Video-ControlNetを紹介します:コントロール可能なビデオ生成の未来を形作る革新的なテキストからビデオへの拡散モデル
Introducing Video-ControlNet An innovative model for spreading text to video that shapes the future of controllable video generation.


近年、テキストベースのビジュアルコンテンツ生成が急速に発展しています。大規模なイメージテキストペアでトレーニングされた現在のテキストから画像へ(T2I)の拡散モデルは、ユーザーが提供したテキストプロンプトに基づいて高品質な画像を生成する驚異的な能力を発揮しています。画像生成の成功は、ビデオ生成にも拡張されています。いくつかの方法は、T2Iモデルをワンショットまたはゼロショットの方法でビデオを生成するために利用していますが、これらのモデルから生成されたビデオはまだ一貫性がないか、バラエティに欠けています。ビデオデータをスケーリングアップすることで、テキストからビデオ(T2V)の拡散モデルを使用すると、生成されたコンテンツに制御がかかる一貫したビデオを作成できます。ただし、これらのモデルは、生成されたコンテンツの制御ができないビデオを生成します。
最近の研究では、深度マップを制御できるT2V拡散モデルが提案されています。ただし、一貫性と高品質を実現するには大規模なデータセットが必要で、リソースに優しくありません。また、T2V拡散モデルは、一貫性、任意の長さ、多様性を持つビデオを生成することはまだ難しいとされています。
これらの問題に対処するために、制御可能なT2VモデルであるVideo-ControlNetが導入されました。Video-ControlNetには、以下の利点があります。モーションプライオリティと制御マップを使用することで一貫性が向上し、最初のフレームの条件付け戦略を採用することで任意の長さのビデオを生成することができ、画像からビデオへの知識移行によるドメイン汎化、限られたバッチサイズを使用してより速い収束でリソース効率が向上します。
- グラフの復活:グラフの年ニュースレター2023年春
- PythonとRにおける機械学習アルゴリズムの比較
- 事前学習済みのViTモデルを使用した画像キャプショニングにおけるVision Transformer(ViT)
Video-ControlNetのアーキテクチャは、以下の通りです。
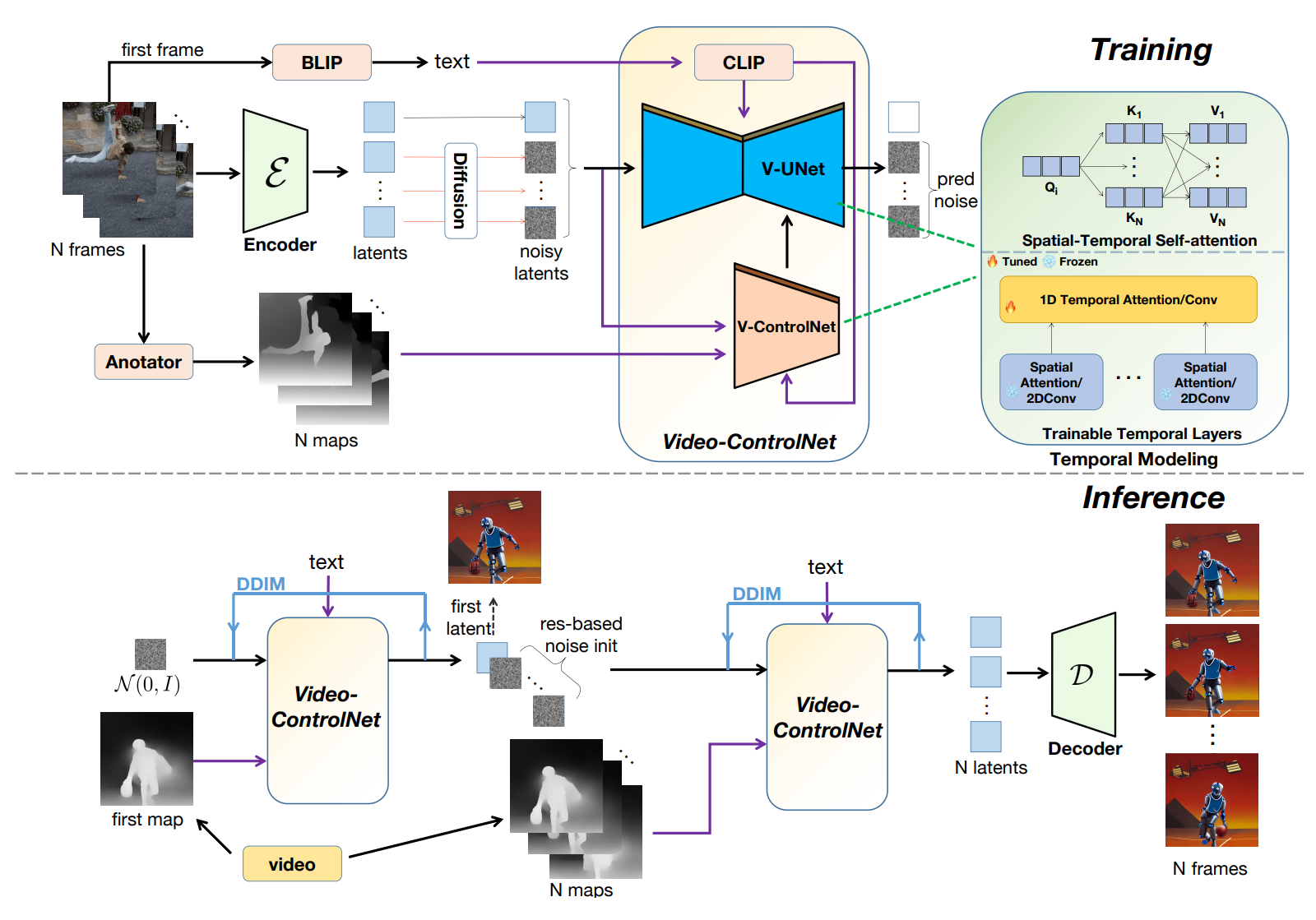

