ベイズ深層学習への優しい入門
Introduction to Bayesian Deep Learning
確率的プログラミングのエキサイティングな世界へようこそ!この記事は、その分野の優しい入門です。深層学習とベイズ統計の基本的な理解が必要です。
この記事の終わりまでに、この分野の基本的な理解、その応用、および従来の深層学習方法との違いを持つことができるはずです。
私と同じように、ベイジアンディープラーニングについて聞いたことがあり、ベイズ統計を関連付けていると予想しているが、具体的にどのように使用されるのかはわからない場合、ここが正しい場所です。
従来の深層学習の制約
従来の深層学習の主な制約の1つは、非常に強力なツールであるにもかかわらず、不確実性の尺度を提供しないことです。
Chat GPTは、まったくの自信を持って誤った情報を述べることができます。分類器はしばしばキャリブレーションされていない確率を出力します。
不確実性推定は、意思決定プロセスにおいて重要な側面です特に、医療、自動運転車などの分野では、脳腫瘍の分類について非常に不確実な場合、医療専門家によるさらなる診断が必要です。同様に、新しい環境を特定すると自動車は減速する能力が欲しいです。
ニューラルネットワークがリスクをどれほど悪く推定できるかを示すために、最後にソフトマックス層がある非常に単純な分類器ニューラルネットワークを見てみましょう。
ソフトマックスは非常に理解しやすい名前であり、ソフトマックス関数という意味です。これは、最大関数の「滑らかな」バージョンです。その理由は、最も確率の高いクラスを取る「ハード」な最大関数を選択した場合、他のすべてのクラスに対してゼロ勾配になってしまうからです。
ソフトマックスでは、クラスの確率は1に近くなることができますが、決して1にはなりません。また、すべてのクラスの確率の合計が1であるため、他のクラスにまだいくらかの勾配が流れます。
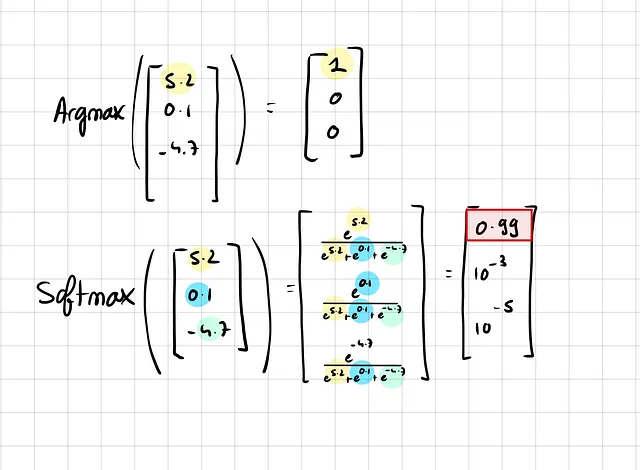
ただし、ソフトマックス関数には問題もあります。それはキャリブレーションが不十分な確率を出力することです。ソフトマックス関数を適用する前の値のわずかな変化は、指数によって押し潰され、出力確率への最小限の変化しか引き起こしません。
これはしばしば過信につながり、不確実性があるにもかかわらず、モデルが特定のクラスに高い確率を与える特性であり、ソフトマックス関数の「最大」の性質に内在しています。
従来のニューラルネットワーク(NN)とベイズニューラルネットワーク(BNN)を比較すると、不確実性推定の重要性が浮き彫りになります。BNNは、トレーニングデータからの既知の分布に遭遇すると確信度が高くなりますが、既知の分布から離れるにつれて不確実性が増し、より現実的な推定を提供します。
以下は、不確実性の推定の例です:
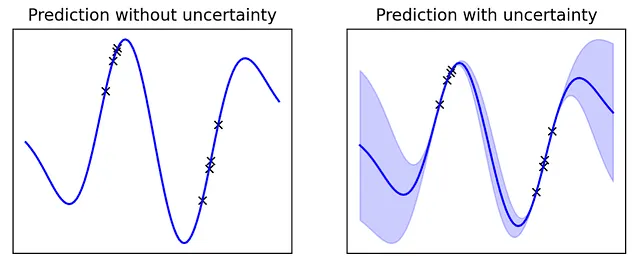
トレーニング中に観測した分布に近い場合、モデルは非常に確実ですが、既知の分布から遠ざかるにつれて不確実性が増します。
ベイズ統計の簡単なまとめ
ベイズ統計で知っておくべき中心的な定理が1つあります:ベイズの定理です。

- 事前確率は、観測の前に最も可能性が高いと考えられるθの分布です。たとえば、コイントスの場合、ヘッドが出る確率は p = 0.5 の周りのガウス分布と仮定できます。
- できるだけ帰納的なバイアスを入れたい場合、p を [0,1] の間の均一な確率とも言えます。
- 尤度は、パラメータθが与えられた場合、観測値X、Yを得る確率です。
- 周辺尤度は、可能なすべてのθについての尤度を積分したものです。これは「周辺」と呼ばれますが、確率のすべての可能性についてθを平均化することでθを周辺化しています。
ベイズ統計学を理解するための重要な考え方は、事前分布から始めることです。これはパラメータがどのようなものかの最善の推測(分布)です。そして、行った観測に基づいて推測を調整し、事後分布を得ます。
なお、事前分布と事後分布はθの確定的な推定値ではなく、確率分布であることに注意してください。
