Hugging Faceを使用してWav2Vec2を英語音声認識のために微調整する
'Hugging Faceの使用でWav2Vec2を英語音声認識のために微調整する'
![]()
Wav2Vec2は、自動音声認識(ASR)のための事前学習済みモデルであり、Alexei Baevski、Michael Auli、Alex Conneauによって2020年9月にリリースされました。
Wav2Vec2は、革新的な対比的事前学習目標を使用して、50,000時間以上の未ラベル音声から強力な音声表現を学習します。BERTのマスクされた言語モデリングと同様に、モデルはトランスフォーマーネットワークに渡す前に特徴ベクトルをランダムにマスクすることで、文脈化された音声表現を学習します。
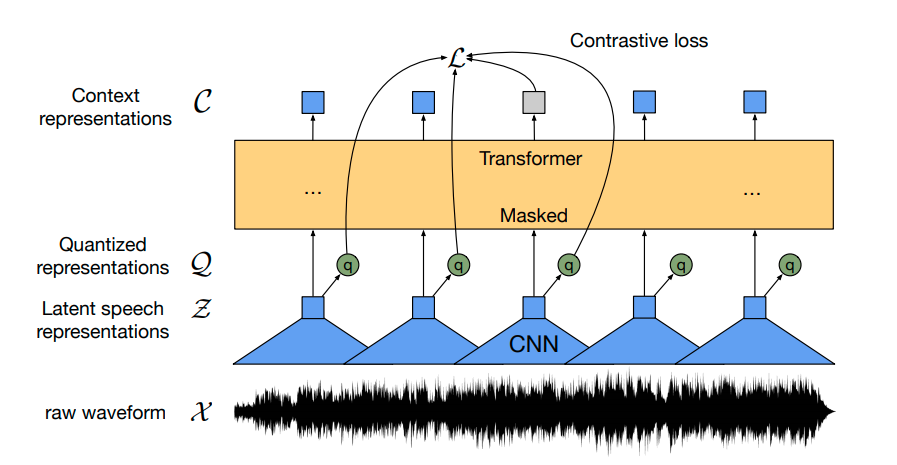
初めて、事前学習に続いてわずかなラベル付き音声データで微調整することで、最先端のASRシステムと競合する結果が得られることが示されました。Wav2Vec2は、わずか10分のラベル付きデータを使用しても、LibriSpeechのクリーンテストセットで5%未満の単語エラーレート(WER)を実現します – 論文の表9を参照してください。
このノートブックでは、Wav2Vec2の事前学習チェックポイントをどの英語のASRデータセットでも微調整する方法について詳しく説明します。このノートブックでは、言語モデルを使用せずにWav2Vec2を微調整します。言語モデルを使用しないWav2Vec2は、エンドツーエンドのASRシステムとして非常にシンプルであり、スタンドアロンのWav2Vec2音響モデルでも印象的な結果が得られることが示されています。デモンストレーションの目的で、わずか5時間のトレーニングデータしか含まれていないTimitデータセットで「base」サイズの事前学習チェックポイントを微調整します。
Wav2Vec2は、コネクショニスト時系列分類(CTC)を使用して微調整されます。CTCは、シーケンス対シーケンスの問題に対してニューラルネットワークを訓練するために使用されるアルゴリズムであり、主に自動音声認識および筆記認識に使用されます。
Awni Hannunによる非常にわかりやすいブログ記事Sequence Modeling with CTC(2017)を読むことを強くお勧めします。
始める前に、datasetsとtransformersを最新バージョンからインストールすることを強くお勧めします。また、オーディオファイルを読み込むためにsoundfileパッケージと、単語エラーレート(WER)メトリックを使用して微調整モデルを評価するためにjiwerが必要です1 {}^1 1 。
!pip install datasets>=1.18.3
!pip install transformers==4.11.3
!pip install librosa
!pip install jiwer次に、トレーニング中にトレーニングチェックポイントをHugging Face Hubに直接アップロードすることを強くお勧めします。Hubには統合されたバージョン管理があり、トレーニング中にモデルチェックポイントが失われることはありません。
これを行うには、Hugging Faceのウェブサイトから認証トークンを保存する必要があります(まだ登録していない場合はこちらでサインアップしてください!)
