「IDEFICSをご紹介します:最新の視覚言語モデルのオープンな再現」
Introducing IDEFICS Open Reproduction of the Latest Visual Language Model
私たちは、IDEFICS(Image-aware Decoder Enhanced à la Flamingo with Interleaved Cross-attentionS)をリリースすることを喜んでいます。IDEFICSは、Flamingoに基づいたオープンアクセスのビジュアル言語モデルです。FlamingoはDeepMindによって開発された最先端のビジュアル言語モデルであり、公開されていません。GPT-4と同様に、このモデルは画像とテキストの任意のシーケンスを受け入れ、テキストの出力を生成します。IDEFICSは、公開されているデータとモデル(LLaMA v1およびOpenCLIP)のみを使用して構築されており、ベースバージョンと指示付きバージョンの2つのバリアントが9,000,000,000および80,000,000,000のパラメーターサイズで利用可能です。
最先端のAIモデルの開発はより透明性を持つべきです。IDEFICSの目標は、Flamingoのような大規模な専有モデルの能力に匹敵するシステムを再現し、AIコミュニティに提供することです。そのために、これらのAIシステムに透明性をもたらすために重要なステップを踏みました。公開されているデータのみを使用し、トレーニングデータセットを探索するためのツールを提供し、このようなアーティファクトの構築における技術的な教訓とミスを共有し、リリース前に敵対的なプロンプトを使用してモデルの有害性を評価しました。IDEFICSは、マルチモーダルAIシステムのよりオープンな研究のための堅固な基盤として機能することを期待しています。また、9,000,000,000のパラメータースケールでのFlamingoの別のオープン再現であるOpenFlamingoなどのモデルと並んでいます。
デモとモデルをハブで試してみてください!
- あなたのCopy-Paste ChatGPTカスタムの指示は、こちらです
- NVIDIAが新しいDLSS 3.5を使用して、ゲームやアプリのためのAI強化リアルタイムレイトレーシングを発表しました
- この秋登場予定:NVIDIA DLSS 3.5 が Chaos Vantage、D5 Render、Omniverse、そして人気のあるゲームタイトルに対応します
IDEFICSとは何ですか?
IDEFICSは、80,000,000,000のパラメーターを持つマルチモーダルモデルであり、画像とテキストのシーケンスを入力とし、一貫したテキストを出力します。画像に関する質問に答えることができ、視覚的なコンテンツを説明し、複数の画像に基づいて物語を作成することができます。
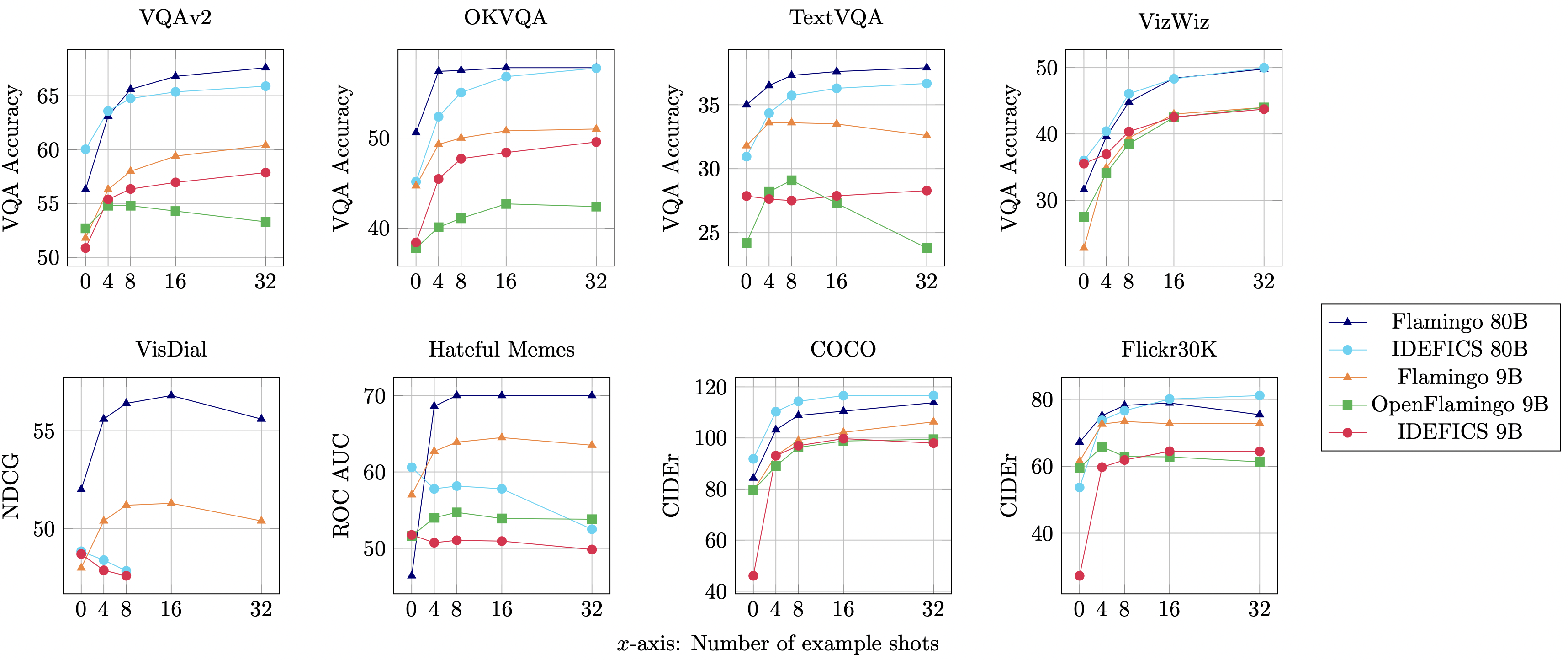
IDEFICSは、Flamingoのオープンアクセス再現であり、さまざまな画像テキスト理解ベンチマークで元のクローズドソースモデルと同等のパフォーマンスを発揮します。80,000,000,000および9,000,000,000のパラメーターの2つのバリアントがあります。
会話型の使用事例に適した、idefics-80B-instructとidefics-9B-instructのファインチューニングバージョンも提供しています。
トレーニングデータ
IDEFICSは、Wikipedia、Public Multimodal Dataset、LAION、および新しい115BトークンのデータセットであるOBELICSのオープンデータセットの混合物でトレーニングされました。OBELICSは、ウェブからスクレイプされた141,000,000の交互に配置された画像テキストドキュメントで構成され、353,000,000の画像を含んでいます。
OBELICSの内容をNomic AIで探索できるインタラクティブな可視化も提供しています。

IDEFICSのアーキテクチャ、トレーニング方法論、評価、およびデータセットに関する詳細は、モデルカードと研究論文で入手できます。さらに、モデルのトレーニングから得られた技術的な洞察と学びを文書化しており、IDEFICSの開発に関する貴重な見解を提供しています。
倫理的評価
このプロジェクトの開始時に、一連の議論を通じて、プロジェクト中に行われる決定を導くための倫理的な憲章を策定しました。この憲章では、自己批判、透明性、公平性などの価値観を掲げ、プロジェクトとモデルのリリースにおいて追求しました。
リリースプロセスの一環として、私たちは、モデルが望ましくない応答を引き起こす可能性のある画像とテキストを使用してモデルを敵対的にプロンプトすることにより、モデルの潜在的なバイアスを内部で評価しました(これはレッドチーミングとして知られるプロセスです)。
