「Hugging Face Transformersライブラリを解剖する」
Hugging Face Transformers解剖
オープンソースLLMの使い方に関するクイックスタートガイド
これは、実践的な大規模言語モデル(LLM)の使用に関するシリーズの3番目の記事です。ここでは、Hugging Face Transformersライブラリの初心者向けガイドを紹介します。このライブラリは、さまざまなオープンソース言語モデルと簡単かつ無料で作業するための手段を提供します。まず、キーコンセプトの復習から始め、次にPythonの例コードに入ります。
このシリーズの前の記事では、OpenAI Python APIを探求し、カスタムチャットボットを作成しました。ただし、このAPIの欠点は、APIの呼び出しに費用がかかることであり、一部のユースケースにはスケーラビリティがないかもしれません。
このようなシナリオでは、オープンソースのソリューションを利用することが有利になる場合があります。その中でも、Hugging FaceのTransformersライブラリは一般的な方法です。
Hugging Faceとは何ですか?
Hugging Faceは、オープンソースの機械学習(ML)の主要なハブとなったAI企業です。彼らのプラットフォームには、ユーザーが機械学習リソースにアクセスし共有できる3つの主要な要素があります。
- 『過学習から卓越へ:正則化の力を活用する』
- 「5分でPythonとTkinterを使用してシンプルなユーザーフォームを作成する-初心者ガイド」
- 映画チャットをご紹介しますビデオの基礎モデルと大規模な言語モデルを統合した革新的なビデオ理解システムです
まずは、自然言語処理(NLP)、コンピュータビジョンなどのための事前学習済みオープンソースMLモデルの急速に成長しているリポジトリです。2番目は、ほとんどのタスクに対してMLモデルのトレーニングに使用できるデータセットのライブラリです。最後に、Hugging FaceがホストするオープンソースのMLアプリのコレクションであるSpacesがあります。
これらのリソースの強力な点は、それらがコミュニティによって生成されていることで、オープンソースのすべての利点(すなわち、無料、多様なツール、高品質なリソース、素早いイノベーションのペース)を活用していることです。これにより、強力なMLプロジェクトの構築が以前よりも容易になりましたが、Hugging Faceエコシステムのもう1つの重要な要素であるTransformersライブラリもあります。
🤗Transformers
Transformersは、最新のMLモデルのダウンロードとトレーニングを簡単にするPythonライブラリです。最初は言語モデルの開発のために作られましたが、その機能はコンピュータビジョン、音声処理などのモデルも含めて拡張されています。
このライブラリの2つの大きな強みは、1つ目はHugging Face(前述した)のModels、Datasets、Spacesのリポジトリと簡単に統合できること、2つ目はライブラリがPyTorchやTensorFlowなどの人気のあるMLフレームワークもサポートしていることです。
これにより、ダウンロード、トレーニング、デプロイメントのためのシンプルで柔軟なオールインワンプラットフォームが実現します。
Pipeline()
このライブラリを使用する最も簡単な方法は、pipeline()関数を介してNLP(および他の)タスクを1行のコードに抽象化することです。たとえば、感情分析を行いたい場合、モデルを選択し、入力テキストをトークン化し、モデルを通過させ、数値出力をデコードして感情のラベル(ポジティブまたはネガティブ)を判断する必要があります。
これは多くのステップのように思えるかもしれませんが、pipeline()関数を使用することで、以下のコードスニペットに示すように、1行でこれらすべてを行うことができます。
pipeline(task="sentiment-analysis")("Love this!")# 出力 -> [{'label': 'POSITIVE', 'score': 0.9998745918273926}]もちろん、感情分析だけでなく、この方法でほぼすべてのNLPタスクを行うことができます。要約、翻訳、質問応答、特徴抽出(テキスト埋め込み)、テキスト生成、ゼロショット分類など、組み込みタスクの完全なリストについては、pipleine()のドキュメントを参照してください。
上記の例のコードでは、モデルを指定しなかったため、感情分析のデフォルトモデル(つまり、distilbert-base-uncased-finetuned-sst-2-english)が使用されました。ただし、より明示的にするために、次のコードを使用することもできます。
