Imagen EditorとEditBench:テキストによる画像補完の進展と評価
Image Editor and EditBench Progress and Evaluation of Text-based Image Completion
グーグルリサーチの研究エンジニアであるスー・ワンとセズリー・モンゴメリーによる投稿
過去数年間、テキストから画像を生成する研究は、画期的な進展(特に、Imagen、Parti、DALL-E 2など)を見ており、これらは自然に関連するトピックに浸透しています。特に、テキストによる画像編集(TGIE)は、完全にやり直すのではなく、生成された物と撮影された視覚物を編集する実践的なタスクであり、素早く自動化されたコントロール可能な編集は、視覚物を再作成するのに時間がかかるか不可能な場合に便利な解決策です(例えば、バケーション写真のオブジェクトを微調整したり、ゼロから生成されたかわいい子犬の細かいディテールを完璧にする場合)。さらに、TGIEは、基礎となるモデルのトレーニングを改良する大きな機会を表しています。マルチモーダルモデルは、適切にトレーニングするために多様なデータが必要であり、TGIE編集は高品質でスケーラブルな合成データの生成と再結合を可能にすることができ、おそらく最も重要なことに、任意の軸に沿ってトレーニングデータの分布を最適化する方法を提供できます。
CVPR 2023で発表される「Imagen Editor and EditBench: Advancing and Evaluating Text-Guided Image Inpainting」では、マスクインペインティングの課題に対する最先端の解決策であるImagen Editorを紹介します。つまり、ユーザーが、編集したい画像の領域を示すオーバーレイまたは「マスク」(通常、描画タイプのインターフェイス内で生成されるもの)と共にテキスト指示を提供する場合のことです。また、画像編集モデルの品質を評価する方法であるEditBenchも紹介します。EditBenchは、一般的に使用される粗い「この画像がこのテキストに一致するかどうか」の方法を超えて、モデルパフォーマンスのより細かい属性、オブジェクト、およびシーンについて詳細に分析します。特に、画像とテキストの整合性の信頼性に強い重点を置きつつ、画像の品質を見失わないでください。
 |
| Imagen Editorは、指定された領域にローカライズされた編集を行います。モデルはユーザーの意図を意味を持って取り入れ、写真のようなリアルな編集を実行します。 |
Imagen Editor
Imagen Editorは、Imagenでファインチューニングされた拡散ベースのモデルで、編集を行うために改良された言語入力の表現、細かい制御、および高品質な出力を目的としています。Imagen Editorは、ユーザーから3つの入力を受け取ります。1)編集する画像、2)編集領域を指定するバイナリマスク、および3)テキストのプロンプトです。これら3つの入力は、出力サンプルを誘導します。
- 新時代の幕開け:「エイジ オブ エンパイア」シリーズがGeForce NOWに参加、6月に20タイトルがリリース予定
- フォトグラメトリとは何ですか?