from huggingface_hub import notebook_login
notebook_login()出力結果:
ログインに成功しました
トークンは/root/.huggingface/tokenに保存されました
Gitの資格情報ストアを介して認証されましたが、これはマシン上で定義されたヘルパーではありません。
Hugging Face Hubにプッシュするときに再認証する必要があります。ターミナルで次のコマンドを実行して、デフォルトに設定します
git config --global credential.helper storeその後、モデルチェックポイントをアップロードするためにGit LFSをインストールする必要があります:
!apt install git-lfs1 {}^1 1 Timitは通常、音素エラーレート(PER)を使用して評価されますが、ASRで最も一般的なメトリックは単語エラーレート(WER)です。このノートブックをできるだけ一般的に保つために、WERを使用してモデルを評価することにしました。
データの準備、トークナイザー、特徴抽出器
ASRモデルは音声をテキストに変換するため、音声信号をモデルの入力形式(例:特徴ベクトル)に処理するための特徴抽出器と、モデルの出力形式をテキストに処理するためのトークナイザーの両方が必要です。
🤗 Transformersでは、Wav2Vec2モデルにはWav2Vec2CTCTokenizerと呼ばれるトークナイザーとWav2Vec2FeatureExtractorと呼ばれる特徴抽出器が付属しています。
モデルの予測結果をデコードするためのトークナイザの作成から始めましょう。
Wav2Vec2CTCTokenizerの作成
事前学習済みのWav2Vec2チェックポイントは、上記の図に示されているように音声信号をコンテキスト表現のシーケンスにマッピングします。ファインチューニングされたWav2Vec2チェックポイントは、このコンテキスト表現のシーケンスを対応する転写にマッピングする必要があります。そのため、トランスフォーマーブロックの上に線形層(黄色で示されています)を追加する必要があります。この線形層は、例えばBERTの埋め込みにさらなる分類のための線形層が事前学習後に追加されるのと同様に、各コンテキスト表現をトークンクラスに分類します。
この層の出力サイズは、ボキャブラリのトークン数に対応しています。これは、Wav2Vec2の事前学習タスクには依存せず、ファインチューニングに使用されるラベル付きデータセットにのみ依存します。そのため、最初のステップでは、Timitを見て、データセットの転写に基づいてボキャブラリを定義します。
データセットをロードして、その構造を確認することから始めましょう。
from datasets import load_dataset, load_metric
timit = load_dataset("timit_asr")
print(timit)出力結果:
DatasetDict({
train: Dataset({
features: ['file', 'audio', 'text', 'phonetic_detail', 'word_detail', 'dialect_region', 'sentence_type', 'speaker_id', 'id'],
num_rows: 4620
})
test: Dataset({
features: ['file', 'audio', 'text', 'phonetic_detail', 'word_detail', 'dialect_region', 'sentence_type', 'speaker_id', 'id'],
num_rows: 1680
})
})多くのASRデータセットでは、各オーディオファイル'file'に対してターゲットテキスト'text'のみが提供されます。Timitでは、'phonetic_detail'など、各オーディオファイルに関するさらに多くの情報が提供されるため、多くの研究者はTimitで作業する際に音素の分類ではなく音声認識でモデルを評価することを選びます。しかし、ノートブックをできるだけ一般的なものにしたいので、ファインチューニングには転写テキストのみを考慮します。
timit = timit.remove_columns(["phonetic_detail", "word_detail", "dialect_region", "id", "sentence_type", "speaker_id"])データセットのいくつかのランダムなサンプルを表示するための短い関数を書いて、それを数回実行して転写についての感触をつかんでみましょう。
from datasets import ClassLabel
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=10):
assert num_examples <= len(dataset), "データセット内の要素より多くの要素を選択することはできません。"
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
display(HTML(df.to_html()))
show_random_elements(timit["train"].remove_columns(["file", "audio"]))出力結果:
よし!転写は非常にきれいで、言語は対話ではなく書かれたテキストに対応しているようです。これは、Timitが読み上げ音声コーパスであることを考慮に入れると理にかなっています。
転写には,.?!;:などの特殊文字が含まれていることがわかります。特殊文字は、言語モデルがないと、特徴的な音声単位に対応しないため、音声チャンクを特殊文字に分類するのははるかに難しいです。例えば、文字"s"は比較的明確な音を持っていますが、特殊文字"."はそうではありません。また、音声信号の意味を理解するためには、通常、転写に特殊文字を含める必要はありません。
さらに、テキストを小文字のみに正規化します。
import re
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"]'
def remove_special_characters(batch):