pipeline(task="sentiment-analysis", model='distilbert-base-uncased-finetuned-sst-2-english')("Love this!") # 出力 -> [{'label': 'POSITIVE', 'score': 0.9998745918273926}]Transformersライブラリの最大の利点の1つは、pipeline()関数に渡されるモデル名を変更するだけで、Hugging Faceのモデルリポジトリ内の28,000以上のテキスト分類モデルのいずれかを簡単に使用できることです。
モデル
Hugging Faceには、事前学習済みモデルの巨大なリポジトリがあります(この時点で277,528個あります)。これらのほとんどのモデルは、上記のコードブロックで見た構文を使用して、Transformersを介して簡単に使用できます。
ただし、Hugging FaceのモデルはTransformersライブラリに限定されているわけではありません。他の人気のある機械学習フレームワーク(PyTorch、Tensorflow、Jaxなど)用のモデルもあります。これにより、Hugging Faceのモデルリポジトリは、Transformersライブラリのコンテキストを超えたMLプラクティショナーにとっても有用です。
リポジトリのナビゲーションの例を見るために、以下の例を考えてみましょう。テキスト生成ができるモデルが必要であり、それを1行のコードで使用できるようにしたい場合(上記のように)、”Tasks”と”Libraries”のフィルタを使用してこれらの条件に合致するすべてのモデルを簡単に表示できます。
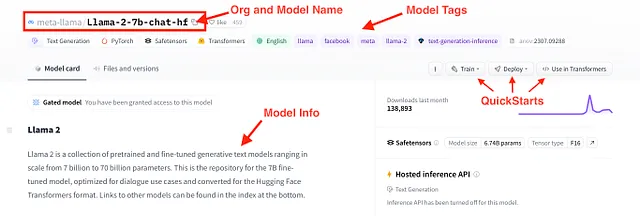
これらの条件に合致するモデルの1つが、新たにリリースされたLlama 2です。具体的には、Llama-2–7b-chat-hfというモデルで、約70億のパラメータを持ち、チャット向けに最適化されており、Hugging Face Transformersの形式で提供されています。このモデルに関する詳細情報は、以下の図に示すモデルカードで確認できます。
🤗Transformers(Condaを使用したインストール)
Hugging FaceとTransformersライブラリが提供するリソースの基本的なアイデアを持っているので、それらをどのように使用するかを見てみましょう。まず、ライブラリとその他の依存関係をインストールします。
Hugging Faceのウェブサイトにはインストールガイドが提供されています。そのため、ここでそのガイドを(まずく)重複させることはしません。ただし、以下の例コードのためのconda環境を設定するためのクイックな2ステップガイドを提供します。
ステップ1)最初に、GitHubリポジトリで入手できるhf-env.ymlファイルをダウンロードします。ファイルを直接ダウンロードするか、リポジトリ全体をクローンできます。
ステップ2)次に、ターミナル(またはAnacondaコマンドプロンプト)で、次のコマンドを使用してhf-env.ymlに基づいて新しいconda環境を作成できます
>>> cd <hf-env.ymlがあるディレクトリ>>>> conda env create --file hf-env.ymlこれには数分かかる場合がありますが、完了したら準備が整います!
例:NLP with 🤗Transformers
必要なライブラリがインストールされたので、いくつかの例コードを見てみましょう。ここでは、pipeline()関数を使用して3つのNLPユースケース、つまり感情分析、要約、対話型テキスト生成を調査します。
最後に、Gradioを使用してこれらのユースケースのいずれかに対してクイックなユーザーインターフェース(UI)を生成し、Hugging Face Spaces上のアプリとして展開します。すべての例コードはGitHubリポジトリで入手できます。
感情分析
感情分析を開始します。以前にpipeline関数を使用して、以下のようなコードブロックで入力テキストを肯定的または否定的にラベル付けする分類器を作成したことを思い出してください。
from transformers import pipeline
classifier = pipeline(task="sentiment-analysis", \
model="distilbert-base-uncased-finetuned-sst-2-english")
classifier("Hate this.")# output -> [{'label': 'NEGATIVE', 'score': 0.9997110962867737}]
一歩進んで、テキストを1つずつ処理する代わりに、リストを分類器に渡してバッチ処理することもできます。
text_list = ["This is great", \
"Thanks for nothing", \
"You've got to work on your face", \
"You're beautiful, never change!"]