デモでIDEFICSを試してみてください。対応するモデルカードとデータセットカードをチェックし、コミュニティタブを使用してフィードバックをお知らせください。私たちは、これらのモデルを改善し、大規模なマルチモーダルAIモデルを機械学習コミュニティにアクセス可能にすることに取り組んでいます。
ライセンス
このモデルは、2つの事前トレーニングされたモデル(laion/CLIP-ViT-H-14-laion2B-s32B-b79Kおよびhuggyllama/llama-65b)を使用して構築されています。最初のモデルはMITライセンスの下でリリースされ、2番目のモデルは研究目的に焦点を当てた特定の非商用ライセンスの下でリリースされました。したがって、ユーザーはそのライセンスに従い、Metaのフォームに直接申し込むことによってそのライセンスを遵守する必要があります。
2つの事前学習モデルは、新しく初期化されたパラメータで互いに接続されます。これらは、合成モデルを形成する2つのベースの凍結モデルに基づいていません。私たちはMITライセンスの下でトレーニングした追加の重みを公開します。
IDEFICSのはじめ方
IDEFICSモデルはHugging Face Hubで利用可能であり、最新のtransformersバージョンでサポートされています。以下は試すためのコードサンプルです。
import torch
from transformers import IdeficsForVisionText2Text, AutoProcessor
device = "cuda" if torch.cuda.is_available() else "cpu"
checkpoint = "HuggingFaceM4/idefics-9b-instruct"
model = IdeficsForVisionText2Text.from_pretrained(checkpoint, torch_dtype=torch.bfloat16).to(device)
processor = AutoProcessor.from_pretrained(checkpoint)
# モデルには、テキスト文字列と画像の任意のシーケンスを供給します。画像はURLまたはPILイメージのいずれかであることができます。
prompts = [
[
"User: この画像には何が写っていますか?",
"https://upload.wikimedia.org/wikipedia/commons/8/86/Id%C3%A9fix.JPG",
"<end_of_utterance>",
"\nAssistant: この写真はアステリックスとオベリックスのイデフィックスという犬を描いています。イデフィックスは地面を走っています。<end_of_utterance>",
"\nUser:",
"https://static.wikia.nocookie.net/asterix/images/2/25/R22b.gif/revision/latest?cb=20110815073052",
"それは誰ですか?<end_of_utterance>",
"\nAssistant:",
],
]
# --バッチモード
inputs = processor(prompts, add_end_of_utterance_token=False, return_tensors="pt").to(device)
# --シングルサンプルモード
# inputs = processor(prompts[0], return_tensors="pt").to(device)
# 生成の引数
exit_condition = processor.tokenizer("<end_of_utterance>", add_special_tokens=False).input_ids
bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
generated_ids = model.generate(**inputs, eos_token_id=exit_condition, bad_words_ids=bad_words_ids, max_length=100)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
for i, t in enumerate(generated_text):
print(f"{i}:\n{t}\n")We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






