データ測定ツールのご紹介:データセットを見るためのインタラクティブツール
Introducing a data measurement tool an interactive tool to view datasets.
要約:データセットを構築し、測定し、比較するためのオンラインツールを作成しました。
🤗データ計測ツールにアクセスするには、ここをクリックしてください。
機械学習データセットの急成長する統一リポジトリの開発者として(Lhoest et al. 2021)、🤗Hugging Faceチームはデータセットのドキュメント化のための良い実践をサポートするために取り組んできました(McMillan-Major et al. 2021)。静的(進化する可能性のある)ドキュメントはこの方向性への必要な第一歩を表しますが、データセットの実際の内容を理解するには、動機付けのある計測とそれに対する対話的な可視化能力が必要です。
そのため、私たちはオープンソースのPythonライブラリとノーコードインターフェースである🤗データ計測ツールを紹介します。これは、私たちのデータセットとSpaces Hubsを使用して、優れたStreamlitツールと組み合わせて、データセットの理解、構築、キュレーション、比較を支援するために使用することができます。
- 🤗データセットを使った画像検索
- カスタムデータセットでセマンティックセグメンテーションモデルを微調整する
- PyTorch完全にシャーディングされたデータパラレルを使用して、大規模モデルのトレーニングを加速する
🤗データ計測ツールとは何ですか?
データ計測ツール(DMT)は、データセットの作成者やユーザーが責任あるデータ開発のために有意義で役立つメトリクスを自動的に計算できるインタラクティブなインターフェースおよびオープンソースライブラリです。
なぜこのツールを作成したのですか?
機械学習データセットの綿密なキュレーションと分析は、AIの開発においてしばしば見落とされています。AIにおける「ビッグデータ」の現在の標準(Luccioni et al. 2021, Dodge et al. 2021)は、さまざまなウェブサイトから収集されたデータを使用しており、異なるデータソースが具体的に何を表しているか、それらがモデルの学習にどのように影響するかについてはほとんど注意が払われていません。データセットの注釈手法は、開発者の目標に合ったデータセットのキュレーションに役立つことがありますが、これらのデータセットのさまざまな側面を「測定する」ための手法はかなり限られています(Sambasivan et al. 2021)。
AIの新しい研究では、データセットの作成方法において基本的なパラダイムシフトが求められています(Paullada et al. 2020, Denton et al. 2021)。これには、開始時からデータセット作成のための詳細な要件の定義(Hutchinson et al. 2021)、問題のあるコンテンツやバイアスの懸念を考慮したデータセットのキュレーション(Yang et al. 2020, Prabhu and Birhane 2020)、データセットの構築と維持に内在する価値を明示すること(Scheuerman et al. 2021, Birhane et al. 2021)が含まれます。データセット開発は、さまざまな学問領域の人々が情報を提供できるようにするべきタスクであるとの一般的な合意はありますが、実際には生データ自体とのインターフェースがしばしばボトルネックとなります。データセットの分析とクエリには複雑なコーディングスキルが必要です。
それにもかかわらず、異なる学問領域の人々がデータセットを測定し、照会し、比較できるようにするための公に利用可能なツールはほとんどありません。私たちはこのギャップを埋めることを目指しています。私たちは、Know Your DataやData Quality for AIなどの最近のツールから学び、Vision and Language Datasets(Ferraro et al. 2015)、Datasheets for Datasets(Gebru et al. 2018)、Data Statements(Bender&Friedman 2019)などのデータセットのドキュメント化に関する研究提案からも学びました。その結果、データセットの計測を行うためのオープンソースライブラリと、詳細なデータセット分析のためのノーコードインターフェースが提供されています。
🤗データ計測ツールはいつ使えますか?
🤗データ計測ツールは、既存のNLPデータセットの探索に反復的に使用することができます。また、まもなくゼロからデータセットを開発するための反復的な開発をサポートする予定です。これにより、データセットと責任あるデータセット開発に関する研究に基づいた実用的な洞察を提供し、ユーザーは高レベルの情報と特定のアイテムの両方に焦点を当てることができます。
🤗データ計測ツールを使用して何が学べますか?
