「OpenAI APIを使用して、大規模な言語モデルを用いた表データ予測の改善」
Improving table data prediction using the OpenAI API and large-scale language models.
OpenAI APIを使用した機械学習分類、プロンプトエンジニアリング、テキスト埋め込みとモデルの説明可能性によるPythonの実装
近年、大規模な言語モデルやそれに基づくアプリケーションやツールがニュースやソーシャルVoAGIで話題となっています。GitHubのトレンディングページでは、大規模な言語モデルを広範に利用するリポジトリが多数紹介されています。私たちは大規模な言語モデルの素晴らしい能力を目にしました。それらはマーケティングのための文章作成や文章の要約、音楽の作曲、ソフトウェア開発のためのコード生成などに活用できます。
企業は内部およびオンラインで蓄積された豊富な表形式のデータを持っています。私たちは従来の機械学習ライフサイクルにおいて大規模な言語モデルを表形式のデータに適用し、モデルのパフォーマンスを向上させ、ビジネス価値を追加することができるでしょうか?
本記事では、以下のトピックについてPythonの実装コードを紹介します:
- Kaggle Heart Attack Analysis&Predictionデータセット上での一般化線形モデルとツリーベースモデルの構築
- プロンプトエンジニアリングによる表形式データのテキスト変換
- OpenAI APIを使用したゼロショット分類(GPT-3.5モデル:text-davinci-003)
- OpenAI埋め込みAPI(text-embedding-ada-002)を使用した機械学習モデルのパフォーマンス向上
- OpenAI API(gpt-3.5-turbo)による予測の説明可能性
データセットの説明
このデータは、KaggleのウェブサイトでCC0 1.0 Universal(CC0 1.0)パブリックドメイン奉納ライセンスで提供されています。著作権はありませんので、作品のコピー、変更、配布、実行(商業目的でも可)が可能です。以下のリンクを参照してください:
心臓発作の分析と予測のためのデータセット
心臓発作分類のためのデータセット
www.kaggle.com
このデータセットには、人口統計学的特徴、医療状態、およびターゲットが含まれています。以下に各列の説明を示します:
- age:申請者の年齢
- sex:申請者の性別
- cp:胸痛のタイプ:値1は典型的な狭心症、値2は非典型的な狭心症、値3は非狭心症痛、値4は無症状です。
- trtbps:安静時血圧(mm Hg)
- chol:BMIセンサー経由で取得されたコレステロール(mg/dl)
- fbs:空腹時血糖値>120 mg/dl、1 = True、0 = False
- restecg:安静時心電図結果
- thalachh:最大心拍数
- exng:運動誘発性狭心症(1 = はい、0 = いいえ)
- oldpeak:以前のピーク
- slp:傾斜
- caa:大血管の数
- thall:タール率
- output:目的変数、0=心臓発作の可能性が低い、1=心臓発作の可能性が高い
機械学習モデル
心臓発作の発生可能性を予測するための2値分類モデルが開発されています。このセクションでは以下の内容をカバーします:
- 前処理:欠損値チェック、ワンホットエンコーディング、トレインテスト分割など
- ロジスティック回帰、リッジ回帰、ラッソ回帰、ランダムフォレストを含む4つのモデルの構築
- AUCによるモデルの評価
まず、パッケージをインポートし、データをロードし、前処理を行い、トレインテスト分割を行います。
import warningswarnings.filterwarnings("ignore")# Math and Vectorsimport pandas as pdimport numpy as np# Visualizationsimport plotly.express as px# MLfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import roc_auc_scoreimport concurrent.futures# Utils functionsfrom utils import prediction, compile_prompt, get_embedding, ml_models, create_auc_chart, gpt_reasoningpd.set_option('display.max_columns', None)# load datadf = pd.read_csv("./data/raw data/heart_attack_predicton_kaggle.csv")df.shape# check missing valuedf.isna().sum()# check outcome distributiondf['output'].value_counts()# one-hot encodingcat_cols = ['sex','exng','cp','fbs','restecg','slp','thall']df_model = pd.get_dummies(df,columns=cat_cols)df_model.shape# train test stratified split# Seperate dependent and independent variablesX = df_model.drop(axis=1,columns=['output'])y = df_model['output'].tolist()X_tr, X_val, y_tr, y_val = train_test_split(X, y, test_size=0.2, random_state=101, stratify=y,shuffle=True)さあ、モデルオブジェクトを構築し、モデルにフィットさせ、テストセットでの予測を行い、AUCを計算しましょう。
