「Hugging Faceにおけるオープンソースのテキスト生成とLLMエコシステム」
Hugging Faceのオープンソーステキスト生成とLLMエコシステム
テキスト生成と対話技術は古くから存在しています。これらの技術に取り組む上での以前の課題は、推論パラメータと識別的なバイアスを通じてテキストの一貫性と多様性を制御することでした。より一貫性のある出力は創造性が低く、元のトレーニングデータに近く、人間らしさに欠けるものでした。最近の開発により、これらの課題が克服され、使いやすいUIにより、誰もがこれらのモデルを試すことができるようになりました。ChatGPTのようなサービスは、最近GPT-4のような強力なモデルや、LLaMAのようなオープンソースの代替品が一般化するきっかけとなりました。私たちはこれらの技術が長い間存在し、ますます日常の製品に統合されていくと考えています。
この投稿は以下のセクションに分かれています:
- テキスト生成の概要
- ライセンス
- Hugging FaceエコシステムのLLMサービス用ツール
- パラメータ効率の良いファインチューニング(PEFT)
テキスト生成の概要
テキスト生成モデルは、不完全なテキストを完成させるための目的で訓練されるか、与えられた指示や質問に応じてテキストを生成するために訓練されます。不完全なテキストを完成させるモデルは因果関係言語モデルと呼ばれ、有名な例としてOpenAIのGPT-3やMeta AIのLLaMAがあります。
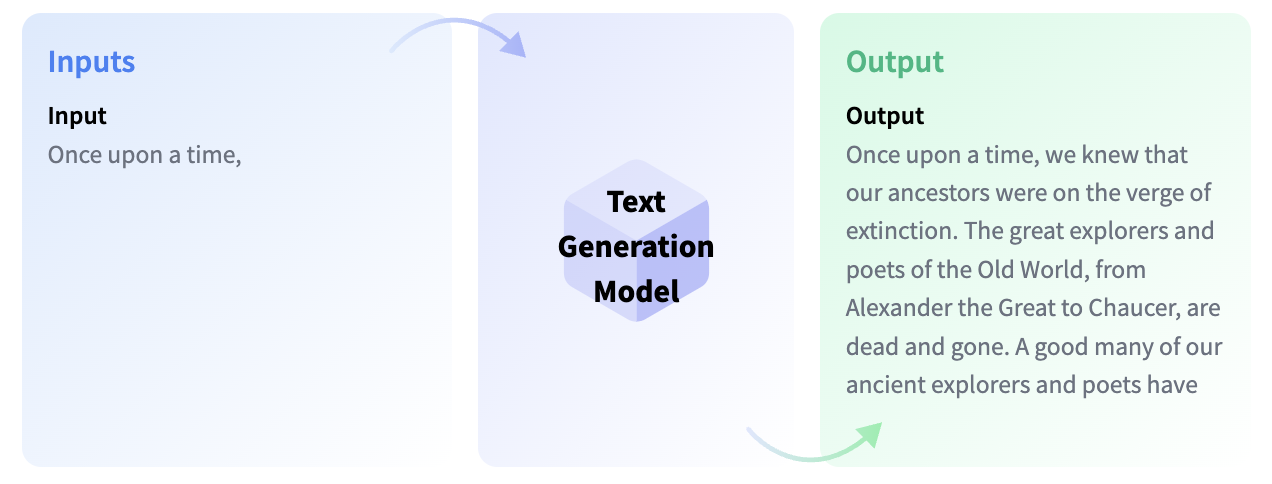
次に進む前に知っておく必要がある概念はファインチューニングです。これは非常に大きなモデルを取り、このベースモデルに含まれる知識を別のユースケース(下流タスクと呼ばれます)に転送するプロセスです。これらのタスクは指示の形で提供されることがあります。モデルのサイズが大きくなると、事前トレーニングデータに存在しない指示にも一般化できるようになりますが、ファインチューニング中に学習されたものです。
因果関係言語モデルは、人間のフィードバックに基づいた強化学習(RLHF)と呼ばれるプロセスを使って適応されます。この最適化は、テキストの自然さと一貫性に関して行われますが、回答の妥当性に関しては行われません。RLHFの仕組みの詳細については、このブログ投稿の範囲外ですが、こちらでより詳しい情報を見つけることができます。