データセットの基本
データセットの概要を把握するために
これにより、「このデータセットは何ですか?欠損値はありますか?」などの質問に答えることができます。これは、作業しているデータセットが期待通りであるかを「健全性チェック」として使用できます。
-
データセットの説明(Hugging Face Hubから)
-
欠損値またはNaNの数
記述統計
データセットの表面的な特徴を見るために
これにより、「このデータセットにはどのような言語が含まれていますか?多様性はどの程度ですか?」といった質問に答えることができます。
-
オープンクラスおよびクローズドクラスの単語のデータセットの語彙サイズと単語の分布。
-
データセットのラベルの分布とクラス(非)の情報。
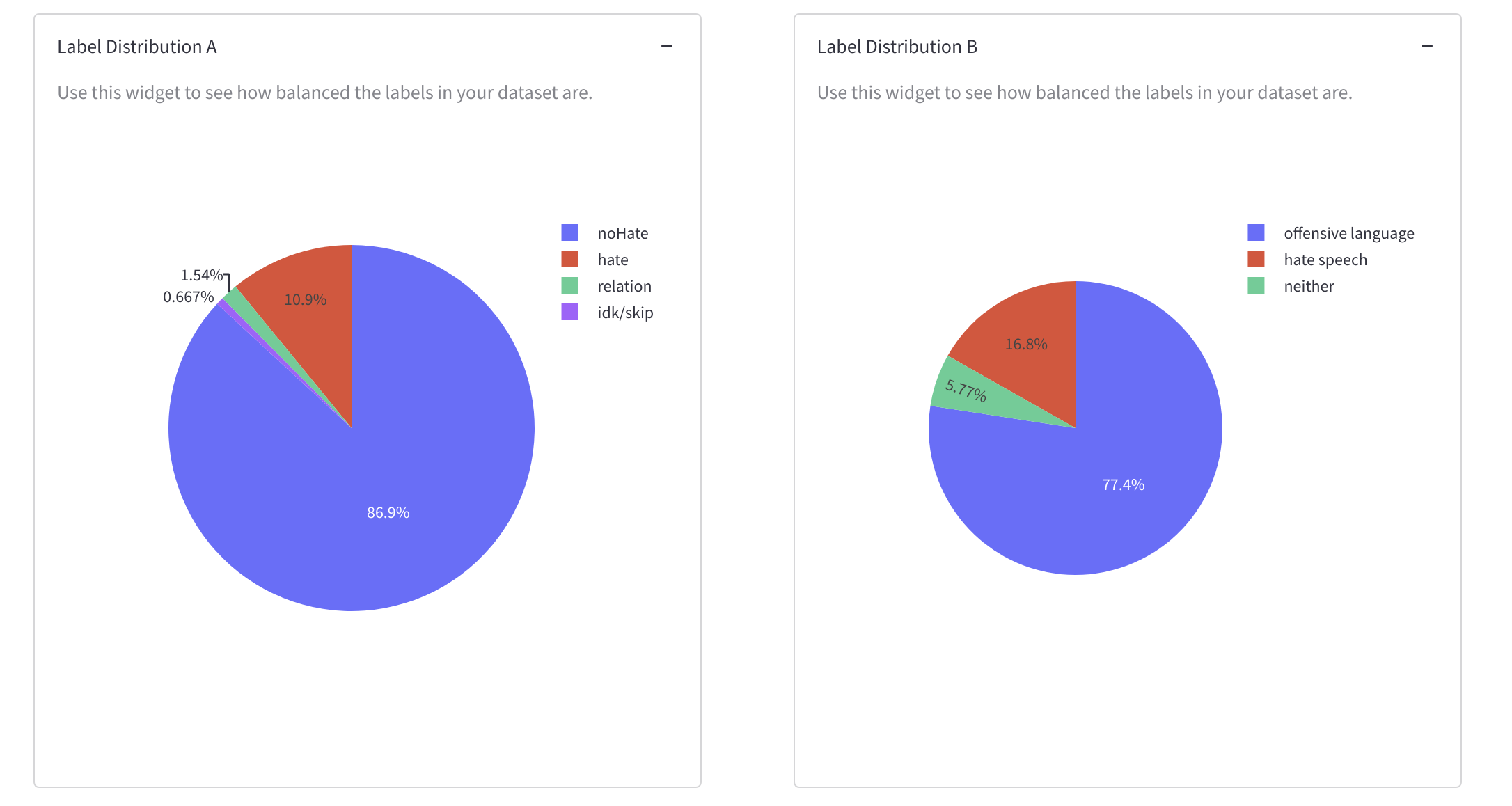
-
インスタンスの長さの平均、中央値、範囲、および分布。
-
データセット内の重複の数とその繰り返し回数。
これらのウィジェットを使用して、データセットの目標に最も代表的な要素と最も少ない要素が意味を持つかどうかを確認することができます。これらの測定値は、データセットがさまざまなコンテキストをキャプチャするのに役立つか、それがより制約されたものをキャプチャするのかを判断するために使用されます。また、ラベルとインスタンスの長さがどれだけ「バランス」しているかを測定するためにもこれらのウィジェットを使用することができます。また、外れ値や重複を特定し、削除することもできます。
