「Retroformer」をご紹介します:プラグインの回顧モデルを学習することで、大規模な言語エージェントの反復的な改善を実現する優れたAIフレームワーク
Introducing Retroformer an excellent AI framework that achieves iterative improvements in large-scale language agents by learning from retrospective models of plugins.


大規模な言語モデル(LLM)を強化して、単にユーザーの質問に応答するのではなく、目標のために独立して活動できる自律的な言語エージェントにするという、力強い新しいトレンドが浮上しています。React、Toolformer、HuggingGPT、生成エージェント、WebGPT、AutoGPT、BabyAGI、Langchainなどは、LLMを利用して自律的な意思決定エージェントを開発する実用性を効果的に実証したよく知られた研究です。これらの手法は、LLMを使用してテキストベースの出力とアクションを生成し、それを使用して特定の文脈でAPIにアクセスし、活動を実行します。
ただし、現在の言語エージェントの大部分は、パラメータ数の多いLLMの範囲が非常に広いため、環境の報酬関数に最適化された行動を持っていません。ReflexionやSelf-Refine、Generative Agentなど、同様のアプローチを取る他の多くの作品とは異なり、比較的新しい言語エージェントアーキテクチャである反省アーキテクチャは、過去の失敗から学ぶために、口頭フィードバック、具体的には自己反省を利用してエージェントを支援します。これらの反射エージェントは、環境のバイナリまたはスカラーの報酬を音声入力としてテキストの要約に変換し、言語エージェントのプロンプトにさらなる文脈を提供します。
自己反省フィードバックは、エージェントに特定の改善領域を指示することで、エージェントにとって意味的な信号となります。これにより、エージェントは過去の失敗から学び、同じ間違いを繰り返さずに次回の試行でより良い結果を出すことができます。ただし、自己反省操作によって反復的な改善が可能になるものの、事前に訓練された凍結LLMから有用な反省フィードバックを生成することは困難です(図1参照)。これは、LLMが特定の環境でエージェントの誤りを特定し、改善の提案を含む要約を生成する能力が必要だからです。
- 「集団行動のデコード:アクティブなベイズ推論が動物グループの自然な移動を支える方法」
- このAI論文では、これらの課題に対処しながらMoEsの利点を維持するために、完全に微分可能な疎なTransformerであるSoft MoEを提案しています
- 「生成モデルを本番環境に展開する際の3つの課題」
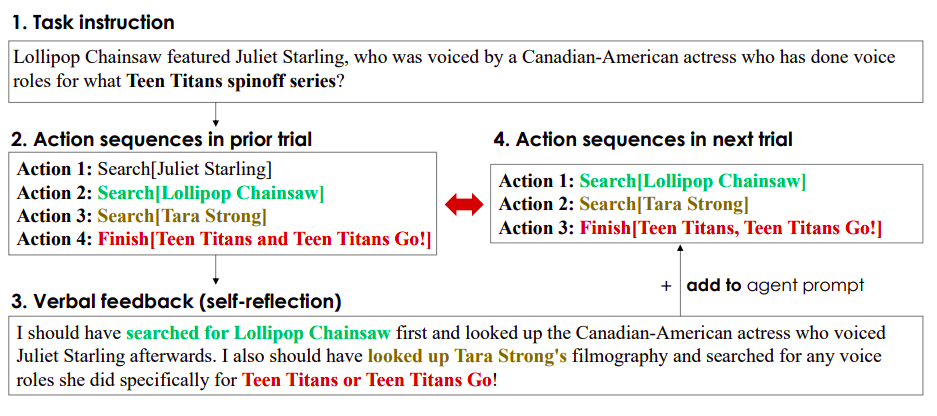
特定の状況でのタスクの信用割り当ての問題を専門にするために、凍結言語モデルを十分に調整する必要があります。また、現在の言語エージェントは、異なる可能な報酬に基づいて勾配ベースの学習からの思考や計画に一貫した方法で取り組んでいません。Salesforce Researchの研究者は、Retroformerというモラルフレームワークを紹介し、制約を解決するためのプラグインの後向きモデルを学習して言語エージェントを強化する方法を提案しています。Retroformerは、方策最適化を通じて環境からの入力に基づいて言語エージェントのプロンプトを自動的に改善します。
具体的には、提案されたエージェントアーキテクチャは、失敗した試行を反省し、将来の報酬に対してエージェントが実行したアクションにクレジットを割り当てることで、事前に訓練された言語モデルを反復的に改善します。これは、複数の環境とタスク全体にわたる任意の報酬情報から学習することによって行われます。HotPotQAなどのオープンソースのシミュレーションおよび実世界の設定(WikipediaのAPIに繰り返し問い合わせる必要があるWebエージェントのツール使用スキルを評価する)で実験を行います。HotPotQAは、検索ベースの質問応答タスクで構成されています。反省に対して、勾配を使用しない思考や計画を行わないRetroformerエージェントは、より速く学習し、より良い意思決定を行います。具体的には、Retroformerエージェントは、検索ベースの質問応答タスクのHotPotQAの成功率をわずか4回の試行で18%向上させ、多くの状態アクション空間を持つ環境でのツール使用における勾配ベースの計画と推論の価値を証明しています。
結論として、彼らが貢献した内容は次の通りです:
• この研究では、大規模言語エージェントへのコンテキスト入力に基づいて提示されるプロンプトを反復的に洗練することで、学習速度とタスク完了を向上させるRetroformerを開発しました。提案された手法は、Actor LLMのパラメータにアクセスせず、勾配を伝播する必要もないため、言語エージェントアーキテクチャ内のレトロスペクティブモデルの強化に焦点を当てています。
• 提案された手法により、さまざまなタスクと環境のためのさまざまな報酬信号からの学習が可能となります。Retroformerは、その汎用性のため、GPTやBardなどのクラウドベースのLLMに適応可能なプラグインモジュールです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「Javaプログラミングの未来:2023年に注目すべき5つのトレンド」
- 「人工知能(AI)とWeb3:どのように関連しているのか?」
- AWSは、大規模なゲーミング会社のために、Large Language Model (LLM) を使って有害なスピーチを分類するためのファインチューニングを行います
- AIの力による教育:パーソナライズされた成功のための学習の変革
- 一貫性のあるAIビデオエディターが登場しました:TokenFlowは、一貫性のあるビデオ編集のために拡散特徴を使用するAIモデルです
- 「メタに立ち向かい、開発者を強力にサポートするために、アリババがAIモデルをオープンソース化」
- 「CT2Hairに会ってください:ダウンストリームグラフィックスアプリケーションで使用するために適した高精細な3Dヘアモデルを完全自動で作成するフレームワーク」