- AIを学校に持ち込む:MITのアナント・アガルワルとの対話
Imagen Editorは、高品質なテキストによる画像インペインティングを行うための3つの核心技術に依存しています。まず、ランダムなボックスとストロークマスクを適用する従来のインペインティングモデル(例:Palette、Context Attention、Gated Convolutionなど)とは異なり、Imagen Editorは、トレーニング中にオブジェクト検出器モジュールを備えたオブジェクト検出器マスキングポリシーを使用します。オブジェクトマスクは、ランダムなパッチではなく検出されたオブジェクトに基づいています。これにより、編集テキストのプロンプトが小さい場合やオブジェクトが部分的にしかカバーされていない場合(例:CogView2)に、テキストプロンプトが無視されるという問題が緩和されます。
 |
| ランダムなマスク(左)は、背景を捉えたりオブジェクトの境界に交差したりすることがよくあり、画像コンテキストだけで合理的にインペインティングできる領域を定義します。オブジェクトマスク(右)は、画像コンテキストだけからインペインティングするのがより困難であるため、トレーニング中にモデルがテキスト入力により頼るようになります。 |
次に、トレーニングと推論中、Imagen Editorは、入力画像とマスクのフル解像度(この研究では1024×1024)のチャンネルごとの連結を条件として使用することにより、高解像度編集を強化します(SR3、Palette、GLIDEと同様)。64×64のベースディフュージョンモデルと64×64→256×256のスーパーレゾリューションモデルについては、パラメータ化されたダウンサンプリング畳み込み(ストライドつき畳み込みなど)を適用します。これは、高い忠実度にとって重要であることが実証されています。
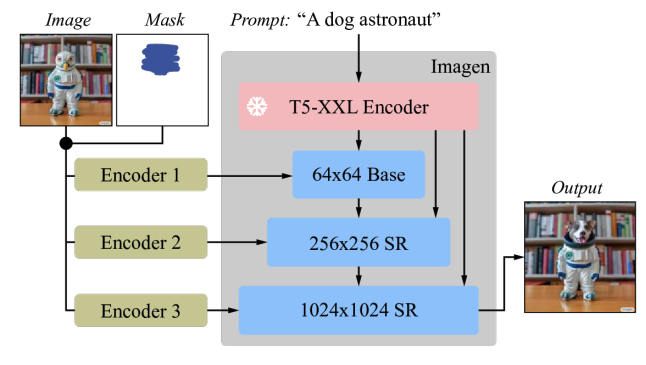 |
| Imagenは、画像編集に適したファインチューニングを行っています。ベースモデルとスーパーレゾリューション(SR)モデル、すべてのディフュージョンモデルは、高解像度の1024×1024の画像とマスクの入力を条件としています。このため、新しい畳み込み画像エンコーダが導入されました。 |
最後に、推論では、クラシファイアフリーガイダンス(CFG)を適用して、この場合はテキストプロンプトにバイアスをかけてサンプルを特定の条件に誘導します。CFGは、テキスト条件付けと非条件付けのモデルの予測の間を補間し、テキストによる画像修復のために生成された画像と入力テキストプロンプトとの間の強力なアライメントを確保します。Imagen Videoに従い、ガイダンス振動(ガイダンス重みの値範囲内で振動するガイダンススケジュール)を備えた高ガイダンス重みを使用します。テキストとの強力なアライメントが最も重要なステージ1の64xディフュージョンの場合、ガイダンス重みのスケジュールを1から30まで振動させます。ガイダンス重みの高い値と振動するガイダンスの組み合わせが、サンプル忠実度とテキスト-画像アライメントの最適なトレードオフを実現することが観察されました。
