「データサイエンスにおけるデータベース入門」
Introduction to Databases in Data Science

データサイエンスは、ビジネスの意思決定を促進するために大量のデータから価値と洞察を抽出することを含みます。また、過去のデータを使用して予測モデルを構築することも含まれます。データベースは、そのような大量のデータの効果的な格納、管理、検索、分析を可能にします。
ですから、データサイエンティストとしては、データベースの基礎を理解する必要があります。なぜなら、データの探索、モデリング、洞察のための効率的なデータセットの格納と管理を可能にするからです。この記事では、これについて詳しく探っていきましょう。
まずは、データサイエンスにおける必要なデータベースのスキルについて、データの取得のためのSQL、データベースの設計、最適化などを含めて説明します。次に、主なデータベースの種類、それらの利点、および使用例について説明します。
- データサイエンスの誕生:史上初の仮説検定とPythonの洞察
- 「カスタムPyTorchオペレーターを使用してDLデータ入力パイプラインを最適化する方法」
- これらの4つのパッケージで、あなたの探索的データ分析を簡素化する
データサイエンスにおける必要なデータベーススキル
データサイエンティストにとって、データベーススキルはデータの管理、分析、解釈のための基盤となります。
以下に、データサイエンティストが理解すべき主要なデータベーススキルを紹介します:
データベースの概念とスキルを異なるカテゴリに分類しようとしていますが、これらは一緒に使われることがあります。プロジェクトを進める中で、これらを知る必要があるかもしれません。
では、上記の各項目を詳しく見ていきましょう。
1. データベースの種類と概念
データサイエンティストとしては、関係型データベースやNoSQLデータベースなどのさまざまな種類のデータベースとそれぞれの使用例について理解しておく必要があります。
2. SQL(Structured Query Language)によるデータの取得
データ領域のどんな役割でも、SQLによる熟練度は必要不可欠です。データベースからデータを取得、フィルタリング、集計、結合するためのSQLクエリを書き、最適化することができる必要があります。
また、クエリの実行計画を理解し、パフォーマンスのボトルネックを特定し、解決することも役立ちます。
3. データモデリングとデータベース設計
データベースのテーブルにクエリを行うだけでなく、エンティティリレーション(ER)ダイアグラム、スキーマ設計、データの妥当性検証制約など、データモデリングとデータベース設計の基礎を理解する必要があります。
また、効率的なクエリとデータの格納をサポートするデータベーススキーマの設計もできるようになるべきです。
4. データのクリーニングと変換
データサイエンティストとしては、生データを前処理し、分析に適した形式に変換する必要があります。データベースはデータのクリーニング、変換、統合のタスクをサポートすることができます。
そのため、さまざまなソースからデータを抽出し、適切な形式に変換し、データベースにロードして分析する方法を知っている必要があります。ETLツール、スクリプト言語(Python、R)、データ変換技術についても習熟していることが重要です。
5. データベースの最適化
データベースのパフォーマンスを最適化するための技術について把握しておくべきです。インデックスの作成、非正規化、キャッシュメカニズムの使用などが含まれます。
データベースのパフォーマンスを最適化するためには、インデックスを作成してデータの検索を高速化します。適切なインデックス作成により、データベースエンジンが必要なデータを迅速に検索できるようになります。
6. データの整合性と品質チェック
