「データの中で最も異常なセグメントを特定する」
Identify the most abnormal segment in the data.
コモンセンスと機械学習を使用して注目すべきセグメントを見つける方法
アナリストは、最大の潜在的な影響を得るために努力を集中することができる「興味深い」セグメントを見つけるというタスクをしばしば持っています。例えば、離反に最も影響を与える顧客セグメントを特定することは興味深いかもしれません。また、どの種類の注文が顧客サポートの負荷や会社の収益に影響を与えるのかを理解しようとすることもできます。
もちろん、そのような傑出した特徴を見つけるためにグラフを見ることができます。しかし、通常は数十、場合によっては数百もの顧客の特性を追跡する必要があるため、時間がかかることがあります。さらに、異なる要素の組み合わせを見る必要があるため、組合せ爆発が起こる可能性があります。このようなタスクでは、フレームワークが本当に役立つでしょう。なぜなら、分析に数時間を節約できるからです。
この記事では、データの最も傑出したスライスを見つけるための2つのアプローチを共有したいと思います:
- コモンセンスと基本的な数学に基づくアプローチ
- 機械学習に基づくアプローチ — Wiseのデータサイエンスチームは、3行のコードで答えを提供するライブラリ「Wise Pizza」をオープンソースで公開しています。
例: 銀行の顧客の離反
この例の完全なコードはGitHubで見つけることができます。
例として、銀行の顧客の離反に関するデータを使用します。このデータセットは、CC0: パブリックドメインライセンスの下でKaggleで入手できます。
グラフ、コモンセンス、機械学習を使用して離反に最も影響を与えるセグメントを見つけようとします。しかし、まずはデータの前処理から始めましょう。
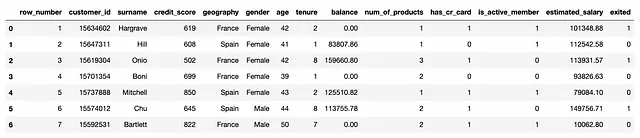
このデータセットには、顧客とその特性(信用スコア、居住国、年齢・性別、残高など)がリストされています。また、各顧客について、離反したかどうか(パラメータ「exited」)も知っています。
私たちの主な目標は、離反した顧客の数に最も影響を与える顧客セグメントを見つけることです。その後、これらのユーザーグループに特有の問題を理解しようとすることができます。これらのセグメントの問題を修正することに焦点を当てれば、離反した顧客の数に最も大きな影響を与えることができます。
計算と解釈を簡単にするために、セグメントをフィルターの集合として定義します。たとえば、「性別=男性」または「性別=男性、国=イギリス」といった具体的な条件です。
私たちは離散的な特性で作業するため、連続的なメトリクス(年齢や残高など)を変換する必要があります。そのために、分布を見て適切なバケットを定義することができます。例えば、年齢を見てみましょう。
連続的な特性をバケットに分割するためのコード例
def get_age_group(a): if a < 25: return '18 - 25' if a < 35: return '25 - 34' if a < 45: return '35 - 44' if a < 55: return '45 - 54' if a < 65: return '55 - 64' return '65+'raw_df['age_group'] = raw_df.age.map(get_age_group)データ内の興味深いセグメントを見つける最も簡単な方法は、視覚化を見ることです。棒グラフやヒートマップを使用して、1つまたは2つの次元で分割した離反率を見ることができます。
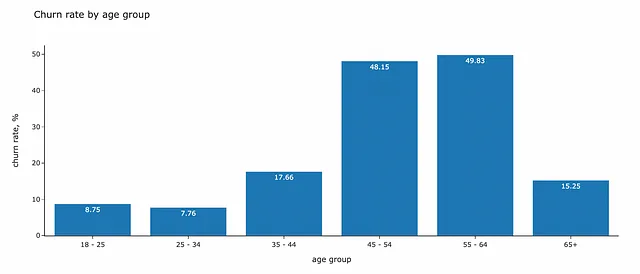
年齢と離反の相関を見てみましょう。35歳未満の顧客の離反率は低く、10%未満です。一方、45歳から64歳までの顧客については、リテンション率が最も悪く、顧客の半数近くが離反しています。
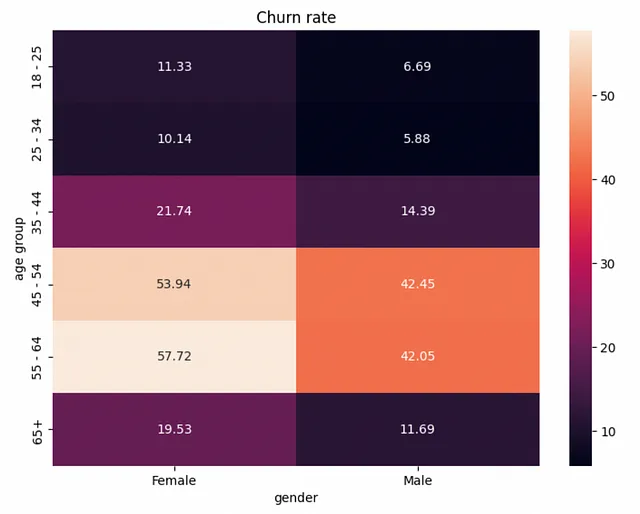
