「NExT-GPT あらゆるモダリティに対応したマルチモーダル大規模言語モデル」の紹介
『次世代の GPT』あらゆるモダリティに対応したマルチモーダル大規模言語モデルの魅力』
近年、生成型AIの研究は私たちの働き方を変えるように進化してきました。コンテンツの開発、仕事の計画、答えを見つけることからアートワークの作成まで、すべてがGenerative AIによって可能になりました。しかし、各モデルは通常特定のユースケースに適しており、例えばテキストからテキストへのGPT、テキストから画像へのStable Diffusionなどがあります。
複数のタスクを実行できるモデルは、マルチモーダルモデルと呼ばれます。多くの最先端の研究では、マルチモーダルなアプローチが多くの場面で有用であることが証明されています。その中でも特に注目すべき研究の一つが、NExT-GPTです。
NExT-GPTは、どんなものでもどんなものに変えることのできるマルチモーダルモデルです。では、どのように動作するのでしょうか。さらに探求してみましょう。
- 「ChatGPTのような大規模言語モデルによる自己説明は感情分析にどれほど効果的か?パフォーマンス、コスト、解釈可能性に迫る深い探求」
- ニューラルネットワークにおける系統的組み合わせ可能性の解除:組み合わせ可能性のためのメタラーニング(MLC)アプローチによるブレイクスルー
- 「ULTRAに会おう:あらゆるグラフで機能する事前学習済みの知識グラフ推論用基礎モデルで、50以上のグラフで教師あり最先端モデルを上回るパフォーマンスを発揮します」
NExT-GPT イントロダクション
NExT-GPTは、テキスト、画像、ビデオ、音声の4つの異なる種類の入力と出力を処理できる任意のマルチモーダルLLMです。この研究は、シンガポール国立大学のNExT++ 研究グループによって開始されました。
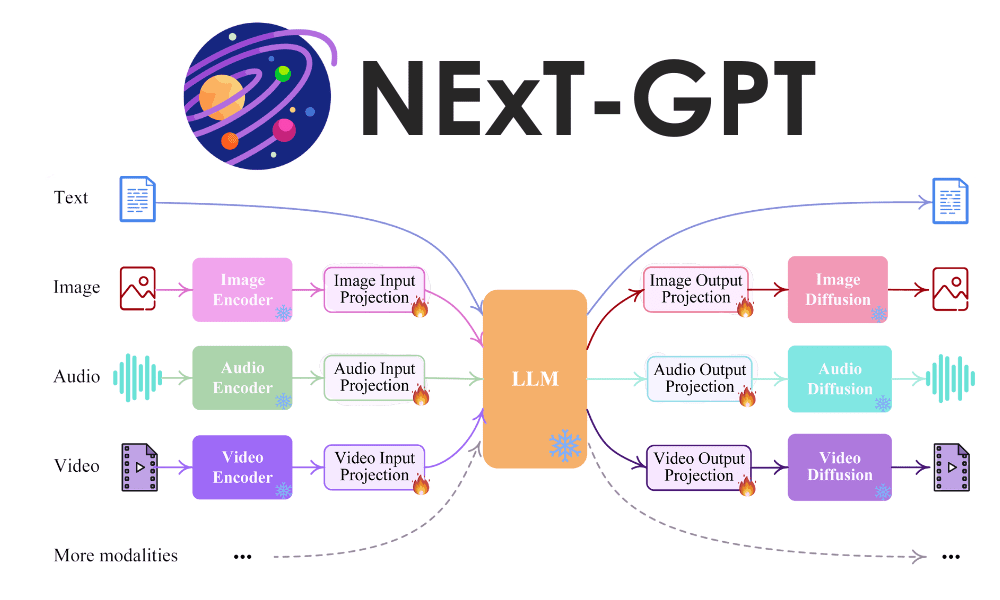
NExT-GPTモデルの全体像は、次の画像に示されています。
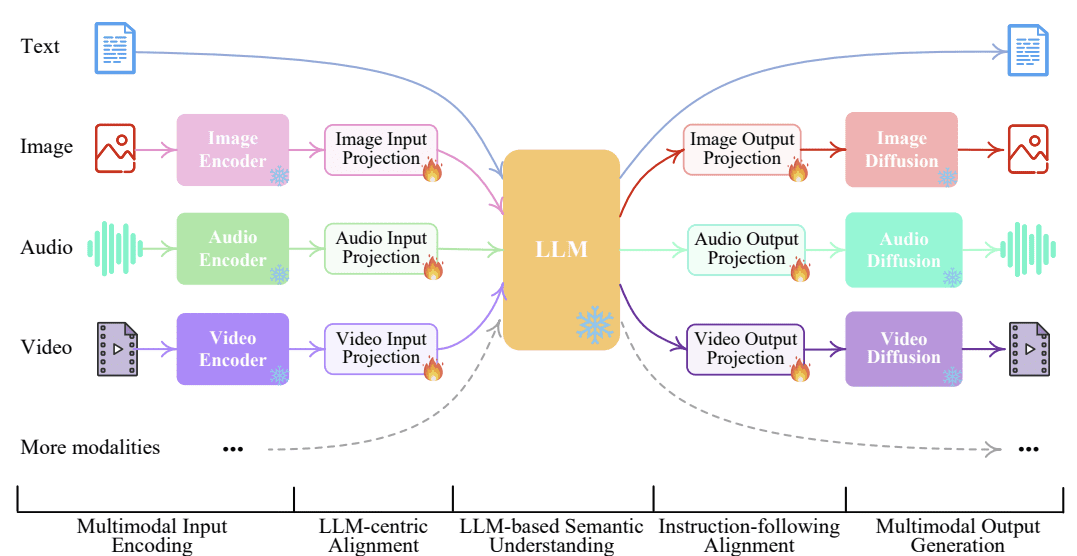
NExT-GPTモデルは、次の3つのパートで構成されています:
- さまざまなモダリティの入力のためのエンコーダを確立し、LLMが受け入れられるようにそれらを言語のような入力に変換すること
- セマンティック理解と追加のユニークなモダリティの信号を使用して、オープンソースのLLMをコアとして入力を処理すること
