一般的に、オープンエンドの遊びから優れたエージェントが生まれる
In general, excellent agents emerge from open-ended play.
近年、人工知能エージェントはさまざまな複雑なゲーム環境で成功を収めています。例えば、AlphaZeroはチェス、将棋、囲碁の世界チャンピオンプログラムに勝利しましたが、最初は基本的なルールしか知らない状態からスタートしました。強化学習(RL)を通じて、この単一のシステムは、試行錯誤の反復プロセスを通じてゲームを繰り返しプレイすることで学習しました。しかし、AlphaZeroはまだ各ゲームごとに個別にトレーニングされており、RLプロセスをゼロから繰り返すことなく別のゲームやタスクを学習することはできませんでした。Atari、Capture the Flag、StarCraft II、Dota 2、Hide-and-Seekなど、RLの他の成功例にも同様の制約があります。DeepMindのミッションである科学と人類の進歩のための知能の解決により、私たちはこの制約を克服し、より一般的かつ適応性のある行動を示すAIエージェントを作成する方法を探求しました。1つのゲームずつ学習するのではなく、これらのエージェントは完全に新しい状況に反応し、これまで見たことのないゲームやタスクを含む多くのゲームやタスクの宇宙をプレイすることができるようになるでしょう。
本日、私たちは「オープンエンドの学習は一般的に有能なエージェントにつながる」というタイトルのプレプリントを公開しました。このプレプリントでは、人間の相互作用データを必要とせずに多くの異なるゲームをプレイできるエージェントのトレーニングの最初の手順について詳細に説明しています。私たちはXLandと呼ぶ広大なゲーム環境を作成しました。この環境には、一貫した人間に関連する3Dワールド内で多くのマルチプレイヤーゲームが含まれています。この環境では、エージェントのトレーニング方法やトレーニング対象のゲームを動的に制御する新しい学習アルゴリズムを形成することが可能です。