『冬-8Bに出会ってください:冴えたプラットフォームの背後にある非常にユニークなファンデーションモデル』
『冬-8Bを見逃すな:鮮やかなプラットフォームの背後にある特別なファンデーションモデル』
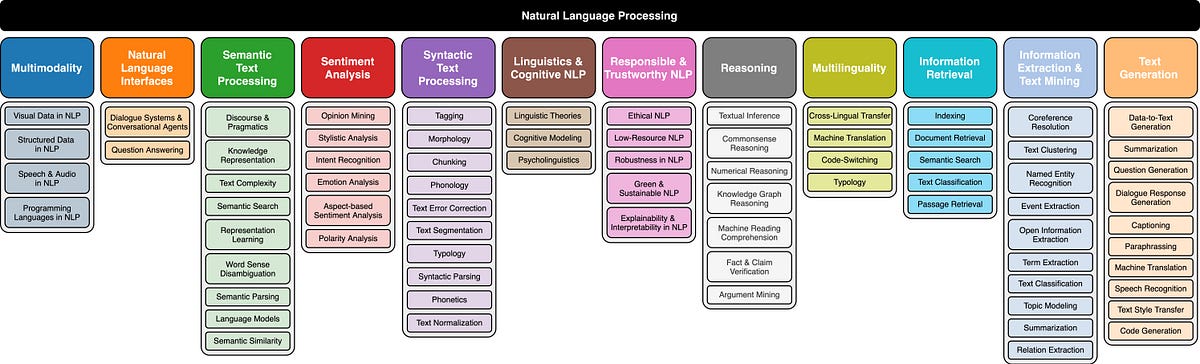
モデルはエージェントベースのタスクに最適化されており、言語とコンピュータビジョンに対して独自の能力を発揮します。
最近、AIに特化した教育ニュースレターを始めました。すでに16万人以上の購読者がいます。TheSequenceは、5分で読めるML志向のニュースレターで、ハラタケニュースや無縁であることを意味します。機械学習のプロジェクト、研究論文、概念について最新の情報を提供することを目指しています。以下の購読ボタンをクリックして試してみてください:
TheSequence | Jesus Rodriguez | Substack
機械学習、人工知能、データの進歩について最新情報を得るための最良の情報源です…
thesequence.substack.com
Adept.aiは新しく生まれたAIユニコーンの一部です。象徴的なトランスフォーマーペーパーの著者の一部によって最初に育てられ、Adeptは自律型AIエージェントの領域で活動しています。Adeptはこれまでに4億1500万ドル以上を調達し、時価総額は10億ドルを超えています。このプラットフォームは、高レベルの目標を理解し、コンピュータビジョンと言語を主に頼りにしてそれらをアクションに変換するエージェントの構築に取り組んでいます。今までAdeptのモデルについてはほとんどわかっていませんでしたが、Adeptは自社のプラットフォームを駆動するモデルの縮小版であるFuyu-8Bをオープンソース化しました。
Adeptは、知識労働者のためのスマートなコンパニオン、幅広い知識を持つデジタル共同者を作ることを目指しています。この目標を達成するために、Adeptはユーザーの文脈を把握し、彼らの代わりにアクションを実行することに重点を置いています。この取り組みの重要な部分は、画像の理解力です。知識労働の世界では、ユーザーはコンパニオンが画面に表示されるものに簡単にアクセスできることを期待しています。多くの場合、チャート、スライド、またはPDFなどのイメージを通じて重要な情報が伝えられます。さらに、アクションの実行には、ボタンやメニューなどの画面上の要素とのやり取りが必要なこともあります。これらのタスクをすべてAPIを介して実行できれば理想的ですが、多くのビジネス向けソフトウェアには包括的なAPIが欠けているため、ユーザーを引き付けるためにこれらのアプリケーションをグラフィカルユーザインタフェース(UI)を介して操作する必要があります。
- 「Mini-DALLE3と出会おう:大規模な言語モデルによるテキストから画像へのインタラクティブアプローチ」
- 『Talent.com』において
- PyTorchEdgeはExecuTorchを発表しました:モバイルおよびエッジデバイス向けのオンデバイスでの推論をエンパワーメント
Fuyu-8Bは新世代のマルチモーダルモデルの中でユニークな特徴を持っています:
1. 標準のアーキテクチャよりも小さく、シンプルです。
2. エージェントパラダイムに適した設計です。
3. 速いです。
4. 標準ベンチマークを超えながら、エージェント固有のタスクで大きなモデルとマッチさせることができます。
アーキテクチャ
最新世代のファウンデーションモデルでは、マルチモーダルモデルは共通の構造を持っています。一般的に、独自の画像エンコーダを備えたモデルは、既存の大規模言語モデル(LLM)にクロスアテンションメカニズムやアダプターを介して統合されます。PALM-e、PALI-X、QWEN-VL、LLaVA 1.5、Flamingoなど、これらのモデルはこのパラダイムに従っています。これらのモデルは通常、固定の画像解像度で動作します。推論時には、この解像度を超える画像は縮小する必要がありますし、アスペクト比が異なる画像にはパディングや歪みが必要です。
トレーニング面では、多くの他のマルチモーダルモデルは多段階のトレーニングプロセスを経ます。画像エンコーダはLLMとは別にトレーニングされ、対照的なトレーニング目標を使用することが一般的ですが、これは実装と管理が複雑なものになる場合があります。様々なコンポーネントの重みをいつ固定するかに関して判断を下す必要があります。一部のモデルでは、高解像度の画像を適切に処理するための追加の高解像度画像フェーズを含める場合さえあります。
これらのモデルをスケーリングする際には、各コンポーネントをどのように比例的にスケールするかを決定することが課題となります。エンコーダとデコーダに追加のパラメータをどのように割り当てるか、トレーニング中に計算リソースをどこに割り当てるかについて疑問が生じます。しかし、Adeptはこれらの複雑さを回避したモデルを提供しています。
アーキテクチャ的には、Fuyuはシンプルなデコーダ専用トランスフォーマーであり、Persimmon-8Bと同じ仕様ですが、専用の画像エンコーダはありません。画像パッチは直接トランスフォーマーの最初のレイヤーに射影され、埋め込みルックアップをバイパスします。このアプローチは、従来のトランスフォーマーデコーダをイメージトランスフォーマーとして扱いますが、プーリングはなく因果関係のあるアテンションもありません。詳細については、添付の図を参照してください。

