好きです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「生成AI技術によって広まる気候情報の誤情報の脅威」
- 「CREATORと出会ってください:ドキュメントとコードの実現を通じて、LLMs自身が自分のツールを作成するための革新的なAIフレームワーク」
- アバカスAIは、新しいオープンロングコンテキスト大規模言語モデルLLM「ジラフ」を紹介します
- 「非常にシンプルな数学が大規模言語モデル(LLMs)の強化学習と高次関数(RLHF)に情報を提供できるのか? このAIの論文はイエスと言っています!」
- 「LEVER(リーバー)とは、生成されたプログラムの実行結果を検証することを学習することで、言語からコードへの変換を改善するためのシンプルなAIアプローチです」
- AWSの知的ドキュメント処理を生成AIで強化する
- マシンラーニングのロードマップ:コミュニティの推奨事項2023