さらに複雑な関係を見つけるために、もう1つのパラメータ(gender)を追加してみましょう。バーチャートでは2次元の関係を表示することができませんので、ヒートマップに切り替えましょう。
女性の離脱率はすべての年齢グループで高く、性別は影響力のある要素です。
このような可視化は非常に洞察力がありますが、このアプローチにはいくつかの問題があります:
- セグメントのサイズを考慮していません
- 持っている特徴のすべての組み合わせを見るのに時間がかかるかもしれません
- 1つのグラフで2つ以上の次元を視覚化するのは難しいです
それでは、効果の推定された興味深いセグメントの優先順位付けリストを取得するのに役立つより構造化されたアプローチに移りましょう。
常識的なアプローチ
仮定
特定のセグメントの問題の修正の潜在的な影響をどのように計算できるでしょうか?低い離脱率の「理想的な」シナリオと比較することができます。
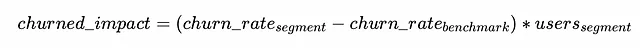
離脱率の基準をどのように推定できるか疑問に思うかもしれません。いくつかの方法があります:
- 市場からのベンチマーク:ドメイン内の製品の典型的な離脱率レベルを検索してみることができます
- 製品内の高パフォーマンスセグメント:通常、少し優れたパフォーマンスのセグメントがあります(例えば、国やプラットフォームで分割できます)それらをベンチマークとして使用できます
- 平均値:最も保守的なアプローチは、グローバルな平均値を見て、すべてのセグメントの平均離脱率に到達する効果の潜在的な影響を推定することです
安全策として、データセットからの平均離脱率(20.37%)をベンチマークとして使用しましょう。
すべての可能なセグメントのリスト化
次のステップは、すべての可能なセグメントを構築することです。私たちのデータセットは10の次元を持ち、それぞれに3〜6のユニークな値があります。組み合わせの総数は約120万です。次元がわずかで異なる値を持っていても、計算上はコストがかかるように見えます。実際のタスクでは、通常は数十の特性とユニークな値があります。
私たちは確かにいくつかのパフォーマンス最適化について考える必要があります。そうしないと、結果を待つために数時間費やさなければならないかもしれません。以下は計算を削減するためのいくつかのヒントです:
- まず最初に、すべての可能な組み合わせを作成する必要はありません。深さを4〜6に制限するのが合理的です。42の異なるフィルタで定義されるユーザーセグメントに製品チームが焦点を当てる可能性は非常に低いでしょう。
- 次に、興味を持っている効果のサイズを定義することができます。例えば、リテンション率を少なくとも1%ポイント増やしたいとします。それは、サイズが全ユーザーの1%未満のセグメントには興味がないことを意味します。そのため、このしきい値を下回る場合は、セグメントの分割を停止することができます。これにより、操作の回数が減ります。
- 最後に、実際のデータセットでは、データサイズと計算に費やすリソースを大幅に削減することができます。そのためには、各次元のすべての小さな特性を
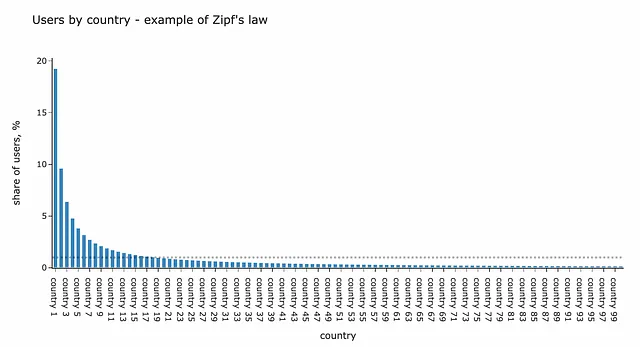
otherグループにまとめることができます。例えば、国は数百あり、各国のユーザーの割合は通常、他の実データ関係と同様にZipfの法則に従います。したがって、ユーザーグループのサイズが全ユーザーの1%未満の多くの国があります。先ほど議論したように、そのような小さなユーザーグループには興味がないので、すべての国をcountry = otherとしてグループ化して計算を容易にすることができます。
最大深度max_depthまでのすべてのフィルタの組み合わせを構築するために再帰を使用します。このコンピュータサイエンスの概念が好きなのは、多くの場合、複雑な問題をエレガントに解決することができるからです。残念ながら、データアナリストはほとんど再帰的なコードを書く必要がない場面に直面することはほとんどありません。私は10年のデータ分析経験を通じて3つのタスクを覚えています。
