データサイエンス入門:初心者向けガイド
Introduction to Data Science Beginner's Guide

過去20年間、あなたは岩の下に住んでいなかったので、データサイエンスについて、おおよそ何であるかはわかっているかもしれません。おそらく、データサイエンスを学び始め、仕事を見つけるために必要なことを簡単に把握したいと思っているでしょう。
この記事が提供するハイライトは以下の通りです:
- データサイエンスの主なポイント:データが入力され、洞察が得られる。データサイエンティストの仕事は、そのデータから洞察を得るためのパイプラインを各段階で管理することです。
- データサイエンスの仕事に必要なツール、技術、スキル。
- データサイエンスとしてのキャリアの一般的な概要。
もしそれがあなたが求めているものに聞こえるなら、さっそく始めましょう。
- 「カオスから秩序へ:データクラスタリングを活用した意思決定の向上」
- GOAT-7B-Communityモデルをご紹介します:GoatChatアプリから収集されたデータセットでLLaMA-2 7Bモデルを微調整したAIモデルです
- FraudGPT AIを活用したサイバー犯罪ツールの驚異的な台頭
データサイエンスとは何ですか?
先に述べたように、データサイエンスはデータから洞察を得るためのパイプラインとして最も簡潔にまとめられます。データサイエンティストとして、どの企業に所属していても、以下のようなタスクを行います:
- データの抽出
- データのクリーニングや整形
- データの分析
- パターンやトレンドの特定
- データの上に予測や統計モデルの構築
- データの可視化および伝達
つまり、問題を解決し、予測を行い、プロセスを最適化し、戦略的な意思決定を導きます。
非常に少数の企業がデータサイエンティストが具体的に何をするか正確に把握しているわけではないため、あなたの役割には他の責任もあるかもしれません。一部の雇用主は、データサイエンティストに情報セキュリティやサイバーセキュリティの責任を追加することを期待しています。他の企業では、データサイエンティストにクラウドコンピューティング、データベース管理、データエンジニアリング、ソフトウェア開発の専門知識を持つことを期待しているかもしれません。多くの役割を果たす準備をしておいてください。
この仕事が重要なのは、ハーバードビジネスレビューがそれを21世紀の最も魅力的な仕事と呼んだからではなく、データの量が増えているのに、データを洞察に変える方法をほとんどの人が知らないからです。データサイエンティストとして、あなたは木々を見ることができます。
2010年から2020年までの世界で作成、キャプチャ、コピー、消費されるデータ/情報の量、2021年から2025年までの予測を含む
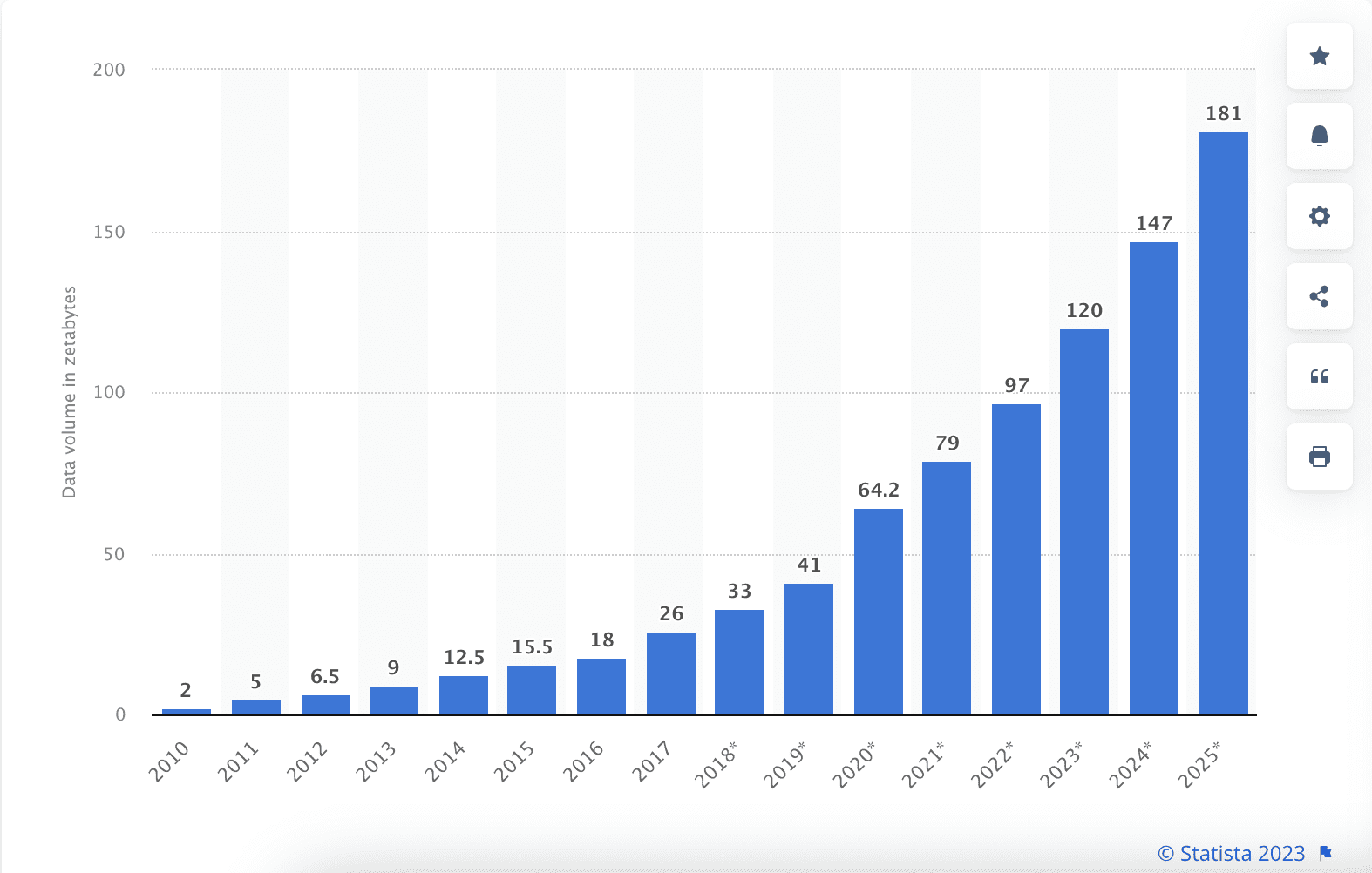
データサイエンスのキーポイント
これで全体像がわかりました。データサイエンスのいくつかのキーポイントを見てみましょう。データから洞察を得るためのパイプラインを想像できれば、それぞれのキーポイントがどこで重要になるかを特定します。
データの操作
そのパイプラインの最初の段階では、品質が異なるデータの混合物があります。データサイエンティストがデータのクリーニングに80%の時間を費やすという有名な(そして誤った)統計があります。それほど高くはないかもしれませんが、ファンネルの構築やデータの整形は仕事の重要な部分です。