batch["text"] = re.sub(chars_to_ignore_regex, '', batch["text"]).lower()
return batch
timit = timit.map(remove_special_characters)前処理された転写を見てみましょう。
show_random_elements(timit["train"].remove_columns(["file", "audio"]))出力:
良いですね!これは見やすくなりました。転写からほとんどの特殊文字を削除し、すべて小文字に正規化しました。
CTCでは、音声チャンクを文字に分類することが一般的ですので、ここでも同様に行います。トレーニングデータとテストデータのすべての異なる文字を抽出し、この文字のセットから語彙を構築しましょう。
すべての転写を1つの長い転写に連結し、その文字列を文字のセットに変換するマッピング関数を作成します。マッピング関数がすべての転写にアクセスできるようにするために、map(...)関数に引数batched=Trueを渡すことが重要です。
def extract_all_chars(batch):
all_text = " ".join(batch["text"])
vocab = list(set(all_text))
return {"vocab": [vocab], "all_text": [all_text]}
vocabs = timit.map(extract_all_chars, batched=True, batch_size=-1, keep_in_memory=True, remove_columns=timit.column_names["train"])次に、トレーニングデータセットとテストデータセットのすべての異なる文字の結合を作成し、その結果のリストを列挙された辞書に変換します。
vocab_list = list(set(vocabs["train"]["vocab"][0]) | set(vocabs["test"]["vocab"][0]))
vocab_dict = {v: k for k, v in enumerate(vocab_list)}
vocab_dict出力:
{
' ': 21,
"'": 13,
'a': 24,
'b': 17,
'c': 25,
'd': 2,
'e': 9,
'f': 14,
'g': 22,
'h': 8,
'i': 4,
'j': 18,
'k': 5,
'l': 16,
'm': 6,
'n': 7,
'o': 10,
'p': 19,
'q': 3,
'r': 20,
's': 11,
't': 0,
'u': 26,
'v': 27,
'w': 1,
'x': 23,
'y': 15,
'z': 12
}素晴らしいですね、アルファベットのすべての文字がデータセットに含まれていることがわかります(それは驚くべきことではありませんが)、さらに、特殊文字" "と'も抽出しました。なぜこれらの特殊文字を除外しなかったかというと:
- モデルは単語の終了を予測する必要があります。そうでないと、モデルの予測は常に文字のシーケンスになってしまい、単語を他の単語から分離することができません。
- 英語では、
'の文字を保持する必要があります。なぜなら、"it's"と"its"は非常に異なる意味を持つからです。
" "が独自のトークンクラスを持つことを明確にするために、より目立つ文字|を使用します。さらに、Timitのトレーニングセットで遭遇しなかった文字に対応できるように、”unknown”トークンも追加します。
vocab_dict["|"] = vocab_dict[" "]
del vocab_dict[" "]最後に、CTCの「空白トークン」に対応するパディングトークンも追加します。 「空白トークン」はCTCアルゴリズムの核となる要素です。詳細については、こちらの「Alignment」セクションをご覧ください。
vocab_dict["[UNK]"] = len(vocab_dict)
vocab_dict["[PAD]"] = len(vocab_dict)
print(len(vocab_dict))出力:
30素晴らしい!これで語彙が完成し、30のトークンで構成されています。つまり、事前学習済みのWav2Vec2チェックポイントの上に追加する線形層の出力次元は30になります。
さあ、語彙をjsonファイルとして保存しましょう。
import json
with open('vocab.json', 'w') as vocab_file:
json.dump(vocab_dict, vocab_file)最後のステップでは、jsonファイルを使用してWav2Vec2CTCTokenizerクラスのオブジェクトをインスタンス化します。
from transformers import Wav2Vec2CTCTokenizer
tokenizer = Wav2Vec2CTCTokenizer("./vocab.json", unk_token="[UNK]", pad_token="[PAD]", word_delimiter_token="|")このノートブックのファインチューニングモデルで作成したトークナイザーを再利用する場合は、tokenizerを🤗 Hubにアップロードすることを強くお勧めします。アップロードするリポジトリの名前を"wav2vec2-large-xlsr-turkish-demo-colab"としましょう:
repo_name = "wav2vec2-base-timit-demo-colab"そして、トークナイザーを🤗 Hubにアップロードします。
tokenizer.push_to_hub(repo_name)素晴らしいですね、作成したリポジトリはhttps://huggingface.co/<your-username>/wav2vec2-base-timit-demo-colabの下に表示されます
Wav2Vec2フィーチャーエクストラクターの作成
音声は連続的な信号であり、コンピュータで扱うためには、まずサンプリングと呼ばれる処理で離散化する必要があります。ここで重要な役割を果たすのは、サンプリングレートです。これによって、1秒ごとに測定される音声信号のデータポイントの数が定義されます。したがって、より高いサンプリングレートでサンプリングすると、実際の音声信号のより良い近似が得られますが、1秒あたりの値も増えます。
