プレフィックス条件付きの画像キャプションと画像分類のデータセットの統合
'Integration of image captioning and image classification datasets with prefix conditions.'
クラウドAIチームの学生研究者である斎藤邦明と知識チームの研究科学者であるソン・キヒョクによる投稿
ウェブスケールの画像キャプションデータセットでの視覚言語(VL)モデルの事前トレーニングは、画像分類データによる従来の事前トレーニングに対する強力な代替手段として最近注目されています。画像キャプションデータセットはより「オープンドメイン」であると考えられており、広範なシーンタイプや語彙の単語を含んでいるため、少数およびゼロショットの認識タスクで強力な性能を持つモデルが得られます。しかし、細粒度のクラスの説明を持つ画像は稀であり、画像キャプションデータセットは手動のキュレーションを経ていないため、クラスの分布が不均衡になる可能性があります。これに対して、ImageNetなどの大規模な分類データセットは通常キュレーションされており、バランスの取れたラベル分布を持つ細粒度のカテゴリを提供することができます。一見有望に聞こえるかもしれませんが、キャプションと分類データセットを直接組み合わせて事前トレーニングすることは、さまざまな下流タスクに対してうまく汎化しないバイアスのある表現を生み出す可能性があるため、通常は成功しないことがあります。
CVPR 2023で発表された「Prefix Conditioning Unifies Language and Label Supervision」では、分類とキャプションデータセットの両方を使用して補完的な利点を提供する事前トレーニング戦略を示しています。まず、データセットを単純に統合すると、モデルはデータセットのバイアスに影響を受け、下流のゼロショット認識タスクでの最適な性能を発揮しない結果となります。各データセットにおける画像ドメインと語彙のカバレッジは異なるためです。この問題に対処するために、我々はプレフィックス条件付けという新しい簡単で効果的な手法を使用して、トレーニング中にデータセットのバイアスと視覚的な概念を分離します。このアプローチにより、言語エンコーダは両方のデータセットから学習すると同時に、各データセットに対して特徴抽出を調整することができます。プレフィックス条件付けは、Contrastive Language-Image Pre-training(CLIP)やUnified Contrastive Learning(UniCL)などの既存のVL事前トレーニング目標に簡単に統合できる汎用の手法です。
高レベルのアイデア
分類データセットは少なくとも2つの方法でバイアスがかかる傾向があります:(1)画像には制限されたドメインの単一のオブジェクトがほとんど含まれており、(2)語彙が限定されており、ゼロショット学習に必要な言語の柔軟性を欠いています。たとえば、「犬の写真」というクラスの埋め込みは、通常、ImageNet向けに最適化されたものでは、ImageNetデータセットから引っ張られた画像の中央に1匹の犬の写真が表示されるものであり、他のデータセットに含まれる複数の位置にいる犬の画像や他の被写体との組み合わせにはうまく汎化しません。
それに対して、キャプションデータセットにはさまざまなシーンタイプと語彙が含まれています。以下に示すように、モデルが単純に2つのデータセットから学習する場合、言語の埋め込みは画像分類とキャプションデータセットのバイアスを絡め取る可能性があり、ゼロショット分類の汎化性能が低下することがあります。2つのデータセットのバイアスを分離できれば、キャプションデータセットに適した言語の埋め込みを使用して汎化性能を向上させることができます。
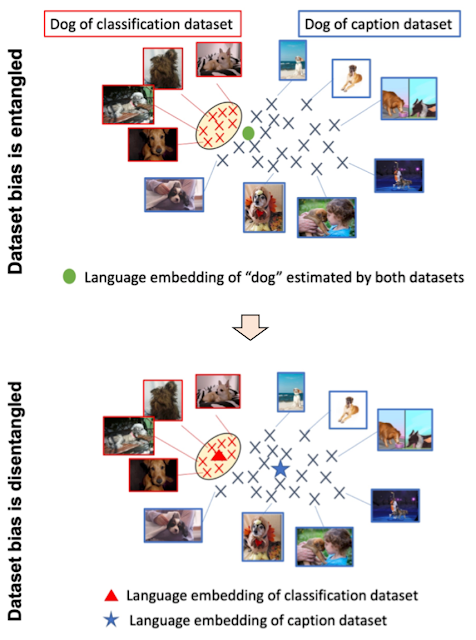 |
| 上:画像分類とキャプションデータセットのバイアスを絡め取る言語の埋め込み。下:2つのデータセットのバイアスを分離した言語の埋め込み。 |
プレフィックス条件付け
プレフィックス条件付けは、プロンプトチューニングに部分的に触発された手法であり、学習可能なトークンを入力トークンシーケンスの前に追加することで、事前トレーニング済みのモデルバックボーンにタスク固有の知識を学習させ、それを使用して下流タスクを解決するための方法を指示します。プレフィックス条件付けアプローチは、プロンプトチューニングとは異なる2つの点で異なります:(1)データセットのバイアスを分離するために画像キャプションと分類データセットを統合するように設計されており、(2)VL事前トレーニングに適用される一方、標準のプロンプトチューニングはモデルの微調整に使用されます。プレフィックス条件付けは、ユーザーが提供するデータセットの種類に基づいてモデルバックボーンの振る舞いを明示的に制御する方法です。特に、さまざまなタイプのデータセットの数が事前にわかっている場合に役立ちます。
