レコメンデーションシステムにおけるディープラーニング:入門
Introduction to Deep Learning in Recommendation Systems.
現代産業推奨システムの最も重要な技術的なブレークスルーのツアー

推奨システムは、今日最も急速に進化している産業用機械学習アプリケーションの一つです。ビジネス的な観点から見ると、これは驚くべきことではありません:より良い推奨はより多くのユーザーをもたらします。それだけです。
ただし、その基盤技術は簡単なものではありません。ディープラーニングの台頭以降、GPUの一般化によって推奨システムはますます複雑になっています。
この記事では、過去10年間における最も重要なモデリングのブレークスルーの中で、ディープラーニングの台頭をマーキングした重要なポイントを再構築することで、推奨システムにおけるディープラーニングの話をします。それは大陸と協力を超えた技術的なブレークスルー、科学的な探求、そして軍備競争の物語です。
準備をしてください。私たちのツアーは2017年のシンガポールから始まります。
NCF(シンガポール大学、2017年)
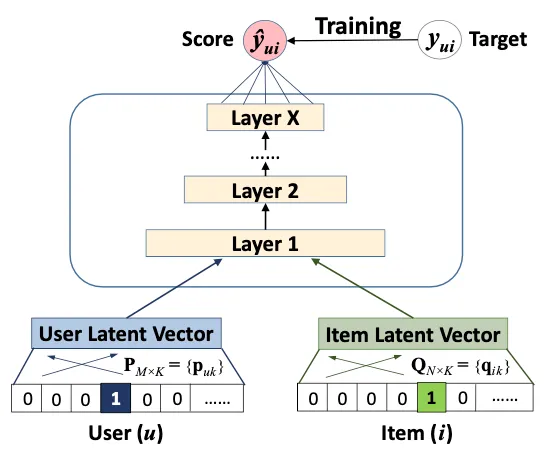
推奨システムにおけるディープラーニングに関する議論は、シンガポール大学のHe et al(2017)によって紹介された最も重要なブレークスルーの1つであるニューラル協調フィルタリング(NCF)の言及なしには不完全です。
NCF以前、推奨システムにおけるゴールドスタンダードは、ユーザーとアイテムの潜在ベクトル(エンベディングとも呼ばれる)を学習し、その後、ユーザーベクトルとアイテムベクトルのドット積を取ることでユーザーに推奨を生成する行列因子分解でした。ドット積が1に近いほど、線型代数からわかるように、予測されるマッチングは良くなります。したがって、行列因子分解は単純に潜在的な要因の線型モデルと見ることができます。
NCFの鍵となるアイデアは、行列因子分解の内積をニューラルネットワークで置き換えることです。実際には、まずユーザーとアイテムの埋め込みを連結し、それらを単一のタスクヘッドを持つ多層パーセプトロン(MLP)に渡して、ユーザーのエンゲージメント(クリックなど)を予測します。MLPの重みと埋め込みの重み(IDをそれらの対応する埋め込みにマッピングするもの)は、損失勾配の逆伝播によってモデルトレーニング中に学習されます。
NCFの仮説は、行列因子分解で仮定されているように、ユーザー/アイテムの相互作用が線形ではなく、非線形であるということです。それが真実であれば、MLPにより層を追加すると性能が向上するはずです。そして、Heらが見つけたのはまさにそれです。 4層で、彼らはMovielensとPinterestのベンチマークデータセットで当時最高の行列因子分解アルゴリズムを約5%ヒット率で打ち破ることができました。
Heらによって、推奨システムにおけるディープラーニングの大きな価値が証明され、行列因子分解からディープリコメンダーへの移行の重要な転機を迎えました。
Wide & Deep(Google、2016年)
私たちのツアーはシンガポールからカリフォルニア州マウンテンビューに移ります。
NCFが推奨システムの領域を革命化しましたが、推奨システムの成功に非常に重要な要素であるクロスフィーチャーが欠けています。クロスフィーチャーのアイデアは、Googleの2016年の論文「Wide & Deep Learning for Recommender Systems」で普及しました。
