「機械学習を利用した資産の健全性とグリッドの耐久性の向上」
Improving Asset Integrity and Grid Durability using Machine Learning
この投稿は、Travis BronsonとDuke EnergyのBrian L Wilkersonと共同で行われました。
機械学習(ML)は、あらゆる業界、プロセス、ビジネスを変革していますが、成功への道は常に直線的ではありません。このブログ投稿では、フォーチュン150にランクされる企業であるDuke Energyが、AWS Machine Learning Solutions Lab(MLSL)と協力して、コンピュータビジョンを使用して木製のユーティリティポールの検査を自動化し、停電、財産の損傷、さらにはけがを防止する方法を示しています。
電力グリッドは、ポール、ライン、発電所から成り、数百万の家庭や企業に電力を供給しています。これらのユーティリティポールは、重要なインフラコンポーネントであり、風、雨、雪などのさまざまな環境要因にさらされるため、資産の摩耗が起こる可能性があります。ユーティリティポールは定期的に検査・保守されることが重要であり、停電、財産の損傷、さらにはけがを引き起こす可能性のある故障を防ぐためです。Duke Energyを含むほとんどの電力会社は、ユーティリティポールの視覚的な手動検査を使用して、送電・配電ネットワークに関連する異常を特定しています。しかし、この方法は費用がかかり、時間がかかり、送電線路作業員が厳重な安全規定に従う必要があります。
Duke Energyは過去に人工知能を使用して日常業務の効率化を図り、大きな成功を収めてきました。同社はAIを使用して発電資産や重要なインフラの検査に活用しており、ユーティリティポールの検査にもAIを適用する機会を模索してきました。Duke EnergyとAWS Machine Learning Solutions Labの連携により、同社は高度なコンピュータビジョン技術を使用して木製ポールの異常検知を自動化する取り組みを進めました。
- 「Amazon Rekognition、Amazon SageMaker基盤モデル、およびAmazon OpenSearch Serviceを使用した記事のための意味論的画像検索」
- 「英語のアクセント分類のための機械学習パイプラインの構築」
- イクイノックスに会いましょう:ニューラルネットワークとsciMLのためのJAXライブラリ
目標とユースケース
Duke EnergyとMachine Learning Solutions Labの間のこの連携の目標は、機械学習を活用して数十万枚の高解像度航空画像を検査し、33,000マイルにわたる送電線路の木製ポールに関連する問題の同定およびレビュープロセスを自動化することです。この目標により、Duke Energyはグリッドの耐久性を向上させ、政府の規制に適合することができます。また、燃料や労働力のコストを削減し、不要なトラック出動を最小限に抑えることで、炭素排出量も削減することができます。最後に、走行距離や登攀ポール、地形や天候条件に関連する物理的な検査リスクを最小限に抑えることで、安全性も向上します。
次のセクションでは、木製ユーティリティポールに関連する異常検出のための堅牢かつ効率的なモデルの開発に関連する主要な課題を紹介します。また、望ましいモデルのパフォーマンスを達成するために使用されるさまざまなデータ前処理技術に関連する主要な課題と仮定についても説明します。次に、モデルのパフォーマンス評価に使用される主要なメトリクスと最終モデルの評価を紹介します。最後に、最先端の教師ありおよび教師なしモデリング技術を比較します。
課題
航空画像を使用して異常を検出するモデルをトレーニングする際の主要な課題の1つは、画像サイズの不均一性です。以下の図は、Duke Energyのサンプルデータセットの画像の高さと幅の分布を示しています。画像のサイズは非常に多様であることがわかります。同様に、画像のサイズも重要な課題です。入力画像のサイズは数千ピクセルの幅と数千ピクセルの長さです。これは、画像内の小さな異常領域の同定のためのモデルのトレーニングには理想的ではありません。

サンプルデータセットの画像の高さと幅の分布
また、入力画像には、植生、車両、農場の動物など、大量の関連しない背景情報が含まれています。背景情報は、モデルのパフォーマンスに悪影響を及ぼす可能性があります。評価に基づいて、画像のわずか5%に木製ポールが含まれ、異常領域はさらに小さくなります。高解像度画像での異常の同定と位置特定は、これらの課題に直面する大きな難関です。異常の数は、データセット全体に対して非常に少なく、全データセットの0.12%(つまり、1000枚の画像中の1.2つの異常)しかありません。最後に、教師あり機械学習モデルのトレーニングに使用できるラベル付きデータが存在しません。次に、これらの課題に対処する方法と提案された手法について説明します。
ソリューションの概要
モデリングの技術
以下の図は、画像処理と異常検出のパイプラインを示しています。まず、Amazon SageMaker Studioを使用してデータをAmazon Simple Storage Service(Amazon S3)にインポートしました。さらに、上記で強調されたいくつかの課題に対処するために、さまざまなデータ処理技術を採用し、モデルのパフォーマンスを向上させました。データの前処理後、Amazon Rekognition Custom Labelsを使用してデータラベリングを行いました。ラベル付きデータは、Vision Transformer、Amazon Lookout for Vision、および異常検出のためのAutoGlounなど、教師ありMLモデルのトレーニングに使用されます。

画像処理と異常検出のパイプライン
以下の図は、データ処理パイプラインと異常検出に使用される各種機械学習アルゴリズムを含む、提案手法の詳細な概要を示しています。まず、データ処理パイプラインに関与する手順について説明します。次に、この取り組みで達成するために使用される各種モデリングテクニックの詳細と直感について説明します。
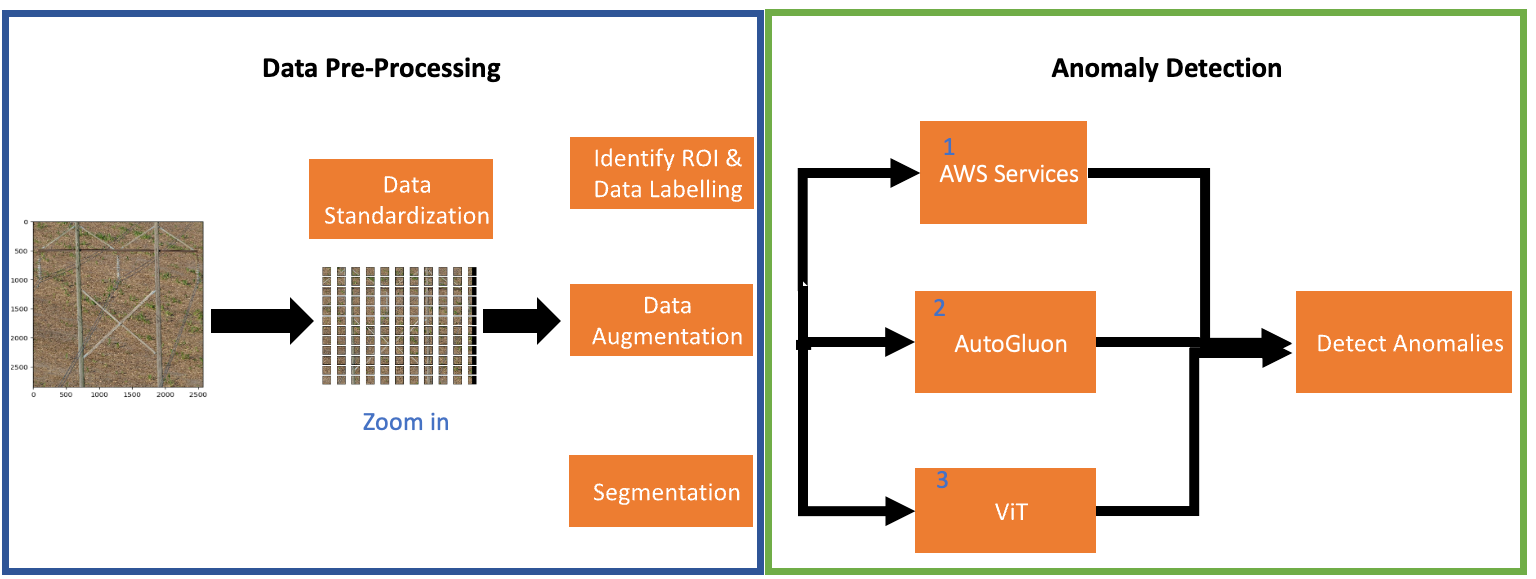
データ前処理
提案されたデータ前処理パイプラインには、データの標準化、関心領域(ROI)の識別、データの拡張、データのセグメンテーション、そして最後にデータラベリングが含まれています。各ステップの目的は以下の通りです。
データの標準化
データ処理パイプラインの最初のステップは、データの標準化です。このステップでは、各画像が224×224ピクセルの非重複パッチに切り取られます。このステップの目的は、一様なサイズのパッチを生成し、高解像度画像での異常の位置特定や機械学習モデルのトレーニングにさらに利用することです。
関心領域(ROI)の識別
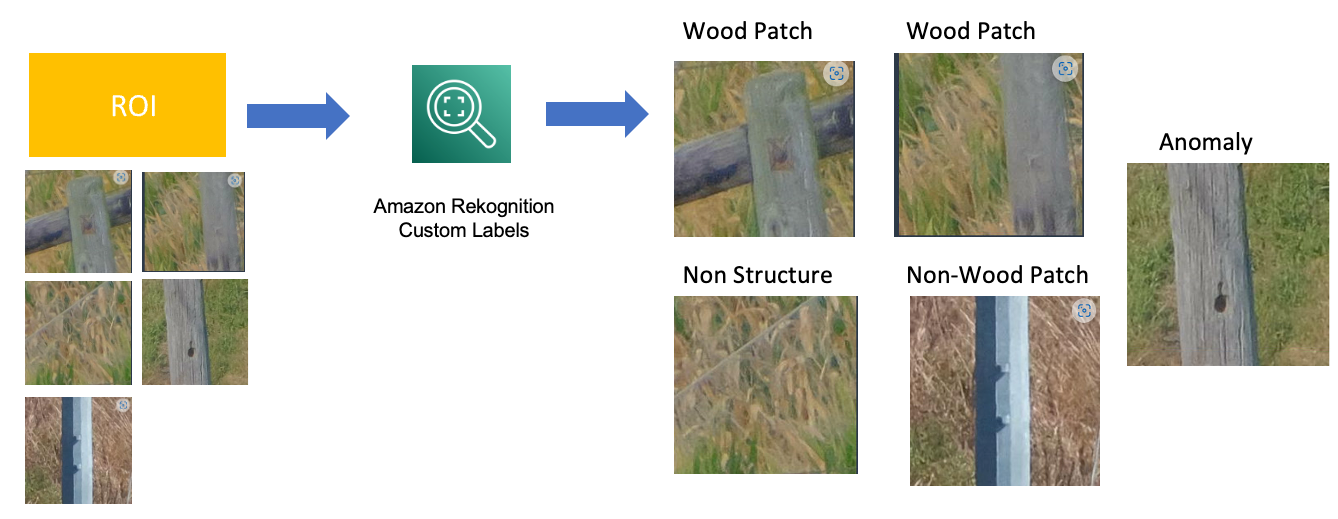
入力データには、(植生、家、車、馬、牛などの)関連性のない背景情報を含む高解像度の画像が含まれています。私たちの目標は、木製ポールに関連する異常を特定することです。ROI(木製ポールを含むパッチ)を特定するために、Amazon Rekognitionのカスタムラベリングを使用しました。ROIと背景画像の両方を含む3,000枚のラベル付き画像を使用して、Amazon Rekognitionのカスタムラベルモデルをトレーニングしました。モデルの目標は、ROIと背景画像の間でバイナリ分類を行うことです。背景情報として識別されたパッチは破棄され、ROIと予測されたクロップは次のステップで使用されます。以下の図はROIを特定するパイプラインを示しています。1,110枚の木製画像の非重複クロップのサンプルを生成し、244,673のクロップを生成しました。これらの画像をAmazon Rekognitionのカスタムモデルの入力として使用し、11,356のクロップをROIとして識別しました。最後に、これらの11,356のパッチを手動で検証しました。手動検査中、モデルは11,356のうち10,969枚の木製パッチを正しくROIとして予測することができました。つまり、モデルの精度は96%でした。

関心領域の特定
データラベリング
画像の手動検査中、各画像に関連するラベルを付けました。画像の関連するラベルには、木製パッチ、非木製パッチ、非構造物、非木製パッチ、最後に異常を持つ木製パッチが含まれます。以下の図は、Amazon Rekognitionのカスタムラベリングを使用して画像の命名規則を示しています。
データの拡張
トレーニングに使用できるラベル付きデータが限られていたため、すべてのパッチの水平反転を行い、トレーニングデータセットを拡張しました。これにより、データセットのサイズが2倍になる効果がありました。
セグメンテーション
Amazon Rekognitionのカスタムラベルを使用して、600枚の画像(ポール、ワイヤー、金属の手すり)のオブジェクトをラベリングし、興味のある3つの主要オブジェクトを検出するためのモデルをトレーニングしました。トレーニングされたモデルを使用して、すべての画像から背景を削除しました。つまり、各画像からポールを特定し、他のすべてのオブジェクトおよび背景を削除しました。結果として得られたデータセットは、元のデータセットよりも少ない画像を含んでおり、木製ポールを含まないすべての画像が削除されたためです。さらに、データセットから除外された誤検出画像もありました。
異常検知
次に、前処理済みのデータを使用して、異常検知のための機械学習モデルのトレーニングを行います。異常検知には、AWSマネージド機械学習サービス(Amazon Lookout for Vision [L4V]、Amazon Rekognition)、AutoGluon、およびVision Transformerベースの自己蒸留メソッドの3つの異なる方法を使用しました。
AWSサービス
Amazon Lookout for Vision (L4V)
Amazon Lookout for Visionは、管理されたAWSサービスであり、迅速な機械学習モデルのトレーニングと展開、異常検知の機能を提供します。完全にラベル付けされたデータが必要であり、Amazon S3の画像パスを指定して提供しました。モデルのトレーニングは、単一のAPI(アプリケーションプログラミングインターフェース)呼び出しまたはコンソールボタンクリックのように簡単であり、L4Vがモデルの選択とハイパーパラメータのチューニングを自動的に行います。
Amazon Rekognition
Amazon Rekognitionは、L4Vと同様の管理型AI/MLサービスであり、モデリングの詳細を隠し、画像分類、物体検出、カスタムラベリングなど多くの機能を提供します。組み込みモデルを使用して、以前に知られているエンティティに適用することも可能です(たとえば、ImageNetやその他の大規模なオープンデータセットから)。ただし、我々はDuke Energyが持つ特定の画像上でROI検出器および異常検出器のトレーニングにAmazon Rekognitionのカスタムラベル機能を使用しました。また、Amazon Rekognitionのカスタムラベルを使用して、各画像の木のポールに境界ボックスを配置するモデルのトレーニングも行いました。
AutoGluon
AutoGluonは、Amazonが開発したオープンソースの機械学習技術です。AutoGluonには、画像データへの簡単なトレーニングが可能なマルチモーダルコンポーネントが含まれています。我々はAutoGluon Multi-modalを使用して、ラベル付きの画像パッチに対してモデルをトレーニングし、異常を識別するためのベースラインを確立しました。
Vision Transformer
最もエキサイティングな新しいAIのブレイクスルーの多くは、最近の2つのイノベーションから生まれています:自己教師あり学習により、機械は無作為な未ラベルの例から学習することができます。また、Transformerにより、AIモデルは入力の特定の部分に重点を置くことができ、より効果的に推論することができます。両方の方法は、機械学習コミュニティの持続的な焦点となっており、私たちはこのプロジェクトでそれらを使用しました。
特に、Duke Energyの研究者との共同作業で、Amazon Sagemakerを使用して、事前学習された自己蒸留ViT(Vision Transformer)モデルを特徴抽出器として使用して、下流の異常検知アプリケーションを構築しました。事前学習された自己蒸留ビジョントランスフォーマーモデルは、Amazon S3に格納された大量のトレーニングデータを使用して、自己教師ありの方法でトレーニングされます。また、大規模なデータセット(例:ImageNet)で事前学習されたViTモデルの転移学習の機能を活用しました。これにより、数千のラベル付き画像のみを使用して、評価セットにおける再現率を83%達成しました。
評価指標
以下の図は、モデルの性能とその影響を評価するために使用される主要な指標を示しています。モデルの主な目標は、異常検知(つまり真陽性)を最大化し、誤検出(つまり画像中に木の穴がないのに誤って木の穴を識別すること)の回数を最小化することです。
異常が特定されると、技術者はそれらに対処することで将来の停電を防ぎ、政府の規制に準拠します。また、誤検知を最小限に抑えることにより、再度画像を調査する必要がなくなるという利点もあります。
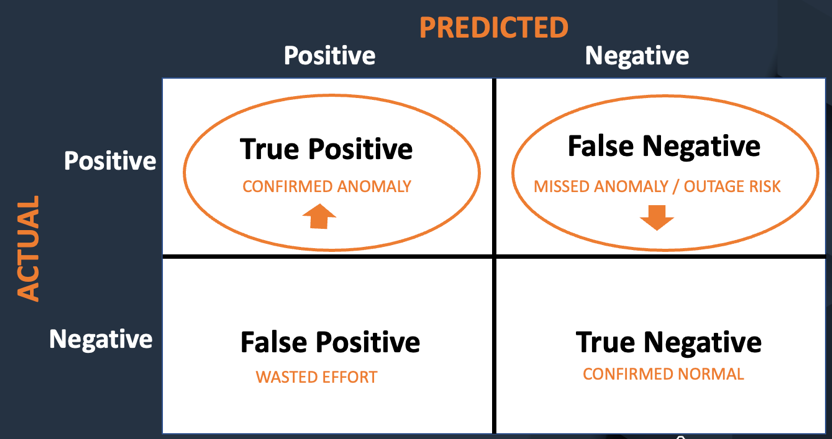
これらの指標を念頭に置いて、以下の指標でモデルのパフォーマンスを追跡しています。これらは、上記で定義された4つの指標を総合的に捉えています。
精度
興味の対象である異常を検出する割合です。精度は、アルゴリズムが異常のみを正確に識別する能力を測定します。このユースケースでは、高い精度は誤検出を低減することを意味します(つまり、画像に木の穴がないのにアルゴリズムが誤って木の穴を識別すること)。

再現率
各興味対象の全異常物の割合。リコールは、全ての異常をどれだけ正しく特定できるかを測定します。このセットは、全異常の一部の割合を捉え、その割合がリコールです。このユースケースでは、高いリコールは、キツツキの穴を発見するのが得意であることを意味します。リコールは、誤報が最高でも迷惑であり、見逃された異常は放置すると重大な結果につながる可能性があるため、このPOCでは注目すべき指標です。
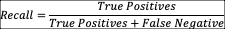
低いリコールは、停止や政府の規制違反につながる可能性があります。一方、低い精度は人的労力の浪費につながります。この取り組みの主な目標は、政府の規制を遵守し、停止を回避するために全ての異常を特定することであり、したがって精度よりもリコールの向上を優先します。
評価とモデルの比較
次のセクションでは、この取り組み中に使用されたさまざまなモデリング技術の比較を示します。私たちは、2つのAWSサービス、Amazon RekognitionとAmazon Lookout for Visionのパフォーマンスを評価しました。また、AutoGluonを使用したさまざまなモデリング技術も評価しました。最後に、最先端のViTベースの自己蒸留法とのパフォーマンスを比較します。
次の図は、この取り組みの期間において、AutoGluonのデータ処理技術の改善によるモデルの進化を示しています。重要な観察結果は、データの品質と量を改善すると、モデルのパフォーマンス(リコール)が30%未満から78%に向上することです。
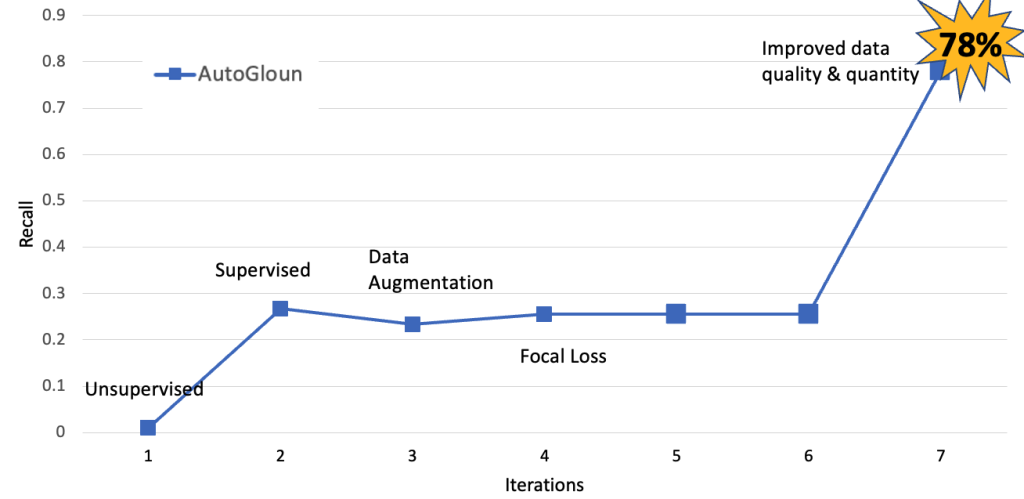
次に、AutoGluonのパフォーマンスをAWSサービスと比較します。また、パフォーマンスを向上させるためにさまざまなデータ処理技術を使用しました。ただし、最も大きな改善はデータの量と品質の向上からもたらされました。データセットのサイズを合計11,000枚から60,000枚に増やしました。
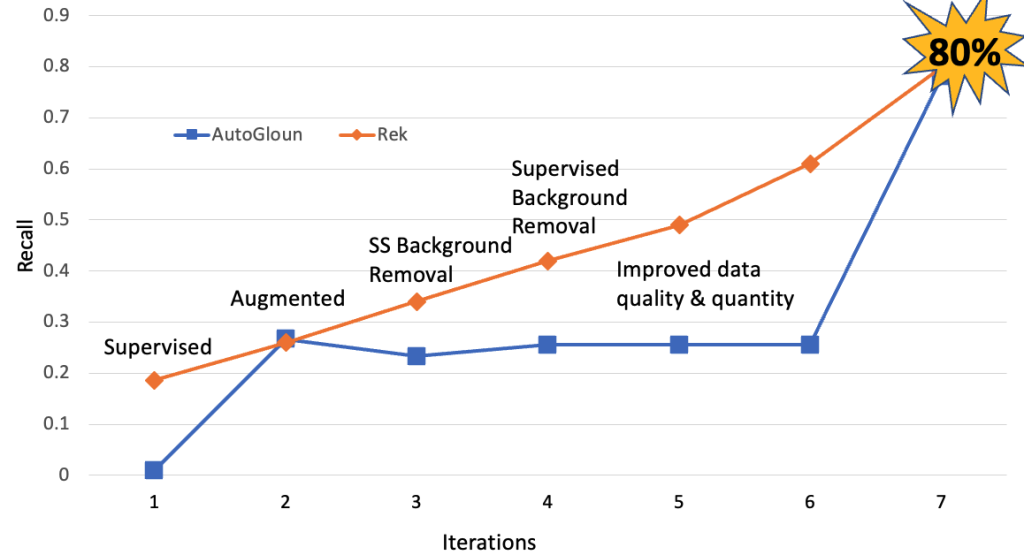
次に、AutoGluonとAWSサービスをViTベースの方法と比較します。次の図は、ViTベースの方法、AutoGluon、AWSサービスがリコールの面で同等のパフォーマンスを発揮していることを示しています。一つの重要な観察結果は、一定のポイントを超えると、データの品質と量の増加がリコールのパフォーマンスの向上に役立たなくなることです。ただし、精度の向上は観察されます。
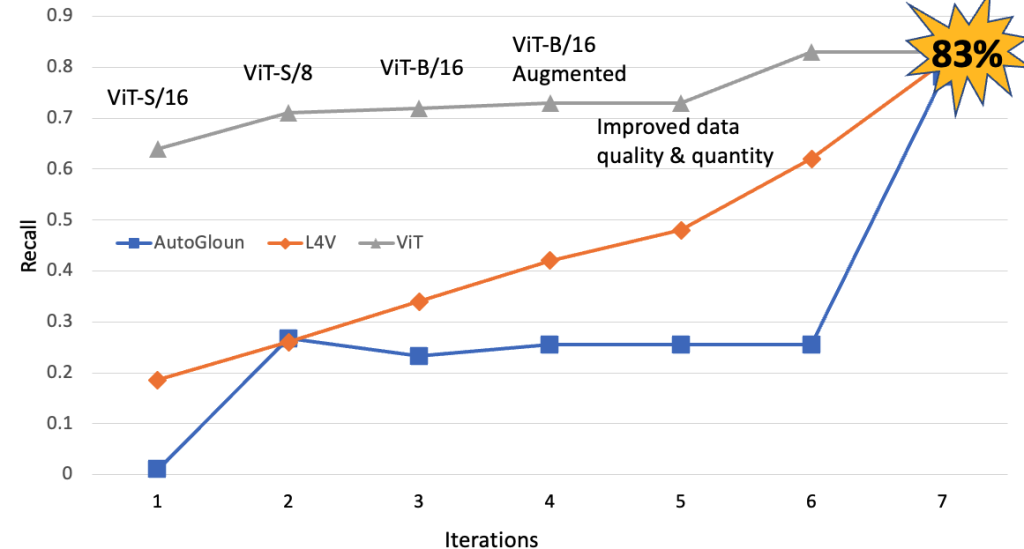
精度とリコールの比較
| Amazon AutoGluon | 予測された異常 | 予測された正常 |
| 異常 | 15600 | 4400 |
| 正常 | 3659 | 38341 |
次に、AutoGluonとAmazon Rekognition、およびViTベースの方法を使用して、62,000サンプルを含むデータセットを使用した混同行列を示します。62,000サンプルのうち、20,000サンプルが異常であり、残りの42,000枚の画像が正常です。観察すると、ViTベースの方法が最も多くの異常(16,600枚)をキャプチャしており、次にAmazon Rekognition(16,000枚)とAmazon AutoGluon(15,600枚)です。同様に、Amazon AutoGluonは最も少ない偽陽性(3659枚の画像)を持っており、次にAmazon Rekognition(5918枚)とViT(15323枚)です。これらの結果は、Amazon Rekognitionが最も高いAUC(曲線下面積)を達成していることを示しています。
| Amazon Rekognition | 予測された異常 | 予測された正常 |
| 異常 | 16,000 | 4,000 |
| 正常 | 5,918 | 36,082 |
| ViT | 予測された異常 | 予測された正常 |
| 異常 | 16,600 | 3,400 |
| 正常 | 15,323 | 26,677 |
結論
この記事では、MLSLとDuke Energyのチームが協力して、ヘリコプター飛行によって収集された高解像度画像を使用して、木製ポールの異常検出を自動化するコンピュータビジョンベースのソリューションを開発した方法を紹介しました。提案されたソリューションでは、データ処理パイプラインを使用して高解像度画像をサイズの標準化のために切り抜きます。切り抜かれた画像は、Amazon Rekognition Custom Labelsを使用して関心領域(つまり、ポールのパッチを含む切り抜き)を識別するためにさらに処理されます。Amazon Rekognitionは、ポールのパッチを正しく識別することにおいて96%の精度を達成しました。関心領域の切り抜きは、ViTベースの自己蒸留モデルAutoGluonとAWSサービスを使用して異常検出に使用されます。私たちは、すべての3つの方法のパフォーマンスを評価するために、標準データセットを使用しました。ViTベースのモデルは、83%の再現率と52%の精度を達成しました。AutoGluonは、78%の再現率と81%の精度を達成しました。最後に、Amazon Rekognitionは、80%の再現率と73%の精度を達成します。3つの異なる方法を使用する目的は、トレーニングサンプルの数、トレーニング時間、および展開時間が異なる場合の各方法のパフォーマンスを比較することです。これらのすべての方法は、単一のA100 GPUインスタンスまたはAmazon AWSの管理サービスを使用して、2時間未満でトレーニングおよび展開されます。モデルのパフォーマンスをさらに向上させるための次のステップは、モデル精度の向上のためにより多くのトレーニングデータを追加することです。
全体的に、この記事で提案されたエンドツーエンドのパイプラインは、異常検出の大幅な改善を実現し、運用コスト、安全事故、規制リスク、炭素排出量、および潜在的な停電を最小化します。
開発されたソリューションは、他の異常検出および資産健康関連のユースケースにも応用できます。これには、絶縁体やその他の機器の欠陥が含まれます。このソリューションを開発およびカスタマイズするためのさらなる支援については、MLSLチームにお気軽にお問い合わせください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「CityDreamerと出会う:無限の3D都市のための構成的生成モデル」
- Google AIは、高いベンチマークパフォーマンスを実現するために、線形モデルの特性を活用した長期予測のための高度な多変量モデル、TSMixerを導入します
- ジャクソン・ジュエットは、より少ないコンクリートを使用する建物の設計をしたいと考えています
- 「YaRNに会ってください:トランスフォーマーベースの言語モデルのコンテキストウィンドウを拡張するための計算効率の高い方法で、以前の方法よりもトークンが10倍少なく、トレーニングステップが2.5倍少なくて済みます」
- 「テンソル量子化:語られなかった物語」
- 「ステーブル拡散」は実際にどのように機能するのでしょうか?直感的な説明
- 「Amazon SageMaker Pipelinesを使用した機械学習ワークフローの構築のためのベストプラクティスとデザインパターン」