EditBench
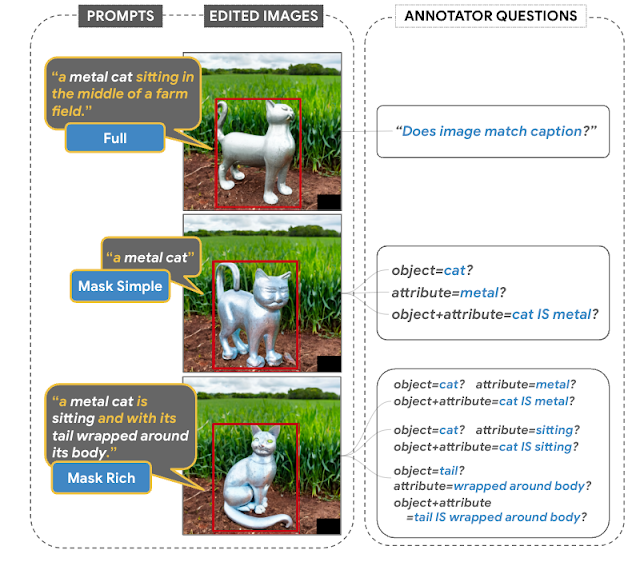
テキストによる画像修復の評価のためのEditBenchデータセットには、240枚の画像が含まれており、120枚の生成画像と120枚の自然画像が含まれています。生成された画像はPartiによって合成され、自然画像はVisual GenomeとOpen Imagesのデータセットから抽出されます。EditBenchには、言語、画像タイプ、テキストプロンプトの特異性(つまり、シンプル、リッチ、フルキャプション)の幅広いバリエーションが含まれます。各例は、(1)マスクされた入力画像、(2)入力テキストプロンプト、および(3)自動メトリックの参照として使用される高品質の出力画像で構成されています。異なるモデルの相対的な強みと弱点を理解するために、EditBenchプロンプトは、3つのカテゴリに沿って細かい詳細をテストするように設計されています:(1)属性(素材、色、形状、サイズ、数など)、(2)オブジェクトタイプ(一般的、珍しい、テキストレンダリングなど)、および(3)シーン(室内、屋外、現実的、または絵画)。プロンプトの仕様がモデルのパフォーマンスにどのように影響するかを理解するために、マスクシンプル、マスクリッチ、およびフルイメージの3つのテキストプロンプトタイプを提供します。特に、マスクリッチは、複雑な属性バインディングと含有を処理するモデルの能力を調べるためのものです。
 |
| フルイメージは、修復が成功した場合の参照として使用されます。マスクは、フリーフォームのヒントのない形状で対象オブジェクトをカバーします。マスクシンプル、マスクリッチ、フルイメージプロンプトを評価し、従来のテキストから画像へのモデルに一致しています。 |
現在の自動評価メトリック(CLIPScoreおよびCLIP-R-Precision)には固有の弱点があるため、EditBenchでは人間の評価を基準としています。以下のセクションでは、EditBenchがモデル評価にどのように適用されるかを示します。
評価
Imagen Editorモデル(オブジェクトマスキング(IM)とランダムマスキング(IM-RM)を含む)を、Stable Diffusion(SD)およびDALL-E 2(DL2)と比較した場合、Imagen EditorはすべてのEditBench評価カテゴリで大幅にこれらのモデルを上回ります。
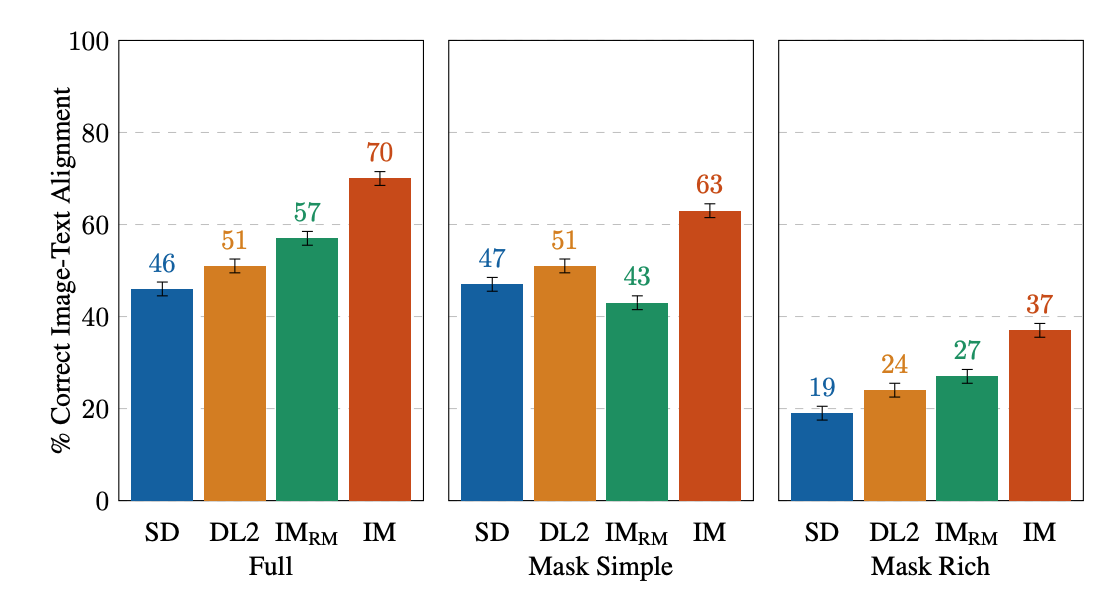
全画像プロンプトの場合、単一画像の人間の評価は、画像がキャプションに一致するかどうかを確認するためのバイナリ回答を提供します。マスクシンプルプロンプトの場合、単一画像の人間の評価は、オブジェクトと属性が適切にレンダリングされ、正しくバインドされているかどうかを確認します(たとえば、赤い猫の場合、赤いテーブルの上の白い猫は誤ったバインディングです)。サイドバイサイドの人間の評価は、Mask RichプロンプトをIM-RM、DL2、SDの各モデルと比較するためにのみ使用され、テキスト-画像の整列性においてキャプションにより適合する画像および最も現実的な画像を示します。