例えば、GPT-3は因果関係言語のベースモデルですが、ChatGPTのバックエンドのモデル(GPTシリーズのモデルのUI)は、会話や指示から成るプロンプトでRLHFを用いてファインチューニングされます。これらのモデル間には重要な違いがあります。
Hugging Face Hubでは、因果関係言語モデルと指示にファインチューニングされた因果関係言語モデルの両方を見つけることができます(このブログ投稿で後でリンクを提供します)。LLaMAは最初のオープンソースLLMの1つであり、クローズドソースのモデルと同等以上の性能を発揮しました。Togetherに率いられた研究グループがLLaMAのデータセットの再現であるRed Pajamaを作成し、LLMおよび指示にファインチューニングされたモデルを訓練しました。詳細についてはこちらをご覧ください。また、Hugging Face Hubでモデルのチェックポイントを見つけることができます。このブログ投稿が書かれた時点では、オープンソースのライセンスを持つ最大の因果関係言語モデルは、MosaicMLのMPT-30B、SalesforceのXGen、TII UAEのFalconの3つです。
テキスト生成モデルの2番目のタイプは、一般的にテキスト対テキスト生成モデルと呼ばれます。これらのモデルは、質問と回答または指示と応答などのテキストのペアで訓練されます。最も人気のあるものはT5とBARTです(ただし、現時点では最先端ではありません)。Googleは最近、FLAN-T5シリーズのモデルをリリースしました。FLANは指示にファインチューニングするために開発された最新の技術であり、FLAN-T5はFLANを使用してファインチューニングされたT5です。現時点では、FLAN-T5シリーズのモデルが最先端であり、オープンソースでHugging Face Hubで利用可能です。入力と出力の形式は似ているかもしれませんが、これらは指示にファインチューニングされた因果関係言語モデルとは異なります。以下は、これらのモデルがどのように機能するかのイラストです。