例えば、あなたが電子商取引会社のデータサイエンティストであると想像してみてください。そこでは、データの操作は、顧客のトランザクションデータのクリーニングや変換、ウェブサイトの分析データや顧客関係管理(CRM)システムからのデータのマージや調整、欠損または不整合データの処理などが関わるかもしれません。
フォーマットの標準化、重複またはNaNの削除、外れ値や誤ったエントリの処理が必要になるかもしれません。このプロセスにより、データが正確で一貫性があり、分析の準備ができた状態になります。
データの探索と可視化
データが整形されたら、それを見ることができます。データサイエンティストはデータにすぐに統計モデルを適用し始めると思うかもしれませんが、真実はモデルがありすぎるためです。まず、手元のデータの種類を把握する必要があります。それから重要な洞察や予測を探すことができます。
例えば、GitHubのデータサイエンティストであれば、データの探索にはプラットフォーム上のユーザーのアクティビティやエンゲージメントの分析が含まれるでしょう。コミット数、プルリクエスト数、イシュー数などの指標や、ユーザーの相互作用やコラボレーションなどを見ることができます。このデータを探索することで、ユーザーがプラットフォームと関わりを持つ方法を理解し、人気のあるリポジトリを特定し、ソフトウェア開発のトレンドを発見することができます。
そして、人間のほとんどが表よりも写真の意義を解析することができるため、データ探索にはデータの可視化も含まれています。たとえば、GitHubのデータサイエンティストとして、時間の経過に伴うコミットの数を示す折れ線グラフを使用することがあります。バーチャートはプラットフォームで使用されるさまざまなプログラミング言語の人気を比較するために使用できます。ネットワークグラフはユーザーやリポジトリの共同作業を示すことができます。

統計分析
データサイエンスのデータから洞察を得るためのパイプラインのこの時点では、最初の2つのステップをカバーしました。データが入ってきて、それを探り、調べています。今度は洞察を引き出す時です。最後に、数値データに統計分析を適用する準備ができます。
Hello Freshのような企業のデータサイエンティストとして、顧客の離反に影響を与える要因を理解するために線形回帰などの統計分析を実行することがあります。クラスタリングアルゴリズムを使用して、顧客を嗜好や行動に基づいてセグメント化したり、仮説検定を行ってマーケティングキャンペーンの効果を判断したりすることもあります。これらの統計分析は、データ内の関係、パターン、および重要な知見を明らかにするのに役立ちます。
機械学習
データサイエンティストのすばらしいところは、未来を予測することです。データから洞察を得るパイプラインを視覚化してみてください。過去と現在の状況についての洞察を持っています。しかし、上司はおそらく尋ねるかもしれません。たとえば、新しい製品を提供に追加した場合、月曜日に休業した場合、半分のフリートを電気自動車に変換した場合、どうなるのでしょうか。
データサイエンティストとして、クリスタルボールを見て、機械学習を使用してインテリジェントな予測を作成します。たとえば、FedExのような物流会社のデータサイエンティストとして、過去の出荷データ、天気データ、およびその他の関連変数を使用して予測モデルを開発することができます。これらのモデルは、出荷量を予測したり、配達時間を推定したり、ルート計画を最適化したり、潜在的な遅延を予測したりすることができます。