データの整合性は、データ入力のためのルールを定義する制約を通じて維持されます。ユニーク、ヌルでない、チェック制約などの制約は、データの正確性と信頼性を保証します。
トランザクションは、データの整合性を確保するために使用され、複数の操作が1つの原子的な単位として扱われることを保証します。
7. ツールや言語との統合
データベースは、人気のある分析および可視化ツールと統合できるため、データサイエンティストは効果的な分析と発表を行うことができます。そのため、Pythonなどのプログラミング言語を使用してデータベースに接続し、相互作用を行い、データ分析を行う方法を知っている必要があります。
Pythonのpandas、R、および可視化ライブラリなどのツールに精通していることも必要です。
要約すると、さまざまなデータベースの種類、SQL、データモデリング、ETLプロセス、パフォーマンス最適化、データの整合性、プログラミング言語との統合は、データサイエンティストのスキルセットの主要な要素です。
この初心者向けガイドの残りの部分では、基本的なデータベースの概念と種類に焦点を当てます。
リレーショナルデータベースの基礎
リレーショナルデータベースは、テーブルを使用してデータを構造化し、行と列を持つ形式で組織化して保存するデータベース管理システム(DBMS)の一種です。人気のあるRDBMSには、PostgreSQL、MySQL、Microsoft SQL Server、Oracleがあります。
例を使用して、いくつかの重要なリレーショナルデータベースの概念について詳しく説明します。
リレーショナルデータベースのテーブル
リレーショナルデータベースでは、各テーブルは特定のエンティティを表し、テーブル間の関係はキーを使用して確立されます。
リレーショナルデータベースのテーブルでデータがどのように組織化されているかを理解するために、エンティティと属性から始めると役立ちます。
よくあるのは、学生、顧客、注文、製品などのオブジェクトに関するデータを格納したい場合です。これらのオブジェクトはエンティティであり、属性を持っています。
たとえば、単純なエンティティである「学生」オブジェクトには、FirstName、LastName、Gradeの3つの属性があります。データを格納する際に、エンティティはデータベースのテーブルになり、属性は列名またはフィールドになります。そして、各行はエンティティのインスタンスです。
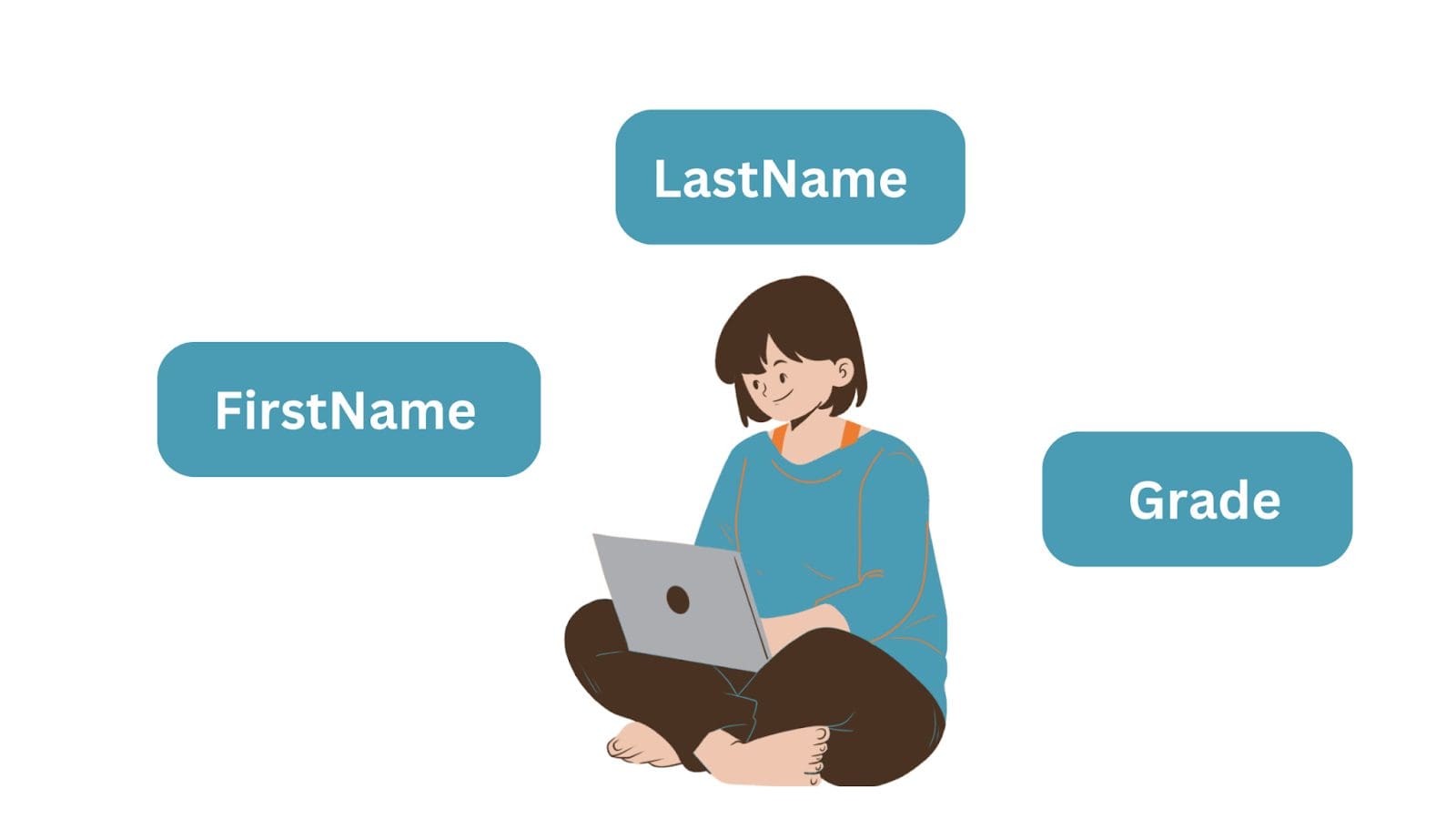
リレーショナルデータベースのテーブルは、行と列で構成されています:
- 行はレコードまたはタプルとしても知られています。
- 列は属性またはフィールドと呼ばれます。
次は、単純な「学生」テーブルの例です:
| StudentID | FirstName | LastName | Grade |
| 1 | Jane | Smith | A+ |
| 2 | Emily | Brown | A |
| 3 | Jake | Williams | B+ |
この例では、各行が学生を表し、各列が学生に関する情報を表しています。
キーの理解
キーはテーブル内の行を一意に識別するために使用されます。重要な2つのキーのタイプは次のとおりです:
- プライマリキー:プライマリキーはテーブル内の各行を一意に識別します。データの整合性を保証し、特定のレコードを参照する方法を提供します。「学生」テーブルでは、「StudentID」がプライマリキーとなります。
- 外部キー:外部キーはテーブル間の関係を確立します。他のテーブルのプライマリキーを参照し、関連するデータをリンクするために使用されます。たとえば、もう1つの「Courses」というテーブルがある場合、「Courses」テーブルの「StudentID」列は、「Students」テーブルの「StudentID」を参照する外部キーとなります。
関係