トレーニング中、接頭辞条件付けは、各データセットタイプごとにテキストトークン(接頭辞トークン)を学習し、データセットのバイアスを吸収し、残りのテキストトークンが視覚的な概念を学習することに集中できるようにします。具体的には、入力トークンの先頭に各データセットタイプごとの接頭辞トークンを追加し、入力データのタイプ(分類対キャプションなど)に関する言語エンコーダと視覚エンコーダに情報を提供します。接頭辞トークンはデータセットタイプ固有のバイアスを学習するため、言語表現のバイアスを分離し、入力キャプションなしでもテスト時に画像キャプションデータセットで学習された埋め込みを利用することができます。
CLIPでは、言語エンコーダと視覚エンコーダを使用して接頭辞条件付けを利用します。テスト時には、画像キャプションデータセットで使用された接頭辞を使用します。このデータセットはより広範なシーンタイプと語彙をカバーするため、ゼロショット認識の性能が向上します。
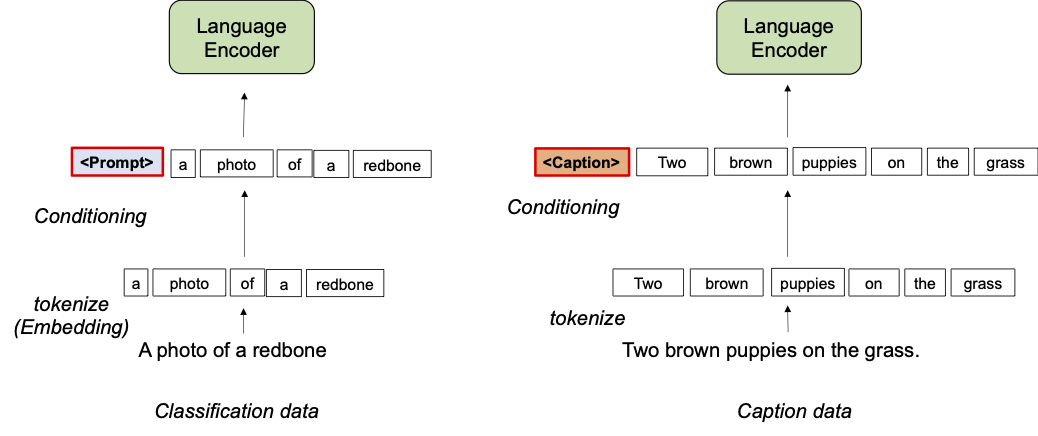 |
| 接頭辞条件付けのイラスト。 |
実験結果
接頭辞条件付けをCLIPとUniCLの2つのタイプの対比損失に適用し、ImageNet21K(IN21K)とConceptual 12M(CC12M)でトレーニングされたモデルと比較して、ゼロショット認識タスクの性能を評価します。接頭辞条件付けを使用するCLIPとUniCLモデルは、ゼロショット分類の精度が大幅に向上します。
 |
| IN21KまたはCC12Mのみでトレーニングされたモデルと、接頭辞条件付きの両方のデータセットを使用してトレーニングされたCLIPとUniCLモデル(”Ours”)との比較によるゼロショット分類の精度。 |
テスト時の接頭辞に関する研究
以下の表は、テスト時に使用される接頭辞による性能の変化を示しています。分類データセット(”Prompt”)に使用される接頭辞を使用すると、分類データセット(IN-1K)の性能が向上します。画像キャプションデータセット(”Caption”)に使用される同じ接頭辞を使用すると、他のデータセット(ゼロショットAVG)の性能が向上します。この分析は、接頭辞が画像キャプションデータセットに合わせられている場合、シーンタイプと語彙のより良い一般化が実現されることを示しています。
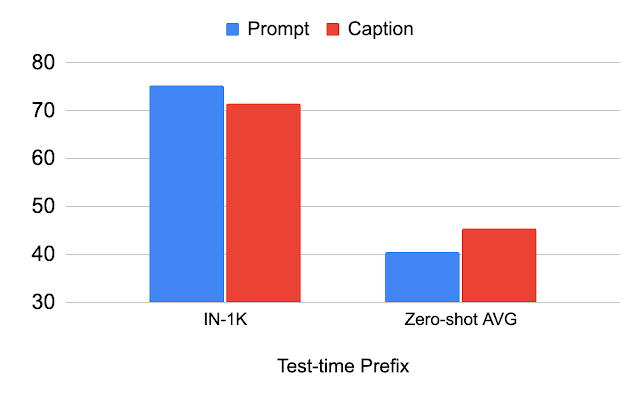 |
| テスト時に使用される接頭辞の分析。 |
画像分布のシフトに関する研究
私たちはImageNetのバリアントを使用して画像分布のシフトを研究しています。ImageNet-R(IN-R)およびImageNet-Sketch(IN-S)では、「Caption」プレフィックスが「Prompt」よりも優れたパフォーマンスを発揮していますが、ImageNet-V2(IN-V2)では劣っています。これは、「Caption」プレフィックスが分類データセットから遠いドメインで一般化を達成していることを示しています。したがって、最適なプレフィックスは、テストドメインが分類データセットからどれだけ遠いかによって異なる可能性があります。
 |
| 画像レベルの分布シフトに対する分析。IN:ImageNet、IN-V2:ImageNet-V2、IN-R:アート、カートゥーンスタイルのImageNet、IN-S:ImageNet Sketch。 |
結論と今後の課題
私たちは、ゼロショット分類のために画像キャプションと分類データセットを統一するためのプレフィックス条件付けという手法を紹介しています。このアプローチにより、ゼロショット分類の精度が向上し、プレフィックスは言語埋め込みのバイアスを制御することができることを示しています。ただし、キャプションデータセットで学習したプレフィックスがゼロショット分類に最適であるとは限りません。各テストデータセットに最適なプレフィックスを特定することは、将来の課題として興味深い方向性です。
謝辞
この研究は、Kuniaki Saito、Kihyuk Sohn、Xiang Zhang、Chun-Liang Li、Chen-Yu Lee、Kate Saenko、およびTomas Pfisterによって行われました。貴重なフィードバックをくれたZizhao ZhangとSergey Ioffeに感謝します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