分布統計
データセット内の言語パターンを測定するために
これにより、「このデータセット内の言語の振る舞いはどのようなものですか?」といった質問に答えることができます。
- 自然言語内の単語の予想される分布にデータセット内の単語の分布がどれだけ近いかを測定するジップの法則への適合度。
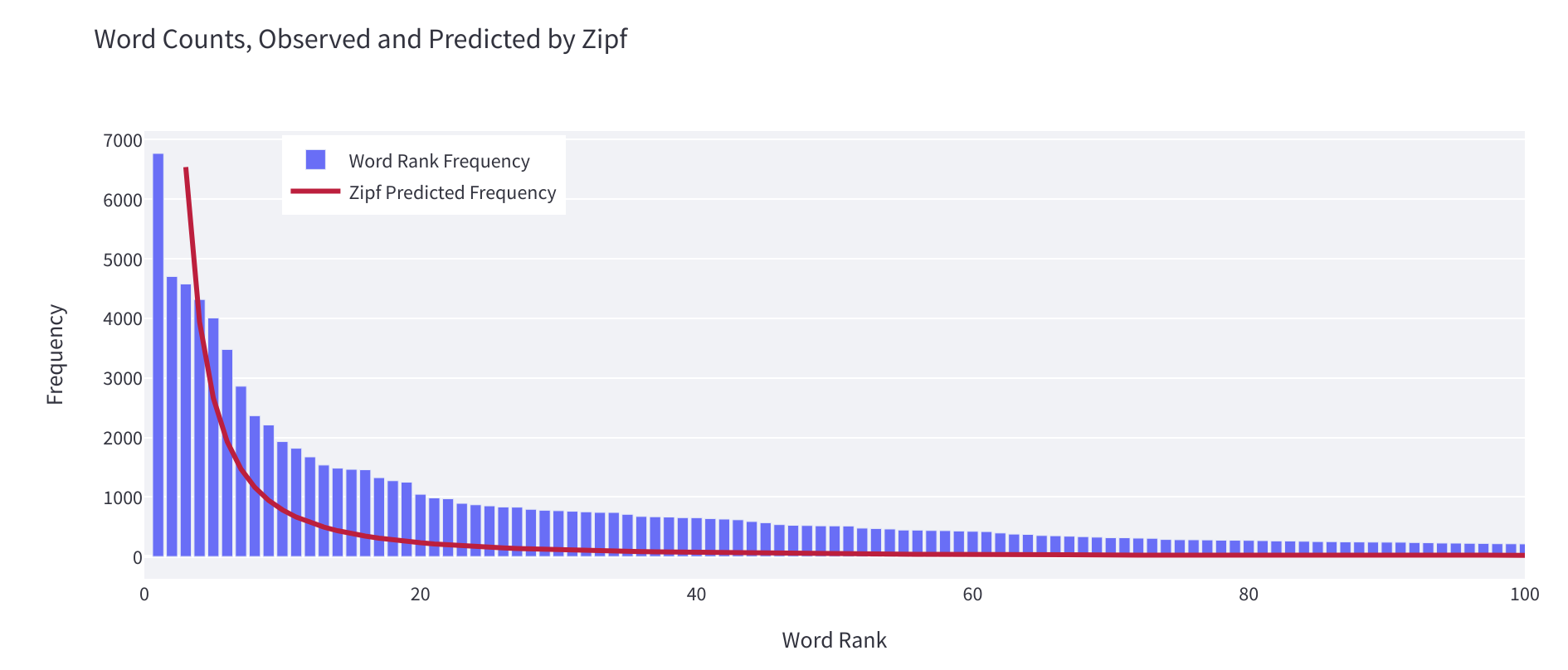
これを使用して、データセットが自然言語の振る舞いに近いか、それ以外の点でより非自然な要素があるかどうかを把握することができます。最適化が好きな方は、このウィジェットが計算するアルファ値を、データセットの開発中にできるだけ1に近づける値として見ることができます。異なる言語でのジップの法則に従ったアルファ値の詳細は、こちらでご覧いただけます。
一般的に、アルファ値が2より大きいか、最小ランクが10より大きい(注意が必要です)場合、データセットの分布は自然言語にとって比較的非自然なものとなります。これは、HTMLマークアップなどのデータセット内の混在アーティファクトの兆候となる可能性があります。この情報を使用して、データセットをクリーンアップしたり、データセットに追加する言語の分布を決定する際のガイドとして使用することができます。
