「SDXL 1.0の登場」
Introduction of SDXL 1.0
SDXL 1.0の紹介:拡散モデルの理解

新しいモデルやテクノロジーがほぼ毎日私たちの情報源に押し寄せる、急速に進化する機械学習の世界では、最新情報を把握し、情報に基づいた選択をすることは困難な課題となります。今日は、SDXL 1.0に焦点を当て、テキストから画像を生成するモデルを詳しく調べてみましょう。このモデルは、この分野内でかなりの関心を集めています。
SDXL 1.0は、「Stable Diffusion XL」の略で、従来のモデルに比べてさまざまな有望な改良が施された、潜在的なテキストから画像への拡散モデルとして称賛されています。次の章では、これらの主張を詳しく検証し、新しい改良を見ていきます。
特に、SDXLはジェネレーティブモデルの領域における重要な懸念事項に対処するオープンソースモデルです。ブラックボックスモデルは最先端の技術として認識されていますが、そのアーキテクチャの透明性が、パフォーマンスの包括的な評価と検証を妨げ、広いコミュニティの参画を制限しています。
この記事では、この有望なモデルの詳細な探求に乗り出し、その機能、構成要素、以前の安定した拡散モデルとの興味深い比較を検討します。私の目標は、技術的な複雑さに深く踏み込まずに、明確な理解を提供し、読者にとって魅力的でアクセスしやすい内容にすることです。さあ、始めましょう!
- 「NeRFたちが望むヒーローではないが、NeRFたちに必要なヒーロー:CopyRNeRFは、NeRFの著作権を保護するAIアプローチです」
- 「50以上の最新AIツール(2023年8月)」
- 「作者の正体を暴く:AIか人間か?IBMの革新的なテキスト検出ツールを用いたAIフォレンジックスの出現を探る」
安定した拡散の理解:テキストから画像生成の魔法を解き明かす
「安定した拡散」の動作原理に自信がある場合、または技術的な部分には関与しない場合は、この章をスキップしても構いません。
2022年にリリースされ、最新の拡散技術の力を活用した画期的な深層学習テキストから画像生成モデルである「安定した拡散」は、AIの世界に衝撃を与えました。
この重要な進展は、AI画像生成における注目すべき進歩であり、より広範なユーザーに高性能なモデルへのアクセスを可能にする可能性があります。平易なテキストの記述を複雑な視覚的な出力に変換するという興味深い能力は、経験したことのある人々の注目を集めています。安定した拡散は、高品質の画像を生成する能力を発揮すると同時に、優れた速度と効率を示し、AI生成のアート作成の利便性を高めています。
安定した拡散のトレーニングには、LAION-5Bなどの大規模なパブリックデータセットが使用され、キャプション付きのさまざまな画像を活用して芸術的な能力を洗練させています。しかし、その進歩に貢献している重要な要素の一つは、コミュニティの積極的な参加であり、時間の経過とともにモデルの開発を促進し、能力を向上させるための貴重なフィードバックを提供しています。
どのように動作するのか?