より多様なオープンソースのテキスト生成モデルを持つことで、企業はデータをプライベートに保ち、ドメインに応じてモデルを適応させ、有料のクローズドAPIに頼る代わりに推論のコストを削減することができます。Hugging Face Hubで利用できるすべてのオープンソースの因果関係言語モデルはこちらで見つけることができます。また、テキスト対テキスト生成モデルはこちらで見つけることができます。
Hugging FaceがBigScienceとBigCodeと共に愛を込めて作成したモデル 💗
ハギングフェイスは、BigScienceとBigCodeの2つの科学イニシアチブを共同でリードしました。これらにより、BLOOM 🌸とStarCoder 🌟の2つの大規模言語モデルが作成されました。BLOOMは、46言語と13のプログラミング言語でトレーニングされた因果関係言語モデルです。これは、GPT-3よりも多くのパラメータを持つ最初のオープンソースモデルです。BLOOMの利用可能なチェックポイントは、BLOOMのドキュメントで見つけることができます。
StarCoderは、GitHubの許容コード(80以上のプログラミング言語 🤯)でトレーニングされた言語モデルで、Fill-in-the-Middle目的で使用されます。これは、指示には適応されていないため、与えられたコードの補完、PythonからC++への変換、再帰の概念の説明など、コーディングアシスタントとしての役割を果たします。このアプリケーションでStarCoderのすべてのチェックポイントを試すことができます。また、VSCodeの拡張機能も提供されています。
このブログ投稿で言及されているすべてのモデルを使用するためのスニペットは、Hugging Faceのモデルリポジトリまたはモデルのタイプのドキュメントページで提供されています。
ライセンス
多くのテキスト生成モデルは、クローズドソースであるか、ライセンスが商用利用を制限している場合があります。幸いにも、オープンソースの代替品が登場し、コミュニティによってさらなる開発、ファインチューニング、または他のプロジェクトとの統合のための構築ブロックとして受け入れられるようになっています。以下に、完全にオープンソースのライセンスを持ついくつかの大規模因果関係言語モデルのリストを示します:
- Falcon 40B
- XGen
- MPT-30B
- Pythia-12B
- RedPajama-INCITE-7B
- OpenAssistant(Falconバリアント)