比較統計
これにより、「このデータセットにはどのようなトピック、バイアス、および関連が含まれていますか?」といった質問に答えることができます。
-
データセット内の類似した言語のクラスタを特定するための埋め込みクラスタ。数百から数十万の文からなるデータセットの多様性を考慮することは困難です。類似性の尺度に基づいてこれらのテキスト項目をグループ化することで、ユーザーはその分布についていくつかの洞察を得ることができます。私たちは、Sentence-Transformerモデルと最大ドット積シングルリンケージ基準に基づいてデータセット内のテキストフィールドの階層クラスタリングを表示します。クラスタを探索するには、次の操作を行うことができます:
- ノード上にカーソルを合わせると、最も代表的な5つの例(重複なし)が表示されます
- テキストボックスに例を入力して、それに最も類似しているリーフクラスタを表示します
- IDでクラスタを選択して、そのすべての例を表示します
-
データセット内の単語ペア間の正規化相互情報(nPMI)。これは、問題のあるステレオタイプを特定するために使用されることがあります。「バイアス」という言葉は、ここではジェンダーや性的指向の軸に沿ったアイデンティティグループのステレオタイプと偏見を指します。将来的にはさらに用語を追加します。
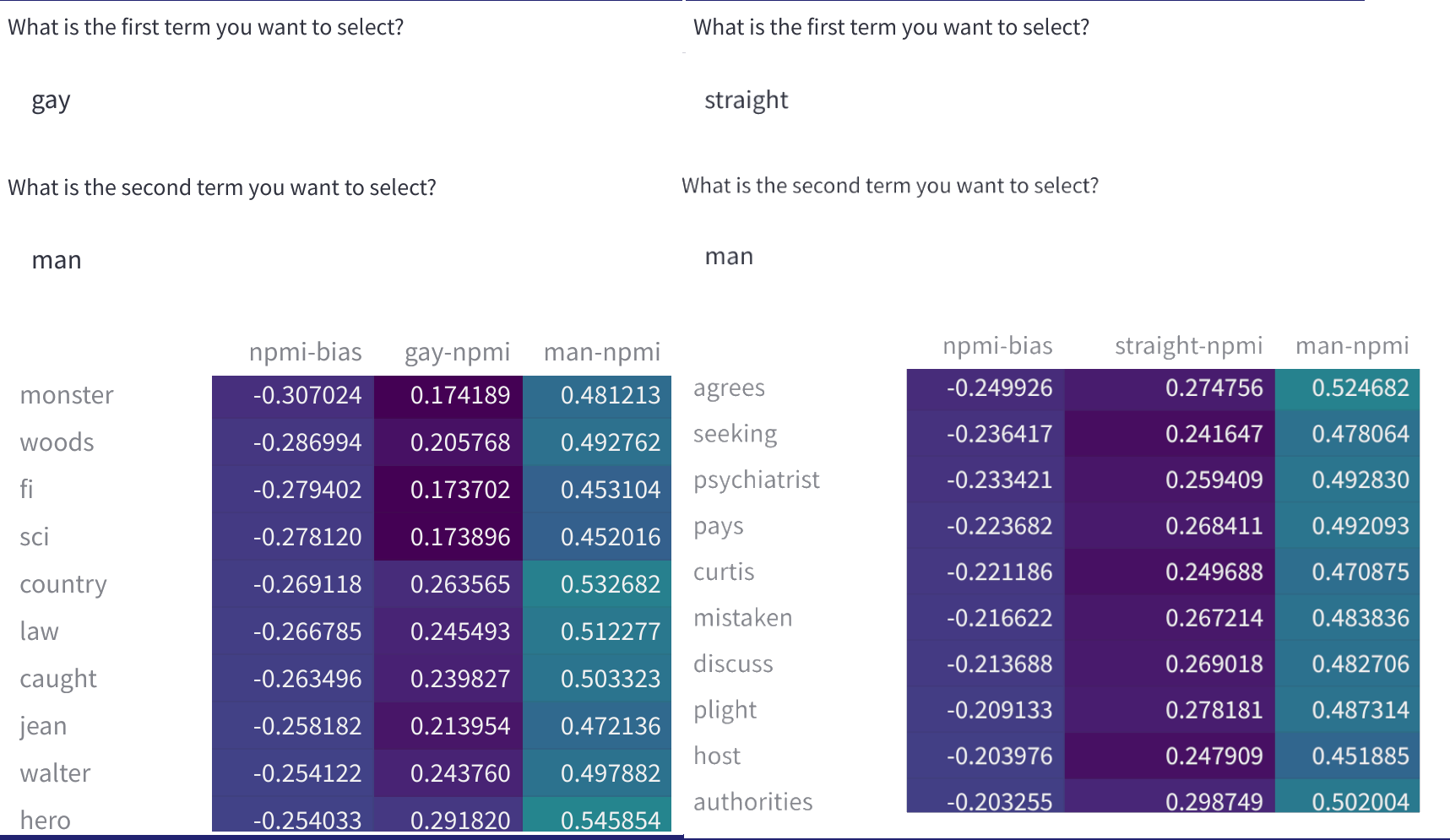
🤗 データ計測ツールの開発の現状はどうなっていますか?
現在、上記の機能を備えた、いくつかの人気のある英語のデータセット(例:SQuAD、imdb、C4、…)を使用して、ツールのアルファ版(v0)を紹介しています。nPMIの可視化に選択した単語は、私たちが取り組んでいるデータセットで頻繁に出てくるアイデンティティの用語の一部です。
今後数週間から数ヶ月にわたり、次のような機能を追加していく予定です:
- 🤗 データセットライブラリに存在するより多くの言語とデータセットをカバーします。
- ユーザーが提供したデータセットと反復的なデータセット構築をサポートします。
- ツール自体にさらなる機能と機能を追加します。例えば、nPMIの視覚化のための独自の用語を追加できるようにし、自分にとって重要な単語を選ぶことができるようにします。
謝辞
この作業を開始したThomas Wolfさんと、🤗 チームの他のメンバー(Quentin、Lewis、Sylvain、Nate、Julien C.、Julien S.、Clément、Omar、その他多くの方々)に感謝します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