これを図で説明すると次のようになります:
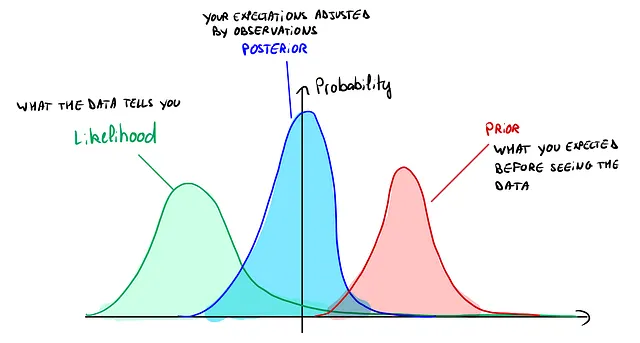
この図では、事前分布が右にシフトしていることがわかりますが、尤度によって事前分布は左に再バランスされ、事後分布はその間に位置しています。
ベイジアン深層学習の紹介
ベイジアン深層学習は、2つの強力な数学理論であるベイズ統計学とディープラーニングを結び付けるアプローチです。
従来のディープラーニングとの重要な違いは、モデルの重みの取り扱いにあります:
従来のディープラーニングでは、モデルをゼロからトレーニングし、ランダムに初期化された一連の重みを持ち、モデルを収束するまでトレーニングします。 単一の重みセットを学習します。
それに対して、ベイジアン深層学習はより動的なアプローチを採用しています。重みについての事前の信念から始め、通常は正規分布に従うと仮定します。データにモデルをさらすことで、この信念を調整し、重みの事後分布を更新します。 要するに、単一のセットではなく、重みの確率分布を学習します。
推論時には、すべてのモデルからの予測を重み付けして平均化します。重み付けは事後分布に基づいて行われます。 つまり、重みのセットが非常に確率的であれば、それに対応する予測にはより重みが与えられます。
それをすべて形式化しましょう:

ベイジアン深層学習における推論は、事後分布を用いてθ(重み)のすべての潜在的な値にわたる積分です。
また、ベイジアン統計学では積分が至る所に存在することもわかります。これは実際にはベイズフレームワークの主な制限です。これらの積分はしばしば解析的に扱いにくい(事後分布の原始関数を常に知っているわけではない)ため、非常に計算コストの高い近似を行う必要があります。
ベイジアン深層学習の利点
利点1:不確実性の推定
- ベイジアン深層学習の最も顕著な利点は、不確実性の推定能力です。ヘルスケア、自動運転、言語モデル、コンピュータビジョン、量的ファイナンスなどの多くの領域では、不確実性を量的化することが意思決定やリスク管理において重要です。
利点2:トレーニングの効率改善
- 不確実性の推定の概念と密接に関連するのが、トレーニングの効率改善です。ベイジアンモデルは自己の不確実性を認識しているため、不確実性(つまり学習の可能性)が最も高いデータポイントから学習を優先することができます。このアプローチはアクティブラーニングとして知られ、非常に効果的で効率的なトレーニングを実現します。
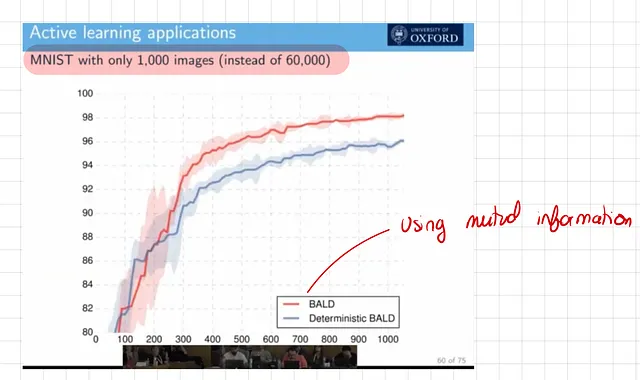
下のグラフで示されるように、アクティブラーニングを使用するベイジアンニューラルネットワークは、わずか1,000のトレーニング画像で98%の正確性を達成します。これに対して、不確実性推定を活用しないモデルは学習のペースが遅くなる傾向があります。
利点3:帰納的バイアス
ベイズ深層学習のもう一つの利点は、事前分布を通じた帰納バイアスの効果的な利用です。事前分布は、モデルパラメータに関する初期の信念や仮定をエンコードすることができます。これは、ドメイン知識が存在する場合に特に有用です。
例えば、生成型AIを考えてみましょう。ここでは、トレーニングデータに似た新しいデータ(例えば医療画像)を作成することが目的です。例えば、脳の画像を生成する場合、脳の一般的なレイアウトを既に知っている場合、この知識を事前分布に含めることができます。これにより、画像の中央に白質が存在する確率を高くし、側面には灰白質が存在する確率を高くすることができます。
要するに、ベイズ深層学習はデータから学習するだけでなく、ゼロから学習を始めるのではなく、既存の知識を元に学習を開始することができるため、幅広いアプリケーションにおいて強力なツールとなります。

ベイズ深層学習の制約事項
ベイズ深層学習は素晴らしいですが、なぜこの分野がそんなに低評価されているのでしょうか?確かに、私たちはしばしば生成型AIやChat GPT、SAM、あるいはより伝統的なニューラルネットワークについて話しますが、ベイズ深層学習についてはほとんど聞かないのはなぜでしょうか?