リレーショナルデータベースは、テーブル間の関係を確立することができます。以下に、最も重要で一般的に発生する関係を示します:
- 1対1の関係: 1対1の関係では、データベース内のテーブルの各レコードは、他のテーブルの1つのレコードにのみ関連付けられます。例えば、各学生に関する追加情報を持つ「StudentDetails」テーブルは、「Students」テーブルと1対1の関係を持つかもしれません。
- 1対多の関係:最初のテーブルの1つのレコードは、2番目のテーブルの複数のレコードに関連付けられます。例えば、「Courses」テーブルは、「Students」テーブルと1対多の関係を持ち、各コースには複数の学生が関連付けられます。
- 多対多の関係:両方のテーブルの複数のレコードが互いに関連付けられます。これを表すために、中間テーブルであるジャンクションまたはリンクテーブルが使用されます。例えば、「StudentsCourses」テーブルは、学生とコースの間に多対多の関係を確立するかもしれません。
正規化
正規化(データベース最適化技術の一環としてよく議論される)は、データの冗長性を最小限に抑え、データの整合性を向上させるためのデータの組織化プロセスです。これは、大きなテーブルをより小さな関連するテーブルに分割することを含みます。各テーブルは、データの重複を避けるために、単一のエンティティまたは概念を表すべきです。
例えば、「Students」テーブルと仮想の「Addresses」テーブルを考えると、正規化では、独自の主キーを持つ別個の「Addresses」テーブルを作成し、外部キーを使用して「Students」テーブルにリンクすることが含まれるかもしれません。
リレーショナルデータベースの利点と制限事項
以下に、リレーショナルデータベースのいくつかの利点を示します:
- リレーショナルデータベースは、データの構造化された整理された方法での格納を提供し、異なる種類のデータ間の関係を定義することが容易です。
- トランザクションのためにACID特性(原子性、一貫性、分離性、耐久性)をサポートし、データの整合性を保証します。
一方で、以下の制限事項があります:
- リレーショナルデータベースは、水平スケーラビリティに課題があり、膨大な量のデータや高トラフィック負荷を処理することが困難です。
- また、厳格なスキーマが必要であり、スキーマを変更せずにデータ構造を変更することは困難です。
- リレーショナルデータベースは、構造化されたデータと定義済みの関係に適していますが、文書、画像、マルチメディアコンテンツなどの非構造化または半構造化データの格納には適していない場合があります。
NoSQLデータベースの探索
NoSQLデータベースは、テーブル形式の行列形式でデータを格納しません(非リレーショナルです)。”NoSQL”という用語は、「SQLだけでなく」という意味で、これらのデータベースが従来のリレーショナルデータベースモデルとは異なることを示しています。
NoSQLデータベースの主な利点は、スケーラビリティと柔軟性です。これらのデータベースは、大量の非構造化または半構造化データを処理するように設計されており、従来のリレーショナルデータベースに比べてより柔軟でスケーラブルなソリューションを提供します。
NoSQLデータベースには、データモデル、ストレージメカニズム、クエリ言語が異なるさまざまなデータベースの種類が含まれます。一般的なNoSQLデータベースのカテゴリには、次のようなものがあります:
- キー値ストア
- ドキュメントデータベース
- カラムファミリデータベース
- グラフデータベース
では、それぞれのNoSQLデータベースのカテゴリについて詳しく説明し、特性、ユースケース、例、利点、制限事項を探ってみましょう。
キー値ストア