事前学習済みのチェックポイントでは、入力データが学習に使用されたデータと同じ分布からサンプリングされていることが期待されます。同じ音声信号を2つの異なるサンプリングレートでサンプリングすると、非常に異なる分布になります。例えば、サンプリングレートを倍にすると、データポイントの長さも2倍になります。したがって、ASRモデルの事前学習済みチェックポイントをファインチューニングする前に、モデルの事前学習に使用されたデータのサンプリングレートがファインチューニングに使用するデータセットのサンプリングレートと一致するかどうかを確認することは非常に重要です。
Wav2Vec2はLibriSpeechとLibriVoxの音声データで事前学習されており、どちらも16kHzでサンプリングされていました。ファインチューニングに使用するデータセットであるTimitも幸いにも16kHzでサンプリングされています。もしファインチューニングに使用するデータセットのサンプリングレートが16kHzより低いか高い場合は、事前学習に使用したデータのサンプリングレートに合わせるために音声信号をアップサンプリングまたはダウンサンプリングする必要があります。
Wav2Vec2のフィーチャーエクストラクターオブジェクトをインスタンス化するには、次のパラメータが必要です:
feature_size:音声モデルは、入力としてフィーチャーベクトルのシーケンスを受け取ります。このシーケンスの長さは明らかに異なりますが、フィーチャーサイズは同じである必要があります。Wav2Vec2の場合、フィーチャーサイズは1であり、モデルは生の音声信号に対してトレーニングされています。sampling_rate:モデルのトレーニングに使用されたサンプリングレートです。padding_value:バッチ推論のために、より短い入力は特定の値でパディングする必要があります。do_normalize:入力をゼロ平均単位分散正規化するかどうかを示します。通常、音声モデルは入力を正規化すると性能が向上します。return_attention_mask:モデルがバッチ推論でattention_maskを使用するかどうかを示します。一般的に、モデルはパディングされたトークンをマスクするためにattention_maskを常に使用する必要があります。ただし、Wav2Vec2の”base”チェックポイントの非常に特定の設計上の選択により、attention_maskを使用しない方がより良い結果が得られます。これは他の音声モデルでは推奨されません。詳細については、この問題を参照してください。 重要:このノートブックをlarge-lv60のファインチューニングに使用する場合、このパラメータをTrueに設定する必要があります。
from transformers import Wav2Vec2FeatureExtractor
feature_extractor = Wav2Vec2FeatureExtractor(feature_size=1, sampling_rate=16000, padding_value=0.0, do_normalize=True, return_attention_mask=False)素晴らしい、Wav2Vec2の特徴抽出パイプラインが完全に定義されました!
Wav2Vec2の使用を可能な限りユーザーフレンドリーにするために、特徴抽出器とトークナイザーは1つのWav2Vec2Processorクラスにラップされており、モデルとプロセッサオブジェクトだけが必要です。
from transformers import Wav2Vec2Processor
processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)データの前処理
これまで、音声信号の実際の値を見ていませんでしたが、転写のみを見ていました。文の他に、データセットにはpathとaudioという2つの列名が含まれています。pathはオーディオファイルの絶対パスを示しています。詳細を確認しましょう。
print(timit[0]["path"])出力:
'/root/.cache/huggingface/datasets/downloads/extracted/404950a46da14eac65eb4e2a8317b1372fb3971d980d91d5d5b221275b1fd7e0/data/TRAIN/DR4/MMDM0/SI681.WAV'Wav2Vec2は、1次元の16kHzの配列形式の入力を期待しています。これは、オーディオファイルをロードしてリサンプリングする必要があることを意味します。
幸いなことに、datasetsはこれを自動的に行います。他の列audioを呼び出すことで、試してみましょう。
common_voice_train[0]["audio"]出力:
{'array': array([-2.1362305e-04, 6.1035156e-05, 3.0517578e-05, ...,
-3.0517578e-05, -9.1552734e-05, -6.1035156e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/404950a46da14eac65eb4e2a8317b1372fb3971d980d91d5d5b221275b1fd7e0/data/TRAIN/DR4/MMDM0/SI681.WAV',
'sampling_rate': 16000}オーディオファイルが自動的にロードされたことがわかります。これは、datasets == 4.13.3で導入された新しい"Audio"の機能によるもので、呼び出し時にオーディオファイルをオンザフライでロードしてリサンプリングします。
サンプリングレートは16kHzに設定されており、これがWav2Vec2が入力として期待するものです。
素晴らしい、データセットをより良く理解し、オーディオが正しくロードされたことを検証するために、いくつかのオーディオファイルを聞いてみましょう。
import IPython.display as ipd
import numpy as np
import random
rand_int = random.randint(0, len(timit["train"]))
print(timit["train"][rand_int]["text"])
