「Amazon SageMaker Canvasによるデータ処理、トレーニング、推論におけるパフォーマンスを70%向上させ、ビジネスの成果を加速させましょう」
Improve performance by 70% in data processing, training, and inference with Amazon SageMaker Canvas, accelerating business outcomes.
Amazon SageMaker Canvasは、ビジネスアナリストが独自に正確な機械学習(ML)の予測を生成できるビジュアルインターフェースです。MLの経験は必要なく、1行のコードを書く必要もありません。SageMaker Canvasの直感的なユーザーインターフェースを使用すると、ビジネスアナリストはクラウド上またはオンプレミスで異なるデータソースを参照およびアクセスし、データを準備および探索し、MLモデルを構築およびトレーニングし、シングルワークスペース内で正確な予測を生成することができます。
SageMaker Canvasを使用すると、アナリストは異なるデータワークロードを使用して高い精度とパフォーマンスで目的のビジネス結果を達成できます。正確な予測を生成するための計算、ストレージ、メモリの要件はエンドユーザーから抽象化されており、彼らが解決すべきビジネスの問題に集中することができます。この記事では、SageMaker Canvasを使用して異なるデータセットのサイズに対して、データの処理、モデルのトレーニング、予測の生成を高速かつ効率的に行う方法を紹介します。
前提条件
この記事を実際に試す場合は、以下の前提条件を満たしてください:
- AWSアカウントを持っていること。
- SageMaker Canvasをセットアップしていること。手順については、Amazon SageMaker Canvasのセットアップの前提条件を参照してください。
- 以下の2つのデータセットをローカルコンピュータにダウンロードしてください。最初のデータセットは、NYCのイエロータクシーのトリップデータセットです。2番目のデータセットは、製品およびユーザーに関連する小売イベントに関するeコマースの行動データです。
両方のデータセットはAttribution 4.0 International(CC BY 4.0)ライセンスの下で提供されており、共有および適応することができます。
データ処理の改善
基礎となるパフォーマンスの最適化により、SageMaker Canvasへのデータのインポート時間が70%以上改善されました。現在、約50秒で2 GBまでのデータセットを、約65秒で5 GBまでのデータセットをインポートできます。
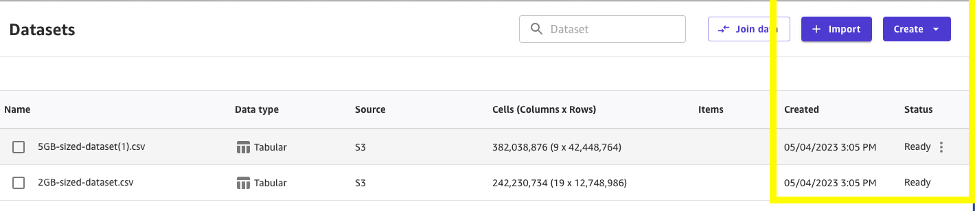