キー値ストアは、シンプルなキーと値のペアとしてデータを格納します。高速な読み取りと書き込み操作に最適化されています。キャッシュ、セッション管理、リアルタイム分析などのアプリケーションに適しています。
ただし、キーに基づく検索以外のクエリ機能が制限されているため、複雑な関係には適していません。
人気のあるキー値ストアには、Amazon DynamoDBとRedisがあります。
ドキュメントデータベース
ドキュメントデータベースは、JSONやBSONなどのドキュメント形式でデータを格納します。各ドキュメントは様々な構造を持つことができ、ネストや複雑なデータを可能にします。柔軟なスキーマにより、半構造化データの簡単な処理が可能であり、進化するデータモデルや階層的な関係をサポートします。
これらは、コンテンツ管理、eコマースプラットフォーム、カタログ、ユーザープロファイル、およびデータ構造が変化するアプリケーションに特に適しています。ドキュメントデータベースは、複数のドキュメントを含む複雑な結合または複雑なクエリに対しては効率的ではない場合があります。
MongoDBとCouchbaseは人気のあるドキュメントデータベースです。
カラムファミリーストア(ワイドカラムストア)
カラムファミリーストア、またはカラム指向データベースとも呼ばれるカラム指向データベースは、関係データベースの従来の行指向方式ではなく、カラム指向の方式でデータを整理・格納するタイプのNoSQLデータベースです。
カラムファミリーストアは、大規模なデータセットで複雑なクエリを実行する分析ワークロードに適しています。集計、フィルタリング、およびデータ変換は、カラムファミリーデータベースでより効率的に行われることが多いです。カラムファミリーストアは、大量の半構造化またはスパースデータの管理に役立ちます。
Apache Cassandra、ScyllaDB、およびHBaseは一部のカラムファミリーストアです。
グラフデータベース
グラフデータベースは、データと関係をノードとエッジでモデル化します。これにより、複雑な関係を表現することができます。これらのデータベースは、複雑な関係の処理と強力なグラフクエリ言語を効率的にサポートします。
これらのデータベースは、ソーシャルネットワーク、推薦エンジン、知識グラフなど、一般的には複雑な関係を持つデータに適しています。
人気のあるグラフデータベースの例には、Neo4jとAmazon Neptuneがあります。
多くのNoSQLデータベースの種類があります。では、どれを使用するかを決めるにはどうすればよいのでしょうか? 答えは、それは状況によるということです。
NoSQLデータベースの各カテゴリは、特定のユースケースに適したユニークな機能と利点を提供しています。アクセスパターン、スケーラビリティの要件、およびパフォーマンスの考慮事項を考慮して、適切なNoSQLデータベースを選択することが重要です。
まとめると、NoSQLデータベースは柔軟性、スケーラビリティ、パフォーマンスの点で利点を提供し、ビッグデータ、リアルタイム分析、動的なWebアプリケーションなど、さまざまなアプリケーションに適しています。ただし、データの整合性に関してはトレードオフがあります。
NoSQLデータベースの利点と制限事項
次は、NoSQLデータベースのいくつかの利点です:
- NoSQLデータベースは、水平スケーラビリティに対応しており、膨大なデータとトラフィックを処理することができます。
- これらのデータベースは柔軟で動的なスキーマを持っています。さまざまなデータ型や構造に対応する柔軟なデータモデルを持っており、非構造化または半構造化データに適しています。
- 多くのNoSQLデータベースは、分散および障害耐性の環境での動作を設計されており、ハードウェアの障害やネットワークの障害が発生しても高い可用性を提供します。
- これらのデータベースは非構造化または半構造化データを扱うことができ、さまざまなデータ型に適しています。