エージェントの能力は、トレーニング中に発生する課題への応答として反復的に改善され、学習プロセスによってトレーニングタスクが絶えず洗練されるため、エージェントは学習を止めることはありません。その結果、トレーニング中に遭遇しなかった単純なオブジェクト検索の問題から、隠れんぼやCapture the Flagといった複雑なゲームまで、幅広いタスクで成功する能力を持つエージェントが生まれます。エージェントは、個々のタスクに特化するのではなく、実験など、多くのタスクに広く適用されるヒューリスティックな行動を示します。この新しいアプローチは、環境が常に変化する中で迅速に適応する柔軟性を持つより一般的なエージェントの創造に向けた重要な一歩となります。
さまざまなテストタスクをプレイするエージェント。エージェントはさまざまなゲームでトレーニングされ、その結果、トレーニング中には見たことのないテストゲームにも一般化することができます。
多様なトレーニングタスクの宇宙
RLでトレーニングされたエージェントの行動がゲーム全体に適用できるほど一般的ではないという問題の1つは、トレーニングデータ(「データ」とは異なるタスクのこと)が不足していることです。RLでトレーニングされたエージェントは、十分な数のタスクでトレーニングすることができないため、学習した行動を新しいタスクに適応させることができませんでした。しかし、プロシージャルに生成されたタスクを可能にするシミュレートされた空間を設計することで、私たちのチームはプログラムによって生成されたタスクでトレーニングし、経験を生成する方法を作り出しました。これにより、XLandには無数のタスクが含まれるようになりました。これらのタスクは、さまざまなゲーム、ワールド、プレイヤーにまたがるものです。
私たちのAIエージェントは、物理的な世界をシミュレートするための3D一人称アバターでマルチプレイヤー環境に存在しています。プレイヤーはRGB画像を観察して周囲の状況を感知し、目標のテキスト説明を受け取り、さまざまなゲームでトレーニングします。これらのゲームは、オブジェクトを見つけたり世界を移動したりする協力ゲームなど、シンプルなものから始まります。