ipd.Audio(data=np.asarray(timit["train"][rand_int]["audio"]["array"]), autoplay=True, rate=16000)聞くことができますが、話者が変わり、話速やアクセントなども変わります。全体的には、録音は比較的クリアに聞こえますが、これは読み上げ音声コーパスから期待されるものです。
最後に、データが正しく準備されているかを最終的にチェックするために、音声入力の形状、転写、および対応するサンプリングレートを出力してみましょう。
rand_int = random.randint(0, len(timit["train"]))
print("Target text:", timit["train"][rand_int]["text"])
print("Input array shape:", np.asarray(timit["train"][rand_int]["audio"]["array"]).shape)
print("Sampling rate:", timit["train"][rand_int]["audio"]["sampling_rate"])出力:
Target text: she had your dark suit in greasy wash water all year
Input array shape: (52941,)
Sampling rate: 16000良いです!全て正常に見えます – データは1次元の配列で、サンプリングレートは常に16kHzに対応しており、ターゲットテキストが正規化されています。
最後に、モデルのトレーニングに期待される形式でデータセットを処理できるようにします。 map(...)関数を使用します。
まず、batch["audio"] を呼び出すことでオーディオデータをロードしてリサンプリングします。次に、ロードされたオーディオファイルから input_values を抽出します。この場合、Wav2Vec2Processor はデータを正規化するだけです。ただし、他の音声モデルの場合、このステップには Log-Mel 特徴抽出など、より複雑な特徴抽出が含まれることがあります。その後、トランスクリプションをラベル ID にエンコードします。
注意:このマッピング関数は、Wav2Vec2Processor クラスの使用方法の良い例です。通常のコンテキストでは、processor(...) を呼び出すと Wav2Vec2FeatureExtractor の呼び出しメソッドにリダイレクトされます。ただし、プロセッサを as_target_processor コンテキストにラップする場合、同じメソッドは Wav2Vec2CTCTokenizer の呼び出しメソッドにリダイレクトされます。詳細についてはドキュメントを参照してください。
def prepare_dataset(batch):
audio = batch["audio"]
# バッチ処理された出力は正しいマッピングを保証するために "un-batched" になります
batch["input_values"] = processor(audio["array"], sampling_rate=audio["sampling_rate"]).input_values[0]
with processor.as_target_processor():
batch["labels"] = processor(batch["text"]).input_ids
return batchデータの準備関数をすべての例に適用しましょう。
timit = timit.map(prepare_dataset, remove_columns=timit.column_names["train"], num_proc=4)注意:現在、datasets ではオーディオのロードとリサンプリングに torchaudio と librosa を使用しています。独自のカスタマイズされたデータのロード/サンプリングを実装したい場合は、"path" 列だけを使用し、"audio" 列を無視してください。
トレーニングと評価
データが処理されたので、トレーニングパイプラインの設定を開始する準備が整いました。🤗 の Trainer を使用するために、次の手順を実行する必要があります:
-
データコレータを定義します。一般的な NLP モデルとは異なり、Wav2Vec2 は入力の長さが出力の長さよりもはるかに大きいです。たとえば、入力長が 50000 のサンプルの出力長は 100 を超えません。大きな入力サイズのため、トレーニングバッチを動的にパディングする方が効率的です。つまり、すべてのトレーニングサンプルは、そのバッチ内の最長サンプルにのみパディングされ、全体の最長サンプルにはパディングされません。したがって、Wav2Vec2 のファインチューニングには特殊なパディングデータコレータが必要です。以下で定義します。
-
評価指標。トレーニング中、モデルは単語エラーレートで評価されるべきです。それに応じた
compute_metrics関数を定義する必要があります。 -
事前学習済みのチェックポイントをロードします。事前学習済みのチェックポイントをロードし、トレーニングのために正しく設定する必要があります。
-
トレーニングの設定を定義します。
モデルのファインチューニングが完了したら、テストデータで正しく評価し、音声の正しい転写を学習していることを確認します。
Trainer のセットアップ
まず、データコレータを定義します。データコレータのコードはこの例からコピーされました。
詳細には立ち入らず、一般的なデータコレータとは異なり、このデータコレータは input_values と labels を異なる方法で処理し、それぞれに別々のパディング関数を適用します(Wav2Vec2 のコンテキストマネージャを使用しています)。これは、音声の入力と出力が異なるモダリティであるため、同じパディング関数で処理してはならないためです。一般的なデータコレータと同様に、ラベルのパディングトークンには -100 を設定して、これらのトークンが損失の計算に含まれないようにします。
import torch
from dataclasses import dataclass, field
from typing import Any, Dict, List, Optional, Union
@dataclass