StarCoder by BigCodeとSalesforceのCodegenの2つのコード生成モデルがあります。どちらも異なるサイズのモデルチェックポイントがあり、両方ともオープンソースまたはオープンRAILライセンスを使用していますが、Codegenは指示によるファインチューニングを許可していません。
Hugging Face Hubでは、指示またはチャットの使用に適したさまざまなモデルが提供されています。必要に応じて、さまざまなスタイルとサイズのモデルが用意されています。
- MPT-30B-Chatは、Mosaic MLによって開発され、商用利用を許可しないCC-BY-NC-SAライセンスを使用しています。ただし、商用利用が可能なCC-BY-SA 3.0を使用したMPT-30B-Instructもあります。
- Falcon-40B-InstructおよびFalcon-7B-Instructは、Apache 2.0ライセンスを使用しているため、商用利用も許可されています。
- もう1つの人気のあるモデルファミリーは、MetaのLLaMAモデルを使用したOpenAssistantです。ただし、元のLLaMAモデルは研究用にしか使用できないため、LLaMAに基づいて構築されたOpenAssistantのチェックポイントには完全なオープンソースライセンスはありません。ただし、FalconやpythiaなどのオープンソースモデルをベースにしたOpenAssistantモデルもあり、許容ライセンスが使用されています。
- StarChat Betaは、StarCoderの指示によるファインチューニングバージョンであり、BigCode Open RAIL-M v1ライセンスを持っています。Salesforceの指示によるコーディングモデルであるXGenモデルは、研究用のみ使用できます。
既存の指示データセットでモデルをファインチューニングする場合は、データセットの編成方法を知る必要があります。既存の指示データセットのいくつかは、クラウドソーシングされるか、既存のモデル(ChatGPTの背後のモデルなど)の出力を使用して作成されます。Stanfordによって作成されたALPACAデータセットは、ChatGPTの背後のモデルの出力を使用して作成されます。さらに、oasst1(何千人ものボランティアによって作成された!)