プレイヤーの目標は「紫のキューブの近くにいること」などです。より複雑なゲームでは、複数の報酬オプションから選択することに基づいています。「紫のキューブの近くにいるか、黄色い球を赤い床に置く」といったものです。さらに競争的なゲームでは、共同プレイヤーと対戦することもあります。対称的な隠れんぼなどは、各プレイヤーが「相手を見て相手に見つからないようにする」という目標を持っています。各ゲームではプレイヤーに報酬が与えられ、各プレイヤーの最終目標は報酬を最大化することです。
XLandはプログラムによって指定できるため、ゲーム空間ではデータを自動的に生成することができます。また、XLandのタスクには複数のプレイヤーが関与しているため、AIエージェントが直面する課題には共同プレイヤーの振る舞いが大きく影響します。これらの複雑な非線形な相互作用は、環境の要素のわずかな変化でもエージェントの課題に大きな変化をもたらすため、トレーニングに適したデータソースとなります。

トレーニング手法
私たちの研究の中心にあるのは、エージェントのニューラルネットワークのトレーニングにおける深層強化学習の役割です。私たちが使用するニューラルネットワークアーキテクチャは、エージェントの内部再帰状態に対する注意機構を提供し、エージェントの注意をゲーム固有のサブゴールの推定値で誘導するのに役立ちます。私たちは、この目標に注意を払うエージェント(GOAT)が、より一般的に有能なポリシーを学習することを発見しました。
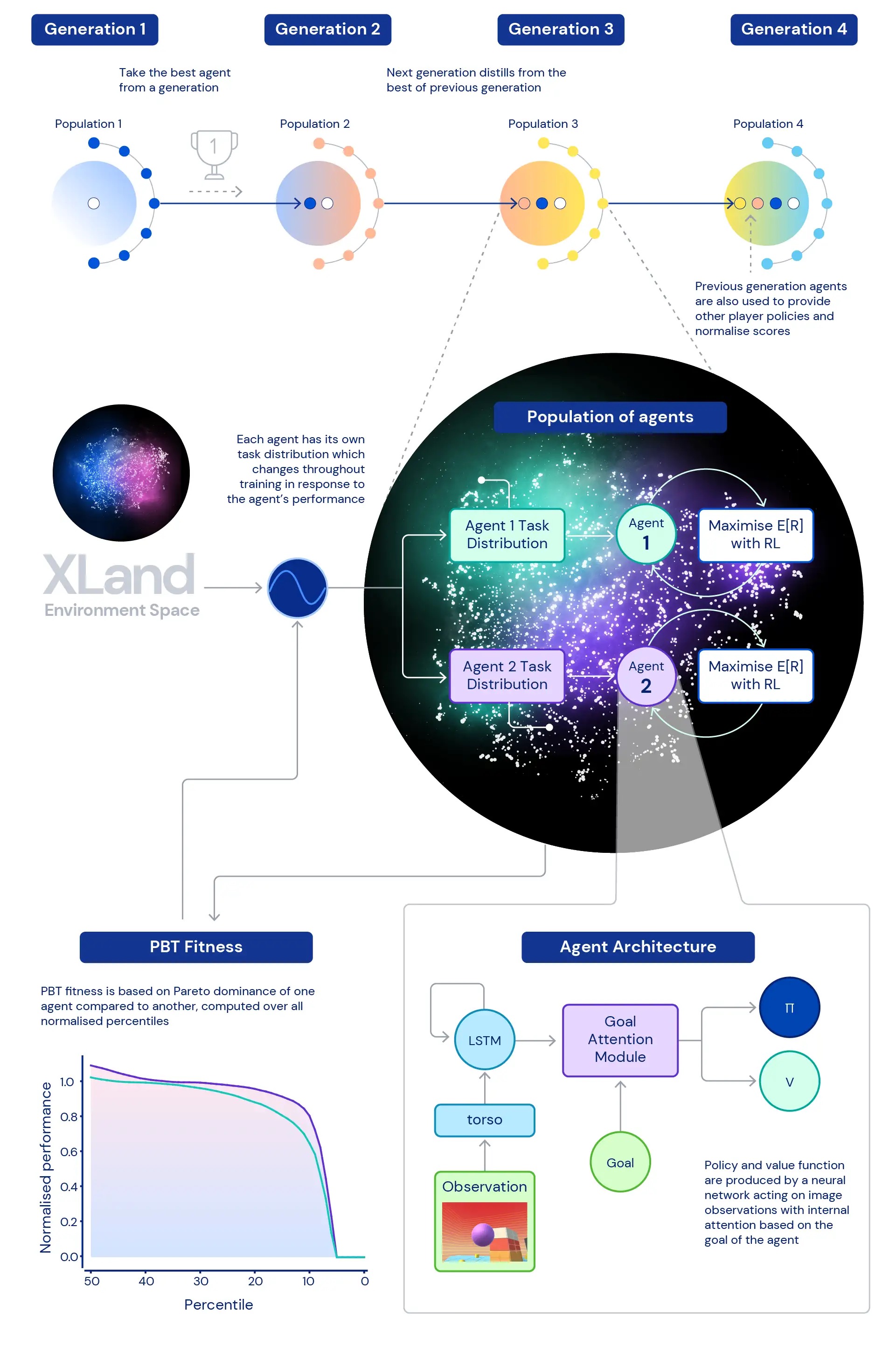
また、私たちは次のような疑問にも取り組みました。どのようなトレーニングタスクの分布が最も優れたエージェントを生み出すのか、特に非常に広範な環境においてはどうでしょうか?私たちが使用する動的タスク生成では、エージェントのトレーニングタスクの分布を継続的に変更することが可能です。すべてのタスクは、トレーニングに適した難しすぎず簡単すぎないように生成されます。その後、エージェントの一般的な能力を向上させることを目指すフィットネスに基づいて、動的タスク生成のパラメータを調整するために集団ベースのトレーニング(PBT)を使用します。最後に、複数のトレーニング実行を連鎖させることで、各世代のエージェントが前の世代からブートストラップできるようにします。