まず、安定した拡散モデルの主要な構成要素と、これらのモデルを個別にトレーニングおよび予測する方法について説明します。
U-Netと拡散プロセスの本質:
コンピュータビジョンモデルを使用して画像を生成するために、分類、検出、セグメンテーションなどのラベル付けデータに頼る従来のアプローチを超えて進出します。安定した拡散の領域では、モデルが画像の複雑な詳細を自ら学習し、イノベーティブな「拡散」と呼ばれるアプローチで複雑な文脈を捉えることを目指しています。
拡散プロセスは2つの異なるフェーズで展開されます:
- 最初のパートでは、画像に制御された量のランダムノイズを導入します。このステップは「フォワード拡散」と呼ばれます。
- 次のパートでは、画像のノイズを除去し、元のコンテンツを再構築します。このプロセスは「リバース拡散」として知られています。

最初のパートでは、各時間ステップtで入力画像にガウスノイズを追加することは比較的簡単です。しかし、2番目のステージは直接的に元の画像を計算することができないため、課題が発生します。この障害を乗り越えるために、私たちはニューラルネットワークを使用し、それが巧妙なU-Netの登場する場所です。
強力なU-Netを活用して、モデルをトレーニングし、時刻tで与えられたランダムにノイズの乗った画像からノイズを予測し、予測されたノイズと実際のノイズの間の損失を計算します。十分な大きさのデータセットと複数のノイズステップにより、モデルはノイズパターンに関する教育された予測能力を獲得します。このトレーニングされたU-Netモデルは、与えられたノイズから画像の近似再構成を生成する際にも非常に貴重です。

基本的な確率とコンピュータビジョンモデルに精通していれば、このプロセスは比較的簡単です。ただし、注意すべき別の問題があります。ノイズ付きの画像を何百万もトレーニングし、再構築することは非常に時間がかかり、計算能力を消耗します。この課題に対処するため、研究者はよく知られたアーキテクチャであるオートエンコーダを再評価しました。すでにU-Netと同様のアプローチを利用しているため、転置畳み込みと残差ブロックの組み合わせも、条件付きテキストの入力を扱う際に重要な要素となります。
オートエンコーダを使用すると、データをより小さな「潜在」空間に「エンコード」し、元の空間に「デコード」することができます。実際、元のStable Diffusionの論文がLatent Diffusionと呼ばれているのはそれが理由です。これにより、大きな画像を効果的に低次元に圧縮することができます。
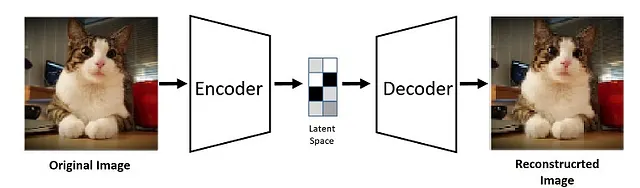
前方および逆方向の拡散操作は、より小さな潜在空間内で行われるため、メモリ要件が減少し、処理速度が大幅に向上します。
有名な「Stable Diffusion」アーキテクチャはほぼ完成です。最後の部分は条件付きテキストです。通常、この側面はテキストエンコーダを使用して実現されますが、ControlNetなどの画像を条件とする他の方法も存在しますが、この記事の範囲外です。テキストの条件付けは、Stable Diffusionモデルの真の魔法がある画像の生成において重要な役割を果たします。