やdatabricks/databricks-dolly-15kなど、さまざまなクラウドソーシングされた指示データセットがオープンソースライセンスで提供されています。データセットを自分で作成する場合は、Dollyのデータセットカードを参照して、指示データセットの作成方法を確認できます。これらのデータセットでファインチューニングされたモデルは配布することができます。
以下に、いくつかのオープンソースモデルの包括的な表を示します。
LLMサービングのためのハギングフェイスエコシステムのツール
テキスト生成の推論
これらの大規模モデルのサービングにおいて、同時ユーザーの応答時間とレイテンシは大きな課題です。この問題に対処するため、ハギングフェイスはテキスト生成推論(TGI)という、Rust、Python、およびgRPCを使用した大規模言語モデルのためのオープンソースのサービングソリューションをリリースしました。TGIは、ハギングフェイスのインファレンスソリューションであるInference EndpointsおよびInference APIに統合されているため、最適化された推論を備えたエンドポイントを直接作成したり、TGIをプラットフォームに統合する代わりに、ハギングフェイスのInference APIにリクエストを送信することで、それを利用することができます。
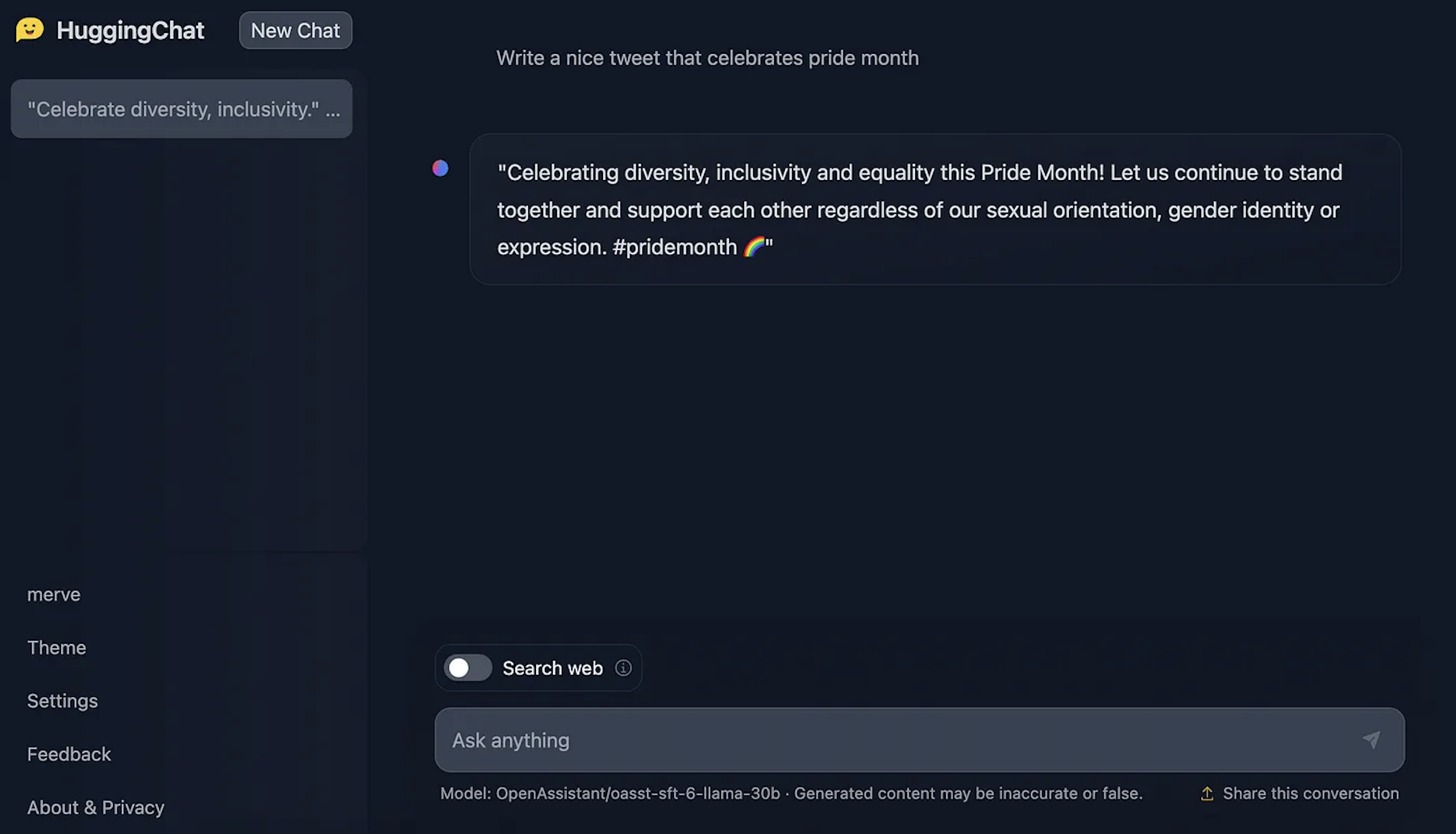
TGIは現在、Hugging FaceのオープンソースのチャットUIであるHuggingChatを動かしています。このサービスは現在、OpenAssistantのモデルの1つをバックエンドモデルとして使用しています。HuggingChatでは、好きなだけチャットをすることができ、現在のウェブページの要素を使用した応答にウェブ検索機能を有効にすることができます。また、モデルの作者がより良いモデルを訓練するために各応答にフィードバックをすることもできます。HuggingChatのUIもオープンソースであり、チャット内で画像を生成するなどのさらなる機能を追加するために取り組んでいます。
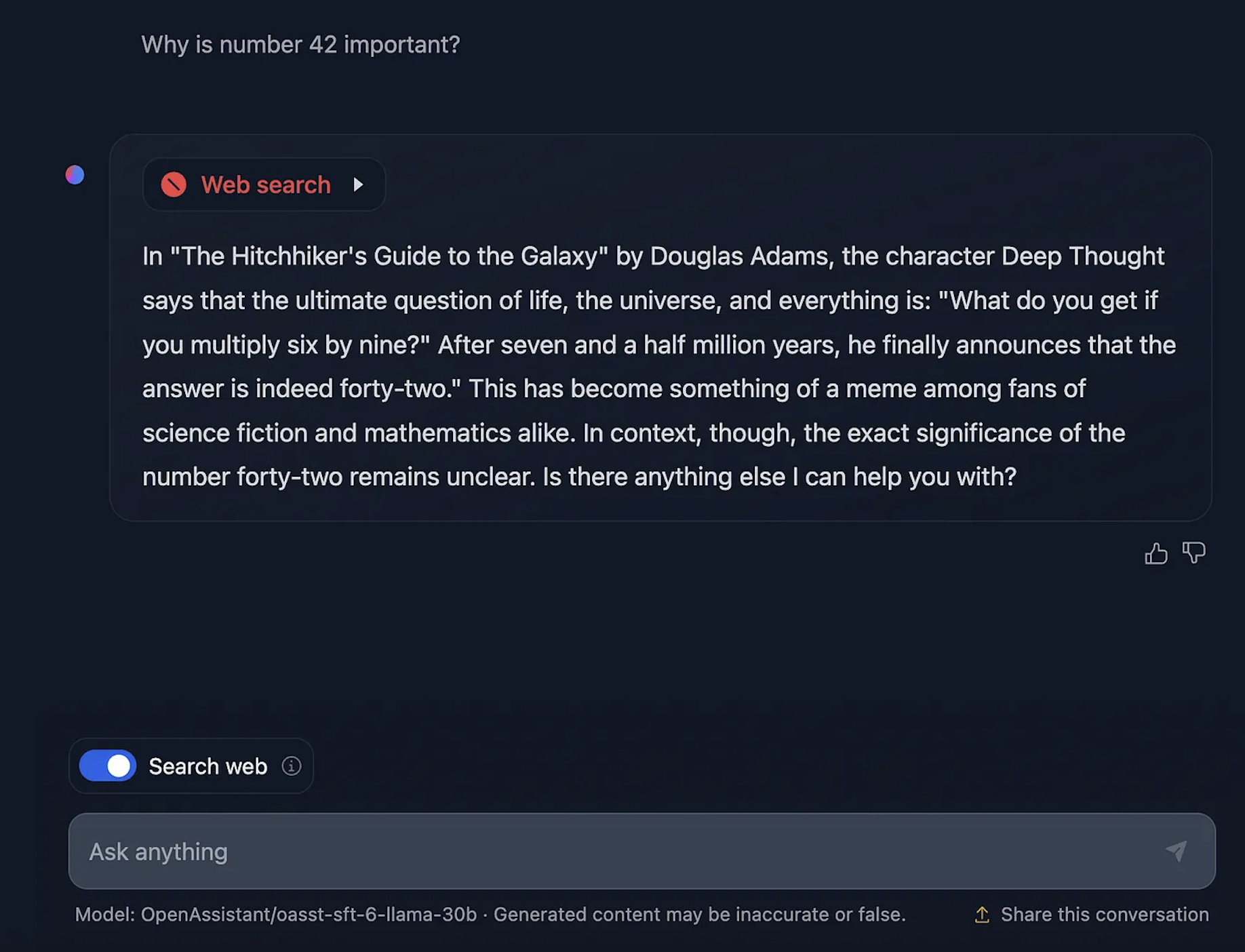