## モデル関数def ml_models(): lr = LogisticRegression(penalty='none', solver='saga', random_state=42, n_jobs=-1) lasso = LogisticRegression(penalty='l1', solver='saga', random_state=42, n_jobs=-1) ridge = LogisticRegression(penalty='l2', solver='saga', random_state=42, n_jobs=-1) rf = RandomForestClassifier(n_estimators=300, max_depth=5, min_samples_leaf=50, max_features=0.3, random_state=42, n_jobs=-1) models = {'LR': lr, 'LASSO': lasso, 'RIDGE': ridge, 'RF': rf} return modelsmodels = ml_models()lr = models['LR']lasso = models['LASSO'] ridge = models['RIDGE'] rf = models['RF'] pred_dict = {}for k, m in models.items(): print(k) m.fit(X_tr, y_tr) preds = m.predict_proba(X_val)[:,1] auc = roc_auc_score(y_val, preds) pred_dict[k] = preds print(k + ': ', auc)次に、モデルのパフォーマンス(AUC)を可視化して比較しましょう。
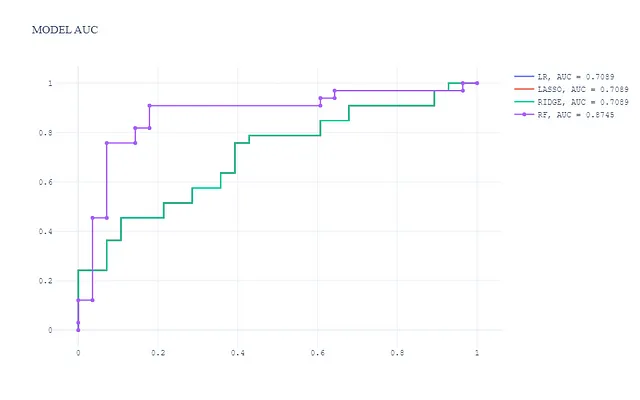
この可視化では:
- ツリーベースのモデル(ランダムフォレスト)が最も優れたパフォーマンスを発揮し、AUCがはるかに高いです。
- 3つの一般化線形モデルはパフォーマンスレベルが似ており、AUCはツリーベースのモデルよりも低くなっていますが、これは予想された結果です。
OpenAI APIを使用したゼロショット分類
テキスト-davinci-003モデルを基に、表形式のデータでゼロショット分類を実行します。Pythonの実装に入る前に、ゼロショット分類についてもう少し理解しましょう。Hugging Faceの定義によれば:
ゼロショット分類は、モデルが訓練中に見たことのないクラスを予測するタスクです。この方法は、事前に学習済みの言語モデルを活用しており、通常は元々の訓練用途とは異なるアプリケーションで使用されるモデルを指します。ラベル付きデータの量が少ない場合に特に有用です。
ゼロショット分類では、モデルに対して実行したいタスクを説明するプロンプトとテキストのシーケンスが与えられますが、期待される振る舞いの例は提供されません。このセクションでは以下の内容をカバーします:
- プロンプトエンジニアリングのための表形式データの前処理
- LLMへのプロンプティング
- GPT-3.5 APIによるゼロショット予測:テキスト-davinci-003
- AUCによるモデル評価
表形式データの前処理
まず、プロンプトを使う前にデータを処理しましょう:
df_gpt = df.copy()df_gpt['sex'] = np.where(df_gpt['sex'] == 1, 'Male', 'Female')df_gpt['cp'] = np.where(df_gpt['cp'] == 1, 'Typical angina', np.where(df_gpt['cp'] == 2, 'Atypical angina', np.where(df_gpt['cp'] == 3, 'Non-anginal pain', 'Asymptomatic')))df_gpt['fbs'] = np.where(df_gpt['fbs'] == 1, 'Fasting blood sugar > 120 mg/dl', 'Fasting blood sugar <= 120 mg/dl')df_gpt['restecg'] = np.where(df_gpt['restecg'] == 0, 'Normal', np.where(df_gpt['restecg'] == 1, 'Having ST-T wave abnormality (T wave inversions and/or ST elevation or depression of > 0.05 mV)', "Showing probable or definite left ventricular hypertrophy by Estes' criteria"))df_gpt['exng'] = np.where(df_gpt['exng'] == 1, 'Exercise induced angina', 'Without exercise induced angina')df_gpt['slp'] = np.where(df_gpt['slp'] == 0, 'The slope of the peak exercise ST segment