class DataCollatorCTCWithPadding:
"""
受け取った入力を動的にパディングするデータコレータです。
Args:
processor (:class:`~transformers.Wav2Vec2Processor`)
データの処理に使用されるプロセッサ。
padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
パディングストラテジーを選択します(モデルのパディングサイドとパディングインデックスに従って、返されたシーケンスをパディングします):
* :obj:`True` または :obj:`'longest'`:バッチ内の最長シーケンスにパディングします(単一のシーケンスの場合はパディングしない)。
* :obj:`'max_length'`:引数 :obj:`max_length` で指定された最大長さにパディングします。引数が指定されていない場合はモデルの最大許容入力長にパディングします。
* :obj:`False` または :obj:`'do_not_pad'`(デフォルト):パディングなし(つまり、長さが異なるシーケンスのバッチを出力できます)。
max_length (:obj:`int`, `optional`):
返されたリストの ``input_values`` の最大長さおよびオプションのパディング長(上記を参照)。
max_length_labels (:obj:`int`, `optional`):
返されたリストの ``labels`` の最大長さおよびオプションのパディング長(上記を参照)。
pad_to_multiple_of (:obj:`int`, `optional`):
指定された値の倍数にシーケンスをパディングします。これは、Tensor Cores を NVIDIA ハードウェアで使用するために特に有用です(compute capability >= 7.5(Volta))。
"""
processor: Wav2Vec2Processor
padding: Union[bool, str] = True
max_length: Optional[int] = None
max_length_labels: Optional[int] = None
pad_to_multiple_of: Optional[int] = None
pad_to_multiple_of_labels: Optional[int] = None
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# 入力とラベルを分割し、異なる長さであるために異なるパディング関数を適用します(Wav2Vec2 のコンテキストマネージャを使用しています)
input_features = [{"input_values": feature["input_values"]} for feature in features]
label_features = [{"input_ids": feature["labels"]} for feature in features]
batch = self.processor.pad(
input_features,
padding=self.padding,
データコレータを初期化しましょう。
data_collator = DataCollatorCTCWithPadding(processor=processor, padding=True)
次に、評価メトリックを定義します。先ほども述べたように、ASRで主要なメトリックは単語エラーレート(WER)ですので、このノートブックでも使用します。
wer_metric = load_metric("wer")
モデルは、ログットベクトルのシーケンスを返します:
y 1 , … , y m \mathbf{y}_1, \ldots, \mathbf{y}_m y 1 , … , y m ,
ただし、 y 1 = f θ ( x 1 , … , x n ) [ 0 ] \mathbf{y}_1 = f_{\theta}(x_1, \ldots, x_n)[0] y 1 = f θ ( x 1 , … , x n ) [ 0 ] であり、 n > > m n >> m n > > m です。
ログットベクトル y 1 \mathbf{y}_1 y 1 には、先ほど定義した語彙の各単語のログオッズが含まれています。そのため、 len ( y i ) = \text{len}(\mathbf{y}_i) = len ( y i ) = config.vocab_size です。モデルの最もありそうな予測に興味があり、ログットの argmax(...) を取ります。また、エンコードされたラベルを元の文字列に戻すために、 -100 を pad_token_id で置き換え、連続するトークンが CTC スタイル 1 {}^1 1 にグループ化されないようにしながら ID をデコードします。
def compute_metrics(pred):
pred_logits = pred.predictions
pred_ids = np.argmax(pred_logits, axis=-1)
pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
pred_str = processor.batch_decode(pred_ids)
# メトリックを計算する際にトークンをグループ化したくないため
label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
wer = wer_metric.compute(predictions=pred_str, references=label_str)
return {"wer": wer}
これで、事前学習済みの Wav2Vec2 チェックポイントをロードできます。トークナイザの pad_token_id をモデルの pad_token_id または Wav2Vec2ForCTC の CTC のブランクトークン 2 {}^2 2 に設定する必要があります。GPUメモリを節約するために、PyTorchの勾配チェックポイントを有効にし、損失の縮小を " mean " に設定します。
from transformers import Wav2Vec2ForCTC