classifier(text_list)# output -> [{'label': 'POSITIVE', 'score': 0.9998785257339478},# {'label': 'POSITIVE', 'score': 0.9680058360099792},# {'label': 'NEGATIVE', 'score': 0.8776106238365173},# {'label': 'POSITIVE', 'score': 0.9998120665550232}]
ただし、Hugging Faceのテキスト分類モデルは単にポジティブとネガティブの感情に限定されているわけではありません。例えば、SamLoweの「roberta-base-go_emotions」モデルは、さまざまなクラスのラベルを生成します。以下のコードスニペットに示すように、このモデルをテキストに簡単に適用することもできます。
classifier = pipeline(task="text-classification", \
model="SamLowe/roberta-base-go_emotions", top_k=None)
classifier(text_list[0])# output -> [[{'label': 'admiration', 'score': 0.9526104927062988},# {'label': 'approval', 'score': 0.03047208860516548},# {'label': 'neutral', 'score': 0.015236231498420238},# {'label': 'excitement', 'score': 0.006063772831112146},# {'label': 'gratitude', 'score': 0.005296189337968826},# {'label': 'joy', 'score': 0.004475208930671215},# ... などなど]]
要約
pipeline()関数を使用するもう一つの方法は、テキストの要約に使用することです。これは感情分析とはまったく異なるタスクですが、構文はほぼ同じです。
まず、要約モデルを読み込みます。次に、テキストといくつかの入力パラメータを渡します。
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
text = """Hugging Faceは、オープンソースの機械学習における主要なハブとなったAI企業です。彼らのプラットフォームには、ユーザーが機械学習リソースにアクセスして共有するための3つの主要な要素があります。まず、自然言語処理(NLP)、コンピュータビジョンなどのための事前学習済みオープンソースの機械学習モデルの急速に成長するリポジトリです。次に、ほとんどのタスクに対して機械学習モデルをトレーニングするためのデータセットのライブラリがあります。そして、最後に、オープンソースのMLアプリケーションであるSpacesです。これらのリソースの強力な点は、コミュニティによって生成されていることで、オープンソースの利点である無料、多様なツール、高品質のリソース、革新の速さを活用しています。これにより、以前よりも強力なMLプロジェクトの構築がより手軽になっています。さらに、Hugging Faceエコシステムのもう一つの重要な要素は、彼らのTransformersライブラリです。"""
summarized_text = summarizer(text, min_length=5, max_length=140)[0]['summary_text']
print(summarized_text)# output -> 'Hugging Faceは、オープンソースの機械学習における主要なハブとなったAI企業です。ユーザーは機械学習リソースにアクセスして共有することができます。'
より洗練されたユースケースでは、複数のモデルを連続して使用する必要がある場合があります。例えば、要約されたテキストに感情分析を適用して実行時間を短縮することができます。
