「Amazon TextractとAmazon OpenSearchを使用してスマートなドキュメント検索インデックスを実装する」
Implementing a smart document search index using Amazon Textract and Amazon OpenSearch
巨大な契約書、請求書、履歴書、レポートなどの文書を扱う現代の企業にとって、効率的にデータを処理し、関連する情報を検索することは競争力を維持する上で重要です。しかし、伝統的な文書の保存と検索の方法は時間がかかり、特に手書きの場合は特定の文書を見つけるために大きな努力が必要です。もし、文書を知能的に処理し、高い精度で検索可能にする方法があったらどうでしょうか?
これは、Amazon TextractとAWSのインテリジェントドキュメント処理サービスを組み合わせ、OpenSearchの高速検索機能と組み合わせることで実現できます。この記事では、文書の検索インデックスソリューションを迅速に構築し、展開する方法について説明します。このソリューションにより、組織は文書からの洞察をより効果的に抽出して利用することができます。
人事部門が従業員契約の特定の条項を探している場合や、財務アナリストが多くの請求書を処理して支払いデータを抽出している場合、このソリューションは必要な情報に迅速かつ正確にアクセスできるようにするためにカスタマイズされています。
提案されたソリューションでは、文書は自動的に取り込まれ、その内容が解析され、高速かつスケーラブルなOpenSearchインデックスにインデックスされます。
Amazon Textract、AWS Lambda、Amazon Simple Storage Service(Amazon S3)、およびAmazon OpenSearch Serviceなどのテクノロジーを使用して、文書をシームレスに処理するワークフローを統合する方法、そしてこのデータをOpenSearchにインデックスし、指先で利用可能な検索機能をデモンストレーションします。
組織がデジタルトランスフォーメーション時代に最初のステップを踏んでいる場合または情報検索を高速化するためにすでに確立された大手企業である場合、このガイドはAWSのインテリジェントドキュメント処理とOpenSearchが提供する機会を探索するための指南書です。
この記事で使用されている実装は、Amazon Textract IDP CDKコンストラクトを利用しています。IDP CDKコンストラクトは、インテリジェントドキュメント処理(IDP)ワークフローのインフラストラクチャを定義するためのAWS Cloud Development Kit(CDK)コンポーネントであり、ユースケース固有のカスタマイズ可能なIDPワークフローを構築することができます。IDP CDKコンストラクトとサンプルは、AWS上でIDPプロセスを定義し、GitHubに公開するためのコンポーネントのコレクションです。主な使用されるコンセプトは、AWS Cloud Development Kit(CDK)コンストラクト、実際のCDKスタック、およびAWS Step Functionsです。ワークショップ “スケールでドキュメントを自動化および処理するために機械学習を利用する” は、ワークフローのカスタマイズ方法や他のサンプルワークフローを自分自身の基盤とするための出発点として、より詳細な情報を学ぶための良いスタート地点です。