これにより、深層強化学習を中心とした最終的なトレーニングプロセスが形成され、エージェントのニューラルネットワークが経験の各ステップで更新されます:
- 経験のステップは、エージェントの行動に応じて動的に生成されるトレーニングタスクから得られます。
- エージェントのタスク生成関数は、エージェントの相対的なパフォーマンスと堅牢性に応じて変異します。
- 最も外側のループでは、エージェントの世代はお互いにブートストラップし、マルチプレイヤー環境にますます豊かな共同プレイヤーを提供し、進行の測定自体を再定義します。
トレーニングプロセスはゼロから始まり、反復的に複雑さを構築し、エージェントの学習を継続するために学習問題を常に変更します。組み合わせた学習システムの反復的な性質は、境界の定義されたパフォーマンス指標を最適化するのではなく、一般能力のスペクトルを反復的に定義することにより、エージェントのために潜在的に無限の学習プロセスにつながります。ただし、環境空間とエージェントのニューラルネットワークの表現能力に制限されます。
進捗の測定
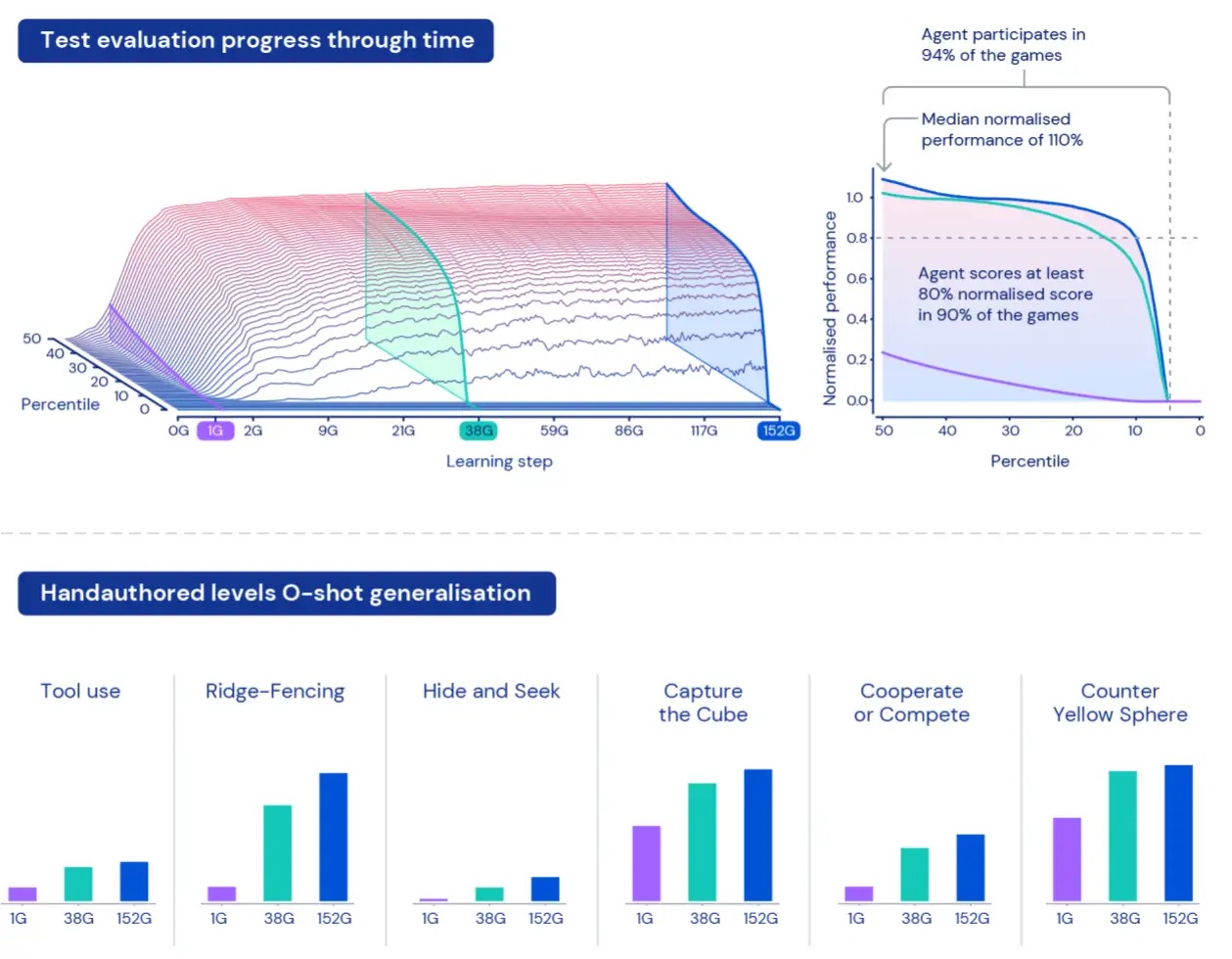
この広大な宇宙内でエージェントのパフォーマンスを測定するために、トレーニングに使用されるデータとは別に、ゲームやワールドを使用した一連の評価タスクを作成します。これらの「保留中」のタスクには、かくれんぼやフラッグキャプチャなど、特に人間が設計したタスクが含まれます。
XLandのサイズのため、エージェントのパフォーマンスを理解し、特徴づけることは難しい場合があります。各タスクには異なる複雑さレベル、達成可能な報酬のスケール、エージェントの異なる能力が関与しているため、保留中のタスクの報酬を単純に平均するだけでは、実際の複雑さや報酬の違いが隠されてしまいます。