制約事項1:ベイズ深層学習は遅いです
ベイズ深層学習を理解するためのキーは、モデルの予測を「平均化」することであり、平均化がある場合、パラメータの集合上の積分があります。
しかし、積分を計算することはしばしば困難です。つまり、この積分を迅速に計算するための閉形式または明示的な形式は存在しないということです。ですので、直接計算することはできず、いくつかの点をサンプリングして積分を近似する必要があり、これにより推論が非常に遅くなります。
各データポイントxごとに10,000モデルの予測を平均化する必要があると仮定すると、各予測に1秒かかる場合、大量のデータには対応できないスケーラブルなモデルになってしまいます。
ほとんどのビジネスケースでは、迅速かつスケーラブルな推論が必要です。これがベイズ深層学習があまり人気がない理由です。
制約事項2:近似誤差
ベイズ深層学習では、重みの事後分布を計算するために変分推論などの近似手法を使用する必要があることがよくあります。これらの近似は最終的なモデルで誤差を引き起こす可能性があります。近似の品質は、変分ファミリや発散度の選択に依存するため、適切に選択して調整することが難しいことがあります。
制約事項3:モデルの複雑性と解釈性の増加
ベイズ手法は不確実性の改善を提供しますが、その代わりにモデルの複雑性が増します。BNN(ベイズニューラルネットワーク)は、単一の重みのセットではなく、可能な重みの分布を持つため、解釈が困難になる場合があります。特に解釈性が重要な分野では、この複雑性はモデルの意思決定の説明に課題をもたらす可能性があります。
XAI(解釈可能なAI)への関心は高まっており、既存のディープニューラルネットワークは重みの解釈が難しいため、ベイズ深層学習はさらに困難です。
ご意見、共有したいアイデア、私と一緒に働きたい、または単にこんにちはと言いたい場合は、以下のフォームに記入して、会話を始めましょう。
こんにちは 🌿
応援やフォローしていただけると嬉しいです!
参考文献
- Ghahramani, Z.(2015)。確率的機械学習と人工知能。Nature、521(7553)、452–459。 リンク
- Blundell, C.、Cornebise, J.、Kavukcuoglu, K.、Wierstra, D.(2015)。ニューラルネットワークの重みの不確実性。arXivプレプリントarXiv:1505.05424。 リンク
- Gal, Y.、Ghahramani, Z.(2016)。ドロップアウトはベイズの近似です:ディープラーニングにおけるモデルの不確実性の表現。国際会議機械学習(pp. 1050–1059)。 リンク
- Louizos, C.、Welling, M.、Kingma, D. P.(2017)。L0正則化を介した疎なニューラルネットワークの学習。arXivプレプリントarXiv:1712.01312。 リンク
- Neal, R. M.(2012)。ニューラルネットワークのベイズ学習(Vol. 118)。 Springer Science & Business Media. リンク
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 『私をすばやく中心に置いてください:主題拡散は、オープンドメインのパーソナライズされたテキストから画像生成を実現できるAIモデルです』
- 「マルチラベル分類:PythonのScikit-Learnを用いた入門」
- 「BeLFusionに出会ってください:潜在的拡散を用いた現実的かつ多様な確率的人間の動作予測のための行動的潜在空間アプローチ」
- 「40以上のクールなAIツールをチェックアウトしましょう(2023年8月)」
- 大規模画像モデルのための最新のCNNカーネル
- 「生成AI技術によって広まる気候情報の誤情報の脅威」
- 「CREATORと出会ってください:ドキュメントとコードの実現を通じて、LLMs自身が自分のツールを作成するための革新的なAIフレームワーク」