ソリューションの概要
このソリューションでは、情報と文書のクイック検索と取得のために文書をOpenSearchインデックスにインデックスすることに焦点を当てています。PDF、TIFF、JPEG、PNG形式の文書は、Amazon Simple Storage Service(Amazon S3)バケットに配置され、このStep Functionsワークフローを使用してOpenSearchにインデックスされます。
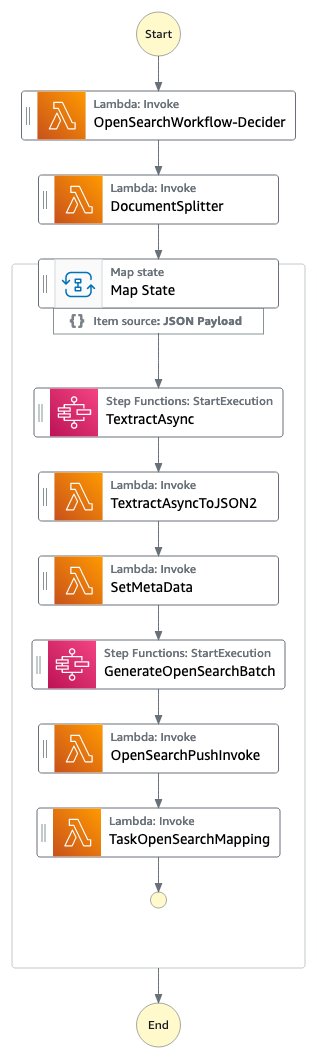
図1:Step Functions OpenSearchワークフロー
OpenSearchWorkflow-Deciderは、文書を確認し、サポートされているMIMEタイプ(PDF、TIFF、PNG、JPEG)の1つであることを検証します。これには1つのAWS Lambda関数が含まれています。
DocumentSplitterは、文書から最大2500ページのチャンクを生成します。つまり、Amazon Textractは最大3000ページの文書をサポートしているにもかかわらず、より多くのページを含む文書を渡すことができ、プロセスは正常に機能し、ページをOpenSearchに配置し、正しいページ番号を作成します。DocumentSplitterは、AWS Lambda関数として実装されています。
Map Stateは、各チャンクを並列で処理します。
TextractAsyncタスクは、非同期のApplication Programming Interface(API)を使用してAmazon Textractを呼び出し、Amazon Simple Notification Service(Amazon SNS)の通知とOutputConfigを使用してAmazon TextractのJSON出力をカスタマーのAmazon S3バケットに保存します。これには2つのAmazon Lambda関数が含まれています:処理のためのドキュメントを送信するための1つと、Amazon SNSの通知によってトリガーされるものです。
TextractAsyncタスクは複数のページネーションされた出力ファイルを生成することができるため、TextractAsyncToJSON2プロセスではそれらを1つのJSONファイルに結合します。
Step Functionsコンテキストには、OpenSearchインデックスで検索可能な情報も含まれています。SetMetaDataステップでは、サンプルの実装ではORIGIN_FILE_NAME、START_PAGE_NUMBER、およびORIGIN_FILE_URIが追加されます。バックエンドシステムからの情報、特定のIDや分類情報など、検索エクスペリエンスを豊かにするための任意の情報を追加できます。
GenerateOpenSearchBatchは、生成されたAmazon Textractの出力JSONを取り、SetMetaDataによって設定されたコンテキストの情報と組み合わせて、OpenSearchへのバッチインポートに最適化されたファイルを準備します。