また、すべてのタスクを等しく興味深いものとして扱うことは必ずしも真ではありません。これらの制限を克服するために、異なるアプローチを取ります。まず第一に、現在の訓練済みプレーヤーのセットを使用して計算されたナッシュ均衡値を使用してタスクごとのスコアを正規化します。次に、正規化されたスコアの全体的な分布を考慮します。平均正規化スコアではなく、正規化スコアの異なるパーセンタイルを見ることにより、報酬のステップを少なくとも1つ獲得するタスクの割合(参加度)も考慮します。つまり、他のエージェントよりもすべてのパーセンタイルでパフォーマンスを上回る場合にのみ、エージェントは他のエージェントよりも優れていると見なされます。この測定方法により、エージェントのパフォーマンスと堅牢性を意味のある方法で評価することができます。
より一般的に有能なエージェント
5世代にわたってエージェントを訓練した結果、保留中の評価空間全体で学習とパフォーマンスの一貫した改善が見られました。XLand内の4,000のユニークなワールドで約700,000のユニークなゲームをプレイし、最終世代の各エージェントは3.4百万のユニークなタスクによる2000億のトレーニングステップを経験しました。現時点では、私たちのエージェントは人間でさえ不可能なわずかなタスクを除いて、手順で生成された評価タスクすべてに参加することができました。そして、私たちが見ている結果は、タスク空間全体でゼロショットの振る舞いを示し、正規化スコアのパーセンタイルのフロンティアが絶えず改善していることを明確に示しています。
エージェントを定性的に見ると、個々のタスクに特化した高度に最適化された具体的な行動ではなく、一般的なヒューリスティックな行動が現れることがよくあります。新しい状況でエージェントが正確に「最善の行動」を知っているのではなく、報酬の得られる状態に到達するまでエージェントが実験し、世界の状態を変える様子が観察されます。また、エージェントは視界を遮るために物体を使用したり、ランプを作成したり、他の物体を回収したりするために他のツールを使用することも見られます。