 |
| 人間の評価。全画像プロンプトは、アノテーターのテキスト-画像の整列の総合的な印象を引き出します。マスクシンプルおよびMask Richについては、特定の属性、オブジェクト、および属性バインディングが適切に含まれているかどうかを確認します。異なる評価設計のFull vs. Mask-onlyプロンプトのため、結果は直接比較できません。 |
単一画像の人間の評価において、IMは全体的に最高の評価を受けています(2番目にパフォーマンスが高いモデルよりも10〜13%高い)。その他の場合、パフォーマンスの順序は、マスクシンプルおよびマスクリッチを除いて、IM-RM>DL2>SD(3〜6%の差)です。 FullおよびMask Richには比較的に多くの意味的なコンテンツが含まれるため、IM-RMおよびIMは、高性能なT5 XXLテキストエンコーダによって恩恵を受けていると考えられます。
 |
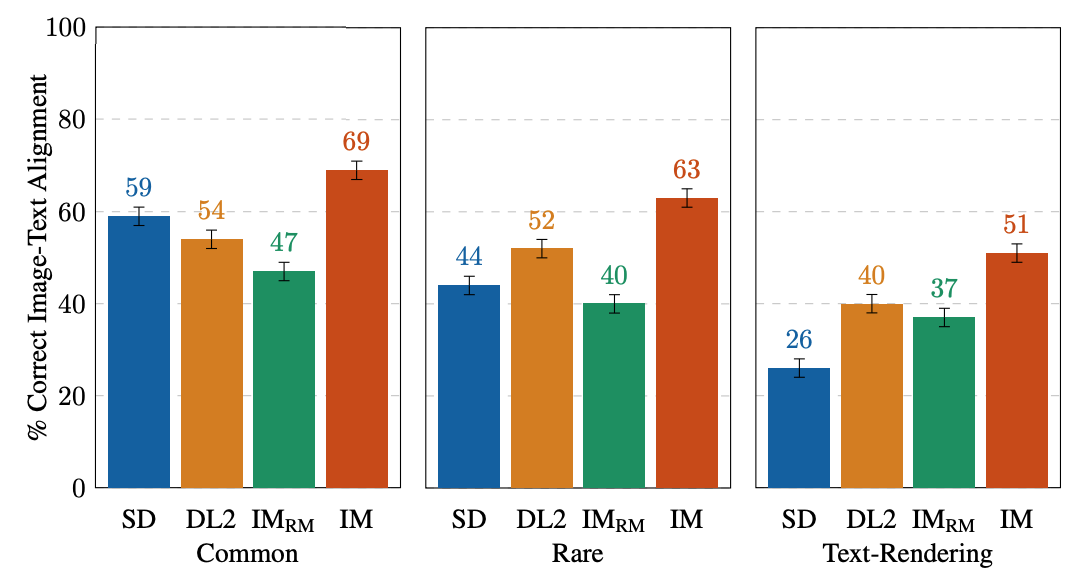
| EditBenchによるテキストガイド画像補完の単一画像の人間の評価、プロンプトタイプ。マスクシンプルおよびMask Richプロンプトの場合、編集された画像がプロンプトで指定されたすべての属性とオブジェクト、正しい属性バインディングを正確に含んでいる場合、テキスト-画像の整列が正しいことを確認します。 Full vs. Mask-onlyプロンプトの評価設計が異なるため、結果は直接比較できません。 |
EditBenchは細かい注釈に焦点を当てているため、オブジェクトタイプおよび属性タイプのモデルを評価します。オブジェクトタイプについては、IMがすべてのカテゴリでリードし、共通、レア、およびテキストレンダリングで2番目にパフォーマンスが高いモデルよりも10〜11%優れています。
 |
| EditBench Mask Simpleにおけるオブジェクトタイプの単一画像の人間の評価。モデル全体として、オブジェクトのレンダリングの方がテキストレンダリングよりも優れています。 |
属性タイプについては、カウントを除いて、IMは次点のモデルよりも高い評価(13-16%)を受けています。DL2はわずか1%差のみです。
 |
| 属性タイプによるEditBench Mask Simpleの単一画像人間評価。オブジェクトマスキングは、全体的にプロンプト属性への遵守を向上させます(IM vs. IM-RM)。 |
その他のモデルとの比較で、IMはテキストの整列性において、SD、DL2、IM-RMよりも注釈付け者に好まれ、大幅なマージンでリードしています。
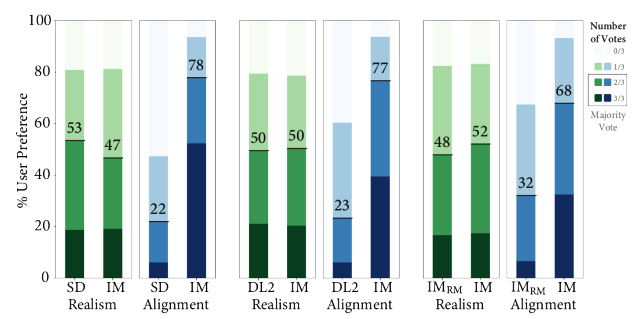 |
| EditBench Mask Richプロンプトの画像リアリズムとテキスト-イメージ整列の横並び人間評価。テキスト-イメージの整列については、Imagen Editorがすべての比較で優先されます。 |
