「時系列データセットで欠損データを特定する方法」
Identifying missing data in time series datasets
タイムシリーズデータは、複数のソースからほぼ毎秒収集されるデータであり、しばしばデータ品質の問題、特に欠損データが発生します。
時系列データの文脈では、欠損情報はいくつかの理由で発生する可能性があります。例えば、取得システムのエラー(センサーの故障など)、送信プロセス中のエラー(ネットワーク接続の不具合など)、データ収集中のエラー(データ記録中のヒューマンエラーなど)などです。これらの状況は、収集されたデータのストリームにおける小さなギャップに対応する、散発的で明示的な欠損値を頻繁に生成します。
さらに、ドメイン自体の特性に起因して自然に欠損情報が発生することもあり、データにはより大きなギャップが生じます。たとえば、一定期間にわたって収集が停止する特徴があり、非明示的な欠損データが生成されます。
欠損データがあると、予測モデリングや予測に対して大きな悪影響を及ぼし、個人(誤ったリスク評価など)やビジネスの結果(バイアスのあるビジネスの意思決定、収益や機会の損失など)に深刻な影響を与える可能性があります。
モデリング手法にデータを準備する際には、未知の情報のパターンを特定できることが重要なステップです。これにより、データを効率的に処理し、一貫性を向上させるための最適なアプローチを選択できます。これには、アライメントの修正、データ補間、データ補完、または場合によってはケースごとの削除(特定の分析に使用される特徴の欠損値を持つケースを省略する)などが含まれます。
そのため、徹底的な探索的データ分析とデータプロファイリングを実施することは、データの特性を理解するだけでなく、分析のためにデータを最適に準備するためにも不可欠です。
このハンズオンチュートリアルでは、最新リリースで導入された新機能を使用して、ydata-profilingがこれらの問題を解決するのにどのように役立つかを探求します。米国の公害データセットを使用します。このデータセットはKaggle(ライセンスDbCL v1.0)で入手でき、米国の州ごとのNO2、O3、SO2、およびCOの汚染物質に関する情報を詳細に記載しています。
ハンズオンチュートリアル:米国の公害データセットのプロファイリング
チュートリアルを開始するためには、まず最新バージョンのydata-profilingをインストールする必要があります:
pip install ydata-profiling==4.5.1
次に、データを読み込んで不要な特徴を削除し、調査したい内容に焦点を当てる必要があります。この例では、アリゾナ州、マリコパ、スコッツデールの測定局で行われた大気汚染物質の測定の特定の振る舞いに焦点を当てます:
import pandas as pd
data = pd.read_csv("data/pollution_us_2000_2016.csv")
data = data.drop('Unnamed: 0', axis = 1) # 不要なインデックスを削除
# アリゾナ州、マリコパ、スコッツデール(サイト番号:3003)のデータを選択
data_scottsdale = data[data['Site Num'] == 3003].reset_index(drop=True)
これで、データセットのプロファイリングを開始する準備が整いました!時系列のプロファイリングを使用するためには、tsmode=Trueというパラメータを渡す必要があるため、ydata-profilingが時系列に依存する特徴を識別できるようにします:
# 'Data Local'を日時型に変更
data_scottsdale['Date Local'] = pd.to_datetime(data_scottsdale['Date Local'])