目的は、テキストと参照制御マップに基づいてビデオを生成することです。そのため、生成モデルは、事前にトレーニングされた制御可能なT2Iモデルを再編成し、追加のトレーニング可能な時間層を組み込み、フレーム間の細かい相互作用を促進する空間・時間自己注意メカニズムを提示することで開発されました。このアプローチにより、広範なトレーニングがなくても、コンテンツに一貫性のあるビデオを作成できます。
ビデオ構造の一貫性を確保するために、著者らは、ノイズ初期化段階でノイズ除去プロセスにソースビデオのモーションプライオリティを組み込む先駆的なアプローチを提案しています。モーションプライオリティと制御マップを活用することで、Video-ControlNetは、マルチステップのノイズ除去プロセスの性質による他のモーションベースの方法のエラー伝搬を避けながら、フリッカリングが少なく、入力ビデオのモーション変化に近くなるビデオを生成することができます。
さらに、以前の方法が直接ビデオ全体を生成するようにモデルをトレーニングするのに対して、この研究では、初期フレームに基づいてビデオを生成する革新的なトレーニングスキームが導入されています。このような簡単で効果的な戦略により、コンテンツと時間的学習を分離することがより簡単になります。前者は最初のフレームとテキストプロンプトで提示され、モデルは、後続フレームの生成方法のみを学習する必要があります。これにより、ビデオデータの需要が軽減され、画像領域から生成能力を継承することができます。推論中、最初のフレームは、最初のフレームの制御マップとテキストプロンプトによって条件付けられて生成されます。その後、最初のフレーム、テキスト、および後続の制御マップによって条件付けられた後続フレームが生成されます。また、このような戦略の別の利点は、モデルが前のイテレーションの最後のフレームを初期フレームとして扱い、無限に長いビデオを自動的に生成できることです。
これがどのように機能するかを説明し、著者によって報告された結果と最先端のアプローチとの比較を含む制限されたサンプル結果が以下の図に示されています。

これはVideo-ControlNetの概要であり、最新の品質と時間的一貫性を備えたT2V生成のための新しい拡散モデルです。もし興味があれば、以下のリンクでこの技術について詳しく学ぶことができます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- TensorFlowを使用して責任あるAIを構築する方法は?
- Microsoft AIは、バッチサイズや帯域幅の制限に阻まれることなく、効率的な大規模モデルのトレーニングにZeROを搭載した高度な通信最適化戦略を導入しています
- CoDiに会おう:任意対任意合成のための新しいクロスモーダル拡散モデル
- AIがYouTubeの多言語吹替を開始します
- vLLMについて HuggingFace Transformersの推論とサービングを加速化するオープンソースLLM推論ライブラリで、最大24倍高速化します
- がん検出の革命:サリー大学が機械学習における画像ベースのオブジェクト検出ツールを発表し、ゲームチェンジとなる
- あなたのポケットにアーティストの相棒:SnapFusionは、拡散モデルのパワーをモバイルデバイスにもたらすAIアプローチです