回帰、時系列分析、またはニューラルネットワークなどの機械学習アルゴリズムを使用して、新しい配送センターの追加が配達時間に与える影響を予測したり、さまざまな運用変更が配送料に与える効果をシミュレートしたり、特定の配送サービスの顧客需要を予測したりすることができます。
コミュニケーションとビジネスインテリジェンス
データサイエンスで最も重要な概念は、機械学習やデータクリーニングではありません。それはコミュニケーションです。あなたは、ニューラルネットワークと勾配ブースティングアルゴリズムの違いを知らない会社の意思決定者に洞察を提示します。これがデータサイエンスの重要な概念であるコミュニケーションとビジネスの洞察です。
Metaのような企業のデータサイエンティストとして、ユーザーエンゲージメント指標と顧客の継続率との間に重要な相関関係を発見したばかりですが、「統計的な有意性」という概念について詳しく知らないマーケティング担当副社長と共有する必要があります。また、顧客生涯価値(CLV)についても理解している必要があり、発見の関連性と重要性を説明することができます。
データサイエンティストの必須スキル
データサイエンスの主要な概念をカバーしました。では、データサイエンティストとして期待される必須のスキルを見てみましょう。さらに詳しく学びたい場合は、データサイエンティストに必要ないくつかの細かいスキルもカバーしています。
プログラミング言語、データクエリ、およびデータ可視化
スキルを重要度でランク付けするのは難しいです – データサイエンティストは、それぞれ同じくらい重要なスキルの組み合わせが必要です。それにもかかわらず、絶対に欠かせないスキルが1つあるとすれば、それはプログラミングです。
プログラミングはいくつかの側面に分かれます – 通常、RまたはPython(または両方)などのプログラミング言語が必要です。また、関係データベースの場合はSQL(Structured Query Language)などのデータの取得と操作のためのクエリ言語も必要です。最後に、データの可視化にはTableauなどの他の言語やプログラムも必要ですが、最近ではPythonやRを使用してデータの可視化が行われることも多いです。
数学
先ほど言及した統計には覚えていますか?データサイエンティストとして、数学の知識が必要です。データの可視化は、実際の統計的な意義が必要になるまでしか進みません。重要な数学のスキルには、以下が含まれます:
- 確率と統計:確率分布、仮説検定、統計的推論、回帰分析、分散分析(ANOVA)など。これらのスキルを活用することで、データから適切な統計的判断を下し、意味のある結論を導くことができます。
- 線形代数:ベクトルと行列の操作、連立一次方程式の解法、行列の分解、固有値と固有ベクトル、行列変換など。これらの概念に精通していることは、モデルのトレーニング、最適化、微調整を行うために必要です。
- 微分積分学:導関数、勾配、最適化などの概念に精通している必要があります。これらの知識は、モデルのトレーニング、最適化、微調整に役立ちます。
- 離散数学:組合せ論、グラフ理論、アルゴリズムなどのトピック。これらを使用してネットワーク分析、推薦システム、アルゴリズム設計などを行います。特に大規模なデータを扱うアルゴリズムの開発には重要です。
モデル管理
では、モデルについて話しましょう。データサイエンティストとして、モデルの構築、展開、保守方法を知る必要があります。これには、モデルが既存のインフラストラクチャとシームレスに統合されること、スケーラビリティと効率の問題に対処すること、そして現実のシナリオでのパフォーマンスを継続的に評価することが含まれます。