# プロファイルレポートを作成
profile_scottsdale = ProfileReport(data_scottsdale, tsmode=True, sortby="Date Local")
profile_scottsdale.to_file('profile_scottsdale.html')
時系列の概要
出力レポートは、既に知っているものに似ていますが、改善された体験と時系列データのための新しい要約統計情報があります:
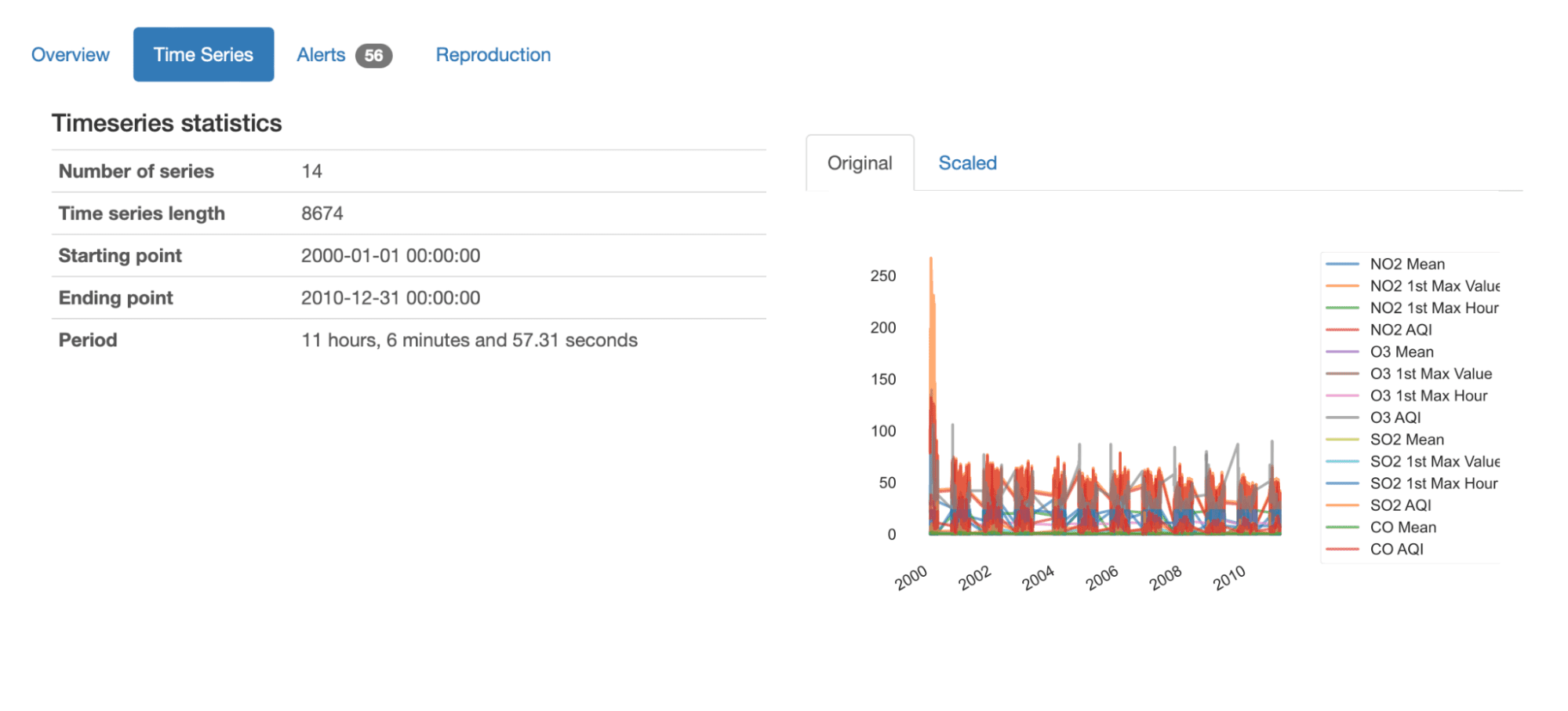
概要からすぐに、提示された要約統計情報を見ることで、このデータセットの全体的な理解を得ることができます:
- 14種類の異なる時系列が含まれており、それぞれに8674個の記録値があります。
- データセットは2000年1月から2010年12月までの10年間のデータを報告しています。
- 時間の期間は平均で11時間とほぼ7分です。つまり、平均して11時間ごとに計測が行われています。
データのすべてのシリーズの概要プロットも取得できます。元の値またはスケーリングされた値で表示できます。これにより、シーケンスの全体的な変動、および測定されている成分(NO2、O3、SO2、CO)と特性(平均、最初の最大値、最初の最大時間、AQI)を簡単に把握できます。
欠損データの調査
データの全体像を把握した後、各時系列の詳細に焦点を当てることができます。
ydata-profilingの最新リリースでは、時間系列データの専用の分析も含まれるようになり、”Time Series”および”Gap Analysis”の指標に関するレポートが大幅に改善されました。これらの新機能により、傾向や欠損パターンの特定が非常に容易になり、具体的な要約統計と詳細な可視化が利用できるようになりました。
すぐに目立つのは、すべての時系列が示す不安定なパターンで、連続した測定値の間で特定の「ジャンプ」が発生しているように見えます。これは、欠損データ(欠損情報の「ギャップ」)の存在を示しており、より詳細に調査する必要があります。例として、S02 Meanを見てみましょう。

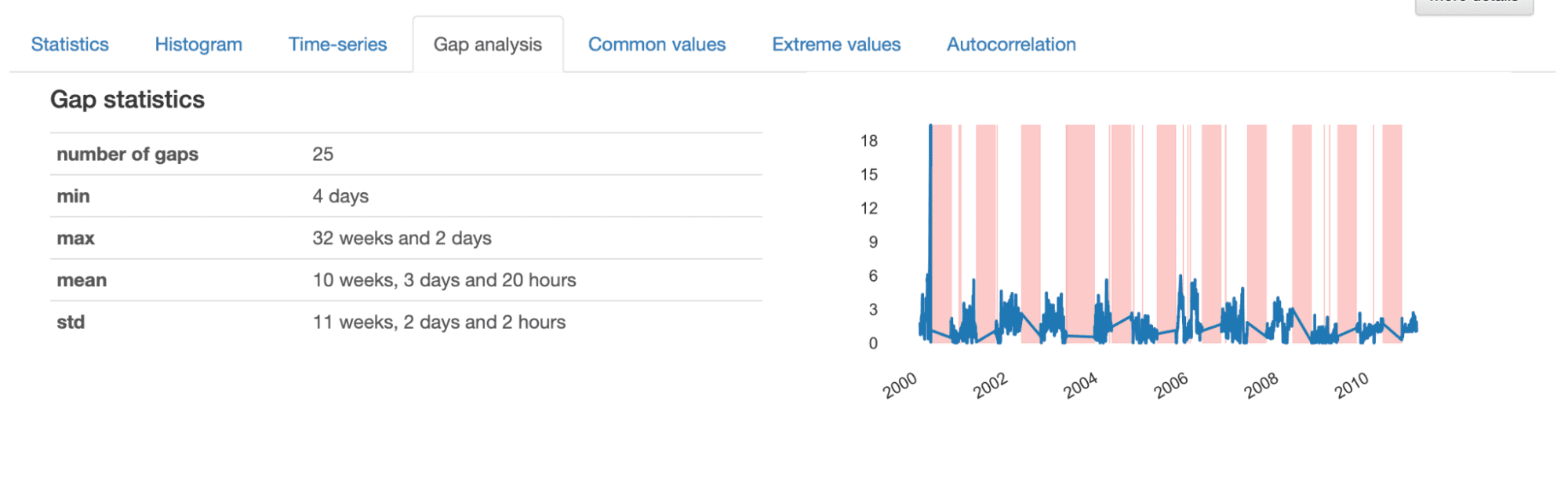
ギャップ分析の詳細を調査すると、特定のギャップの特性についての情報を得ることができます。全体的には、時間系列には25のギャップがあり、最小の長さは4日、最大は32週、平均は10週です。
提示された可視化からは、より「ランダムな」ギャップが薄いストライプで表されており、より大きなギャップは繰り返しパターンに従っているように見えます。これは、データセット内の欠損データの2つの異なるパターンが存在する可能性を示しています。
小さいギャップは、欠損データを生成する散発的なイベントに対応しており、おそらく取得プロセスのエラーによるものであり、データセットから簡単に補間または削除できることが多いです。一方、大きなギャップはより複雑で、より詳細に分析する必要があります。なぜなら、それらにはより徹底的に対処する必要のある潜在的なパターンが示される可能性があるからです。
この例では、より大きなギャップを調査すると、季節パターンが反映されていることがわかります:
df = data_scottsdale.copy()
for year in df["Date Local"].dt.year.unique():
for month in range(1,13):
if ((df["Date Local"].dt.year == year) & (df["Date Local"].dt.month ==month)).sum() == 0:
print(f'Year {year} is missing month {month}.')