環境がマルチプレイヤーであるため、自己分析ゲームなどの社会的ジレンマを訓練中にエージェントの行動の進展を調べることができます。訓練が進むにつれて、エージェントは自身のコピーとプレイする際により協力的な行動を示すようになります。環境の性質上、意図を特定するのは難しいですが、私たちが見る行動はしばしば偶然のように見えますが、それでも一貫して発生することがわかります。
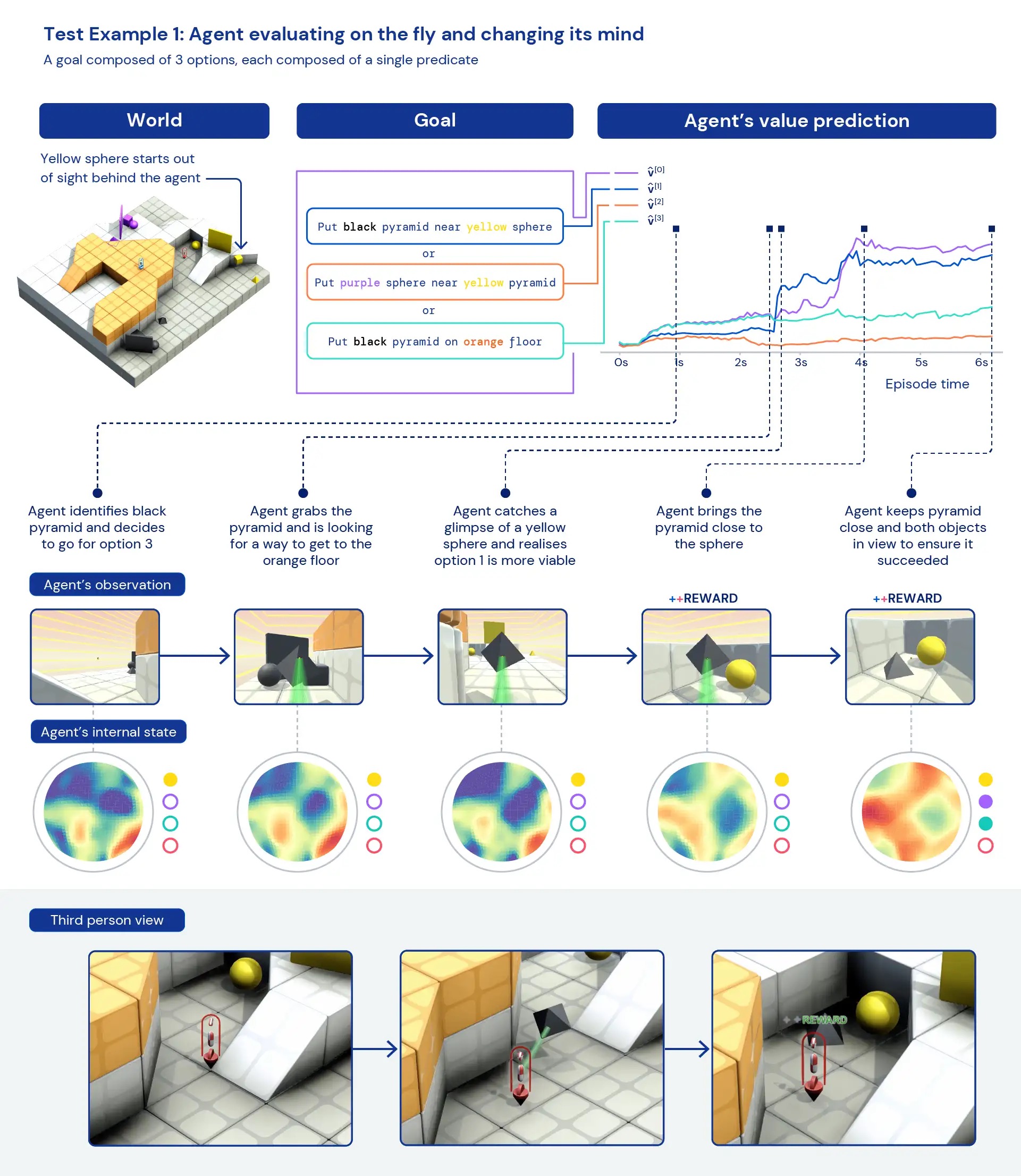
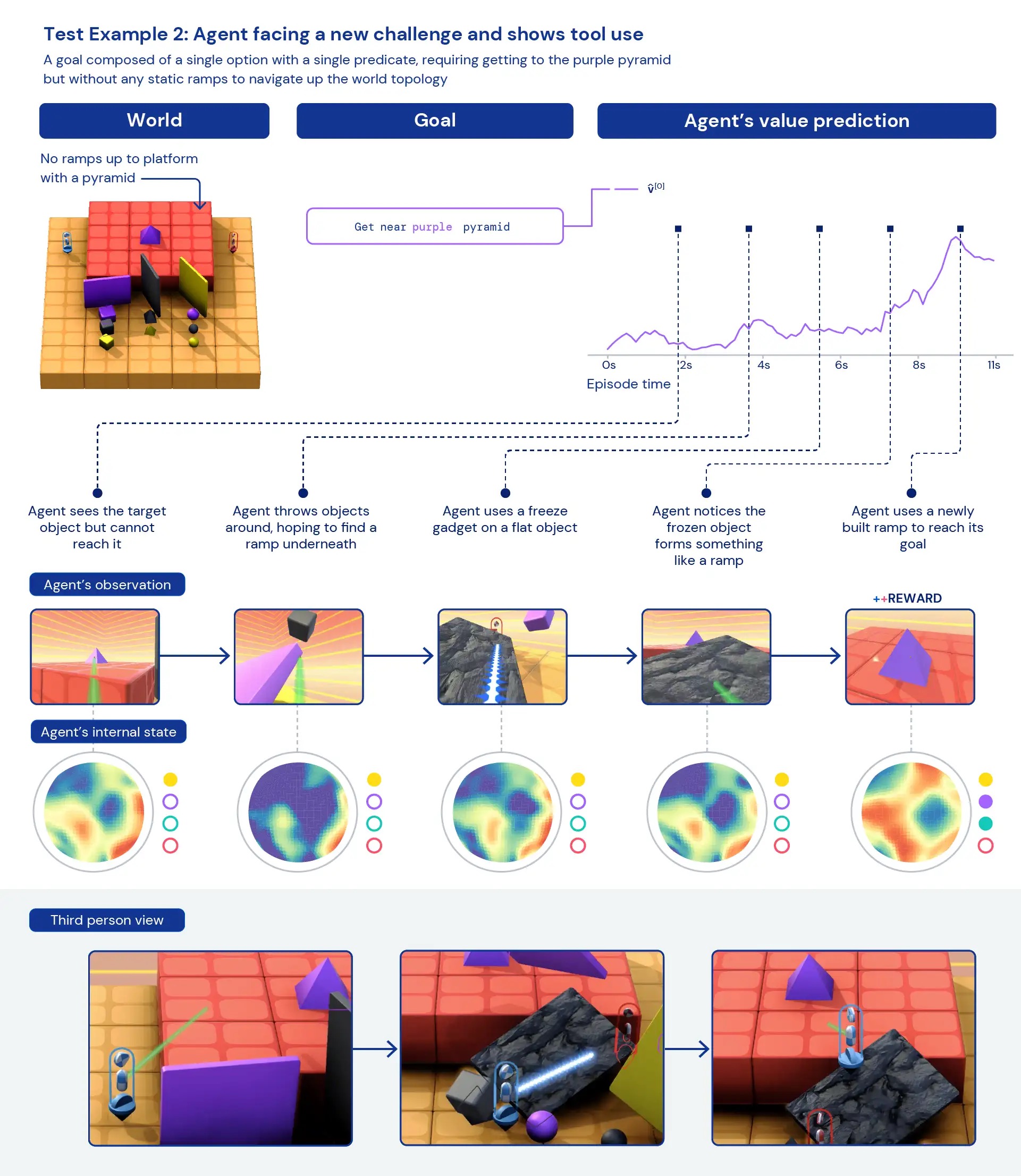



エージェントの内部表現を分析すると、広範なタスク空間での強化学習へのこのアプローチにより、エージェントは自身の体の基本的な概念と時間の経過、および遭遇するゲームの高レベルの構造を理解していることがわかります。さらに興味深いことに、彼らは環境の報酬の状態を明確に認識しています。新しいタスクにおいては、これらのエージェントを30分間だけ集中的に訓練することで、エージェントは迅速に適応することができますが、ゼロから強化学習で訓練されたエージェントはこれらのタスクをまったく学習することができません。
XLandのような環境と、複雑さの創造をサポートする新しいトレーニングアルゴリズムを開発することで、強化学習エージェントのゼロショット汎化の明白な兆候を見ることができました。これらのエージェントはこのタスク空間内で一般的に能力を持ち始めていますが、私たちは彼らのパフォーマンスをさらに向上させ、ますます適応性のあるエージェントを作成するために研究と開発を続けることを期待しています。
詳細については、技術論文のプレプリントと結果のビデオをご覧ください。これにより、他の研究者もより適応性のある、一般的に能力のあるAIエージェントの新しい道を見つけることができると期待しています。これらの進歩に興奮している場合は、私たちのチームに参加を検討してください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