再帰のアイデアは非常にシンプルです — 実行中に関数が自身を呼び出すことです。階層構造やグラフと一緒に作業する場合に便利です。Pythonで再帰についてもっと学びたい場合は、この記事を読んでください。
私たちの場合のハイレベルなコンセプトは次の通りです:
- データセット全体とフィルタがない状態から始めます。
- 次に、フィルタを1つ追加し(セグメントのサイズが十分に大きく、最大深度に達していない場合)、その関数を適用します。
- 条件が有効な限り、前のステップを繰り返します。
num_metric = 'exited'denom_metric = 'total'max_depth = 4def convert_filters_to_str(f): lst = [] for k in sorted(f.keys()): lst.append(str(k) + ' = ' + str(f[k])) if len(lst) != 0: return ', '.join(lst) return ''def raw_deep_dive_segments(tmp_df, filters): # セグメントを返す yield { 'filters': filters, 'numerator': tmp_df[num_metric].sum(), 'denominator': tmp_df[denom_metric].sum() } # 最大深度に達していなければ、さらに深く進むことができる if len(filters) < max_depth: for dim in dimensions: # この次元が既に使用されているかチェックする if dim in filters: continue # 可能な組み合わせの重複排除 if (filters != {}) and (dim < max(filters.keys())): continue for val in tmp_df[dim].unique(): next_tmp_df = tmp_df[tmp_df[dim] == val] # セグメントのサイズが十分に大きいかチェックする if next_tmp_df[denom_metric].sum() < min_segment_size: continue next_filters = filters.copy() next_filters[dim] = val # 次のセグメントに対して関数を実行する for rec in raw_deep_dive_segments(next_tmp_df, next_filters): yield rec# データフレームのすべてのセグメントを集計するsegments_df = pd.DataFrame(list(raw_deep_dive_segments(df, {})))その結果、約10,000のセグメントが得られました。これで、各セグメントの推定効果を計算し、負の効果を持つセグメントをフィルタリングし、最もポテンシャルの高い影響を持つユーザーグループを見ることができます。
baseline_churn = 0.2037segments_df['churn_share'] = segments_df.churn/segments_df.totalsegments_df['churn_est_reduction'] = (segments_df.churn_share - baseline_churn)\ *segments_df.totalsegments_df['churn_est_reduction'] = segments_df['churn_est_reduction']\ .map(lambda x: int(round(x)))filt_segments_df = segments_df[segments_df.churn_est_reduction > 0]\ .sort_values('churn_est_reduction', ascending = False).set_index('segment')これはすべての答えを与える聖杯のはずです。しかし、重複が多すぎて、連続するセグメントがあります。重複を減らし、最も情報量の高いユーザーグループのみを保持することはできるでしょうか?
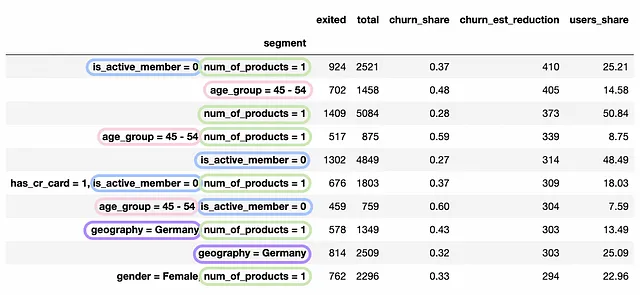
整える
いくつかの例を見てみましょう。
子セグメントage_group = 45–54, gender = Maleの離脱率はage_group = 45–54よりも低いです。 gender = Maleフィルタを追加しても、具体的な問題には近づけません。そのような場合は、このようなケースを排除することができます。

以下の例は逆の状況を示しています。子セグメントの離脱率は著しく高く、さらに、子セグメントには親ノードからの離脱した顧客の80%が含まれています。この場合、credit_score_group = poor, tenure_group = 8+セグメントを排除するのは合理的です。なぜなら、主な問題はis_active_member = 0グループにあるからです。

興味のないセグメントをフィルタリングしましょう。
import statsmodels.stats.proportion# getting all parent - child pairsdef get_all_ancestors_recursive(filt): if len(filt) > 1: for dim in filt: cfilt = filt.copy() cfilt.pop(dim) yield cfilt for f in get_all_ancestors_recursive(cfilt): yield f def get_all_ancestors(filt): tmp_data = [] for f in get_all_ancestors_recursive(filt): tmp_data.append(convert_filters_to_str(f)) return list(set(tmp_data))tmp_data = []for f in tqdm.tqdm(filt_segments_df['filters']): parent_segment = convert_filters_to_str(f) for af in get_all_ancestors(f): tmp_data.append( { 'parent_segment': af, 'ancestor_segment': parent_segment } ) full_ancestors_df = pd.DataFrame(tmp_data)# filter child nodes where churn rate is lower filt_child_segments = []for parent_segment in tqdm.tqdm(filt_segments_df.index): for child_segment in full_ancestors_df[full_ancestors_df.parent_segment == parent_segment].ancestor_segment: if child_segment in filt_child_segments: continue churn_diff_ci = statsmodels.stats.proportion.confint_proportions_2indep( filt_segments_df.loc[parent_segment][num_metric], filt_segments_df.loc[parent_segment][denom_metric], filt_segments_df.loc[child_segment][num_metric], filt_segments_df.loc[child_segment][denom_metric] ) if churn_diff_ci[0] > -0.00: filt_child_segments.append( { 'parent_segment': parent_segment, 'child_segment': child_segment } ) filt_child_segments_df = pd.DataFrame(filt_child_segments)filt_segments_df = filt_segments_df[~filt_segments_df.index.isin(filt_child_segments_df.child_segment.values)]# filter parent nodes where churn rate is lower filt_parent_segments = []for child_segment in tqdm.tqdm(filt_segments_df.index): for parent_segment in full_ancestors_df[full_ancestors_df.ancestor_segment == child_segment].parent_segment: if parent_segment not in filt_segments_df.index: continue churn_diff_ci = statsmodels.stats.proportion.confint_proportions_2indep( filt_segments_df.loc[parent_segment][num_metric], filt_segments_df.loc[parent_segment][denom_metric], filt_segments_df.loc[child_segment][num_metric], filt_segments_df.loc[child_segment][denom_metric] ) child_coverage = filt_segments_df.loc[child_segment][num_metric]/filt_segments_df.loc[parent_segment][num_metric] if (churn_diff_ci[1] < 0.00) and (child_coverage >= 0.8): filt_parent_segments.append( { 'parent_segment': parent_segment, 'child_segment': child_segment } ) filt_parent_segments_df = pd.DataFrame(filt_parent_segments)filt_segments_df = filt_segments_df[~filt_segments_df.index.isin(filt_parent_segments_df.parent_segment.values)]ここで約4Kの興味深いセグメントがあります。このおもちゃのデータセットでは、トップのセグメントに対するこの整形の後にはほとんど差がないことがわかります。しかし、実際のデータでは、これらの取り組みがしばしば実を結びます。
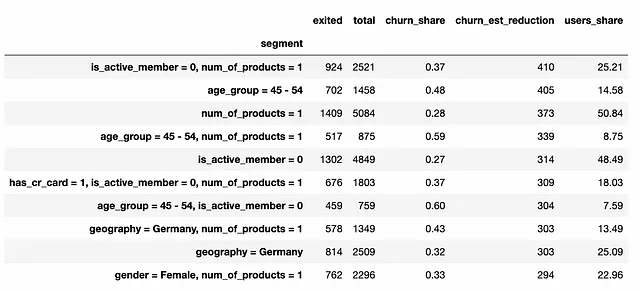
ルート原因
最も意味のあるセグメントのみを残すために、セグメントのルートノードのみを保持します。これらのセグメントはルート原因であり、他のセグメントはそれらに含まれます。ルート原因の中でもさらに詳しく調べたい場合は、子ノードを見てください。
ルート原因のみを取得するには、最終的な興味深いセグメントのリストに親ノードがあるすべてのセグメントを除外する必要があります。
root_segments_df = filt_segments_df[~filt_segments_df.index.isin( full_ancestors_df[full_ancestors_df.parent_segment.isin( filt_segments_df.index)].ancestor_segment )]ここで、焦点を当てるユーザーグループのリストがあります。複数の特性が完全な効果を説明するデータの複雑な関係が少ないため、トップのセグメントは1次元のものだけです。
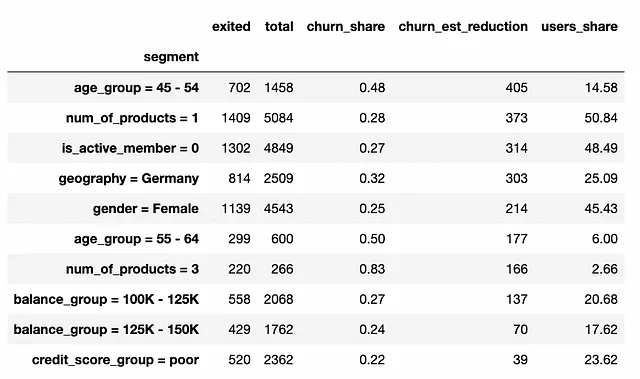
結果を解釈する方法について話し合うことは非常に重要です。推定された影響を持つ顧客セグメントのリストを取得しました。私たちの推定は、ベンチマークレベル(この例では平均値)に到達するために、全セグメントの離脱率を減らすことができるという仮説に基づいています。したがって、各ユーザーグループの問題を修正することの影響を推定しました。
このアプローチは、焦点を当てるべきユーザーグループを高レベルで示すだけであることに留意する必要があります。これは、これらの問題を完全に修正できるかどうかは考慮していません。
結果を得るためにかなりの量のコードを書きました。データサイエンスや機械学習を使用してこのタスクを解決する別のアプローチがあるかもしれませんが、それにはそれほどの努力が必要ではありません。
ピザの時間
実際には、別の方法があります。Wiseのデータサイエンスチームが開発したWise Pizzaというライブラリがあります。このライブラリは、瞬時に最も興味深いセグメントを見つけることができます。Apache 2.0ライセンスのオープンソースであり、あなたも自分のタスクに使用することができます。
Wise Pizzaライブラリについて詳しく知りたい場合は、データサイエンスフェスティバルでのEgorのプレゼンテーションをお見逃しなく。
Wise Pizzaの適用
このライブラリは使いやすいです。結果に含めたい寸法とセグメント数を指定するために、わずか数行のコードを書く必要があります。