技術的な観点では、以下に精通している必要があります:
- 機械学習ライブラリ:Pythonのscikit-learn、TensorFlow、PyTorch、または深層学習のためのKeras、勾配ブースティングのためのXGBoostまたはLightGBMなど。
- モデル開発フレームワーク:対話的で共同作業が可能なJupyter NotebookやJupyterLabなどのフレームワーク。
- クラウドプラットフォーム:Amazon Web Services(AWS)、Microsoft Azure、Google Cloud Platform(GCP)などを活用して、機械学習モデルを展開しスケーリングします。
- 自動機械学習(AutoML):Google AutoML、H2O.ai、またはDataRobotなどを使用して、繁雑なコーディングなしで機械学習モデルを構築するプロセスを自動化します。
- モデル展開とサービング:DockerとKubernetesは、モデルをコンテナとしてパッケージ化し展開するために一般的に使用されます。これにより、モデルを異なる環境で展開しスケーリングすることができます。さらに、PythonのFlaskやDjangoなどのツールを使用すると、モデルを提供し、プロダクションシステムに統合するためのWeb APIを作成することができます。
- モデルの監視と評価:ログの集約と分析のためのPrometheus、Grafana、またはELK(Elasticsearch、Logstash、Kibana)スタック。これらのツールは、モデルのメトリクスを追跡し、異常を検出し、モデルが時間とともに適切に機能し続けることを保証するのに役立ちます。
コミュニケーション
これまでに「ハード」なスキルについて説明しました。次は、必要なソフトスキルについて考えましょう。前述の「概念」の部分で言及したように、データサイエンティストとして重要なスキルの1つはコミュニケーションです。以下に、データサイエンティストとして行う必要のあるコミュニケーションのいくつかの例を示します:
- データストーリーテリング:複雑な技術的な概念を明確で簡潔な説明に変え、分析の重要性と意思決定への影響を伝える必要があります。
- 視覚化:データの視覚化には技術的なスキルだけでなく、どのようなチャートを作成し、どのようにデータの視覚化について話すかを知る必要があります。
- 協力とチームワーク:データエンジニア、ビジネスアナリスト、ドメインエキスパートと協力します。積極的なリスニングと建設的なフィードバックのスキルを磨いてください。
- クライアントマネジメント:すべてのデータサイエンティストに当てはまるわけではありませんが、クライアントや外部の利害関係者と直接取り組むこともあります。クライアントマネジメントのスキルを磨き、要件を理解し、期待に応え、プロジェクトの進捗状況について定期的に報告する必要があります。
- 継続的な学習と適応力:最新の技術動向について常に情報を収集し、必要に応じて新しいスキルや知識を取得する準備ができている必要があります。
ビジネスの知識
これは、数字がビジネスの文脈でなぜ重要なのかを理解することに帰結します。たとえば、日曜日に卵を買う人々と天気の間に高い有意な関係があることがわかるかもしれません。しかし、それがビジネスにとってなぜ重要なのでしょうか?