いくつかの制限事項には次のものがあります:
- NoSQLデータベースは、厳密なACID準拠よりもスケーラビリティとパフォーマンスを優先します。その結果、最終的な整合性が生じ、データの整合性が強く求められるアプリケーションには適していない場合があります。
- NoSQLデータベースはさまざまなAPIやデータモデルを備えたさまざまなバリエーションで提供されているため、標準化の欠如はデータベースの切り替えやシームレスな統合が困難になる場合があります。
NoSQLデータベースは一つの解決策ではありません。リレーショナルデータベースとNoSQLデータベースの選択は、アプリケーションの特定のニーズに依存します。データのボリューム、クエリパターン、スケーラビリティの要件などを考慮する必要があります。
リレーショナル vs. NoSQLデータベース
ここまでに議論した違いをまとめましょう:
| 特徴 | リレーショナルデータベース | NoSQLデータベース |
| データモデル | 表形式(テーブル) | 異なるデータモデル(ドキュメント、キーバリューペア、グラフ、カラムなど) |
| データ整合性 | 強い整合性 | 最終的な整合性 |
| スキーマ | 明確に定義されたスキーマ | 柔軟またはスキーマレス |
| データ関係 | 複雑な関係をサポート | タイプによって異なる(制約付きまたは明示的な関係) |
| クエリ言語 | SQLベースのクエリ | 特定のクエリ言語またはAPI |
| 柔軟性 | 非構造化データに対してはあまり柔軟ではありません | さまざまなデータ型に適しており、 |
| ユースケース | よく構造化されたデータ、複雑なトランザクション | 大規模な、高スループット、リアルタイムアプリケーション |
タイムシリーズデータベースに関する注意事項
データサイエンティストとして、タイムシリーズデータも扱うことになります。タイムシリーズデータベースも非リレーショナルデータベースですが、より具体的な用途があります。
タイムスタンプ付きのデータポイント(時間の経過によって記録されるデータポイント、例えばセンサーの読み取り値や株価など)の保存、管理、およびクエリ処理をサポートする必要があります。タイムベースのデータパターンの保存、クエリ処理、および分析のための専門機能を提供します。
タイムシリーズデータベースの例には、InfluxDB、QuestDB、TimescaleDBなどがあります。
結論
このガイドでは、リレーショナルデータベースとNoSQLデータベースについて説明しました。さらに、人気のあるリレーショナルデータベースとNoSQLデータベースの種類を超えて、いくつかのデータベースを探索することも価値があります。CockroachDBなどのNewSQLデータベースは、SQLデータベースの伝統的な利点と同時に、NoSQLデータベースの拡張性とパフォーマンスを提供します。
また、コンピュータのメインメモリ(RAM)にデータを主に格納および管理するインメモリデータベースも使用することができます。これは、データをディスク上に保存する従来のデータベースとは異なり、メモリ内での読み書き操作がディスクストレージに比べてはるかに高速に行えるため、大幅なパフォーマンスの向上が得られます。 Bala Priya C は、インド出身の開発者兼技術ライターです。彼女は数学、プログラミング、データサイエンス、コンテンツ作成の交差点での作業が好きです。彼女の関心と専門知識の領域には、DevOps、データサイエンス、自然言語処理などが含まれます。彼女は読書、執筆、コーディング、そしてコーヒーを楽しんでいます!現在は、チュートリアル、ハウツーガイド、意見記事などの執筆を通じて開発者コミュニティと知識を共有するための学習に取り組んでいます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