OpenSearchPushInvokeでは、このバッチインポートファイルがOpenSearchインデックスに送信され、検索が可能になります。このAWS Lambda関数は、AWS Solutionsライブラリのaws-lambda-opensearchコンストラクトと接続されており、m6g.large.searchインスタンス、OpenSearchバージョン2.7、およびAmazon Elastic Block Service(Amazon EBS)ボリュームサイズをGeneral Purpose 2(GP2)に構成し、200 GBに設定されています。OpenSearchの構成は、必要に応じて変更することができます。
最終的なTaskOpenSearchMappingステップでは、コンテキストをクリアします。これにより、タスク、状態、または実行の最大入力または出力サイズのステップ関数クォータを超えることがなくなります。
前提条件
サンプルを展開するには、AWSアカウント、AWS Cloud Development Kit(AWS CDK)、現行のPythonバージョン、およびDockerが必要です。AWS CloudFormationテンプレートを展開する権限、Amazon Elastic Container Registry(Amazon ECR)へのプッシュ権限、Amazon Identity and Access Management(AWS IAM)ロール、Amazon Lambda関数、Amazon S3バケット、Amazon Step Functions、Amazon OpenSearchクラスタ、およびAmazon Cognitoユーザープールを作成する権限が必要です。AWS CLI環境が適切な権限でセットアップされていることを確認してください。
デプロイを開始するために、AWS CDK、Python、およびDockerが事前にインストールされたAWS Cloud9インスタンスを立ち上げることもできます。
手順
デプロイ
- 前提条件を設定した後、まずリポジトリをクローンします:
git clone https://github.com/aws-solutions-library-samples/guidance-for-low-code-intelligent-document-processing-on-aws.git- 次に、リポジトリフォルダに移動して依存関係をインストールします:
cd guidance-for-low-code-intelligent-document-processing-on-aws/
pip install -r requirements.txt- OpenSearchWorkflowスタックをデプロイします:
cdk deploy OpenSearchWorkflowデフォルトの設定でGitHubのサンプルからデプロイすると、デプロイには約25分かかり、Step Functionsワークフローが作成されます。このワークフローは、Amazon S3バケット/プレフィックスにドキュメントが配置されると呼び出され、その後、ドキュメントの内容がOpenSearchクラスタにインデックスされるまで処理されます。
以下は、cdk deploy OpenSearchWorkflowコマンドから生成された便利なリンクと情報を含むサンプル出力です:
OpenSearchWorkflow.CognitoUserPoolLink = https://us-east-1.console.aws.amazon.com/cognito/v2/idp/user-pools/us-east-1_1234abcdef/users?region=us-east-1