最後に、すべてのモデルの代表的な横並び比較を示します。より多くの例については、論文を参照してください。
 |
| Mask Simple vs. Mask Richプロンプトの例のモデル出力。オブジェクトマスキングは、ランダムマスキングでトレーニングされた同じモデルに比べて、Imagen Editorのプロンプトへの細かい遵守を向上させます。 |
結論
Imagen EditorとEditBenchを提供し、テキストによる画像のインペインティングおよびその評価において重要な進展を遂げました。Imagen EditorはImagenからファインチューニングされたテキストによる画像のインペインティングです。EditBenchは、属性、オブジェクト、シーンの複数の次元でパフォーマンスを評価する、総合的なシステマチックベンチマークです。責任あるAIに関する懸念から、Imagen Editorは一般に公開されません。一方、EditBenchは研究コミュニティの利益のために完全にリリースされています。
謝辞
Gunjan Baid、Nicole Brichtova、Sara Mahdavi、Kathy Meier-Hellstern、Zarana Parekh、Anusha Ramesh、Tris Warkentin、Austin Waters、Vijay Vasudevanに感謝します。人間の評価タスクを完了するための調整に、Igor Karpov、Isabel Kraus-Liang、Raghava Ram Pamidigantam、Mahesh Maddinala、すべての匿名の人間アノテーターに感謝します。Huiwen Chang、Austin Tarango、Douglas Eckに論文のフィードバックを提供していただき感謝いたします。リソース調整のためにErica MoreiraとVictor Gomesに感謝します。最後に、DALL-E 2の著者に感謝して、研究目的でモデル出力を使用する許可をいただきました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Link-credible:Steam、Epic Games Store、Ubisoftアカウントリンクを使用して、GeForce NOWでより速くゲームに参加しましょう
- NVIDIAとHexagonが、産業のデジタル化を加速するためのソリューションスイートを提供します
- 映像作家のサラ・ディーチシーが今週の「NVIDIA Studio」でAIについて話します
- 進め、GOを通過し、もっと多くのゲームを収集:Xbox Game PassがGeForce NOWにやってくる
- Python開発のための12のVSCodeのヒントとトリック
- GPT-4は、誤情報を引き起こすプロンプトインジェクション攻撃に対して脆弱です
- ChatGPT、GPT-4、Bard、およびClaudeを検出するためのトップ10ツール