これを実現するために、画像キャプションを使用したBERTやCLIPなどのテキスト埋め込みモデルをトレーニングし、トークン埋め込みベクトルを条件付けの入力として追加します。クロスアテンションメカニズム(クエリ、キー、値)を使用して、条件付けテキスト埋め込みをU-Net残留ブロックにマッピングすることで、トレーニングプロセス中に画像のキャプションと画像自体を効果的に組み合わせ、提供されたテキストに基づいて画像生成を条件付けることができます。
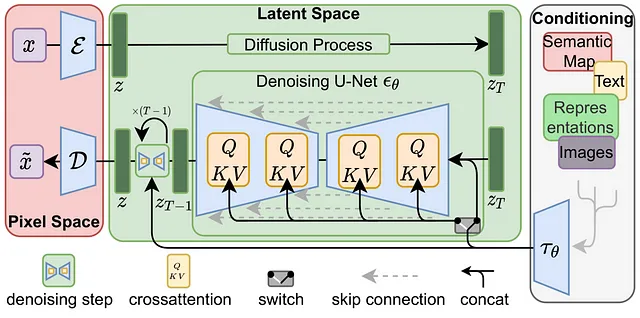
これで、Stable Diffusionモデルの構成要素についてすべて知っているので、この知識を武器に、以前のStable Diffusionモデルを比較し、その強みと制限をより具体的に評価することができます。
SDXLの新機能
SDモデルの基本を理解したので、SDXLの論文に掘り下げ、この新しいモデルで導入された変革的な変更を明らかにしましょう。要約すると、SDXLは以下の進化を提供します:
- U-Netパラメータの増加:SDXLは、より多くのU-Netパラメータを組み込むことにより、モデルの容量を向上させ、より洗練された画像生成を可能にします。
- Transformerブロックの異種分布:以前のモデル([1,1,1,1])の均一なTransformerブロックの分布から逸脱し、SDXLは異種分布([0,2,4])を採用し、最適化された学習能力を導入しました。
- 強化されたテキスト条件付けエンコーダ:SDXLは、より大きなテキスト条件付けエンコーダであるOpenCLIP ViT-bigGを活用し、テキスト情報を画像生成プロセスに効果的に組み込みます。
- 追加のテキストエンコーダ:モデルは、出力を連結する追加のテキストエンコーダであるCLIP ViT-Lを使用し、補完的なテキスト特徴を条件付けプロセスに組み込みます。
- 「サイズ条件付け」の導入:「サイズ条件付け」という新しい条件付け子は、元のトレーニング画像の幅と高さを条件付けの入力として受け取り、モデルがサイズ関連の手がかりに基づいて画像生成を適応させることを可能にします。
- 「クロップ条件付け」パラメータ:SDXLは、「クロップ条件付け」パラメータを導入し、画像のクロッピング座標を条件付けの入力として組み込みます。
- 「マルチアスペクト条件付け」パラメータ:条件付けのためのバケットサイズを組み込むことで、「マルチアスペクト条件付け」パラメータは、SDXLがさまざまなアスペクト比に対応することができるようにします。
- 専用のリファイナーモデル:SDXLは、高品質で高解像度のデータを扱うための第2のSDモデルを導入し、複雑なローカルの詳細を効果的に捉えます。
さて、これらの追加要素が以前の安定した拡散モデルと比較してどのように異なるか、より詳しく見てみましょう。
Stability.aiの公式比較:
まず、著者によって提示されたStability.aiの公式比較を見てみましょう。この比較は、SDXLとStable Diffusionの間のユーザーの好みに関する貴重なインサイトを提供しています。ただし、その結果には注意が必要です…
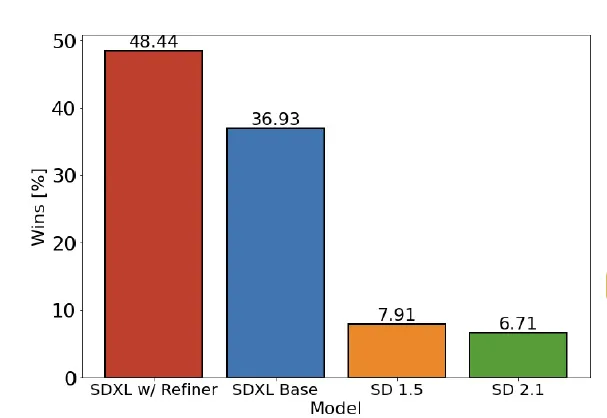
この研究では、参加者がSD 1.5および2.1の以前のモデルよりもSDXLモデルを選択したことが示されています。特に、リファイナーの追加を備えたSDXLモデルは、勝率48.44%を達成しました。この結果は統計的に有意であるという点を強調する必要がありますが、生成モデルの人間要素および固有のランダム性によって導入される固有のバイアスも考慮する必要があります。