この場合、さらに分析を行い、日曜日の増加した卵の購入が晴れた天気と相関していることがわかるかもしれません。これは、顧客が好天候の条件下で屋外活動やブランチを楽しむ可能性が高いことを示しています。この洞察を利用することで、食料品店やレストランは在庫やプロモーション活動を計画することができます。
データパターンとビジネスの成果を結びつけることで、戦略的なガイダンスや実行可能な推奨事項を提供することができます。例えば、晴れた週末に卵関連の製品のマーケティングキャンペーンを最適化したり、地元のブランチスポットと提携を探索したりすることが考えられます。
データサイエンスのワークフロー
データサイエンティストは何をするのでしょうか? 理解するために、データサイエンスプロジェクトに関わる典型的なステップを見てみましょう:問題の定義、データの収集、データのクリーニング、探索的データ分析、モデル構築、評価、およびコミュニケーションです。
私は各ステップを例として説明します:このセクションの残りの部分では、あなたが電子商取引会社のデータサイエンティストとして働いていると想像し、会社のマーケティングチームが顧客の維持を改善したいと考えているとしましょう。
1. 問題の定義:
これはビジネス目標に理解を深め、問題の声明を明確にし、顧客の維持を測定するための主要な指標を定義することを意味します。
顧客の離脱に寄与する要因を特定し、離脱率を低減する戦略を開発することを目指します。
顧客の維持を測定するために、顧客の離脱率、顧客生涯価値(CLV)、リピート購入率、顧客満足度スコアなどの主要な指標を定義します。これらの指標を定義することにより、顧客の維持を改善する戦略の効果を追跡・評価するための数量化された方法を確立します。
2. データの収集
顧客の購入履歴、人口統計情報、ウェブサイトの相互作用、顧客フィードバックなど、関連するデータソースを収集します。このデータはデータベース、API、またはサードパーティのソースから取得できます。
3. データのクリーニング
収集したデータにはほとんどの場合、欠損値、外れ値、または不整合が含まれています。データのクリーニング段階では、欠損値の処理、重複の削除、外れ値の対処、およびデータの整合性の確保を行い、データを前処理してクリーニングします。
4. 探索的データ分析(EDA)
次に、データの洞察を得てその特性を理解するために、データを可視化し、統計的な要約を調べ、相関関係を特定し、パターンや異常を発見します。たとえば、頻繁な購入を行う顧客は離脱率が高い傾向にあることがわかるかもしれません。
5. モデルの構築
異なる変数と顧客の維持の関係を分析するための予測モデルを開発します。たとえば、購入頻度、顧客の人口統計情報、またはウェブサイトのエンゲージメントメトリクスなどのさまざまな要素に基づいて顧客の離脱の可能性を予測するために、ロジスティック回帰やランダムフォレストのような機械学習モデルを構築するかもしれません。
6. 評価
正確度、精度、再現率、またはROC曲線下の面積などの指標を使用して、モデルの性能を評価します。信頼性を確保するために、交差検証やトレインテスト分割などの技術を使用してモデルを検証します。
7. コミュニケーション