クロスフィーチャーとは何ですか?それは、元の2つのフィーチャーを「クロス」して作成された2次のフィーチャーです。たとえば、Google Playストアでは、第1のフィーチャーにはインストールされたアプリのリストなどが含まれます。これら2つを組み合わせて、強力なクロスフィーチャーを作成できます。
AND(user_installed_app='netflix', impression_app='hulu')これは、ユーザーがNetflixをインストールしており、印象付けられたアプリがHuluである場合に1となります。
クロスフィーチャーは、より一般的なものにすることもできます。例えば、
AND(user_installed_category='video', impression_category='music')などです。著者たちは、異なる粒度のクロスフィーチャーを追加することで、より細かいクロスからの記憶と、より一般的なクロスからの汎化が可能になると主張しています。
Wide&Deepの主要なアーキテクチャの選択は、すべてのクロスフィーチャーを直接入力として受け取る線形層であるワイドモジュールと、本質的にはNCFであるディープモジュールの両方を持ち、ユーザー/アプリのエンゲージメントから学習する単一の出力タスクヘッドに両モジュールを組み合わせることです。
そして確かに、Wide&Deepは驚くほどうまく機能します。著者たちは、ディープのみからワイド&ディープに移行することで、オンラインアプリの取得率が1%向上することを発見しています。Googleは年間数十億ドルの収益をGoogle Playストアから上げており、Wide&Deepがどれだけ影響力があるかがわかります。
DCN(Google、2017年)
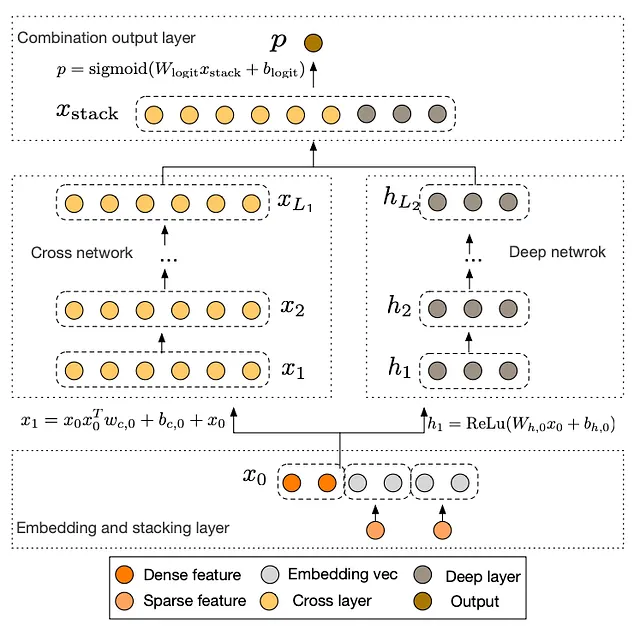
Wide&Deepは、クロスフィーチャーの重要性を示しましたが、巨大な欠点があります。クロスフィーチャーは手動でエンジニアリングする必要があり、エンジニアリングリソース、インフラストラクチャ、ドメイン知識が必要であり、コストがかかります。Wide & Deepのクロスフィーチャーは高価です。スケーリングできません。
Googleからも紹介された2017年の論文である「Deep and Cross neural networks(DCN)」に登場し、Wide&Deepのワイドコンポーネントを「クロスニューラルネットワーク」で置き換えるというキーのアイデアがあります。これは、任意の高次クロスフィーチャーを学習するニューラルネットワークです。
クロスニューラルネットワークとは何ですか?リマインダーとして、MLPでは、次のレイヤーの各ニューロンは、前のレイヤーのすべてのレイヤーの線形結合です。
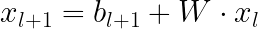
対照的に、クロスニューラルネットワークでは、次のレイヤーは、自分自身との第1レイヤーの2次の組み合わせを形成することによって構築されます。
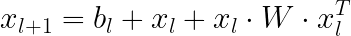
したがって、深さLのクロスニューラルネットワークは、Lまでの次数の多項式の形でクロスフィーチャーを学習します。ニューラルネットワークが深くなるほど、高次の相互作用が学習されます。
そして実験結果は、DCNが機能することを確認しています。 Criteoディスプレイ広告ベンチマークデータセットでは、ディープコンポーネントのみを持つモデルと比較して、DCNは0.1%低いログロス(統計的に有意と考えられる)を持ちます。そして、Wide&Deepのように手動のフィーチャーエンジニアリングはありません!