model = Wav2Vec2ForCTC.from_pretrained(
"facebook/wav2vec2-base",
ctc_loss_reduction="mean",
pad_token_id=processor.tokenizer.pad_token_id,
)
出力を表示:
Some weights of Wav2Vec2ForCTC were not initialized from the model checkpoint at facebook/wav2vec2-base and are newly initialized: ['lm_head.weight', 'lm_head.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Wav2Vec2の最初のコンポーネントは、生の音声信号から音響的に意味のあるが文脈に依存しない特徴を抽出するために使用されるCNN層のスタックです。このモデルのこの部分は、事前学習中に十分にトレーニングされており、さらなる微調整は必要ありません。したがって、特徴抽出部のすべてのパラメータの requires_grad を False に設定できます。
model.freeze_feature_extractor()
最後のステップでは、トレーニングに関連するすべてのパラメータを定義します。いくつかのパラメータについて説明します:
group_by_length は、入力の長さが似ているトレーニングサンプルを1つのバッチにグループ化することで、トレーニングをより効率的に行います。これにより、モデルを通過する無駄なパディングトークンの総数が大幅に減少し、トレーニング時間が大幅に短縮されますlearning_rate と weight_decay は、微調整が安定した状態になるまで経験的に調整されました。これらのパラメータは Timit データセットに強く依存し、他の音声データセットには最適ではない可能性があります。
他のパラメータの詳細については、ドキュメントを参照してください。
トレーニング中、チェックポイントは400回のトレーニングステップごとに非同期でハブにアップロードされます。これにより、モデルのトレーニング中でもデモウィジェットを操作できます。
注意: モデルのチェックポイントをハブにアップロードしたくない場合は、push_to_hub=Falseと設定します。
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir=repo_name,
group_by_length=True,
per_device_train_batch_size=32,
evaluation_strategy="steps",
num_train_epochs=30,
fp16=True,
gradient_checkpointing=True,
save_steps=500,
eval_steps=500,
logging_steps=500,
learning_rate=1e-4,
weight_decay=0.005,
warmup_steps=1000,
save_total_limit=2,
)
これで、すべてのインスタンスをTrainerに渡し、トレーニングを開始する準備が整いました!
from transformers import Trainer
trainer = Trainer(
model=model,
data_collator=data_collator,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=timit_prepared["train"],
eval_dataset=timit_prepared["test"],
tokenizer=processor.feature_extractor,
)
1 {}^1 1 モデルが話者の速度に依存しないようにするために、CTCでは、連続する同じトークンは単一のトークンとしてグループ化されます。ただし、エンコードされたラベルはデコード時にグループ化されないため、モデルの予測トークンに対応しないため、group_tokens=Falseパラメータを渡す必要があります。このパラメータを渡さないと、"hello"のような単語が誤ってエンコードされ、"helo"としてデコードされます。
2 {}^2 2 ブランクトークンにより、モデルは"hello"のような単語を予測することができます。ブランクトークンを2つのlの間に挿入することで、"hello"のCTC-conform予測は[PAD] [PAD] "h" "e" "e" "l" "l" [PAD] "l" "o" "o" [PAD]となります。
トレーニング
トレーニングには、このノートブックに接続されているGoogle Colabに割り当てられたGPUによって、90分から180分かかります。訓練されたモデルはTimitのテストデータで満足のいく結果を示しますが、最適に微調整されたモデルではありません。このノートブックの目的は、Wav2Vec2のbase、large、およびlarge-lv60のチェックポイントを任意の英語のデータセットで微調整する方法を示すことです。
このGoogle Colabを使用してモデルを微調整する場合、トレーニングが非アクティブになることを防ぐ必要があります。これを防ぐための簡単なハックは、次のコードをこのタブのコンソールに貼り付けることです(右クリック -> 検証 -> コンソールタブにコードを挿入)。
function ConnectButton(){
console.log("Connect pushed");
document.querySelector("#top-toolbar > colab-connect-button").shadowRoot.querySelector("#connect").click()
}
setInterval(ConnectButton,60000);
trainer.train()
GPUによっては、ここで"out-of-memory"エラーが発生する可能性があります。その場合は、per_device_train_batch_sizeを16またはそれ以下に減らし、必要に応じてgradient_accumulationを使用するのが最善です。
プリントアウト:
最終的なWERは0.3未満であるべきです。これは、最新の音素エラー率(PER)が0.1未満であること(リーダーボードを参照)と、WERが通常PERよりも悪いことを考慮すると、合理的な値です。
トレーニングの結果をハブにアップロードするには、次の命令を実行してください。
trainer.push_to_hub()
このモデルを友達、家族、お気に入りのペットと共有できます。識別子"your-username/the-name-you-picked"でロードできます。たとえば:
from transformers import AutoModelForCTC, Wav2Vec2Processor
model = AutoModelForCTC.from_pretrained("patrickvonplaten/wav2vec2-base-timit-demo-colab")
processor = Wav2Vec2Processor.from_pretrained("patrickvonplaten/wav2vec2-base-timit-demo-colab")
評価
最後の部分では、テストセット上で微調整したモデルを評価し、それを少しいじってみます。
processorとmodelをロードしましょう。
processor = Wav2Vec2Processor.from_pretrained(repo_name)
model = Wav2Vec2ForCTC.from_pretrained(repo_name)
次に、map(...)関数を使用して、すべてのテストサンプルの転写を予測し、予測結果をデータセット自体に保存します。結果の辞書を"results"と呼びます。
注意:この問題のために、テストデータセットをbatch_size=1で評価しています。パディングされた入力は非パディングされた入力と完全に同じ出力を生成しないため、入力を一切パディングしない方がより良いWERを得ることができます。
def map_to_result(batch):
with torch.no_grad():
input_values = torch.tensor(batch["input_values"], device="cuda").unsqueeze(0)
logits = model(input_values).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_str"] = processor.batch_decode(pred_ids)[0]
batch["text"] = processor.decode(batch["labels"], group_tokens=False)
return batch
results = timit["test"].map(map_to_result, remove_columns=timit["test"].column_names)
さあ、全体のWERを計算しましょう。
print("Test WER: {:.3f}".format(wer_metric.compute(predictions=results["pred_str"], references=results["text"])))
出力結果:
Test WER: 0.221
22.1%のWER - 悪くありません!私たちのデモモデルはおそらく公式のリーダーボードに載ることができたでしょう。
モデルがどのようなエラーを犯すかを確認するために、いくつかの予測結果を見てみましょう。
出力結果:
show_random_elements(results.remove_columns(["speech", "sampling_rate"]))
予測された転写は音響的には目標の転写に非常に似ていることが明らかになりますが、つづりや文法のエラーが多く含まれています。これは、言語モデルを使用せずにWav2Vec2に完全に依存しているため、非常に驚くべきことではありません。
最後に、CTCの動作をより深く理解するために、モデルの正確な出力を詳しく見てみる価値があります。最初のテストサンプルをモデルに通し、予測されたIDを取得し、それらを対応するトークンに変換しましょう。
model.to("cuda")
with torch.no_grad():
logits = model(torch.tensor(timit["test"][:1]["input_values"], device="cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
# IDをトークンに変換
" ".join(processor.tokenizer.convert_ids_to_tokens(pred_ids[0].tolist()))
出力結果:
[PAD] [PAD] [PAD] [PAD] [PAD] [PAD] t t h e e | | b b [PAD] u u n n n g g [PAD] a [PAD] [PAD] l l [PAD] o o o [PAD] | w w a a [PAD] s s | | [PAD] [PAD] p l l e e [PAD] [PAD] s s e n n t t t [PAD] l l y y | | | s s [PAD] i i [PAD] t t t [PAD] u u u u [PAD] [PAD] [PAD] a a [PAD] t t e e e d d d | n n e e a a a r | | t h h e | | s s h h h [PAD] o o o [PAD] o o r r [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
この出力は、CTCが実際にどのように動作するかを少し明確にしてくれるはずです。モデルは、分類する音声チャンクがまだ同じトークンに対応している場合、単に同じトークンを繰り返すことを学習しているため、話す速度にある程度不変です。これにより、CTCは音声認識に非常に強力なアルゴリズムとなります。音声ファイルの転写は、その長さとはほとんど関係なく、独立していることが多いからです。
CTCをより理解するために、読者にはこの素晴らしいブログ記事をご覧いただくことをお勧めします。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