この単純化は、さまざまな解像度の画像を簡単に処理する柔軟性を提供します。これを実現するために、画像トークンはテキストのトークンと同様に扱われます。画像固有の位置埋め込みが削除され、画像トークンはラスタスキャン順でモデルに供給され、改行を示す特別な画像改行文字があります。モデルは既存の位置埋め込みを活用して、異なる画像サイズに適応することができます。トレーニング中には、任意のサイズの画像を使用することができ、高解像度と低解像度の別々のトレーニング段階が不要になります。
機能
マルチモーダル基盤モデルで期待される標準的な機能に加えて、Fuyu-8Bは興味深い一連のユニークな機能を備えています:
画像内のQA
Fuyuは、以下のように示されるような複雑な質問に取り組む能力を備えています:

チャートの理解
下記のような複雑な視覚データに直面した場合、Fuyuは複雑な関係を識別し、さまざまな要素の間の関連を追跡し、洞察に富んだ回答を提供することに優れています:

ドキュメントの習熟度
Fuyuの能力は、複雑なインフォグラフィックや古いPDFを含むさまざまなドキュメントを解読することにも及んでいます:

図解の解釈
このモデルの専門知識は、複雑な科学的な図表の解読にも及び、細かい関連クエリに対処することができます:

OCRの熟練度
これらのスキルに加えて、Adeptは内部モデルを磨いて、ユーザーインターフェース(UI)の画像が与えられた場合に以下の2つの重要なタスクで優れた成績を収めています:
・bbox_to_text:バウンディングボックスが与えられると、Adeptはそのバウンディングボックスに含まれるテキストを正確に識別できます。
・text_to_bbox:逆に、テキストが与えられると、Adeptは指定されたテキストを囲むバウンディングボックスを巧みに返すことができます。

Fuyu-8Bは、オープンソースの基盤モデルで最も興味深い最近のリリースの一つです。そのアーキテクチャのシンプルさとユニークな機能セットは、この分野で追跡する価値のあるモデルの一つです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 『BOSSと出会ってください:新しい環境で新しい課題を解決するためにエージェントをトレーニングする強化学習(RL)フレームワーク、LLMガイダンス』
- 「ニューラルネットワークにおける記憶の解読イメージ分類のベンチマークにおけるモデルサイズ、記憶、および一般化への深い探求」
- 「ロボット義足の足首は、自然な運動と安定性を向上させる」
- ミニGPT-5:生成的なヴォケンによる交錯したビジョンと言語の生成
- 言語の愛好家であるなら、ChatGPTの多言語対応機能について知っておく必要があります
- 思考のグラフ:大規模言語モデルにおける緻密な問題解決のための新たなパラダイム
- ロボット学習の革命:NVIDIAのユーレカが複雑なタスクをこなす