いくつかの結果を得ました – これをクラスと共有しましょう。私たちの例に合わせて、顧客の離脱結果についてビジネス全体および広いビジネス環境の文脈で賢く話す必要があります。人々に関心を持たせ、なぜこの特定の発見が重要であり、何をすべきかを説明します。
たとえば、顧客の離脱を分析すると、顧客満足度スコアと離脱率の間に有意な相関関係があることがわかるかもしれません。
マーケティングチームや上級幹部とこれを共有する際には、その意義と具体的な洞察を効果的に伝える必要があります。改善された顧客サポート、個別化された体験、またはターゲットされたプロモーションを通じて顧客満足度を向上させることに焦点を当てることにより、会社は離脱を抑制し、より多くの顧客を維持し、最終的に収益を増加させることができると説明します。
さらに、この発見を広いビジネス環境の中で位置づけます。競合他社との離脱率を比較します。
こうして、データの湖から実際のビジネスへと進む方法です。最終的には、データサイエンスは反復的で循環的なものであることを覚えておいてください。興味深い洞察を見つけ、ビジネスの質問に答え、雇用主の問題を解決するために、このプロセスの個々のステップおよび全体のプロセスを繰り返すことになります。
データサイエンスの応用
データサイエンスは広範な分野です。ほぼすべての業界、どんな規模の会社でもデータサイエンティストが働いています。これは重要な役割です。
以下は、複雑な問題を解決するためのデータサイエンスの影響を示すいくつかの実世界の例です:
- ヘルスケア:データサイエンティストは、患者の結果と医療の提供を改善するために、大量の医療データを分析します。彼らは高リスクの患者を特定するための予測モデルを開発し、治療計画を最適化し、疾病の流行のパターンを検出します。
- ファイナンス:リスク評価、詐欺検出、アルゴリズム取引、ポートフォリオ管理などを考えてみてください。データサイエンティストは、情報を基にした投資の意思決定を支援し、金融リスクを管理するモデルを開発します。
- 輸送と物流:データサイエンティストは、ルートプランニングを最適化し、燃料消費を削減し、サプライチェーンの効率を向上させ、メンテナンスのニーズを予測します。
- 小売りとEコマース:データサイエンティストは、顧客データ、購買履歴、ブラウジングパターン、人口統計情報を分析して、顧客エンゲージメントを促進し、売上を増やし、顧客満足度を向上させるモデルを開発します。
データサイエンスへの入門
さて、これはたくさんの情報です。今では、データサイエンスが何であり、それがどのように機能し、どのようなツールと技術に精通する必要があり、データサイエンティストが何をするかについて明確な理解を持っているはずです。
さて、どこでデータサイエンスを学び、実践するかを見てみましょう。これは別の記事になるかもしれませんので、始めるためのリソースのリストへのリンクを張ります。
- 最高の無料のデータサイエンスコース
- データサイエンスのための最高の学習リソース(書籍、コース、チュートリアル)
- 初心者向けの最高のPythonデータサイエンスプロジェクト
- 最高のコンピュータサイエンスの書籍
- データサイエンスの可視化のベストプラクティス
- データサイエンスプロジェクトのためのデータの入手先
- 重要なデータサイエンススキルを練習するための最高のプラットフォーム
- 参加するのに最適なデータサイエンスコミュニティ