データのインポート後、ビジネスアナリストは通常、データセット内に問題がないことを検証します。例えば、列が正しいデータ型を持っていることを確認したり、値の範囲が予想と一致しているかどうかを確認したり、該当する場合に値の一意性を確認したり、その他の検証チェックを行うことができます。
データの検証は現在、より高速に行うことができます。テストでは、5 GBを超えるタクシーデータセットのすべての検証に50秒かかり、速度が10倍向上しました。
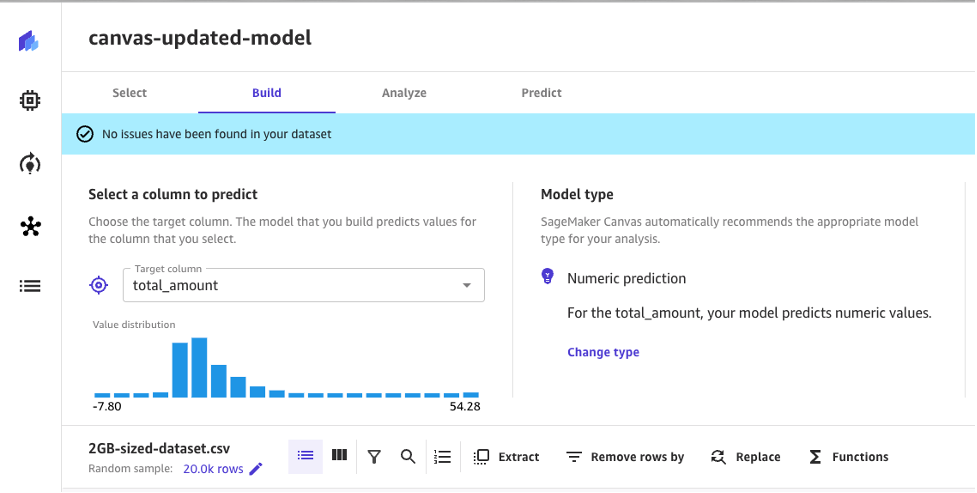
モデルトレーニングの改善
SageMaker CanvasにおけるMLモデルトレーニングに関連するパフォーマンスの最適化により、ポテンシャルなメモリリクエストの失敗を回避してモデルをトレーニングすることができるようになりました。
以下のスクリーンショットは、total_amountの特徴がターゲット変数に与える影響を示した大規模データセットを使用した成功したビルド実行の結果です。
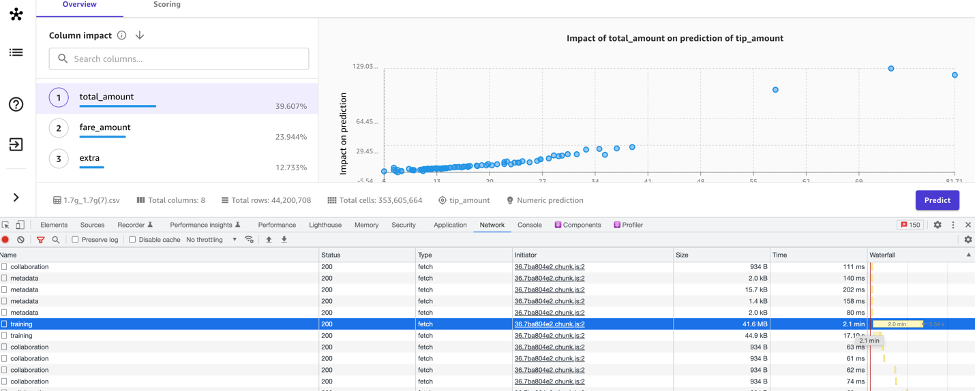
推論の改善
最後に、内部テストにおいて、SageMaker Canvasの推論の改善により、より大きなデータセットの場合のメモリ消費量が3.5倍に削減されました。
結論
この記事では、SageMaker Canvasにおけるインポート、検証、トレーニング、推論に関するさまざまな改善点を見ました。データセットの大規模なインポートは70%向上しました。データの検証は10倍速くなり、メモリ消費量は3.5倍減少しました。これらの改善により、SageMaker Canvasを使用して大規模なデータセットで作業し、MLモデルの構築にかかる時間を短縮することができます。
改善点を実際に体験していただくことをお勧めします。ユーザーエクスペリエンスを向上させるためのパフォーマンスの最適化に取り組んでいるので、フィードバックをお待ちしています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Excalidraw 図を使ってデータサイエンスで自分自身をより明確に表現する方法
- データの壁を破る:ゼロショット、ワンショット、およびフューショットラーニングが機械学習を変革している
- 「共通の悪いデータの10つのケースとその解決策を知る必要があります」
- 「ToolLLMをご紹介します:大規模言語モデルのAPI利用を向上させるためのデータ構築とモデルトレーニングの一般的なツールユースフレームワーク」
- 「データクリーニングと前処理の技術をマスターするための7つのステップ」
- 「LP-MusicCapsに会ってください:データの乏しさ問題に対処するための大規模言語モデルを使用したタグから疑似キャプション生成アプローチによる自動音楽キャプション作成」
- 「ゼロから効果的なデータ品質戦略を構築するためのステップバイステップガイド」