classifier(summarized_text)# output -> [[{'label': 'neutral', 'score': 0.9101783633232117}, # {'label': 'approval', 'score': 0.08781372010707855}, # {'label': 'realization', 'score': 0.023256294429302216}, # {'label': 'annoyance', 'score': 0.006623792927712202}, # {'label': 'admiration', 'score': 0.004981081001460552}, # {'label': 'disapproval', 'score': 0.004730119835585356}, # {'label': 'optimism', 'score': 0.0033590723760426044}, # ... などなど]]対話型
最後に、会話文を生成するために特に開発されたモデルを使用することができます。会話では、前のプロンプトと応答を後続のモデル応答に渡す必要があるため、ここでは構文が少し異なります。ただし、まず、pipeline() 関数を使用してモデルをインスタンス化します。
chatbot = pipeline(model="facebook/blenderbot-400M-distill")次に、往復を処理するためにConversation() クラスを使用できます。ユーザープロンプトで初期化し、その後のコードブロックから chatbot モデルに渡します。
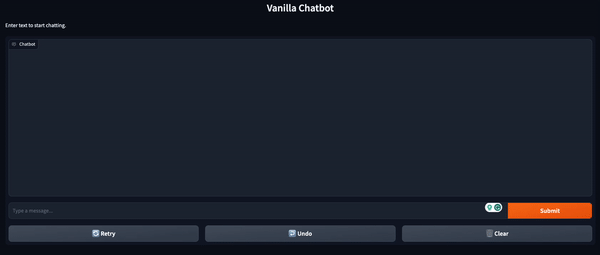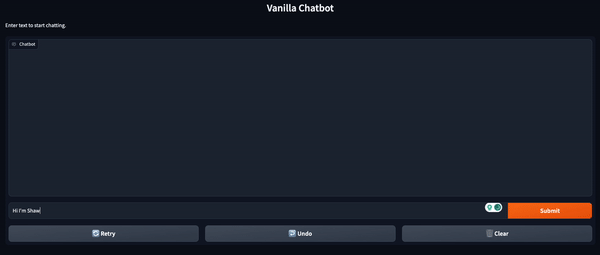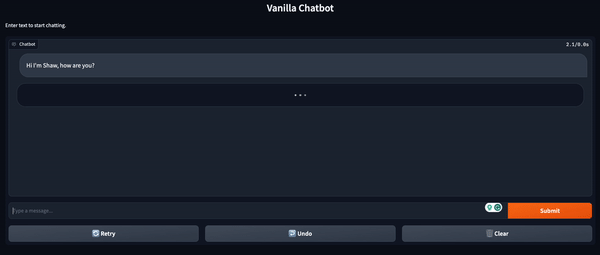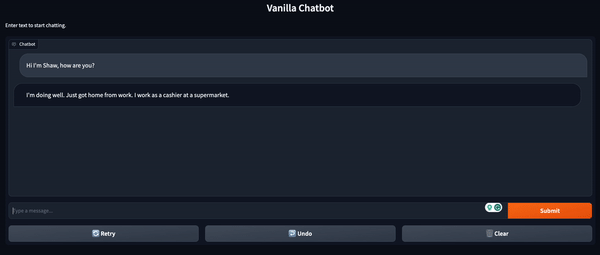
from transformers import Conversationconversation = Conversation("Hi I'm Shaw, how are you?")conversation = chatbot(conversation)print(conversation)# output -> Conversation id: 9248ee7d-2a58-4355-9fba-525189fae206 # user >> Hi I'm Shaw, how are you? # bot >> I'm doing well. How are you doing this evening? I just got home from work. 会話を続けるためには、add_user_input() メソッドを使用して会話に別のプロンプトを追加できます。その後、会話オブジェクトを chatbot に再度渡します。
conversation.add_user_input("Where do you work?")conversation = chatbot(conversation)print(conversation)# output -> Conversation id: 9248ee7d-2a58-4355-9fba-525189fae206 # user >> Hi I'm Shaw, how are you? # bot >> I'm doing well. How are you doing this evening? I just got home from work.# user >> Where do you work? # bot >> I work at a grocery store. What about you? What do you do for a living? Gradio を使用したチャットボットの UI
Transformer ライブラリで基本的なチャットボットの機能を得ることができますが、これはチャットボットとの対話を行うには不便な方法です。対話をより直感的にするために、Python コードの数行で Gradio を使用してフロントエンドを作成することができます。