OpenSearchWorkflow.DocumentQueueLink = https://us-east-1.console.aws.amazon.com/sqs/v2/home?region=us-east-1#/queues/https%3A%2F%2Fsqs.us-east-1.amazonaws.com%2F123412341234%2FOpenSearchWorkflow-ExecutionThrottleDocumentQueueABC1234-ABCDEFG1234.fifo
OpenSearchWorkflow.DocumentUploadLocation = s3://opensearchworkflow-opensearchworkflowbucketabcdef1234/uploads/
OpenSearchWorkflow.OpenSearchDashboard = https://search-idp-cdk-opensearch-abcdef1234.us-east-1.es.amazonaws.com/states/_dashboards
OpenSearchWorkflow.OpenSearchLink = https://us-east-1.console.aws.amazon.com/aos/home?region=us-east-1#/opensearch/domains/idp-cdk-opensearch
OpenSearchWorkflow.StepFunctionFlowLink = https://us-east-1.console.aws.amazon.com/states/home?region=us-east-1#/statemachines/view/arn:aws:states:us-east-1:123412341234:stateMachine:OpenSearchWorkflow12341234この情報は、AWS CloudFormationコンソールでも利用できます。
OpenSearchWorkflow.DocumentUploadLocationに新しいドキュメントが配置されると、このドキュメントに対して新しいStep Functionsワークフローが開始されます。
このドキュメントのステータスをチェックするには、OpenSearchWorkflow.StepFunctionFlowLinkを使用してAWS Management ConsoleのStepFunction実行のリストにアクセスし、Amazon S3にアップロードされた各ドキュメントの処理状況を表示します。Step Functionsコンソールでの実行の表示とデバッグに関するチュートリアルでは、AWSコンソールのコンポーネントとビューについて概説しています。
テスト
- サンプルファイルを使用した最初のテスト。
aws s3 cp s3://amazon-textract-public-content/idp-cdk-samples/moby-dick-hidden-paystub-and-w2.pdf $(aws cloudformation list-exports --query 'Exports[?Name==`OpenSearchWorkflow-DocumentUploadLocation`].Value' --output text)- ステップ関数ワークフローへのリンクを選択するか、AWS Management Consoleに移動してステップ関数サービスページを開くと、異なるワークフロー呼び出しを確認することができます。