(Criteoデータセットのクロスフィーチャーを手動で作成する良い方法がなかったため、DCNの著者はこの比較をスキップしました。)
DeepFM(Huawei、2017年)
次に、2017年のGoogleから2017年のHuaweiに移ります。
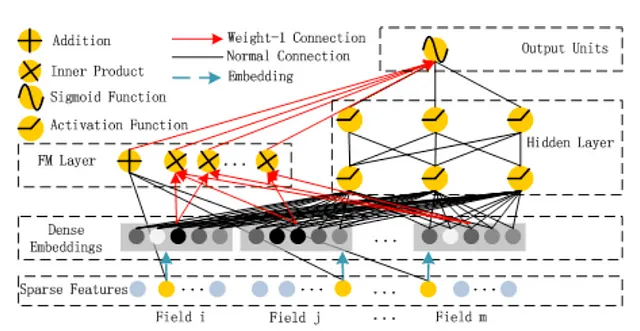
深い推薦のためのHuaweiのソリューション「DeepFM」は、Wide&Deepのワイドコンポーネントでの手動フィーチャーエンジニアリングを、交差フィーチャーを学習する専用のニューラルネットワークに置き換えます。ただし、DCNとは異なり、ワイドコンポーネントは「因数分解マシン」(FM)レイヤーであるため、クロスニューラルネットワークではありません。
FM層は何をするのでしょうか?単純に、全ての埋め込みのペアのドット積を取っています。例えば、映画の推薦システムがユーザーID、映画ID、俳優ID、監督IDなどの4つのID特徴を入力として受け取る場合、モデルはそれぞれのID特徴に対して埋め込みを学習し、FM層はユーザー-映画、ユーザー-俳優、ユーザー-監督、映画-俳優、映画-監督、俳優-監督の6つのドット積を計算します。これは行列分解のアイデアの復活です。FM層の出力は、ディープコンポーネントの出力と組み合わされ、シグモイド活性化された出力になり、モデルの予測を導きます。
そして、DeepFMがうまく機能することが示されていることは確かです。著者らは、AUCとLoglossの両方の指標で、GoogleのWide&Deepを含む多数の競合他社を、社内データにおいてそれぞれ0.37%と0.42%以上上回ることを示しています。
DLRM(Meta、2019年)
さて、GoogleやHuaweiについては一旦置いておきましょう。今回のツアーの次の停車場は、2019年のMetaです。
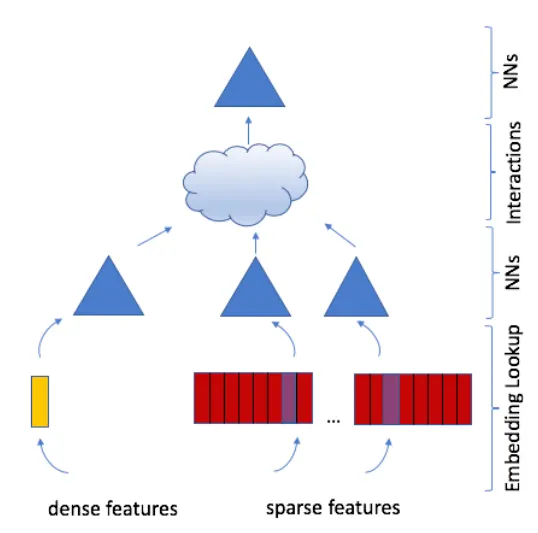
MetaのDLRM(“deep learning for recommender systems”)アーキテクチャは、Naumov et al(2019)で発表されたもので、以下のように機能します。すべてのカテゴリ特徴は、埋め込みテーブルを使用して埋め込みに変換されます。全ての密な特徴は、その特徴のための埋め込みを計算するMLPに渡されます。重要なことに、すべての埋め込みは同じ次元を持っています。その後、単にすべての埋め込みのペアのドット積を計算し、それらを1つのベクトルに連結し、シグモイド活性化されたタスクヘッドを持つ最終MLPを通して予測を生成します。
DLRMは、DeepFMの単純化されたバージョンのようなものです。DeepFMを取り、ディープコンポーネントを削除して(FMコンポーネントのみを保持して)、DLRMの密なMLPを除いたものがDLRMに似ています。
実験では、Naumov et alは、Criteoディスプレイ広告ベンチマークデータセットにおいて、トレーニングおよび検証の両方の精度において、DLRMがDCNを上回ることを示しています。この結果は、DCNのディープコンポーネントが実際には不要かもしれないことを示唆し、DLRMではドット積によって特徴の相互作用が捉えられているため、最良の推薦を実現するために必要なのはそれだけだということを示しています。
DHEN(Meta、2022年)