最新のブラックボックスモデルとの性能比較:
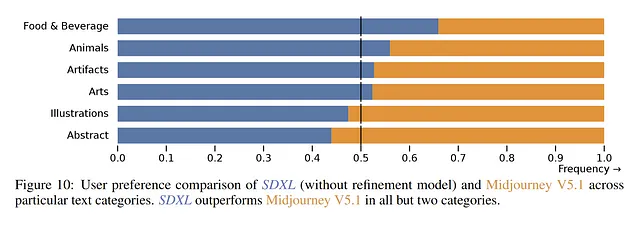
現在、Midjourneyはユーザーの間で非常に人気があり、一部の人々は現在の最先端のソリューションと見なしています。公式の調査によると、SDXLは「食品・飲料」と「動物」などのカテゴリでより高い優先度を示しています。しかし、「イラスト」と「抽象」などの他のカテゴリでは、ユーザーはまだMidjourney V5.1を好む傾向にあります。
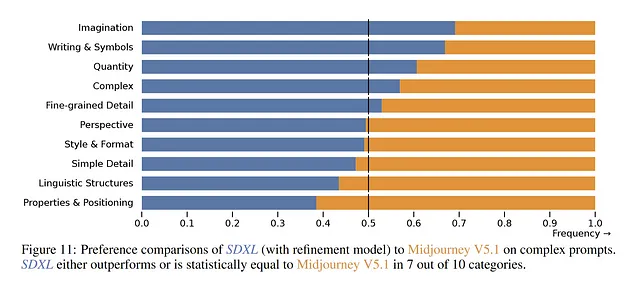
複雑なプロンプトの場合も同様の傾向が見られます。論文では、10件の複雑なテーマのうち7件でSDXLが優先されると主張しています。ただし、使用された具体的なプロンプトに関する情報がないため、結論を導くことは困難です。さらに、Midjourneyのプロンプトエンコーダに関する情報がないことも事態を複雑化させ、真の優先度は時間が経って初めて明らかになるでしょう。
U-Netパラメータの数
先に述べたように、U-NetモデルはStable Diffusionで画像の再構築を容易にするために重要な役割を果たしています。SDXLでは、SDの以前のバージョンと比較して、かなり大きなU-Netモデルが組み込まれています。先代に比べて2.6BのU-Netパラメータという合計で、860Mのパラメータに対してです。
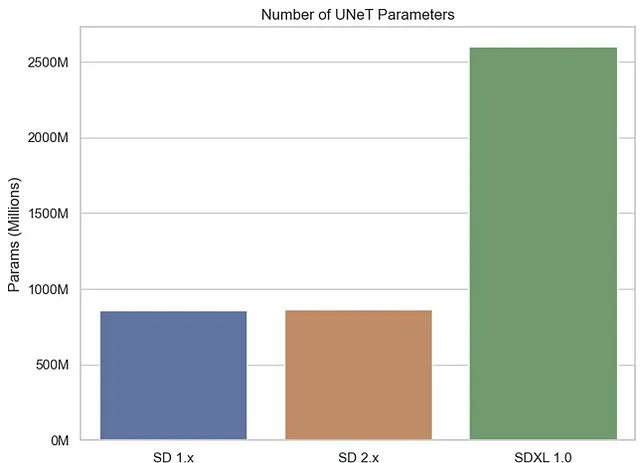
パラメータが多くある方が初めは有望に思えるかもしれませんが、複雑さと品質のトレードオフを考慮することが重要です。パラメータの数が増えるにつれて、トレーニングと生成の両方のシステム要件も増えます。製品の品質についてはまだ確定的な結論を出すには早すぎますが、複雑さと品質のトレードオフは既に明らかです。
テキストエンコーダパラメータの数
確かに、テキストエンコーダのパラメータ数の総数を見ると、SDXL 1.0は以前のバージョンと比較して著しく増加していることがわかります。SDXLでは、以前のバージョンの1つに比べて2つのテキストコンディショナが導入されており、これがテキストエンコーダのパラメータ数の大幅な増加の要因となっています。この拡張により、SDXLはより多くのテキスト情報を活用することができます。
SDXLは、694.7百万のパラメータを持つOpenCLIP G/14テキストエンコーダを使用しており、CLIP L/14の123.65百万パラメータと比較して、合計で8億を超えるパラメータがあります。これは以前のバージョンからの大幅な進歩を表しています。
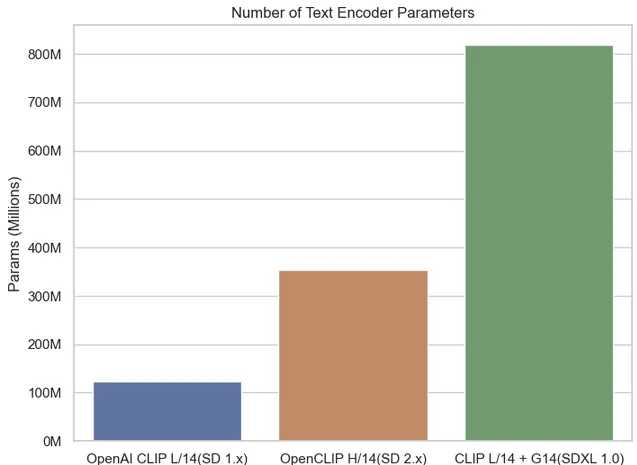
より大きなテキストエンコーダを複数使用することは最初は魅力的に見えるかもしれませんが、それによって追加の複雑さが導入され、逆効果となる可能性があります。自分自身のデータでSDXLモデルを微調整するシナリオを考えてみてください。このような場合、以前のSDモデルと比較して最適なパラメータを決定することは、両方のエンコーダのハイパーパラメータの「Sweet Spot」を見つけることがより難しいとなります。
ワークフロー
実際に、SDXLの「XL」という用語は、以前のSDモデルと比較して拡大スケールと増加した複雑性を示しています。SDXLはさまざまな側面で前任者を凌駕し、2つのテキストエンコーダと2つのU-Netモデル(基本モデルとリファイナー、つまり画像から画像へのモデル)を含む、より多くのパラメータを誇っています。自然に、このような高度な複雑性を持つSDXLパイプラインは以下のようなものです:
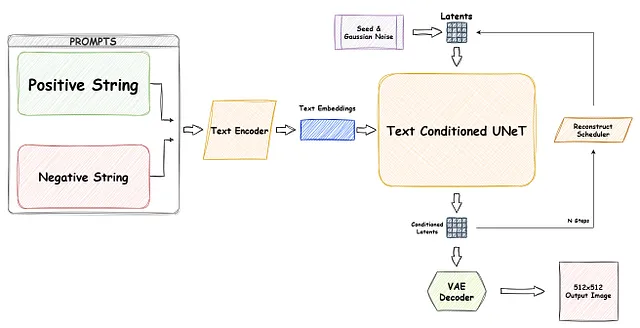
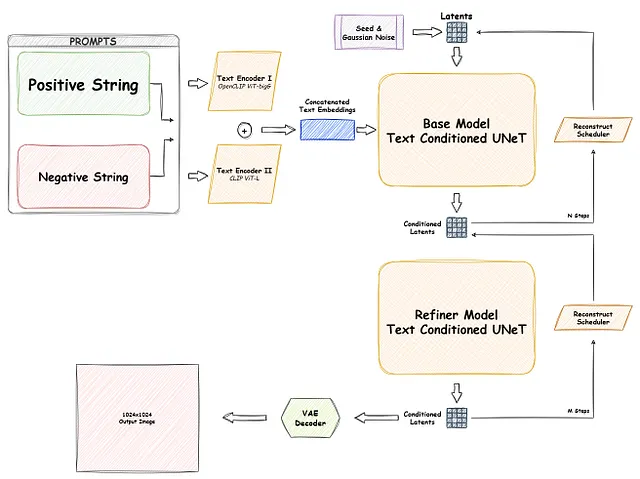
SDXLの実践
SDXLのモデルウェイトは公式にリリースされ、Hugging Faceのdiffusersライブラリを介してPythonスクリプトとして自由にアクセスできます。さらに、ComfyUIという使いやすいGUIオプションも利用可能です。このGUIは高度にカスタマイズ可能なノードベースのインターフェースを提供し、ユーザーは直感的にStable Diffusionモデルのビルディングブロックを配置し、視覚的に接続することができます。
このすぐに利用可能な実装により、ユーザーはSDXLをプロジェクトにシームレスに統合することができ、最先端の潜在的なテキストから画像への拡散モデルのパワーを活用することができます。
diffusersの基本的な使用例
SDXLの現状と個人の経験
SDXLの新機能と追加要素は有望に見えますが、微調整されたSD 1.5モデルの方がまだより良い結果を提供しています。この結果は、オープンソースのアプローチから生まれる繁栄するコミュニティからの強力なサポートに主に起因しています。
初期モデル段階では、SDXLは1.5よりも改善されており、継続的なコミュニティのサポートにより、将来的にはさらに強力なパフォーマンスを発揮すると確信しています。ただし、モデルがより複雑になるにつれて、それらを使用して微調整するためにはより多くのリソースが必要とされます。しかし、心配する必要はまだありません…
LoRA(Locally Rank-Adaptive Decompositions)は、大規模な言語モデルの微調整において人気があります。このアプローチでは、既存の重みにランク分解の重み行列のペアを追加し、追加された重みのみをトレーニングします。その結果、トレーニングはより速く、計算的に効率的になります。LoRAの組み込みは、将来的にはさらに優れたカスタムバージョンをコミュニティが作成する道を開くことが期待されています。特に、SDXLは既にLoRAを完全にサポートしています。
前向きな展開にもかかわらず、SDXLは公式に認められている通り、通常のStable Diffusionの短所に苦しんでいます:
- モデルは完璧な写真現実主義を実現していません
- モデルは読み取り可能なテキストをレンダリングできません
- モデルは、「赤いキューブが青い球の上にある」などの組成性を伴うより難しいタスクに苦戦しています
- 顔や人物全般を適切に生成できない場合があります
- モデルのオートエンコーディング部分は損失があります
個人的な観察結果
個人的には、SDXLモデルを試行錯誤している間に、特定の場合では以前のSD 1.5のコミュニティチェックポイントを好むことがあります。コミュニティのサポートが数ヶ月続いているため、写真現実主義やよりカートゥーン風のスタイルなど、特定のニーズに合う適切な微調整モデルを見つけることは比較的簡単です。ただし、高い計算能力要件のため、現在はSDXLの特定の微調整モデルを見つけることが難しいです。それでも、SDXLの基本モデルは画像の品質と解像度の面で、SD 1.5や2.1の基本モデルよりも優れた性能を発揮するように見えますし、さらなる最適化と時間が経過することで、これは近い将来に変わる可能性があります。