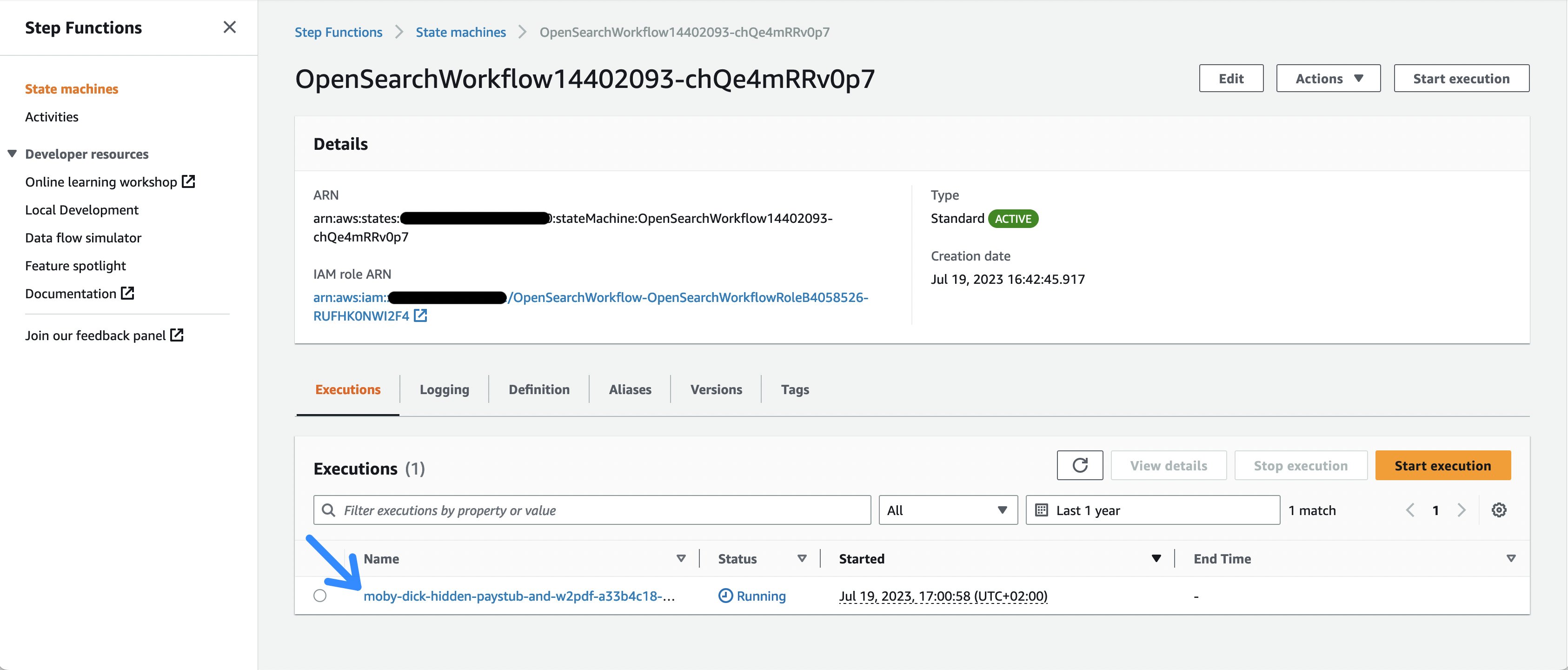
図2: ステップ関数の実行リスト
- 現在実行中のサンプルドキュメント実行を確認し、個々のワークフロータスクの実行を追跡できます。
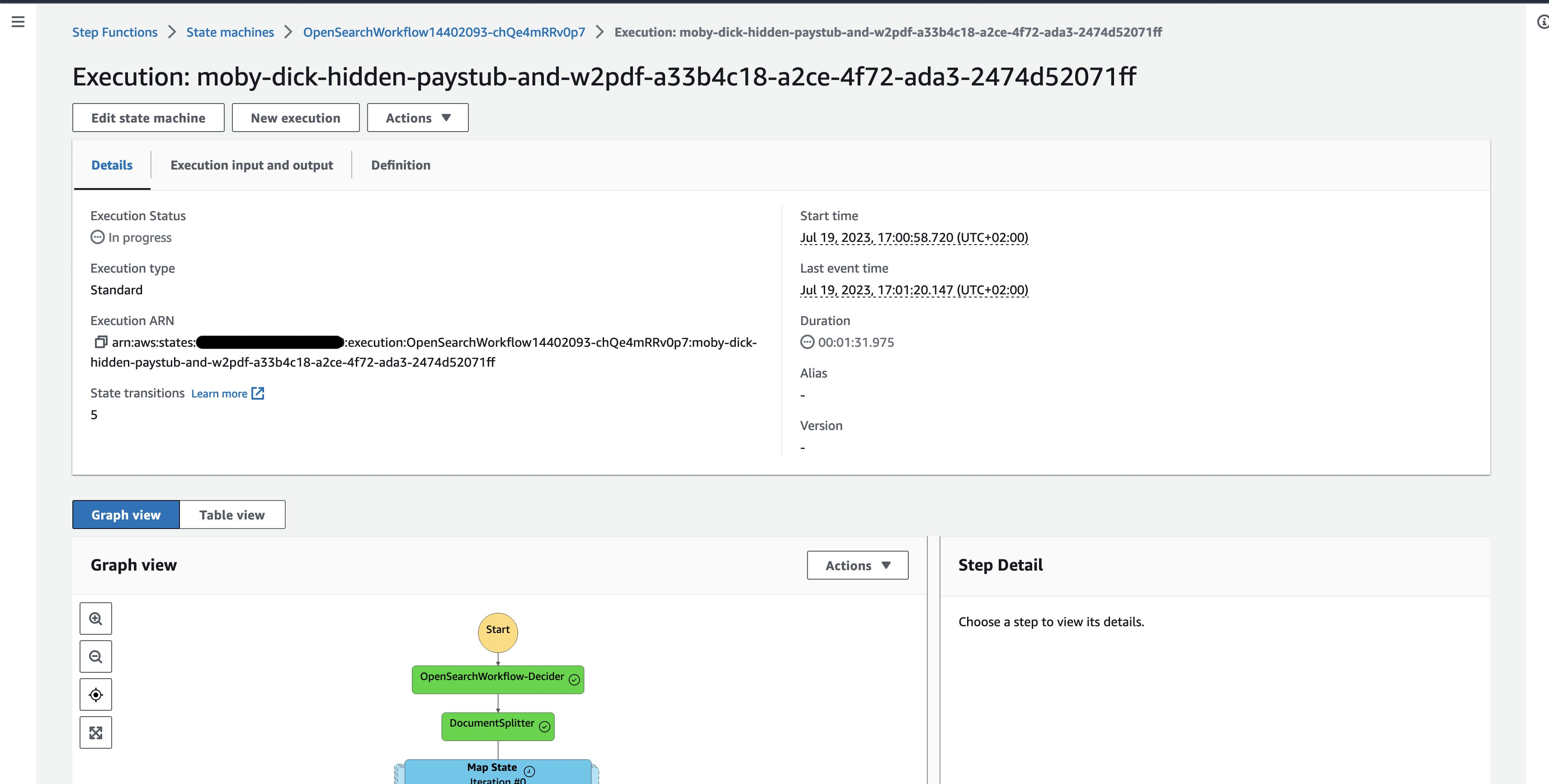
図3: 1つのドキュメントステップ関数ワークフローの実行
検索
プロセスが完了したら、ドキュメントがOpenSearchインデックスにインデックスされていることを検証できます。
- そのためには、まずAmazon Cognitoユーザーを作成します。Amazon Cognitoは、ユーザーのOpenSearchインデックスへの認証に使用されます。cdk deployからの出力のリンク(またはAWS Management ConsoleのAWS CloudFormation出力)であるOpenSearchWorkflow.CognitoUserPoolLinkを選択します。
図4: Cognitoユーザープール
- 次に、Create userボタンを選択し、OpenSearchダッシュボードへのアクセスのためのユーザー名とパスワードを入力するページに移動します。
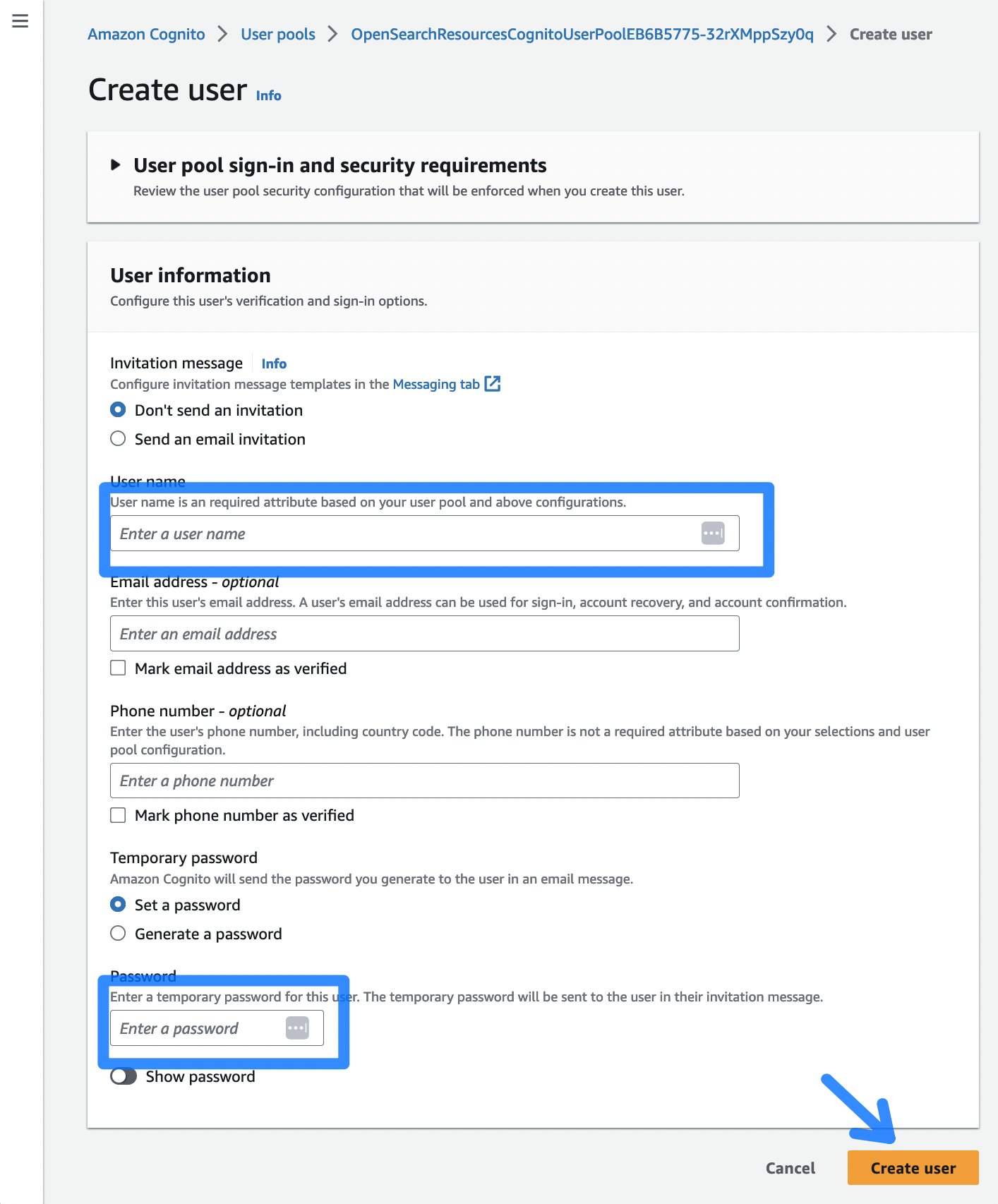
図5: Cognitoユーザー作成ダイアログ
- Create userを選択した後、CDKデプロイの出力からOpenSearchWorkflow.OpenSearchDashboardをクリックしてOpenSearchダッシュボードに進むことができます。以前に作成したユーザー名とパスワードを使用してログインします。初回ログイン時にパスワードを変更する必要があります。
- OpenSearchダッシュボードにログインしたら、Stack Managementセクションを選択し、Index Patternを選択して検索インデックスを作成します。
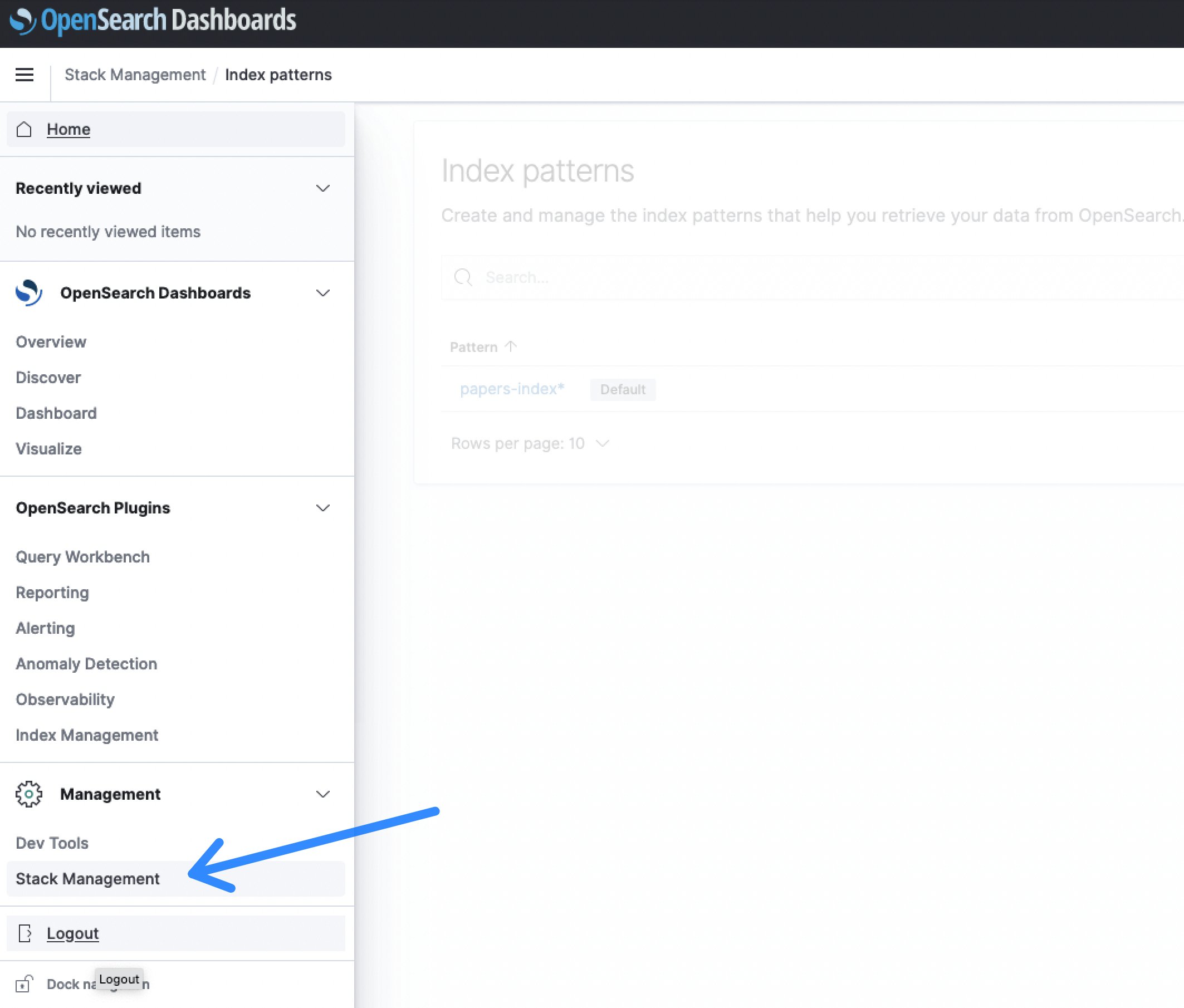
図6: OpenSearchダッシュボードのStack Management
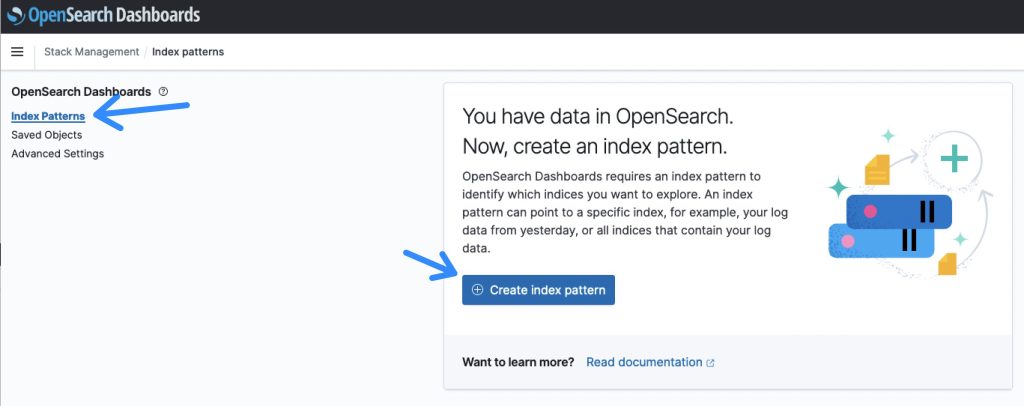
図7: OpenSearchインデックスパターンの概要
- インデックスのデフォルト名はpapers-indexであり、インデックスパターン名papers-index*はそれに一致します。
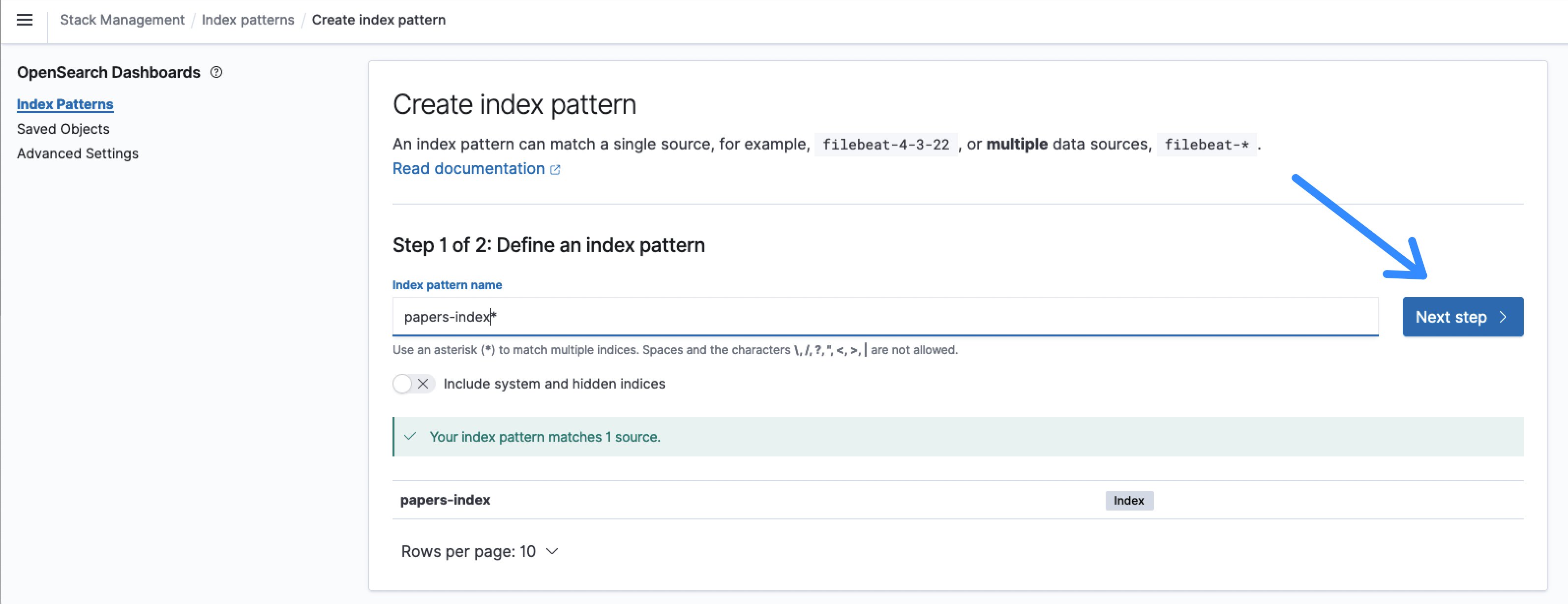
図8:OpenSearchインデックスパターンの定義
- 次のステップをクリックした後、タイムスタンプをタイムフィールドとして選択し、インデックスパターンを作成します。
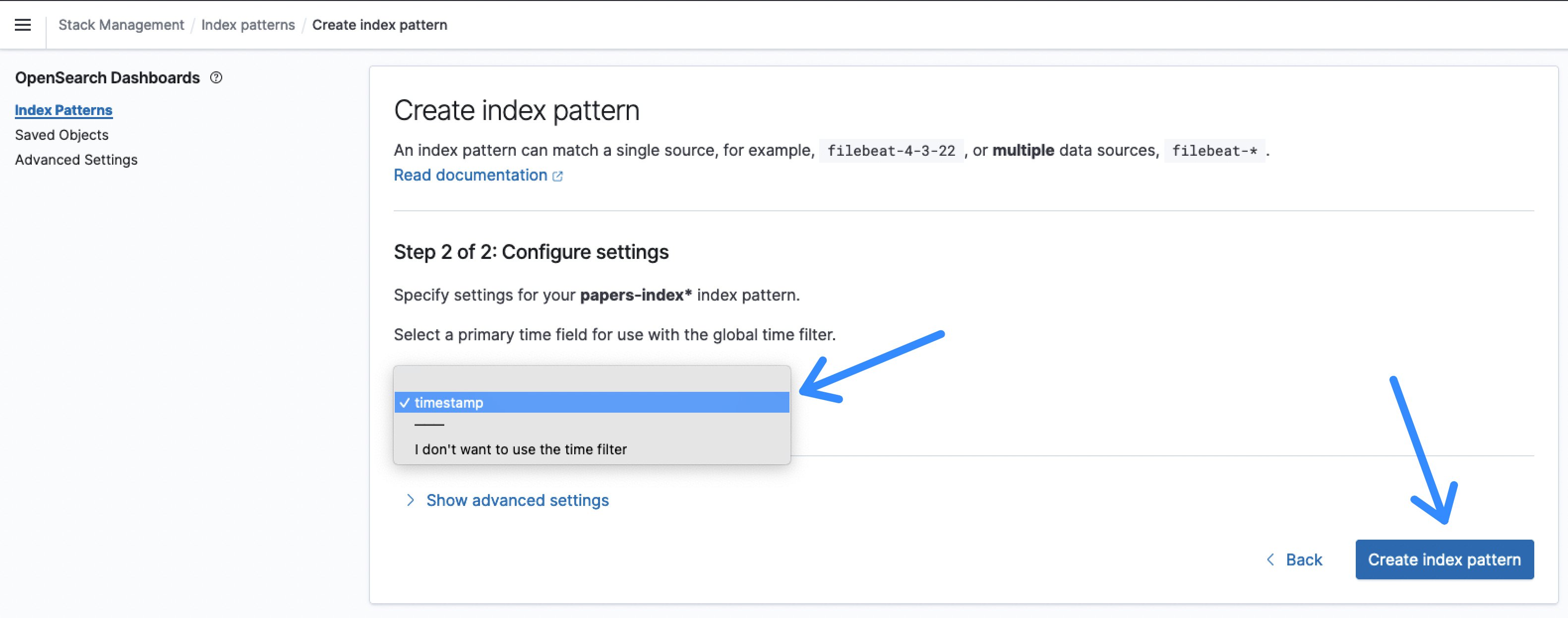
図9:OpenSearchインデックスパターンのタイムフィールド
- メニューからDiscoverを選択します。
図10:OpenSearch Discover
ほとんどの場合、最後の読み込みに合わせて時間範囲を変更する必要があります。デフォルトは15分であり、最後の15分間にアクティビティがなかったことがよくあります。この例では、15日に変更してインデックスを可視化しました。
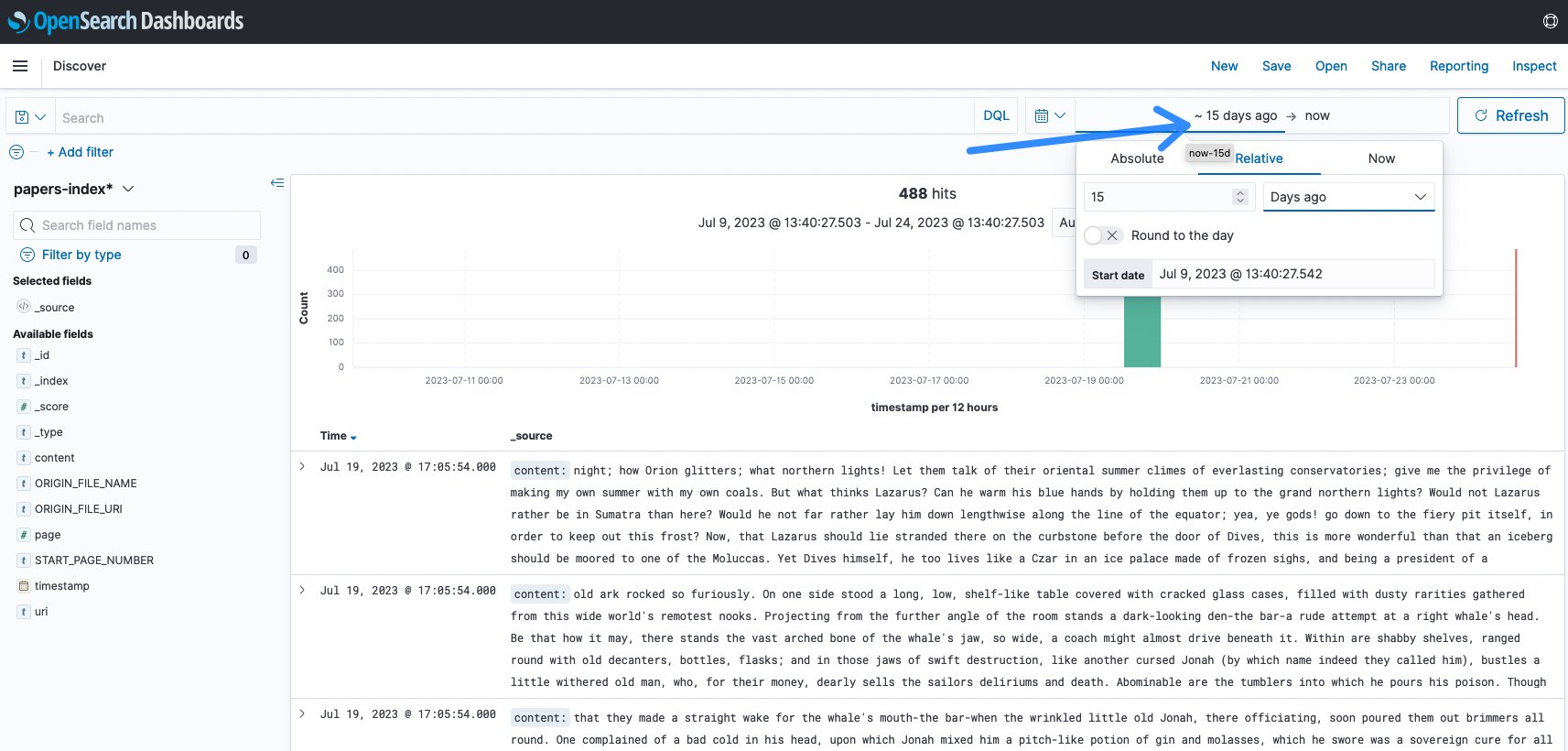
図11:OpenSearchの時間範囲変更
- これで検索を開始できます。小説がインデックスされており、call me Ishmaelのような任意の用語を検索して結果を表示できます。
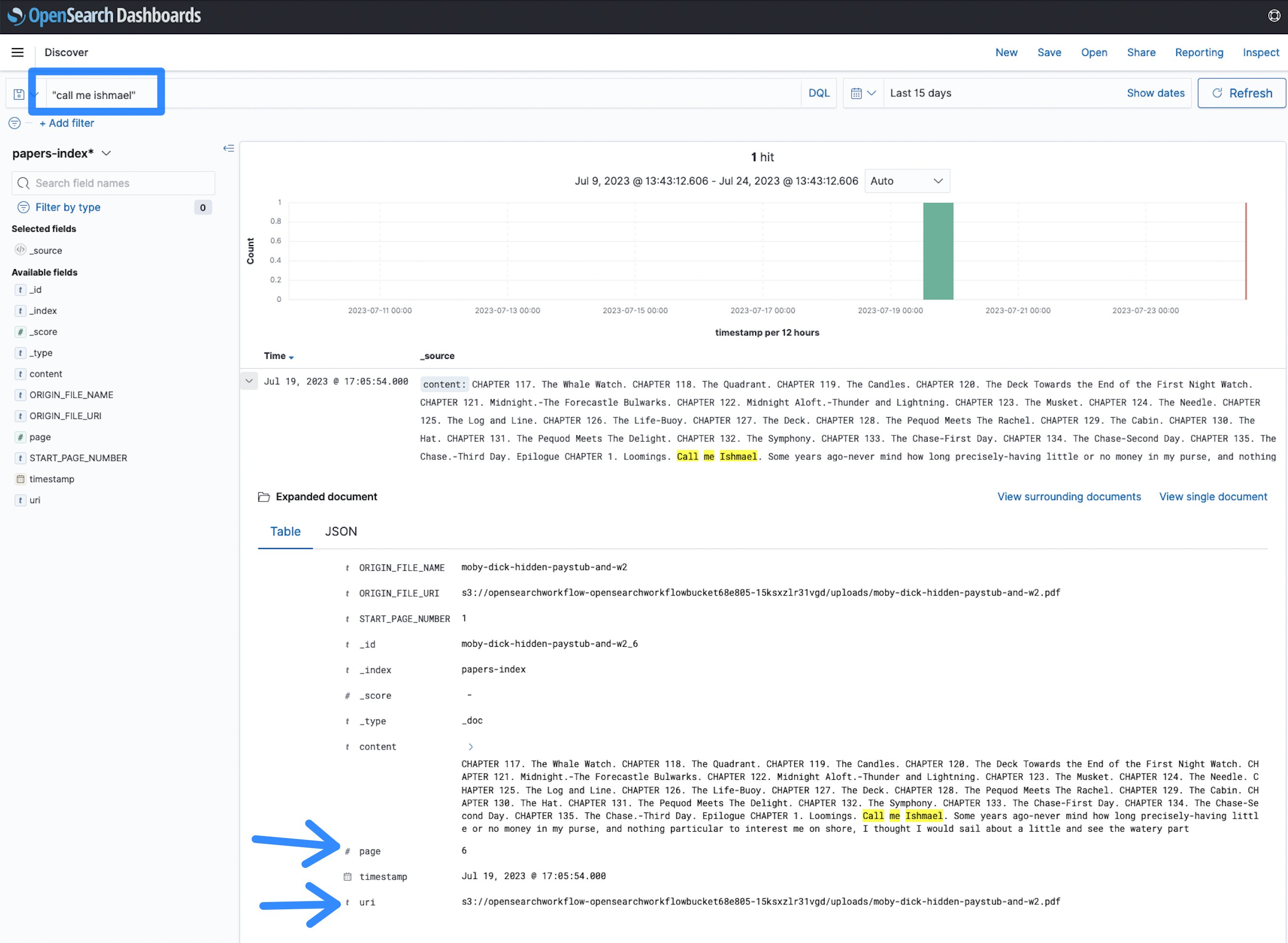
図12:OpenSearchの検索用語
この場合、用語call me Ishmaelはドキュメントの6ページ目に表示されます。これは与えられたUniform Resource Identifier(URI)であり、このURIはファイルのAmazon S3の場所を指します。これにより、手動でスキップするよりも、PDF、TIFF、または画像ドキュメントの大規模なコーパス全体でドキュメントを特定し、情報を見つける速度が向上します。
スケールでの実行
インデックス作成プロセスのスケールと所要時間を推定するために、実装は93,997のドキュメントと合計1,583,197ページ(平均16.84ページ/ドキュメント、最大のファイルは3755ページ)でテストされ、すべてがOpenSearchにインデックスされました。すべてのファイルを処理してOpenSearchにインデックスするのに5.5時間かかりました。これは、デフォルトのAmazon Textractサービスのクォータを使用して、米国東部(バージニア北部 – us-east-1)リージョンで行われました。以下のグラフは、18:00に初期テストが行われ、21:00にメインのインジェストが行われ、すべてが2:30まで完了したことを示しています。
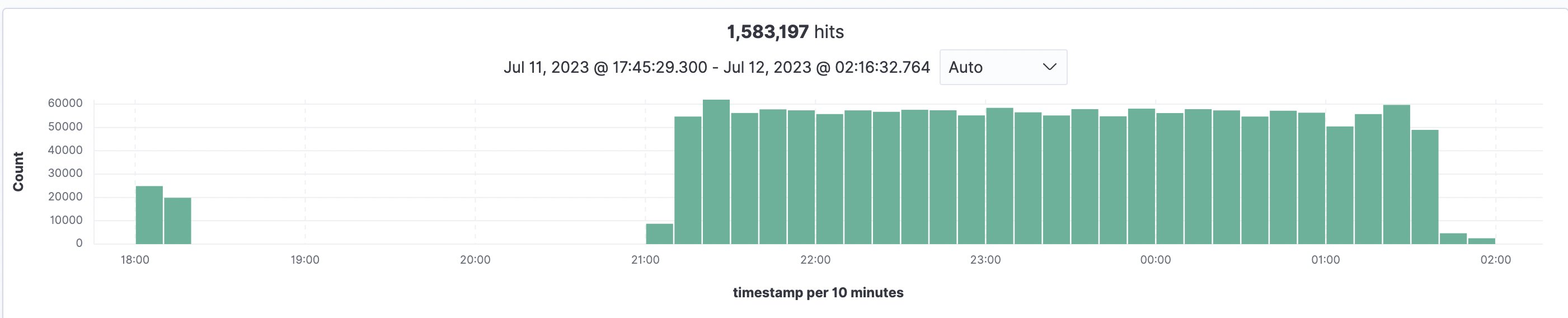
図13:OpenSearchインデックス作成の概要
処理には、tcdk.SFExecutionsStartThrottleがexecutions_concurrency_threshold=550に設定されました。これは、同時に処理されるドキュメントワークフローが550に制限され、余剰のリクエストがAmazon SQSの先入先出(FIFO)キューにキューイングされ、現在のワークフローが完了すると順次処理されます。550のしきい値は、us-east-1リージョンのTextractサービスのクォータが600であるためです。したがって、キューの深さと最も古いメッセージの年齢は、監視する価値があるメトリクスです。
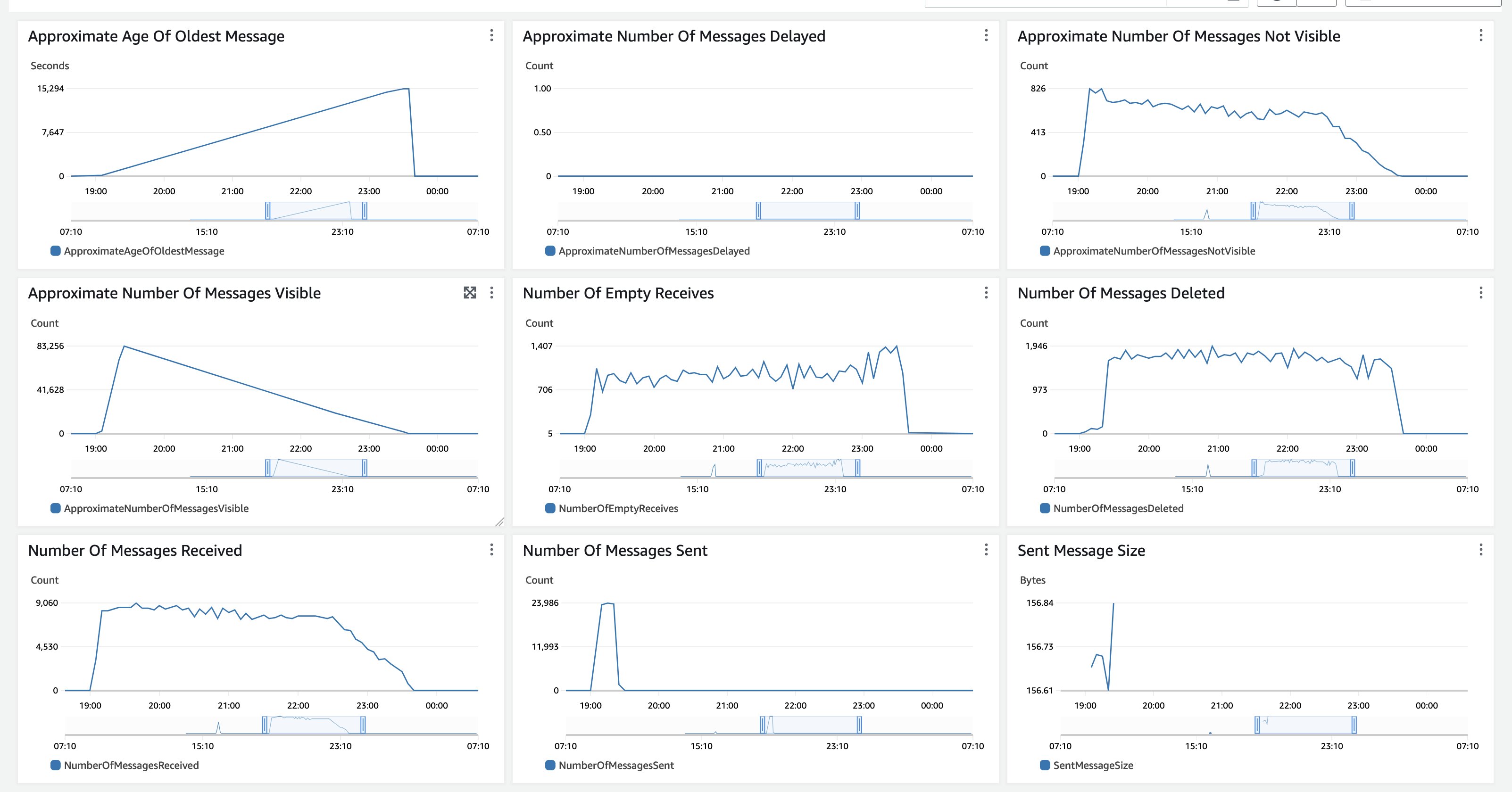
図14:Amazon SQSのモニタリング
このテストでは、すべてのドキュメントが一度にAmazon S3にアップロードされたため、Approximate Number of Messages Visibleは急激に増加し、新しいドキュメントがインジェストされなくなるとゆっくりと減少します。また、Approximate Age Of Oldest Messageは、すべてのメッセージが処理されるまで増加します。 Amazon SQSのMessageRetentionPeriodは14日に設定されています。処理時間が14日を超える可能性のある非常に長いバックログ処理の場合は、最初に代表的なドキュメントのサブセットを処理し、実行時間を監視して14日を超える前に渡すことができるドキュメントの数を推定します。 Amazon SQSのCloudWatchメトリクスは、一度にインジェストされ、完全に処理される大量のドキュメントを処理するユースケースに対しても同様のものです。ユースケースがドキュメントの着実な流れである場合、Approximate Number of Messages VisibleおよびApproximate Age Of Oldest Messageの両方のメトリクスはより直線的になります。また、しきい値パラメータを使用して安定した負荷とバックログ処理を混在させ、処理のニーズに応じて容量を割り当てることもできます。
モニタリングする別のメトリクスは、Amazon OpenSearch ServiceのOperational best practicesに従って設定するべきOpenSearchクラスタの健全性です。デフォルトのデプロイメントでは、m6g.large.searchインスタンスが使用されます。
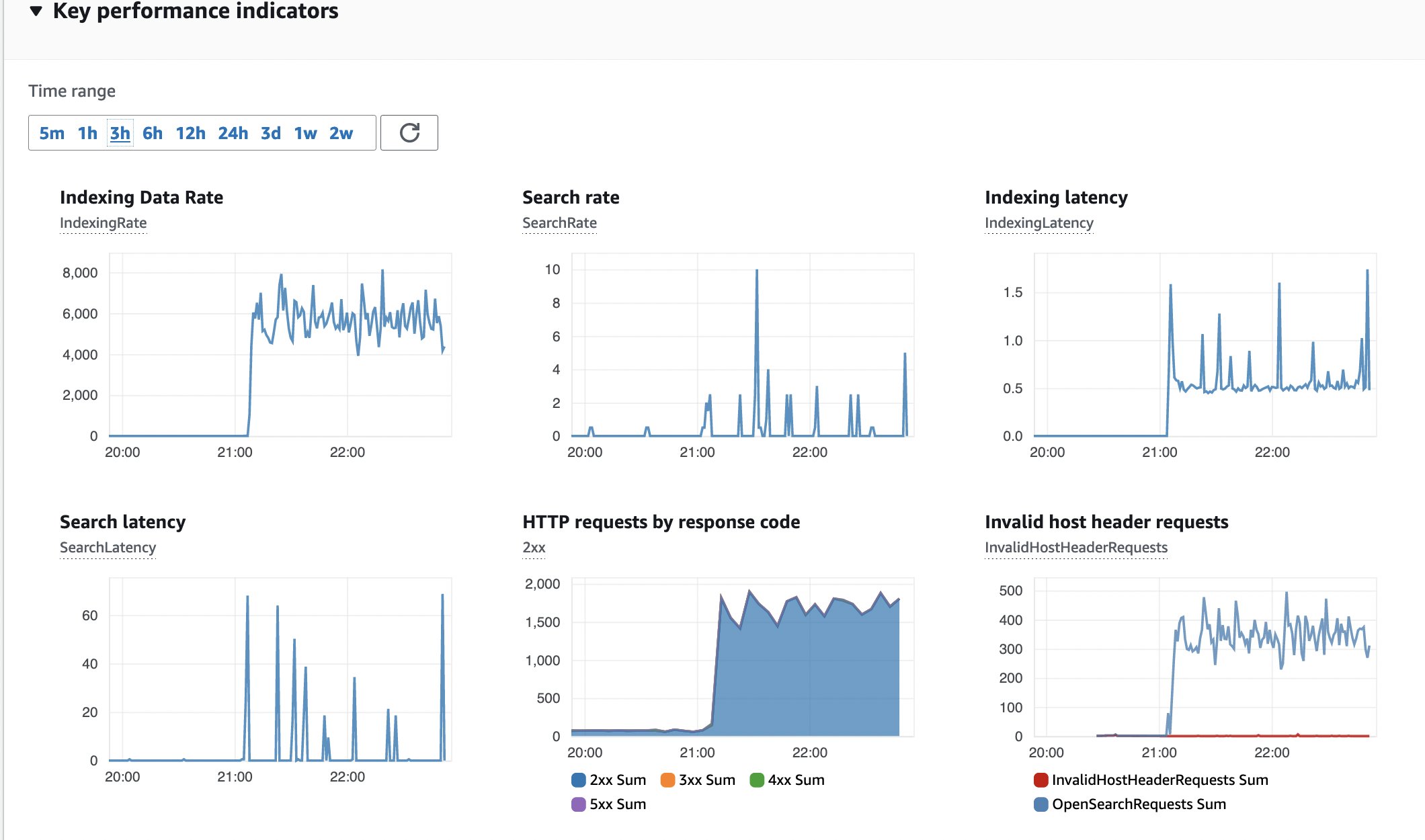
図15:OpenSearchのモニタリング
以下は、OpenSearchクラスタのキーパフォーマンス指標(KPI)のスナップショットです。エラーはなく、インデックスデータのレートとレイテンシが一定です。
Step Functionsのワークフロー実行は、各個々のドキュメントの処理状態を示しています。もしFailed状態の実行がある場合は、詳細を選択してください。Step FunctionsのCloudWatchメトリクスの一部を公開するAWS CloudWatch Automatic Dashboard for Step Functionsは、モニタリングするのに適したメトリクスです。
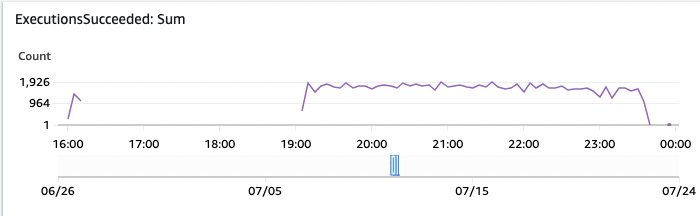
図16:Step Functionsのモニタリング実行が成功したもの
このAWS CloudWatchダッシュボードのグラフでは、時間の経過とともに成功したStep Functionsの実行が表示されます。
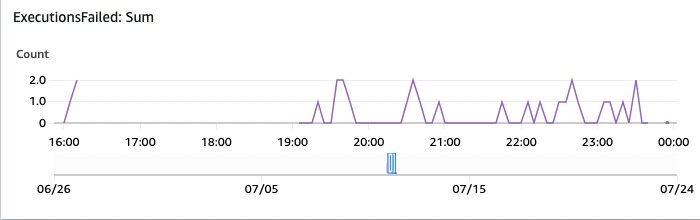
図17:OpenSearchのモニタリング実行が失敗したもの
そして、これは失敗した実行を示しています。これらはAWSコンソールのStep Functionsの概要を通じて調査する価値があります。
以下のスクリーンショットは、原因ファイルがサイズ0のために失敗した実行の例を示しています。これはファイルにコンテンツがなく、処理できなかったためです。失敗したプロセスをフィルタリングし、失敗を可視化することは重要です。そうすることで、ソースドキュメントに戻り、原因を検証することができます。
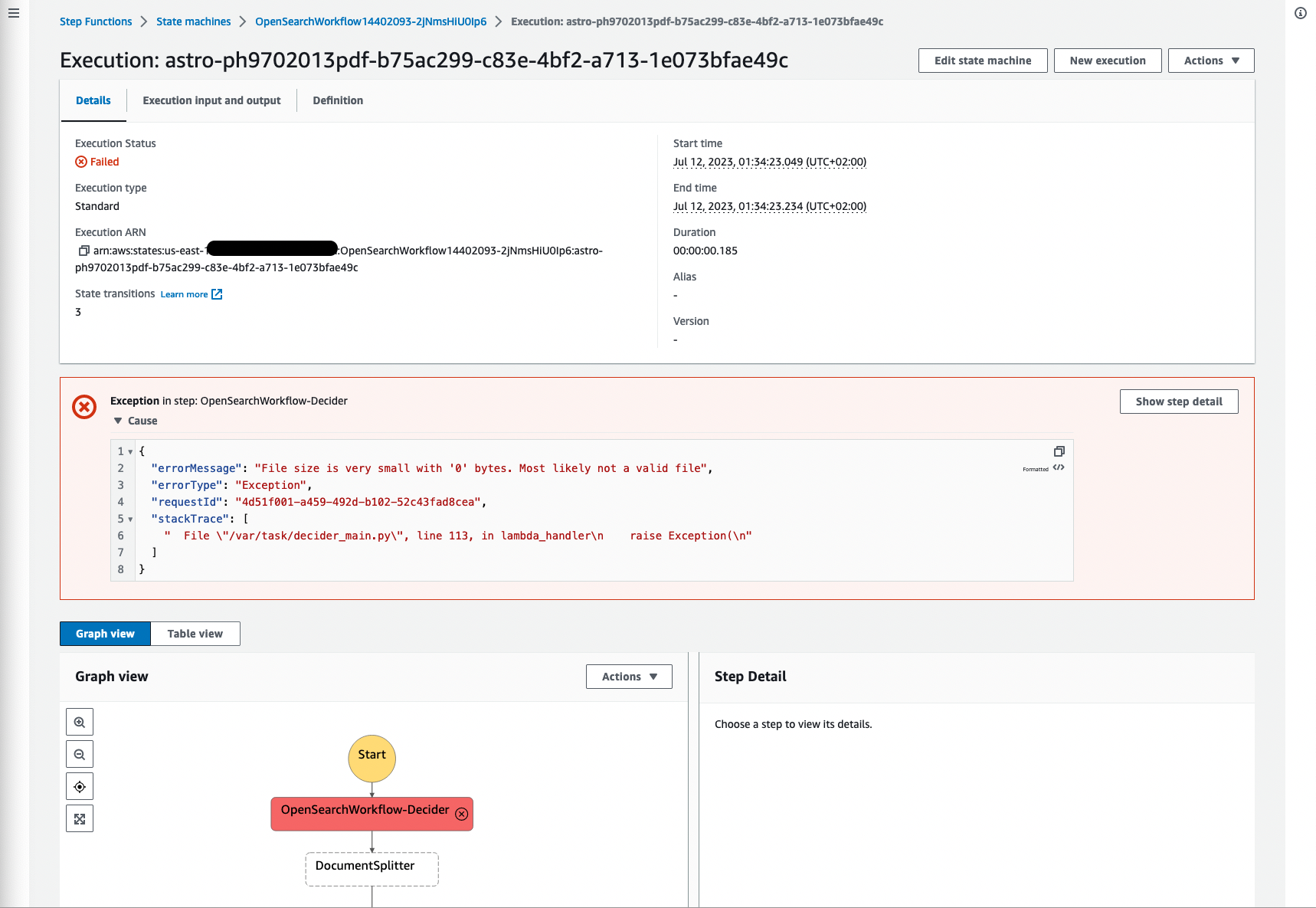
図18:Step Functionsの失敗したワークフロー
その他の失敗の原因は、Amazon Textractがサポートしていないアプリケーション/pdf、image/png、image/jpeg、またはimage/tiff形式でないドキュメントです。
コスト