DCNとは異なり、DLRMの特徴の相互作用は2次のみに制限されています:すべての埋め込みのペアのドット積だけです。映画の例に戻って(ユーザー、映画、俳優、監督の特徴を持つ)、2次の相互作用はユーザー-映画、ユーザー-俳優、ユーザー-監督、映画-俳優、映画-監督、俳優-監督の6つです。3次の相互作用は、ユーザー-映画-監督、俳優-俳優-ユーザー、監督-俳優-ユーザーなどです。特定のユーザーは、トム・ハンクス出演のスティーブン・スピルバーグ監督の映画のファンかもしれませんが、それに対応する交差特徴が存在するべきです!残念ながら、標準のDLRMにはありません。それが大きな制限です。
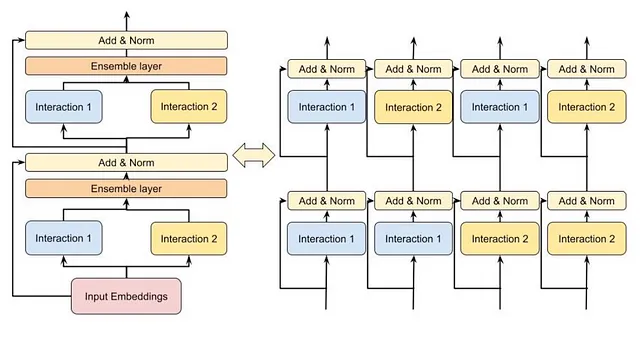
ここで、現代の推薦システムのツアーの最後の画期的な論文であるDHENが登場します。DHENは「Deep Hierarchical Ensemble Network」の略で、キーとなるアイデアは、DHENレイヤーの数に応じてより深い「階層」の交差特徴を作成することです。
最初にシンプルな例でDHENを理解しましょう。DHENに入力される2つの特徴をAとBで表すとしましょう(例えば、ユーザーIDとビデオID)。2層のDHENモジュールは、以下のような2次までの交差特徴の階層を作成します。
A, AxA, AxB, B, BxB,ここで、「x」は以下の5つの相互作用のいずれか、またはそれらの組み合わせであることに注意してください:
- ドット積、
- セルフアテンション、
- 畳み込み、
- 線形:y = Wx、または
- DCNのクロスモジュール。
DHENは獣であり、その再帰的な性質による計算の複雑さは悪夢です。DHEN論文の著者たちは、「Hybrid Sharded Data Parallel」と呼ばれる新しい分散トレーニングパラダイムを発明する必要がありました。この方法により、(当時)最先端のスループットよりも1.2倍高いスループットを実現しました。
しかし、最も重要なことは、この獣が機能することです。内部のクリックスルーレートデータの実験により、著者たちは8(!)個のDHEN層のスタックを使用して、DLRMに比べてNEの0.27%の改善を測定しています。
要約
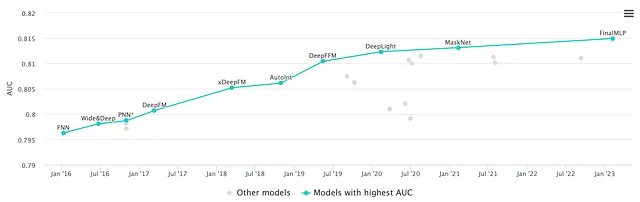
このツアーを締めくくります。各ランドマークを単一の見出しで要約します。
- NCF:ユーザーとアイテムの埋め込みだけが必要です。MLPが残りを処理します。
- Wide&Deep:クロス機能が重要です。実際、それらはタスクヘッドに直接フィードします。
- DCN:クロス機能は重要ですが、手動で設計すべきではありません。クロスニューラルネットワークに処理させましょう。
- DeepFM:クロス機能をFM層で生成し、Wide&Deepから深いコンポーネントを維持します。
- DRLM:FMだけで十分です-また、密な機能用の専用MLPが必要です。
- DHEN:FMだけでは十分ではありません。より高次(2次以上)の階層的な特徴の相互作用が必要です。また、それを実際に動作させるための多くの最適化も必要です。
そして、旅はまだまだ始まったばかりです。この記事を書いている時点で、DCNはDCN-Mに進化し、DeepFMはxDeepFMに進化し、Criteoコンペティションのリーダーボードは、Huaweiの最新の発明であるFinalMLPによって占められています。
より良い推奨システムのための巨大な経済的インセンティブがあるため、この分野では将来的に新しいブレークスルーが続くことが保証されています。このスペースを注視してください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