is downsloping', np.where(df_gpt['slp'] == 1, 'The slope of the peak exercise ST segment is flat', 'The slope of the peak exercise ST segment is upsloping'))df_gpt['thall'] = np.where(df_gpt['thall'] == 1, 'Thall is fixed defect', np.where(df_gpt['thall'] == 2, 'Thall is normal', 'Thall is reversable defect'))# テストデータフレームを辞書に変換application_list = X_val.to_dict(orient='records')len(application_list)LLMのプロンプト
プロンプトは、特定のタスクに対して大規模な言語モデルと対話するための強力なツールです。プロンプトは、ユーザーが提供した入力であり、モデルが応答することを意図しています。プロンプトは、テキストや画像など、さまざまな形式で表現することができます。
この記事では、プロンプトには予想されるJSON出力形式と質問自体が含まれています。心臓発作のデータセットでは、テキストのプロンプトは次のようになります:
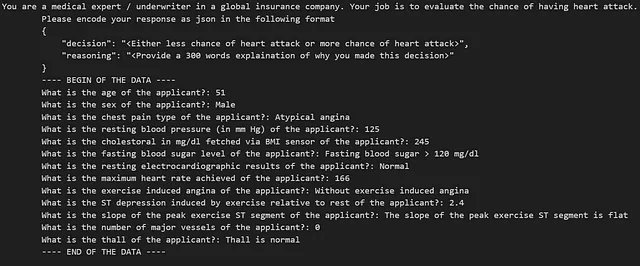
次に、プロンプトとOpenAI-3.5 APIからの応答を作成するためのプロンプトとAPI呼び出し関数を定義します。
def prediction_GPT3_5(data, explain = False): if explain: prompt = prompt_logic(explain) else: prompt = prompt_logic(explain) print(prompt) response = openai.Completion.create( model = 'text-davinci-003', prompt=prompt, max_tokens=64, n=1, stop=None, temperature=0.5, top_p=1.0, frequency_penalty=0.0, presence_penalty=0.0 ) try: output = response.choices[0].text.strip() output_dict = json.loads(output) return output_dict except (IndexError, ValueError): return Nonedef prediction(combined_data_argu): application_data, explain = combined_data_argu response = prediction_GPT3_5(application_data, explain) return responseAPIのレスポンスを取得する – マルチプロセッシング
マルチプロセッシングを利用してAPIの呼び出しを高速化します。コードは以下の通りです:
### GPT-3.5モデル:text-davinci-003から予測を取得する - マルチプロセッシングプールwith concurrent.futures.ThreadPoolExecutor() as executor: # credit_dataとexplainを単一のiterableに結合 combined_data = zip(application_list, [False] * len(application_list)) # トランザクション処理タスクをexecutorに送信 results = executor.map(prediction, combined_data) # 応答をリストに収集 responses = list(results)responses_df = pd.DataFrame(responses)responses_df.shapeゼロショット分類のAUC
ゼロショット分類のAUCは0.48であり、予測がランダムチャンスよりも悪いことを示しています。これは、このデータセットでGPT-3.5モデルのテキストダヴィンチ-003に漏洩がない可能性があることを示しています。
auc_gpt= roc_auc_score(y_val, responses_df['output'])auc_gptOpenAI埋め込みで機械学習モデルのパフォーマンスを向上させる
LLM埋め込みは、自然言語とコードのタスク(セマンティックサーチ、クラスタリング、トピックモデリング、分類など)を実行しやすくする、大規模な言語モデル(例:OpenAI API)のエンドポイントです。プロンプトエンジニアリングにより、表形式のデータを自然言語テキストに変換し、埋め込みを生成することができます。埋め込みは、少量のラベル付きデータを用いて自然言語をより理解し、文脈を適応させることで、従来の機械学習モデルのパフォーマンスを向上させる可能性があります。つまり、これはこの文脈での特徴エンジニアリングの一種です。
特徴エンジニアリングは、未知のデータにおける予測モデルの精度を向上させるために、元のデータをより適切に表現する特徴に変換するプロセスです。
このセクションでは、次の内容を見ていきます:
- API呼び出しを通じてOpenAIの埋め込みを取得する方法
- モデルのパフォーマンス比較 – 埋め込み特徴あり vs 埋め込み特徴なし
まず、APIを介して埋め込みを取得し、元のデータセットとマージするための関数を定義しましょう:
# 埋め込みを取得するための関数を定義するdef get_embedding(text, model="text-embedding-ada-002"): text = text.replace("\n", " ") return openai.Embedding.create(input = [text], model=model)['data'][0]['embedding']# APIの呼び出しと元のデータセットとのマージdf_gpt['ada_embedding'] = df_gpt.combined.apply(lambda x: get_embedding(x, model='text-embedding-ada-002'))df_gpt = df_gpt.join(pd.DataFrame(df_gpt['ada_embedding'].apply(pd.Series)))df_gpt.drop(['combined', 'ada_embedding'], axis = 1, inplace = True)df_gpt.columns = df_gpt.columns.tolist()[:14] + ['Embedding_' + str(i) for i in df_gpt.columns.tolist()[14:]]df = pd.concat([df, df_gpt[[i for i in df_gpt.columns.tolist() if i.startswith('Embedding_')]]], axis=1)df_gpt.shape純粋な機械学習モデルと同様に、層別分割を実施し、モデルを適合させます:
# 依存変数と独立変数を分離する
X = df.drop(axis=1,columns=['output'])
y = df['output'].tolist()
# データをトレーニングセットとバリデーションセットに分割
X_tr, X_val, y_tr, y_val = train_test_split(X, y, test_size=0.2, random_state=101, stratify=y, shuffle=True)
# モデルを初期化
models = ml_models()
lr = models['LR']
lasso = models['LASSO']
ridge = models['RIDGE']
rf = models['RF']
# 予測結果を格納する辞書を初期化
pred_dict_gpt = {}
for k, m in models.items():
print(k)
m.fit(X_tr, y_tr)
preds = m.predict_proba(X_val)[:,1]
auc = roc_auc_score(y_val, preds)
pred_dict_gpt[k + '_With_GPT_Embedding'] = preds
print(k + '_With_GPT_Embedding' + ': ', auc)埋め込み特徴量の有無によるモデルの性能比較
埋め込み特徴量を組み合わせることで、合計8つのモデルが得られます。テストセット上のROC曲線は以下の通りです:
pred_dict_combine = dict(list(pred_dict.items()) + list(pred_dict_gpt.items()))
create_auc_chart(pred_dict_combine, y_val, 'Model AUC')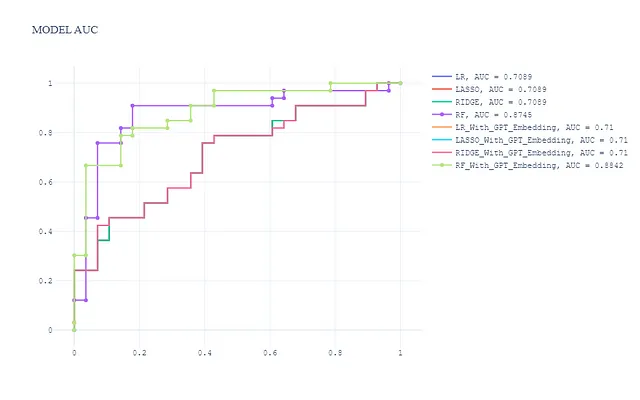
一般的に、以下のことが観察されます:
- 埋め込み特徴量は、一般線形モデル(ロジスティック回帰、Ridge、Lasso)の性能を著しく向上させていません
- 埋め込み特徴量を使用したランダムフォレストモデルの性能が最も優れており、埋め込み特徴量を使用しないランダムフォレストモデルよりもわずかに優れています
大規模言語モデルを伝統的なモデルトレーニングプロセスに統合し、出力の品質を向上させる可能性があります。大規模言語モデルは、モデルの意思決定を説明するのに役立つのでしょうか?次のセクションで詳しく見ていきましょう。
OpenAI APIを使用したモデルの説明可能性 — gpt-3.5-turbo
モデルの説明可能性は、特に保険、医療、金融、法律などの領域において、ユーザーがモデルがどのように意思決定を行うかをローカルおよびグローバルなレベルで理解する必要がある機械学習アプリケーションにおいて、重要なトピックの一つです。ディープラーニングモデルの解釈に関する記事を書いていますので、ディープラーニングモデルの解釈について詳しく知りたい場合は、それをご覧ください。
このセクションでは以下をカバーします:
- OpenAI APIへの入力の準備
- gpt-3.5-turboモデルによる推論の取得
まず、API呼び出しのために入力データを準備しましょう。
application_data = application_list[0]
application_data{'age': 51, 'sex': 'Male', 'cp': 'Atypical angina', 'trtbps': 125, 'chol': 245, 'fbs': 'Fasting blood sugar > 120 mg/dl', 'restecg': 'Normal', 'thalachh': 166, 'exng': 'Without exercise induced angina', 'oldpeak': 2.4, 'slp': 'The slope of the peak exercise ST segment is flat', 'caa': 0, 'thall': 'Thall is normal'}次に、gpt-3.5-turbo APIを呼び出して推論結果を取得しましょう。