1,583,278ページを取り込むための総コストは、実装に使用されたAWSサービスに分割されています。以下のリストは概算の数値として機能します。実際のコストと処理時間は、ドキュメントのサイズ、ドキュメントごとのページ数、ドキュメント内の情報の密度、およびAWSリージョンによって異なります。Amazon DynamoDBは$0.55、Amazon S3は$3.33、OpenSearch Serviceは$14.71、Step Functionsは$17.92、AWS Lambdaは$28.95、Amazon Textractは$1,849.97を消費しています。また、デプロイされたAmazon OpenSearch Serviceクラスタは時間単位で請求され、一定期間実行されると高いコストが発生します。
変更
おそらく、実装を変更し、ユースケースとドキュメントにカスタマイズしたいと考えているでしょう。ワークショップ「Use machine learning to automate and process documents at scale」では、実際のワークフローの操作方法、フローの変更、新しいコンポーネントの追加についての良い概要が説明されています。OpenSearchインデックスにカスタムフィールドを追加するには、ワークフローのSetMetaDataタスクを見てください。これは、set-manifest-meta-data-opensearch AWS Lambda関数を使用してコンテキストにメタデータを追加し、それがOpenSearchインデックスにフィールドとして追加されます。メタデータ情報はインデックスの一部となります。
クリーンアップ
不要になった場合は、例のリソースを削除して将来のコストを回避するために、次のコマンドを使用して削除してください:
cdk destroy OpenSearchWorkflowcdk deployコマンドと同じ環境で実行してください。注意してください、これによりOpenSearchクラスタとすべてのドキュメントとAmazon S3バケットも含め、すべてが削除されます。その情報を保持したい場合は、Amazon S3バケットをバックアップし、OpenSearchクラスタからインデックスのスナップショットを作成してください。多くのファイルを処理した場合は、AWS Management Consoleを使用して最初にAmazon S3バケットを空にする必要があります(情報を保持する場合はバックアップまたは別のバケットに同期させた後に)。なぜなら、クリーンアップ関数がタイムアウトする可能性があり、その後AWS CloudFormationスタックが破壊されるためです。
結論
この投稿では、大量のドキュメントをOpenSearchインデックスに取り込むためのフルスタックソリューションの展開方法を紹介しました。これにより、検索に使用するための準備が整ったドキュメントをインデックスに追加することができます。実装の各コンポーネントについて説明し、スケーリングの考慮事項、コスト、および変更のオプションについても議論しました。すべてのコードは、IDP CDKサンプルとしてGitHubでオープンソースとして利用可能であり、またIDP CDK構築物としても利用できます。次のステップとして、ワークフローを変更し、検索インデックスのドキュメントに情報を追加し、IDPワークショップを探索できます。現在のソリューションを拡張するためのご意見やご経験を以下のコメント欄にお寄せください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