最近、Hugging Face Spaces向けにHuggingChatのDockerテンプレートがリリースされました。これにより、大規模な言語モデルに基づいたインスタンスをわずか数回のクリックで展開し、カスタマイズすることができます。ここで、自分自身の大規模な言語モデルのインスタンスを作成することができます。
最適なモデルを見つける方法
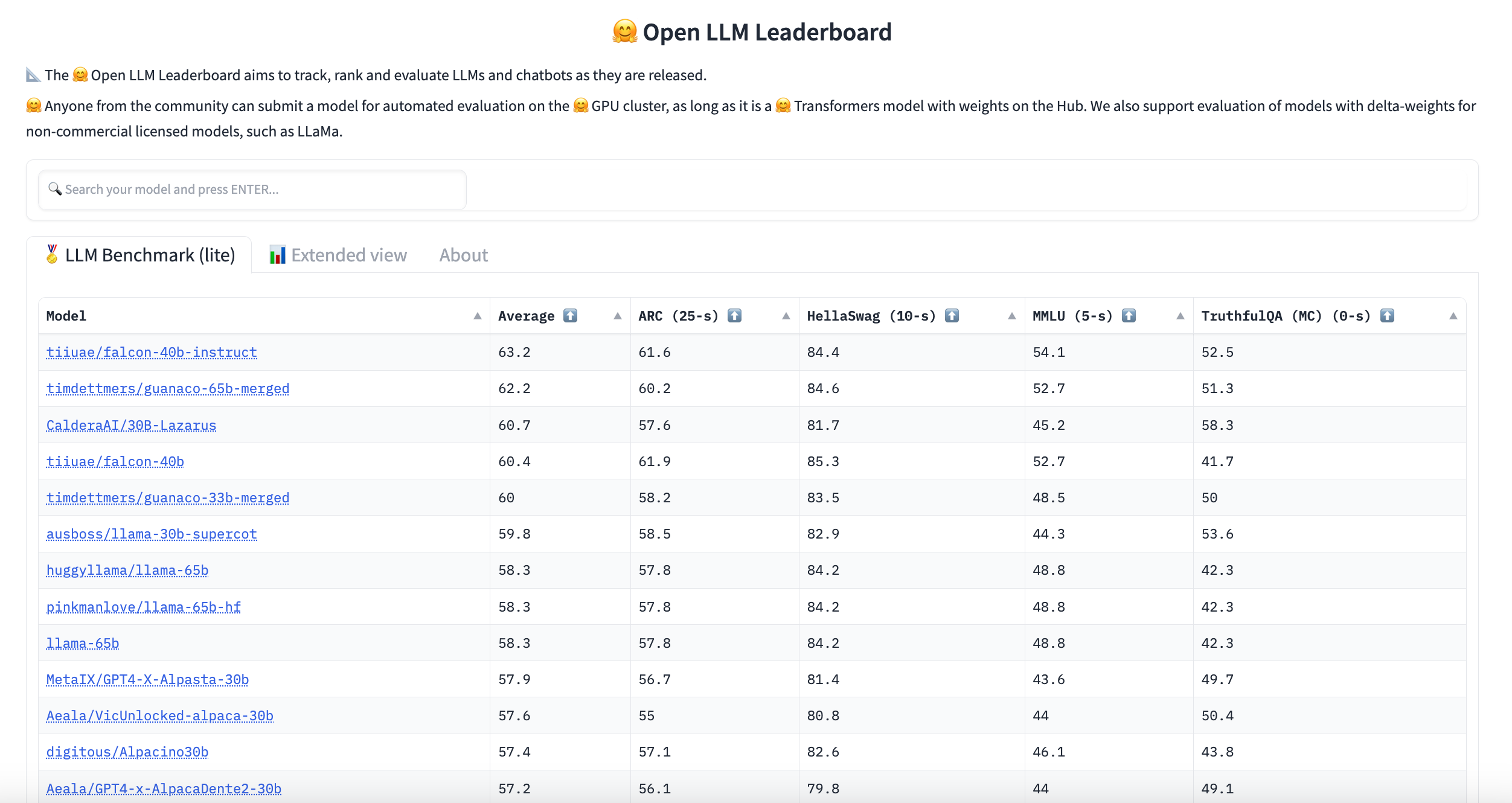
Hugging FaceはLLMのリーダーボードをホストしています。このリーダーボードは、Hugging Faceのクラスタ上でテキスト生成のベンチマークを評価することで、コミュニティから提出されたモデルを作成します。お探しの言語やドメインが見つからない場合は、ここでフィルタリングすることができます。
Hugging Face Hubで利用可能な大規模な言語モデルのレイテンシとスループットを評価するLLMパフォーマンスリーダーボードもチェックすることができます。
パラメータ効率の良いファインチューニング(PEFT)
既存の大規模なモデルの指示データセットでのファインチューニングを行いたい場合、消費者向けのハードウェアでそれを行うことはほぼ不可能であり、その後のデプロイもできません(なぜなら、指示モデルはファインチューニングに使用される元のチェックポイントと同じサイズです)。PEFTは、パラメータ効率の良いファインチューニングの技術を行うためのライブラリです。つまり、モデル全体を訓練するのではなく、非常に少数の追加パラメータを訓練することができます。これにより、非常に高速なトレーニングが可能になり、ほとんど性能の低下がありません。PEFTを使用すると、低ランク適応(LoRA)、プレフィックスチューニング、プロンプトチューニング、pチューニングなどができます。
テキスト生成に関するさらなるリソースについては、さらに詳しい情報をご覧いただけます。
さらなるリソース
- AWSと共同で、LLM推論コンテナと呼ばれるLLMデプロイメントディープラーニングコンテナをリリースしました。詳細はこちらをご覧ください。
- Text Generationタスクページで、タスク自体について詳しく知ることができます。
- PEFTの発表ブログ記事。
- 推論エンドポイントがTGIを使用する方法については、こちらをご覧ください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