- マルチモーダルな信号を異なるエンコーダに提供し、適切なモダリティに対して結果を生成すること
NExT-GPTの推論プロセスの例は、次の画像で見ることができます。
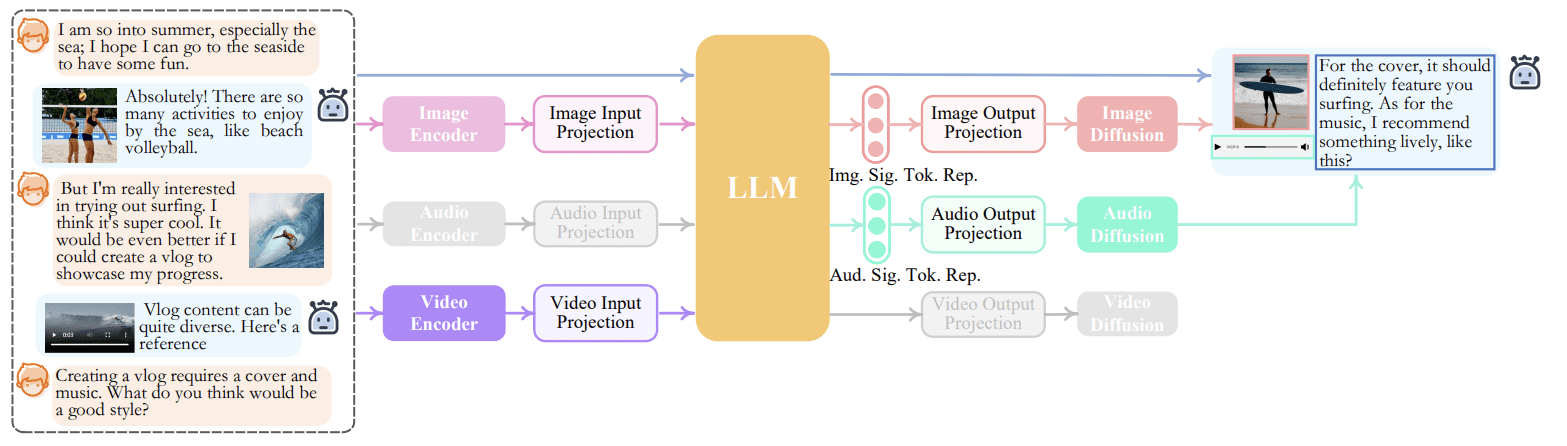
上記の画像で、私たちが望むタスクに応じて、エンコーダとデコーダが適切なモダリティに切り替わることが分かります。このプロセスは、NExT-GPTがユーザーの意図に合わせるためのモダリティ切り替え指示調整という概念を利用してのみ可能です。
研究者たちはさまざまなモダリティの組み合わせで実験を行いました。全体的には、NExT-GPTのパフォーマンスは以下のグラフにまとめられます。
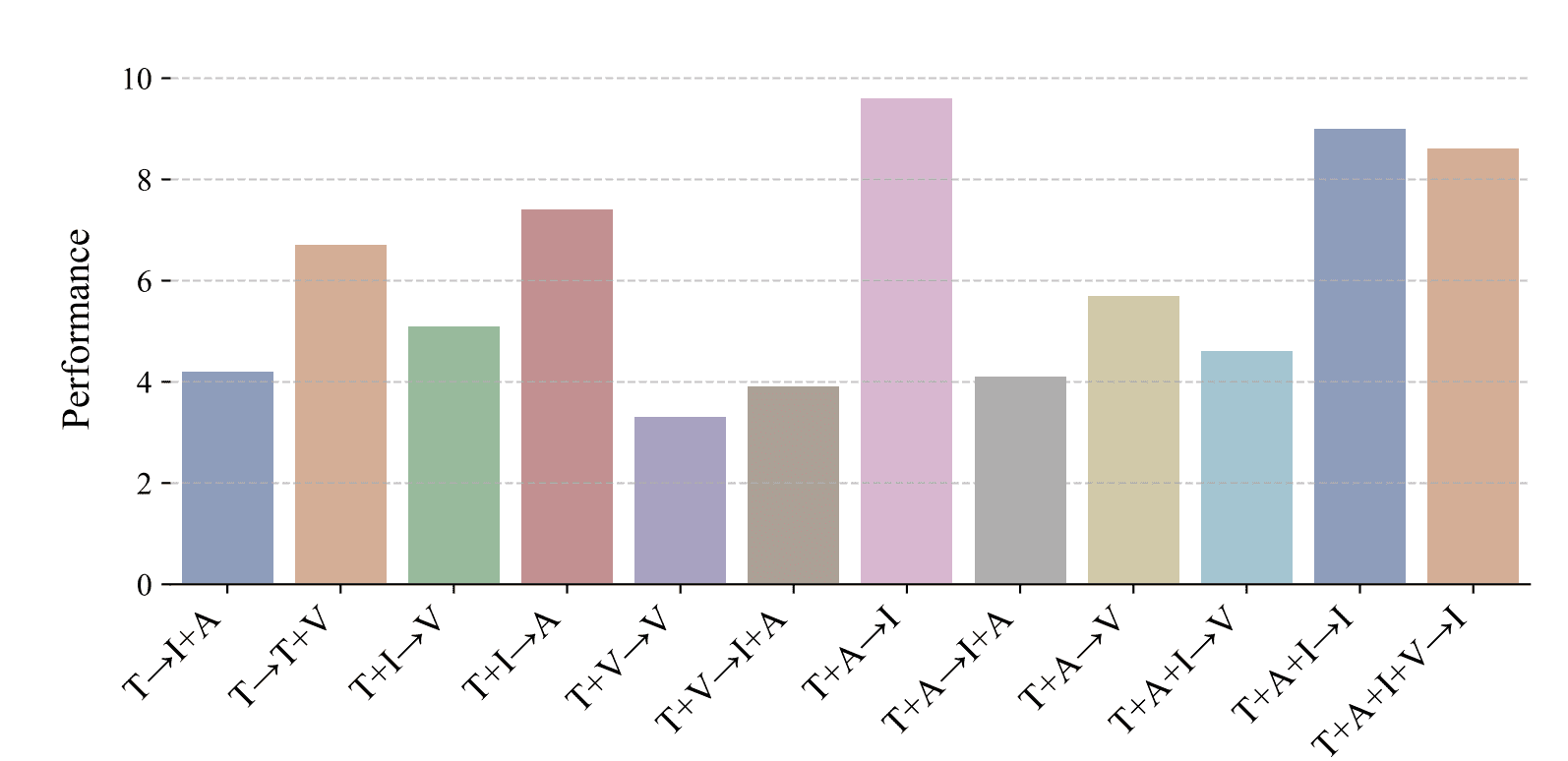
NExT-GPTの最も優れたパフォーマンスは、テキストと音声の入力から画像を生成することであり、次に、テキスト、音声、画像の入力から画像の結果を生成することです。最も低いパフォーマンスは、テキストとビデオの入力からビデオの出力を生成することです。
NExT-GPTの能力の一例が次の画像に示されています。
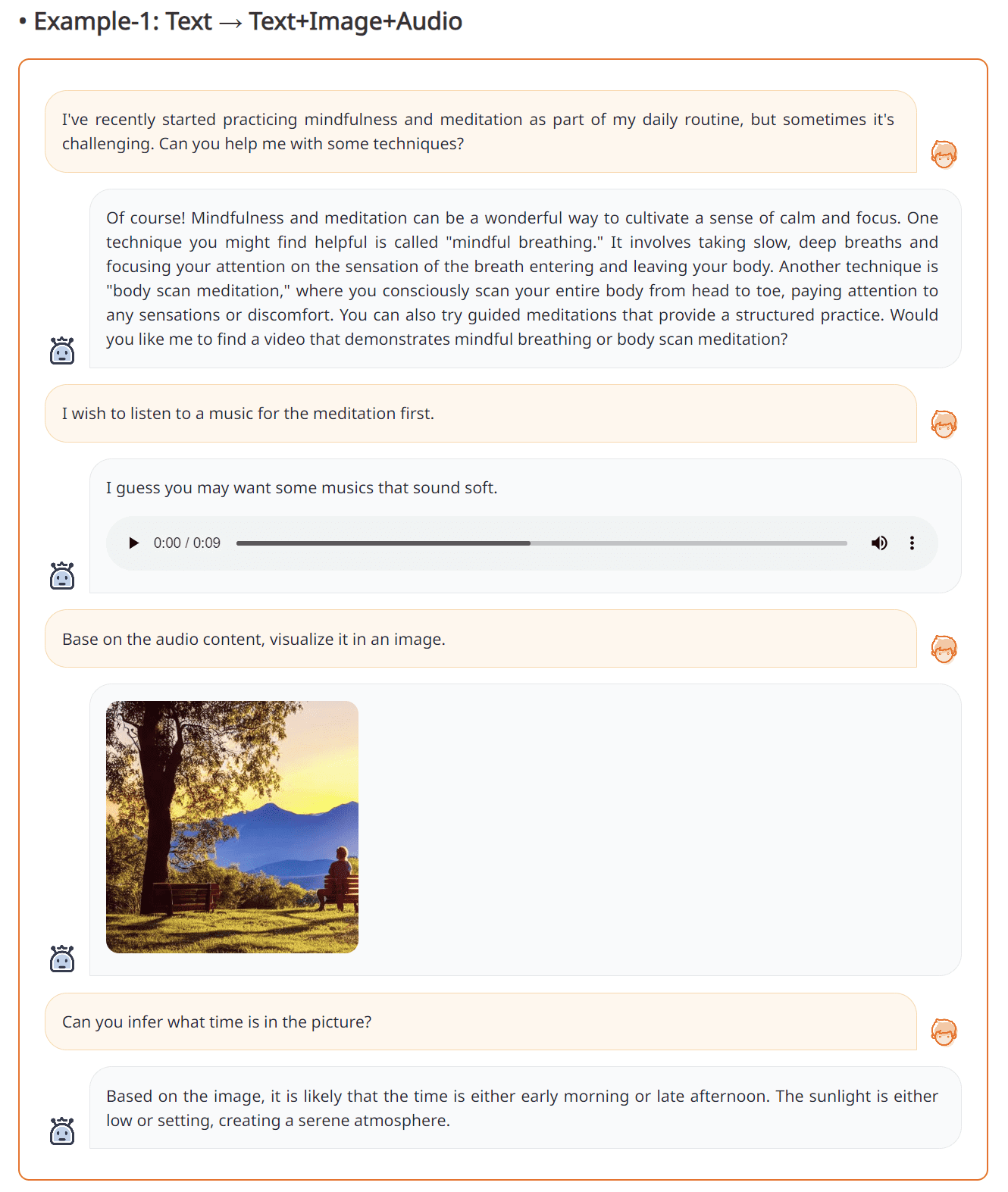