増加したモデルのサイズにより、一部のユーザーは自分の普段使っているノートパソコンやパソコンでモデルを実行する際に困難を報告しています。これは残念なことです。私は、大規模な言語モデルで一般的に使用される量子化技術が、この分野でも役立つ可能性があると期待しています。
また、テキストエンコーダの変更に伴い、私の通常のプロンプトではSDXLの満足できる結果が得られなくなりました。SDXLの開発者は、SDXLを使用したプロンプトが簡単になると主張していますが、私自身はまだ適切なアプローチを見つけることができていません。特に以前のバージョンから来た人々にとって、新しいプロンプトスタイルに慣れるのに時間がかかるかもしれません。
結論
本記事では、プレーンテキストの説明を複雑なビジュアル表現に変換する能力を持つStable Diffusion XL(SDXL)の能力を紹介しました。SDXLのオープンソース性とブラックボックスモデルに関連する懸念事項へのアプローチが、広範なユーザーに訴求していることがわかりました。
パラメータ数の増加と追加機能により、SDXLは従来のモデルと比較して複雑さが高まった「XL」モデルであることが証明されました。
SDXLの実装は、公式リリースにより容易になりました。モデルのウェイトはhuggingfaceからPythonスクリプトとして無料で入手でき、ユーザーフレンドリーなComfyUI GUIオプションも利用できます。
SDXLは非常に有望ですが、完璧を目指す旅はまだ途中です。洗練されたSD 1.5モデルは、活気あるコミュニティのサポートのおかげで、特定のシナリオでまだSDXLを上回る成果を上げています。しかし、積極的な関与とサポートにより、SDXLは時間の経過とともに進化し改善されることが予想されます。
それにもかかわらず、SDXLは従来のモデルと同様にいくつかの制約があることを認識することが重要です。完璧な写真のようなリアリズムの実現、読みやすいテキストのレンダリング、組成の課題の処理、顔や人物の正確な生成など、改善が必要な領域があります。
まとめると、SDXL 1.0はテキストから画像を生成する上で大きな進歩を表しており、AIの創造的な可能性を解き放ち、可能性の限界を押し広げています。AIコミュニティが協力し、イノベーションを続ける限り、SDモデルやそれ以上の魅力的な世界でさらなる驚異的な進展を見ることができるでしょう。
参考文献:
- Denoising Diffusion Probabilistic Models — Jonathan Ho, Ajay Jain, Pieter Abbeel, 2020
- High-Resolution Image Synthesis with Latent Diffusion Models — Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer, 2021
- SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis — Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, Robin Rombach, 2023
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