全体的に、私は次のことをお勧めします:
- このブログ記事とデータサイエンティストの求人募集を使用して、必要なスキルのチェックリストを作成します。
- 基本を無料で始めて、さらに学ぶための良い有料プラットフォームを探します。
- プロジェクトとライブラリのポートフォリオを作成します。
- KaggleやStrataScratchなどのプラットフォームで練習します。
- 認定を取得します – LinkedInなどの一部のプラットフォームでは、スキルを証明するための認定を提供しています。
- 応募を開始します。
- ネットワークを構築します – コミュニティ、Slackグループ、LinkedInグループに参加し、イベントに参加します。
最終的には、このプロセスには時間がかかることが予想されます。しかし、最終的にはそれに値するでしょう。
求人の機会とキャリアパス
FAANGのレイオフにもかかわらず、US News and World Reportによれば、情報セキュリティアナリスト、ソフトウェア開発者、データサイエンティスト、統計学者は2022年の上位10の仕事にランクインしました。
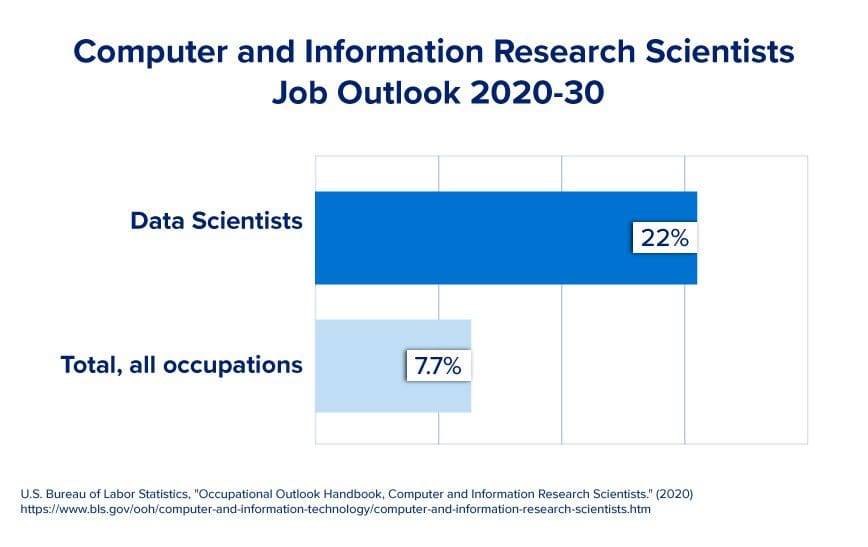
求人市場は依然として活況です。企業はまだデータサイエンティストを求めています。もしデータサイエンティストとしての仕事を見つけるのが難しい場合でも、最初からスタートする必要はありません。私は、より初心者向けの役職から始め、徐々に役職を目指すことをお勧めします。データアナリスト、データエンジニア、または機械学習エンジニアとして始めることができます。
結論
データサイエンスの紹介を書くのは難しいのは、それが巨大なフィールドであり、成長しており、毎日新しいテクノロジーやツールが追加されているからです。この投稿からわずかなことを学ぶなら、次のことを覚えておいてください:
- データサイエンスは多学科的なアプローチを取ります。統計学、機械学習、プログラミング、ドメインの専門知識など、さまざまな知識分野からのスキルが必要です。そして、学習は終わりません。
- データサイエンスは反復的です。非常にプロセスベースですが、続けながらプロセスを繰り返し、最適化し、更新することができます。成功し、満足しているデータサイエンティストは、実験を受け入れます。
- ソフトスキルが重要です。単にPythonの達人であるだけではなく、非技術的な利害関係者に対して、ストーリーや数字、図を使って結果と洞察を伝える必要があります。
これでスタートする場所が見つかったことを願っています。データサイエンスは、やりがいのあるチャレンジングなキャリアパスです。スキルを学び、自分自身に取り組めば、あっという間にこの分野に参加することができるでしょう。 Nate Rosidiは、データサイエンティストであり、プロダクト戦略に携わっています。彼はまた、アナリティクスの教授を務めており、StrataScratchの創設者でもあります。StrataScratchは、トップ企業の実際のインタビューの質問でデータサイエンティストが面接の準備をするのを支援するプラットフォームです。彼とのつながりはTwitter:StrataScratchまたはLinkedInです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