上の結果から分かるように、NExT-GPTとの対話によって、ユーザーの意図に合った音声、テキスト、画像を生成することができます。NExT-GPTは非常に優れたパフォーマンスを発揮し、かなり信頼性があります。
NExT-GPTの別の例が次の画像に示されています。
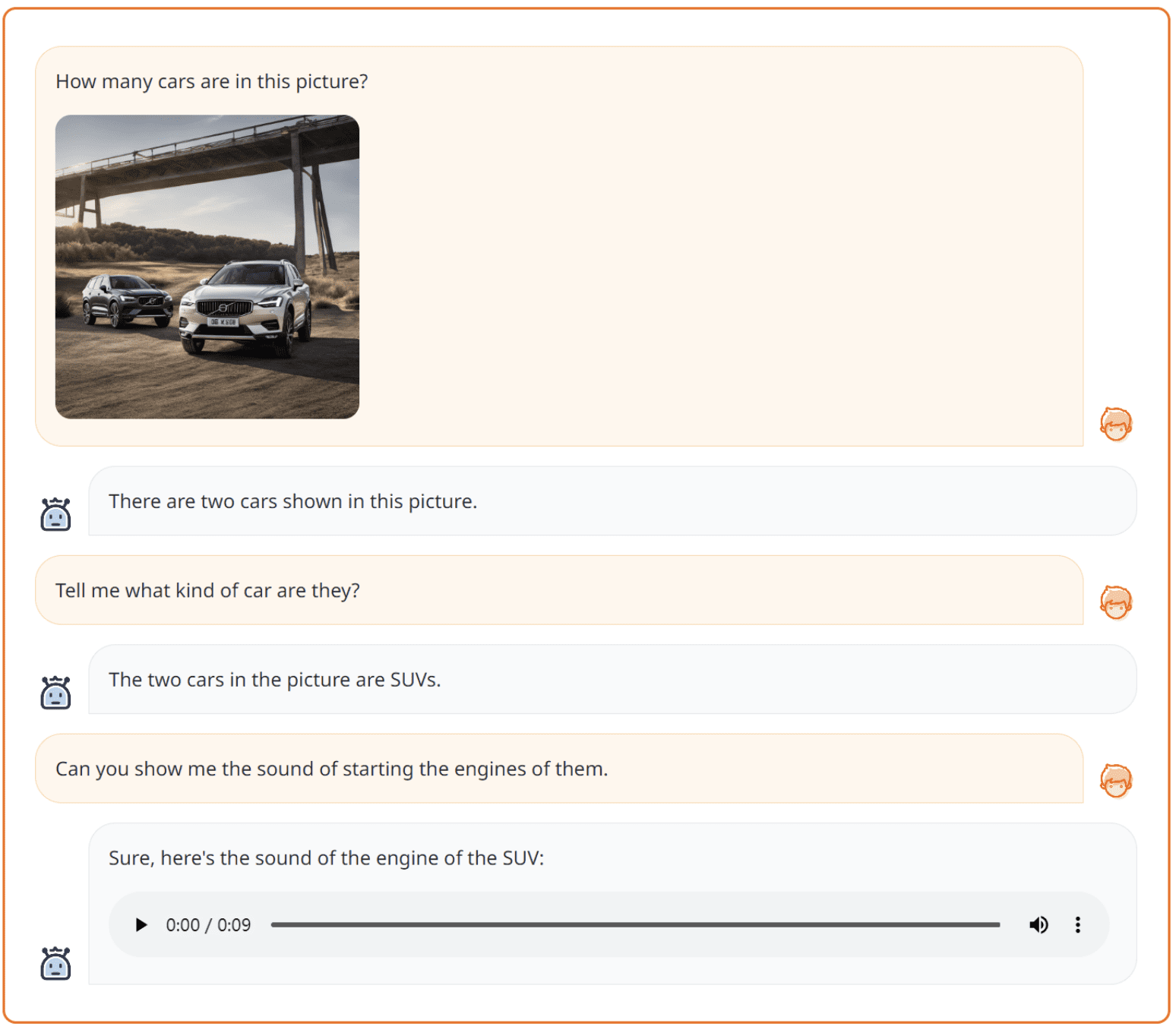
上の画像から、NExT-GPTは2種類のモダリティを処理してテキストと音声の出力を生成することができることがわかります。このモデルの柔軟性が十分に示されています。
モデルを試してみたい場合は、彼らのGitHubページからモデルと環境を設定することができます。また、次のページでデモを試すこともできます。
結論
NExT-GPTは、テキスト、画像、音声、ビデオの入力データを受け取り、それに基づいて出力を生成するマルチモーダルモデルです。このモデルは、モダリティごとに特定のエンコーダを利用し、ユーザーの意図に応じて適切なモダリティに切り替えることで動作します。パフォーマンス実験の結果は良好で、多くのアプリケーションで利用できる有望な取り組みとなっています。
[Cornellius Yudha Wijaya](https://www.linkedin.com/in/cornellius-yudha-wijaya/)は、データサイエンスアシスタントマネージャーであり、データライターです。彼はAllianz Indonesiaでフルタイムで働きながら、ソーシャルメディアや執筆を通じてPythonとデータのヒントを共有することが大好きです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「Amazon Bedrockへのプライベートアクセスを設定するために、AWS PrivateLinkを使用してください」
- 「Amazon SageMaker JumpStartを使用して、2行のコードでファウンデーションモデルを展開して微調整する」
- Pythonでの機械学習のためのテキストの前処理−自然言語処理
- 「Xenovaのテキスト読み上げクライアントツール:自然な音声合成を実現する頑強で柔軟なAIプラットフォーム」
- 「機械学習手法を用いたJava静的解析ツールレポートのトリアージに関する研究」
- 「Inside LlaVA GPT-4Vのオープンソースの最初の代替案」
- 「50以上の最新の最先端人工知能(AI)ツール(2023年11月)」






