韓国のこの人工知能(AI)論文では、FFNeRVという新しいフレーム単位のビデオ表現が提案されていますフレーム単位のフローマップと多重解像度の時空グリッドを使用しています
In this Korean AI paper, a new frame-based video representation called FFNeRV is proposed. It utilizes frame-based flow maps and multi-resolution spatio-temporal grids.


最近では、ニューラルネットワークを用いて座標を数量(スカラーまたはベクトル)にマッピングして信号を表すニューラルフィールドの研究が急速に進展しています。これにより、音声、画像、3D形状、動画など、さまざまな信号を扱うためにこの技術を利用することへの関心が高まっています。普遍近似定理と座標エンコーディング技術は、脳フィールドの正確な信号表現のための理論的な基盤を提供しています。最近の調査では、データ圧縮、生成モデル、信号操作、基本的な信号表現における適応性が示されています。
最近では、ニューラルネットワークを用いて座標を数量(スカラーまたはベクトル)にマッピングして信号を表すニューラルフィールドの研究が急速に進展しています。これにより、音声、画像、3D形状、動画など、さまざまな信号を扱うためにこの技術を利用することへの関心が高まっています。普遍近似定理と座標エンコーディング技術は、脳フィールドの正確な信号表現のための理論的な基盤を提供しています。最近の調査では、データ圧縮、生成モデル、信号操作、基本的な信号表現における適応性が示されています。
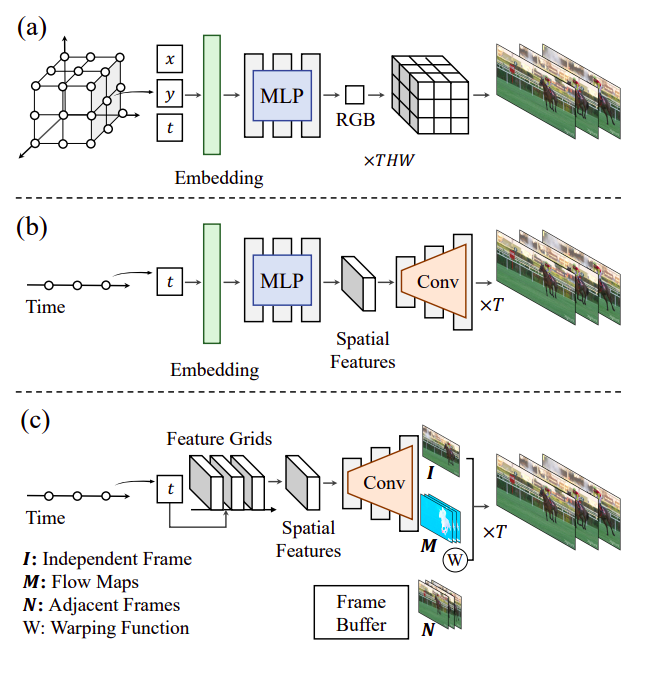
各時刻座標は、MLPと畳み込み層のスタックによって作成されたビデオフレームによって表されます。基本的なニューラルフィールドの設計に比べて、私たちの手法はエンコーディング時間を大幅に削減し、一般的なビデオ圧縮技術を上回ります。このパラダイムは、最近提案されたE-NeRVによっても追求され、さらにビデオの品質を向上させるものです。図1に示すように、彼らはフローガイドのフレームごとのニューラル表現(FFNeRV)を提供しています。彼らは光学フローをフレームごとの表現に埋め込んで、時間的冗長性を利用しています。これは一般的なビデオコーデックからのインスピレーションを得たものです。フローによって導かれる近くのフレームを組み合わせることにより、FFNeRVは前のフレームからピクセルの再利用を強制するビデオフレームを作成します。ネットワークがフレーム間で同じピクセル値を再度覚えることを避けるように促すことで、パラメータの効率性が劇的に改善されます。
- 「Rodinに会ってください:さまざまな入力ソースから3Dデジタルアバターを生成する革新的な人工知能(AI)フレームワーク」
- 「デバイス内AIの強化 QualcommとMetaがLlama 2テクノロジーと共同開発」
- マイクロソフトが「TypeChat」をリリース:型を使用して自然言語インターフェースを簡単に構築できるAIライブラリ
実験結果によると、UVGデータセットでのビデオ圧縮とフレーム補間では、FFNeRVが他のフレームごとのアルゴリズムを上回っています。さらなる圧縮性能の向上のために、連続的な時間座標を対応する潜在的な特徴にマッピングするために、固定された空間解像度の多重解像度の時間グリッドを使用することを提案しています。これは、グリッドベースのニューラル表現に触発されたものです。さらに、より縮小された畳み込みアーキテクチャを利用することを提案しています。彼らは、フレームごとのフロー表現において、高品質の画像と軽量なニューラルネットワークを生成する生成モデルによってドライブされたグループとポイントワイズの畳み込みを使用しています。FFNeRVは、量子化意識トレーニングとエントロピー符号化を使用した人気のあるビデオコーデック(H.264およびHEVC)を上回り、最先端のビデオ圧縮アルゴリズムと同等の性能を発揮します。コードの実装はNeRVに基づいており、GitHubで利用可能です。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「テキストゥアをご紹介します:3Dメッシュのテキストゥアリングのための新しい人工知能(AI)フレームワーク」
- 「Amazon Transcribe Toxicity Detectionを使用して、会話中の有害な言語をフラグ付けします」
- 「AWSは、人工知能、機械学習、生成AIのガイドを提供しており、AI戦略を計画するための新しい情報を提供しています」
- 「グラフ注意ネットワーク論文のイラストとPyTorchによる実装の説明」
- 「AIの力を解き放つ – VoAGIとMachine Learning Masteryによる特別リリース」
- 「DreamPose」というAIフレームワークを使用して、ファッション画像を見事な写真のようなビデオに変換します
- 遺伝的アルゴリズムを使用したPythonによるTV番組スケジューリングの最適化