# インストールするためには pip install wise_pizza を使用してくださいimport wise_pizza# モデルの構築 sf = wise_pizza.explain_levels(df=df, dims=dimensions, total_name="exited", size_name="total", max_depth=4, min_segments=15, solver="lasso")# プロットを作成 sf.plot(width=700, height=100, plot_is_static=False)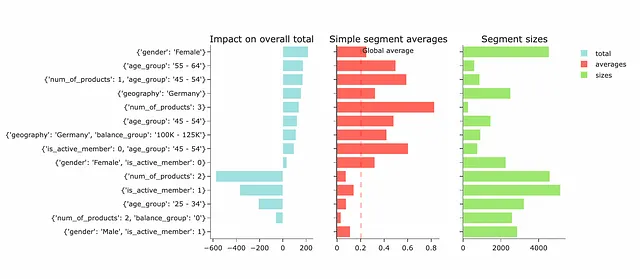
結果として、最も興味深いセグメントとそれらが製品の離脱に与える潜在的な影響のリストも取得しました。セグメントは、前のアプローチで得られたものと似ています。ただし、影響の推定値は大きく異なります。Wise Pizzaの結果を正しく解釈し、違いを理解するには、より詳細にその動作について話し合う必要があります。
動作原理
このライブラリはLassoとLPソルバーに基づいています。単純に言えば、ライブラリはワンホットエンコーディングに似たことを行い、セグメントにフラグを追加し、離脱率をターゲット変数としたLasso回帰を使用します。
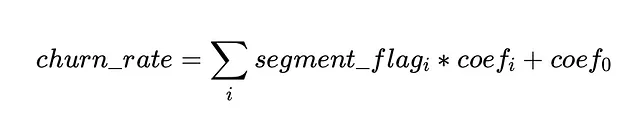
機械学習から覚えているかもしれませんが、Lasso回帰は多くのゼロ係数を持ち、いくつかの有意な要素を選択します。 Wise Pizzaは、指定した数のセグメントを取得するための適切なalpha係数をLasso回帰で見つけます。
Lasso(L1)およびRidge(L2)正則化の説明については、この記事を参照してください。
結果の解釈方法
影響は、係数とセグメントのサイズの積として推定されます。

したがって、私たちが以前に推定したものとはまったく異なります。常識的なアプローチでは、ユーザーグループの問題を完全に修正した場合の影響を推定しますが、Wise Pizzaの影響は他の選択したセグメントへの増分効果を示します。
このアプローチの利点は、異なる効果を合計することができることです。ただし、結果の解釈では注意が必要です。各セグメントの影響は、他の選択したセグメントに依存する可能性があるため、正確でなければなりません。たとえば、私たちの場合では、3つの相関セグメントがあります:
age_group = 45-54num_of_products = 1, age_group = 44–54is_active_member = 1, age_group = 44–54。
age_group = 45–54の影響は、全年齢層に対する潜在的な効果を把握していますが、他のものは特定のサブグループからの追加の影響を推定しています。このような依存関係は、min_segmentsパラメータによって異なる最終セグメントのセットとそれらの間の相関による結果の差異をもたらす可能性があります。
全体像に注意を払い、Wise Pizzaの結果を正しく解釈することが重要です。そうしないと、誤った結論に飛びついてしまう可能性があります。
このライブラリは、データから迅速な洞察を得るための貴重なツールとして評価しています。最初のセグメント候補を深く掘り下げるために使用します。ただし、私は機会のサイジングやより堅牢な分析を行い、製品チームとの焦点の潜在的な影響を共有する必要がある場合には、合理的な基準での常識的なアプローチを使用し続けます。なぜなら、それはより解釈しやすいからです。
要約
- データ内の興味深いスライスを見つけることは、分析者にとって一般的なタスクです(特に発見の段階では)。幸い、それらの質問を解決するために、数十のグラフを作成する必要はありません。より包括的で使いやすいフレームワークがあります。
- Wise PizzaのMLライブラリを使用すると、平均的な影響が最も大きいセグメントに関する迅速な洞察を得ることができます(2つのデータセットの差も確認できます)。通常、意味のある寸法とセグメントの最初のリストを取得するために使用します。
- MLアプローチは、一瞥で高レベルのビューと優先順位付けを提供することができます。ただし、結果の解釈に注意を払い、自分自身と利害関係者がそれを完全に理解していることを確認することをお勧めします。ただし、全ユーザーグループの問題を修正することによるKPIへの潜在的な効果を堅牢に推定する必要がある場合には、算術に基づいた古典的な常識的なアプローチを使用する価値があります。
この記事を読んでいただきありがとうございます。お役に立てれば幸いです。何かご質問やコメントがある場合は、コメント欄にどうぞお気軽にお書きください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