message_objects = [ {"role": "system", "content": '''You are a medical expert / underwriter in a global insurance company. Your job is to evaluate the chance of having heart attack. Please encode your response as json in the following format {{ "decision": "<Either less chance of heart attack or more chance of heart attack>", }}'''}, {"role": "user", "content": prompt}, ]completion = openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=message_objects, max_tokens=1000, # 応答の長さに応じてmax_tokensを調整してください stop=None, # 必要に応じてカスタムの停止条件を設定してください )# 応答メッセージのコンテンツを抽出する response_content = completion.choices[0].message["content"]応答は非常に印象的であり、大規模な言語モデルは強力な推論能力と合理的な説明を示しています。
{ “decision”: “心臓発作の可能性が低い”, “reasoning”: “提供された情報に基づくと、申請者は心臓発作のリスクが低いことを示すいくつかの要素を持っています。まず、申請者の年齢は51歳で、若いとは言えませんが、心臓発作の高リスク範囲にも入りません。次に、申請者は男性です。男性は一般的に女性よりも心臓発作のリスクが高いですが、これは唯一の決定要素ではありません。第三に、申請者が報告した胸痛のタイプは非典型的な狭心症です。非典型的な狭心症は、典型的な狭心症と比べて予測性が低く、異なるパターンを示す胸痛です。これは典型的な狭心症と比べて心臓発作のリスクが低いことを示す可能性があります。第四に、申請者の安静時血圧は125 mm Hgです。これは正常範囲内であり、心臓発作のリスク因子である高血圧を示しません。第五に、申請者のコレステロール値は245 mg/dlです。これは推奨されるレベルよりも高いですが、非常に高いわけではなく、申請者のBMIが提供されていないため、コレステロール値が肥満による高値なのかどうかは判断できません。第六に、申請者の断食時血糖値は120 mg/dlを超えていません。これは糖尿病のリスク因子である心臓発作のリスクが低いことを示します。第七に、申請者の安静時心電図の結果は正常であり、心臓の機能が正常であり、心臓発作のリスクが低いです。第八に、申請者の最大心拍数は166であり、心血管系の健康を示す良い兆候です。第九に、申請者は運動誘発性の狭心症を経験していません。これもプラスの要素です。第十に、安静時に比べて運動によって誘発されるST低下は2.4で、正常範囲内であり、重大な虚血を示しません。第十一に、ピーク運動時のSTセグメントの傾斜は平坦です。これは正常な所見であるか、申請者が報告した非典型的な狭心症に関連している可能性があります。最後に、申請者は大きな血管を持っておらず、正常なThallを持っており、冠動脈疾患のリスクが低いことを示しています。これらのすべての要素を考慮すると、申請者は心臓発作のリスクが低い可能性が高いです。ただし、この評価は提供された情報に基づいており、確定的な判断を行うためにはさらなる医学的評価が必要です。” }
概要
大規模な言語モデルは、さまざまな産業で幅広いユースケースを解決するための強力なツールです。LLM(Large Language Models)アプリケーションの作成は簡単で、ますます手頃になっています。LLMは、企業に真のビジネス価値を追加すること間違いありません。
お帰りに
エキサイティングで実り多いデータサイエンスの学習の冒険に参加していただき、歓迎します!私のVoAGIページをフォローして、魅力的なデータサイエンスコンテンツの連続ストリームを常に受け取ってください。今後数ヶ月間、機械学習の基礎、NLPの基礎、エンドツーエンドのデータサイエンス実装についてさらに共有します。乾杯!
参考
- https://platform.openai.com/docs/guides/embeddings/what-are-embeddings
- https://platform.openai.com/docs/models/overview
ゼロショット分類とは何ですか? – Hugging Face
機械学習を使用したゼロショット分類について学ぶ
huggingface.co
大規模言語モデルの紹介:プロンプトエンジニアリングとP-Tuning | NVIDIA Technical Blog
ChatGPTはかなりのインパクトを与えました。ユーザーはAIチャットボットを使って質問をしたり、詩を書いたり、…を与えたりするのが興奮しています
developer.nvidia.com
SHAPを使用した深層学習モデルの解釈
画像と表形式データに対するPython実装
towardsdatascience.com
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