# Year 2000 is missing month 4.
# Year 2000 is missing month 5.
# Year 2000 is missing month 6.
# Year 2000 is missing month 7.
# Year 2000 is missing month 8.
# (...)
# Year 2007 is missing month 5.
# Year 2007 is missing month 6.
# Year 2007 is missing month 7.
# Year 2007 is missing month 8.
# (...)
# Year 2010 is missing month 5.
# Year 2010 is missing month 6.
# Year 2010 is missing month 7.
# Year 2010 is missing month 8.
疑われていたように、時系列データには大きな情報のギャップがいくつかあります。ほとんどの年において、5月から8月(5から8月)の間にデータが収集されていないことがわかります。これは予測不可能な理由や既知のビジネス上の決定によるものかもしれません。例えば、コスト削減に関連するもの、または気象パターン、温度、湿度、大気条件に関連する汚染物質の季節変動に関連するものです。
これらの調査結果に基づいて、なぜこれが起こったのか、将来的にそれを防ぐために何かをする必要があるのか、現在のデータをどのように処理するかを調査することができます。
最終的な考察:補完、削除、再調整?
このチュートリアルを通じて、時間系列の欠損データのパターンを理解することの重要性と、効果的なプロファイリングによって欠損情報のギャップの謎が明らかになることを見てきました。通信、医療、エネルギー、金融など、すべての時間系列データを収集するセクターは、ある時点で欠損データに直面し、それらを処理し、可能な限りの知識を抽出するための最良の方法を決定する必要があります。
包括的なデータプロファイリングにより、手元のデータの特性に応じて情報を正確かつ効率的に判断することができます:
- 情報のギャップは、獲得、伝送、収集のエラーに起因する断続的なイベントによって引き起こされる可能性があります。問題を修正して再発防止策を講じ、ギャップの長さに応じて欠損部分を補間または埋めることができます。
- 情報のギャップは季節的または繰り返しのパターンを表す場合もあります。欠損情報を収集するためにパイプラインを再構築するか、他の分散システムから外部情報で欠損部分を置き換えることができます。また、取得プロセスが失敗したかどうかも特定できます(たとえば、データエンジニアリング側でのタイポミスなど)。
このチュートリアルがタイムシリーズデータの欠損データを適切に特定・特徴付けする方法について少しでも理解を深めるお手伝いができれば幸いです。また、あなた自身のギャップ分析で見つけることを楽しみにしています!質問や提案があればコメントで連絡してください。または、Data-Centric AIコミュニティで私に会えます! Fabiana Clemente は、データ理解、因果関係、プライバシーを主な研究領域とするYDataの共同創業者兼CDOであり、データを組織のために活用可能にすることを使命としています。熱心なデータプラクティショナーとして、ポッドキャスト「When Machine Learning Meets Privacy」のホストとして活動し、DatacastとPrivacy Pleaseのゲストスピーカーとしても参加しています。また、ODSCやPyDataなどのカンファレンスでも講演しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
