「私はChatGPTのコードインタプリタに乱雑なデータセットと望ましいクリーンなバージョンを示しました」
I demonstrated a messy dataset and its desired clean version to the code interpreter of ChatGPT.
そして、それが私が望んだデータをどのように取得するかを見るために座りました。

生の乱雑なデータセットを見ると、私の最初の反応は通常「この形式であればいいのになぁ」となります。
それから、乱雑なデータセットをきれいで整った形式に変換できる魔法の杖が欲しいと思います。
Code Interpreterはその魔法の杖です。実際には、魔法ではなく、明確な説明とPythonコードを使って望ましい操作を行う方法を教えてくれます。
データのクリーニングは通常のプロジェクトでは最も時間を要する作業です。そして、退屈です。
クリーニングしたデータセットだけでは何かを達成した気分になれません。それは中間段階にすぎません。ただし、後続のプロセスでは絶対に必要です。
タスク
私はCode Interpreterにデータセットのクリーニングを依頼しました。私がしなければならなかったのは、生のデータセットをアップロードし、望む形式を指定するだけでした。それ以外は完璧に行われました。
実際には、私自身でこのデータセットをクリーニングしていました。タスクに費やした時間と労力を考えると、Code Interpreterが行ったことは、このプラグインとその可能性についてさらに興奮させました。
また、私はそれについて記事も書いています。Code Interpreterがどれほど素晴らしい仕事をするかを見るために、その記事も読むことをお勧めします。
生のデータセット
このデータセットには、1975年から2016年の間の195カ国の成人の肥満率が含まれています。
Kaggleで公共ドメインライセンスで提供されており、著作権はありませんので、自由にダウンロードして使用してください。また、Code Interpreterによって生成されたコードも共有しますので、自分自身でも試すことができます。
以下は生の形式の例です:
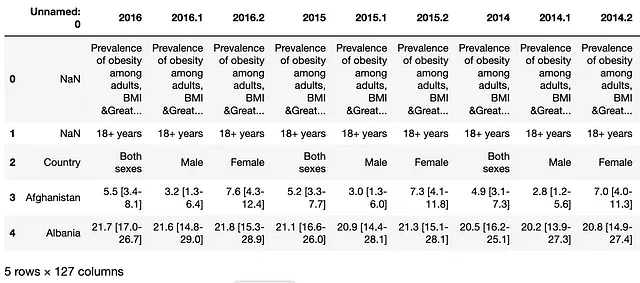
使いやすい形式ではないことは間違いありません。
プロンプト
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