以下のコードでこれを行います。まず、ユーザーメッセージとモデルの応答を格納するための2つのリストを初期化します。次に、ユーザープロンプトを受け取り、チャットボットの出力を生成する関数を定義します。その後、Gradio ChatInterface() クラスを使用してチャットの UI を作成します。最後に、アプリを起動します。
message_list = []response_list = []def vanilla_chatbot(message, history): conversation = Conversation(text=message, past_user_inputs=message_list, generated_responses=response_list) conversation = chatbot(conversation) return conversation.generated_responses[-1]demo_chatbot = gr.ChatInterface(vanilla_chatbot, title="Vanilla Chatbot", description="Enter text to start chatting.")demo_chatbot.launch()これにより、ローカルの URL を介して UI が起動します。ウィンドウが自動的に開かない場合は、URL をブラウザに直接コピーして貼り付けることができます。
Hugging Face Spaces
さらに一歩進んで、Hugging Face Spacesを使用してこの UI を簡単に展開することができます。これらはHugging Face がホストする Git リポジトリで、計算リソースを拡張するものです。使用ケースに応じて、無料および有料のオプションが利用可能です。ここでは無料オプションを選択します。
新しい Space を作成するには、まず Spaces ページに移動し、[新しいスペースを作成] をクリックします。次に、名前(例: “my-first-space”)を付けて、SDK として Gradio を選択して、[スペースを作成] をクリックします。
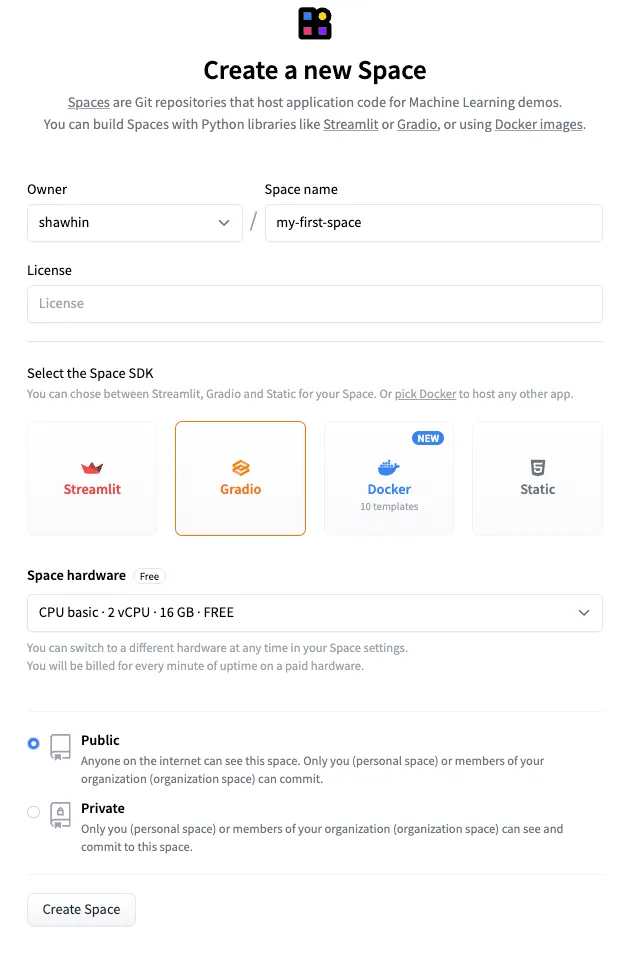
次に、app.pyとrequirements.txtファイルをSpaceにアップロードする必要があります。app.pyファイルには、Gradio UIを生成するために使用したコードが格納されており、requirements.txtファイルにはアプリの依存関係が指定されています。この例のファイルはGitHubのリポジトリとHugging Face Spaceで利用できます。
最後に、コードをSpaceにGitHubと同様にプッシュします。結果として、Hugging Face Spacesにホストされた公開アプリが作成されます。
アプリのリンク: https://huggingface.co/spaces/shawhin/my-first-space
結論
Hugging Faceは、オープンソースの言語モデルと機械学習の代名詞となっています。そのエコシステムの最大の利点は、小規模な開発者、研究者、そしてハッカーが強力な機械学習リソースにアクセスできることです。
この記事では多くの内容をカバーしましたが、Hugging Faceのエコシステムができることはまだごく一部です。このシリーズの将来の記事では、より高度なユースケースを探求し、🤗Transformersを使用してモデルを微調整する方法についても説明します。
👉 LLMsの詳細: 紹介 | OpenAI API
リソース
接続: 私のウェブサイト | 電話を予約する | 何でも質問してください
ソーシャル: YouTube 🎥 | LinkedIn | Twitter
サポート: メンバーになる ⭐️ | コーヒーを買ってください ☕️
データ起業家
データスペースの起業家のためのコミュニティ。👉 Discordに参加してください!
VoAGI.com
[1] Hugging Face — https://huggingface.co/
[2] Hugging Faceコース — https://huggingface.co/learn/nlp-course/chapter1/1
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles