「データサイエンスの面接を改善する簡単な方法」
Improving Data Science Interviews Simple Methods
テクニカルな問題フレーミングを通じて上位5%の候補者を特定する
この投稿では、未経験のデータサイエンスの採用マネージャーとしての私のミスについて共有し、それが私の技術面接の方法を変えた方法を紹介します。また、例としてデータサイエンスの面接問題を取り上げ、より優れた候補者が問題に取り組む方法が弱い候補者と異なることを示します。私の議論はデータサイエンスに焦点を当てていますが、私の洞察と提案のほとんどは、ソフトウェアエンジニアリング、データエンジニアリングなどを含む、他の技術的な役割にも関連しています。
しかし、最初に私自身についての簡単な背景を紹介します。
私はソフトウェアエンジニアリングとデータサイエンス/機械学習の分野で約9年間働いています。私はさまざまな規模の企業で働いてきました。最大のものはWayfair(従業員数13,000人)で、最小のものは現在の雇用主であるFi(約100人)です。私はFiでデータの副社長を務めています。今は、私のキャリアの半分が個別の貢献者(IC)として、半分がマネージャー/ディレクター/副社長として過ごされました。後半の期間には、2人から15人までのチームを構築または引き継いできました。その間に、約20人を採用し、数百回の面接を行い、無数の面接パイプラインを設計しました。
採用マネージャーとしての私の時間には、多くの成功した採用を果たしましたが、途中でいくつかのミスもしました。たとえば、最初に面接パイプラインをゼロから構築する責任を負ったキャリア初期の採用マネージャーとして、私は最大の採用ミスをしました。そのミスが理解できるようになるまでには、別の1年か2年かかりました。しかし、一度それを明確にすることができたら、それが避けられるミスであることを知り、それが再び起こらないようにするための手順を講じることができました。
- なぜデータは新たな石油ではなく、データマーケットプレイスは私たちに失敗したのか
- なぜデータは「新しい石油」ではなく、データマーケットプレイスは私たちに失敗したのか
- アップリフトモデリング—クレジットカード更新キャンペーンの最適化ガイド データサイエンティストのための
この投稿はそのミスについてのものであり、私がそれを繰り返さないために行っていることについてです。
私の採用ミス

2019年に、私はシニア機械学習エンジニアからリードデータサイエンティストへ昇進しました。私のチームは、既に構築したものとは異なるモデルと統合が必要な新しいモデリングアプリケーションを構築することを目指していました。そして、最近マネジメントの役割を引き受けたばかりだったため、必要なインフラをすべて自分で構築する余裕がありませんでした。そのため、新しいモデルと統合を構築し維持するためのシニアデータサイエンティストを採用することにしました。
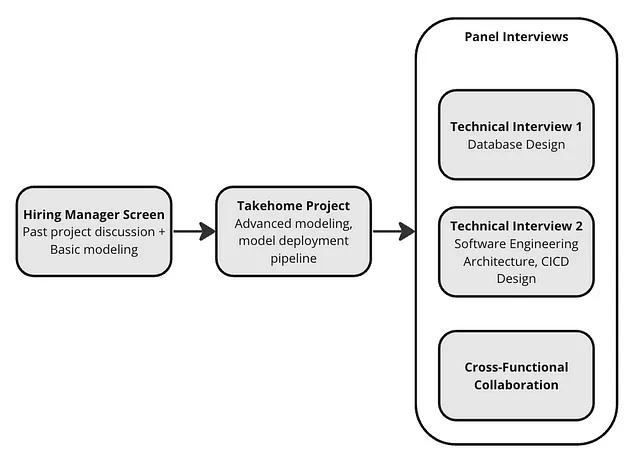
面接プロセス
私は、採用マネージャーのスクリーニング、テイクホームプロジェクト、いくつかのパネル面接からなる面接パイプラインを設計しました。クロスファンクションの面接以外は、すべて技術的な性質の面接であり、機械学習、データエンジニアリング、ソフトウェアエンジニアリングのいずれかの課題や設計問題が含まれていました。数カ月後、理想的な候補者を採用することができました。
新入社員の最初の数週間はうまくいきました。テックスタック、チームメイト、ワークフロープロセスに慣れると、彼らに大規模なプロジェクトを割り当てました。
症状が現れる
割り当てられたプロジェクトに数週間取り組んだ後、タスクが予想よりも長くかかっていることに気付きました。したがって、毎週彼らと追加の時間を過ごして、進捗状況と次のステップについて話し合いました。しかし、残念ながら、状況は改善しませんでした。進捗状況と次のステップについて話し合うたびに、進捗がないように思えることがほとんどでした。それどころか、彼らは解決すべきと考えていた技術的な障害が次々に浮かび上がりました。私はすべての技術的な障害がなぜそんなに関連性があるのか理解するのが難しかったため、イライラを感じました。
プロジェクトに2週間かかると予想していた時点で、2ヶ月経った頃、まだ機能するソリューションを持っていませんでした。さらに悪いことに、完了までの明確な期間さえありませんでした。
根本的な問題
私は数年間管理および採用を担当してきましたが、新卒者の成功と失敗の両方を経験してきました。その経験を通じて、根本的な問題が何であり、どこで間違ったのかを明確に説明できるようになりました。
その根本的な問題は、彼らの役割で成功するために必要なスキルセットが不足していたことでした。表面的には、彼らは技術的な能力が不足しているように思えるかもしれません。なぜなら、彼らは解決できない技術的な障害が頻繁に発生していました。しかし、それはそうではありませんでした。実際、彼らの技術的な能力は非常に優れていました。
むしろ、彼らは技術的なアプリケーションとビジネスのニーズの関連性を理解する能力が不足していたため、トレードオフをどのようにして行うかを知ることができませんでした。これは解決策の簡素化によって回避できた一連の解決不可能な技術的な障害として現れました。
たとえば、彼らが常に直面していた問題の一つは、扱っているデータセットのサイズに起因していました。しかし、彼らがこれを問題として挙げるたびに、私は興味のある上位3つまたは4つのフィーチャーのみのデータセットにトリミングし、関連性のあるレコードのみをフィルタリングすることを提案しました。これにより、全体のデータセットは元のサイズの0.5%未満になり、ボリュームに起因する問題を回避し、データセット全体の付加価値の80%を得ることができました。しかし、私がこれを提案するたびに、彼らがこれについて考えていなかったことは明らかでした。何度も言及しても、彼らが考えたことがなかったのです。
技術的な問題のフレーミング
要約すると、新任者はビジネスの文脈と技術の文脈の両方をしっかりと理解することに苦労していたため、解決しようとする技術的なタスクはしばしば必要以上に複雑でした。つまり、彼らは技術的な問題のフレーミングに問題がありました。これは、ビジネス目標を技術的な目標としてフレーミングする能力、および要件の一連が基盤となるビジネス目標をどのように表現するかを理解する能力です。
技術的な問題のフレーミングやデータチームの典型的なワークフローに詳しくない方々への説明ですが、通常、要件はプロダクトマネージャー(PM)またはマネージャー/テクニカルリードから提供されます。ただし、要件がICに提供される場合でも、要件は完全に網羅的ではありません。したがって、ICはそれらの要件に至った目的を理解する能力が必要です。自分自身でこれを行うことができない場合は、マネージャーまたはPMによって非常に注意深く監視される必要があります。これにより、チームの拡張性が制限され、ICとそのマネージャー/PMとの間に摩擦が生じます。
このシナリオを振り返ると、私が間違ったのは、技術的な問題のフレーミングを評価する面接を構築していなかったことであり、このスキルセットは彼らの役割で成功するための要件でした。これに気付いた後、私はこのスキルを面接プロセスに取り入れる方法を実験し始めました。幸いなことに、最も効果的だったものはわずかな調整だけでした。
面接の調整
以下に私が異なる点を説明します。
少なくとも1つの技術面接では、技術的なタスクを実際のビジネスシナリオに埋め込み、問題を適切に解決するために追加の文脈を完全に理解する必要があります。
技術的な能力の評価に加えて、この調整された面接では、候補者が要件からプロジェクトの実際の意図を推測し、技術的な解決策を設計する際にこの意図が達成されるようにする能力も評価します。
次に、技術的な問題のフレーミングを評価しない例の面接を見て、強力な解決策の見本を説明します。その後、同じ面接を技術的な問題のフレーミングの調整を加えたものとして示し、どのように強力な解決策が変化するかを示します。
この面接で使用する元のデータセットはこちらで入手できます。また、Kaggleノートブックとして設定された面接プロンプトもこちらで見つけることができます。
例1:技術的な問題のフレーミングの評価を行わないデータサイエンスモデリング面接
技術的な問題の評価を含まない面接のプロンプトです。
################################################ 技術的な問題の評価を含まない面接のプロンプト ################################################# 患者の心停止(心臓発作)に関連する# 患者の健康情報で構成されたデータセット# を提供します。# 各レコードは、胸の痛みを経験しているため、# 緊急治療室(ER)を訪れた患者を表します。# 各列は、ERに到着した時点で測定された# 心臓発作のタイプを含む測定値に対応します。# データセットには、# 患者がER訪問後48時間以内に心臓発作を起こしたかどうかを示す# 2値の列も含まれています。import pandas as pd df = pd.read_csv(f"{filepath}/heart.csv")display(df.head(5)# 提供された入力に基づいて、# 心臓発作が発生するかどうかを予測するモデルを構築する# タスクを担当してください。def predict_heart_attack(row): """ 心臓発作のデータセットの1行を受け入れます。 予測として0または1を返します。 """ # TODO pass
以前はこのインタビューを実際の環境で実施しており、小さくて整ったデータセットを使うと便利でした。データセットは小さく(303行と13の入力)で比較的きれいなので、MLの経験の量に関係なく、候補者は難なく分類器を構築できます。
評価
弱い候補者は簡単に見分けることができます。彼らは通常、所定の時間内に基本的なモデルさえ構築するのに苦労するため、良いモデルを構築することはまずありません。インタビュアーとしてより微妙なタスクは、「優れた」候補者を「優秀な」候補者から見分けることです。短時間で動作する分類器を構築する能力を示すだけでなく、より強力な候補者は通常、(1)反復的なアプローチを取ることで自分自身を差別化しており、すぐに動作するものを改善しています。さらに、(2)意図的な決定を下しています。たとえば、候補者にモデルのパフォーマンスを評価するために特定のパフォーマンス指標を選んだ理由を尋ねると、具体的な回答が得られます。弱いまたは経験の浅い候補者は回答を示すかもしれませんが、それに対する正当な理由はありません。
例2:技術的な問題の評価を含むデータサイエンスモデリングの面接
こちらは、同じインタビューの質問ですが、ビジネスシナリオが埋め込まれており、技術的な問題の評価が含まれています。
################################################ 技術的な問題の評価を含む面接のプロンプト ################################################# 緊急治療室(ER)は、# 心臓発作の症状である胸の痛みを経験している# 多数の患者を受け付けています。# 他の心臓発作の症状を示している患者は、# 心臓発作の影響を軽減するため、# またはそれを完全に回避するために# 優先的に(早期に)待合室を通過することが# 必要です。## 平均して、ERは、# 胸の痛みを経験している患者のうち20%を# 優先的に処理できるようになっています。# 現在のERの方針は、# Type 2の胸の痛み(非典型的な狭心症)を経験している# すべての患者を優先的に処理することです。# これは、データセット内の`df['cp'] == 1`の値に# 対応します。 ERスタッフは、# 現在の方針が最適ではないと考えており、# 高リスクの患者をより優先する方針を開発するために、# この患者データに対する分析を実施するように# 要求しています。# # 患者の心臓発作に関連する# 患者の健康情報で構成されたデータセットが# 提供されています。# 各レコードは、胸の痛みを経験しているため、# 緊急治療室(ER)を訪れた患者を表します。# 各列は、ERに到着した時点で測定された# 心臓発作のタイプを含む測定値に対応します。# データセットには、# 患者がER訪問後48時間以内に心臓発作を起こしたかどうかを示す# 2値の列も含まれています。import pandas as pd df = pd.read_csv(f"{filepath}/heart.csv")display(df.head(5)# ERの現行方針よりも優れた# 早期通過ポリシーを構築するために、# データセットを使用するのがタスクです。def fast_track(row): """ 心臓発作のデータセットの1行を受け入れます。 早期通過のための判断として0または1を返します。 """ # TODO pass問題の技術的な側面が変わらないことに注意してください – 同じデータセットが使用され、解の署名も同じです。ただし、理想的な解のプロファイルを変更する追加情報が追加されました。
新しい問題の説明
追加されたビジネスコンテキストには、解を始める前に理解する必要がある2つの新しい情報があります。まず、20%の患者しか高速化できないという制約があることです。これには60.6人、または切り上げると61人が対応します:
.20 * len(df) # 出力: 60.6したがって、高速化によって「救える」患者の最大数は61人であり、ERはそれ以上の高速化は行えません。
ERのコンテキストが提供する2番目の新しい情報は、新しい方針が検討されるために上回る必要のあるベースライン戦略があることです。このベースライン戦略では、正しく41件の心臓発作を予測できます:
# ERのベースラインポリシーは、タイプ2の胸痛の患者# (`df['cp'] == 1`)を高速化することです。# したがって、df['cp'] == 1 の場合は 1 を、# それ以外の場合は 0 を返すのが ERのベースライン# 戦略です。( df.groupby(['cp'])[['had_heart_attack']] .agg(['mean', 'count']))
.82 * 50 # 出力: 41追加された制約(61人の高速化の合計)とベースライン(41件の正しい予測)を組み合わせると、新しい目標は次のように定式化できます:k=61のrecall@k(k=61)が41よりも大きい分類器を見つける。
弱い候補者
技術的な問題のフレーム作成が弱い候補者は、これら2つの情報を見落とし、すぐに解決モードに入ります。これにより、高精度ではあるがリコールが41以下のサブオプティマルな解決策の1つ、またはリコールが高いが精度が非常に悪く、最初の61人の高速化では41件以上の心臓発作が得られない解決策の1つが一般的に導かれます。私は面接官として、候補者が間違った方向に進んでいるのを見ると、ヒントを与えて方向を修正する傾向があります。一部の候補者は私のヒントに気づき、正しい問題を特定するのに苦労する他の候補者はまだ苦しんでいます。
優れた候補者
技術的な問題のフレーム作成が優れている候補者は、問題に異なるアプローチを取ります。最初から解決モードに飛び込むのではなく、コンテキストを正確に理解するためにプロンプトを繰り返し読みます。
次に、成功と強く相関していること、そして私が注意を払っていることを行います:
最も優れた候補者は、取り組みを開始する前にアプローチを書き出し、それが妥当かどうかを私(面接官)に尋ねます。
これを観察すると、私はとても嬉しく思います。なぜなら、これが私が彼らが私のチームに参加する場合に彼らがやってほしいことだからです。私は、計画を事前に明確に説明し、開始する前に私に相談する意識を持っている人を求めています。これにより、最初に時間をかけることで、面接の途中でアプローチを変更する必要がなくなり、残りの時間を効果的に過ごすことができます。
正しい問題を言語化できる候補者は、通常、課題を解決することもできます。これは驚くべきことではありません。なぜなら、ベースラインを上回ることは非常に難しくありません。たとえば、次の単純なルールベースの解決策でもベースラインを上回ります:
def fast_track(row): """ ベースラインを上回る非常に単純な解決策。 """ # "cp"は胸痛の列です。 if row['cp'] == 2 and row['sex'] == 0: return 1 elif row['cp'] == 1 and row['sex'] == 0: return 1 else: return 0# パフォーマンスをチェックdf['pred'] = df.apply( lambda row: fast_track(row), axis=1)top_k_preds = df.sort_values('pred').tail(61)recall_at_k = len( top_k_preds .query('had_heart_attack == 1') .query(pred == 1))print(f"Recall@61 = {recall_at_k}")# 出力: Recall@61 = 50しかし、候補者が問題を明確に説明し、最大限に解決できる(k=61で完全な再現率を持つ)場合、ボーナスポイントが絶対に与えられます。
技術的な問題のフレーミングのインタビューの利点
技術的な問題のフレーミングのインタビューの主な利点は、合格し、採用された人々がより独立して作業できることです。改善のために与えられた目標を内面化できるため、マネージャーやプロダクトオーナーから必要とされるオーバーヘッドの作業量を減らすことができます。これは、特にPMのサポートが少なく、マネージャーがICであり、多くのプロジェクトを監督するための帯域幅が限られている小規模な組織で技術チームの影響力を拡大するために重要です。
たとえば、Fiのデータチームは非常に小さく、機動的であり続けることができましたが、これは強力な技術的な問題のフレーミング能力を持つ個人のみを採用してきたためです。現在、私たちはわずか4人(まもなく5人)のチームですが、100以上のビジネスのすべてのデータ関連のニーズを提供し、ETLプロセス、データウェアハウスの設計とメンテナンス、Tableauの報告、詳細な分析と原因究明、機械学習と予測モデリング、そして最近は新しい機能開発のためのR&Dをすべて担当しています。カバーしているドメインはビジネスのあらゆる側面です-財務、マーケティング、顧客体験、エンジニアリング、ハードウェア、ファームウェア、オペレーション、およびプロダクトです。私たちがそんなに多くの仕事を引き受け、多くのドメインをカバーできるのは、チームの全員が曖昧に定義された問題を取り上げ、それを技術的な問題の文にマッピングするスキルを持っているからです。
近日公開予定
もしマネージャーである場合、独自の技術的な問題のフレーミング能力を向上させる方法、およびチーム全体の能力を向上させる方法については、将来の投稿で詳しく説明しますので、お楽しみに。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
