DataFrameを効率的に操作するためのloc Pandasメソッドの使い方
How to use the loc Pandas method efficiently to manipulate DataFrames.
PYTHON
Pandasを使用して新しいデータセットを探索・クリーニングするためのコード例と説明付きのヒント
新しいデータセットを扱う上で重要なのは、そのデータを理解することです。
データにどのような列があるか、生のデータ型は何か、データの記述統計など、基本的なことを理解することは、そのデータを適切に扱うために重要です。
初期段階のデータ探索にPandasにはすぐに使用できる組み込みメソッドがたくさんあります。データの初期探索を行いながら、データをさらに分析するために使用可能な形式にしたり、機械学習モデルのトレーニングに適した形式にしたりすることができます。
この記事では、以下の質問に答えるために、大学データセットを使用してデータを探索・クリーニングする方法を紹介します。
- どの大学が対面授業のみを提供しているか?
- 最も古く最も新しい創立大学の年間範囲は何ですか?
これらの質問に答えるために、locメソッドを他の組み込みPandasメソッドと組み合わせて使用することになります。最初に、locメソッドが何をするものか簡単に見てから、各例をステップバイステップで説明します。
ノートブックで一緒に進めても大丈夫です!データセットはKaggleからダウンロードでき、Open Data Commons Public Domain Dedication and License (PDDL) v1.0の下で自由に使用できます。次のコードをインポートして実行すれば、すぐに始めることができます!
import pandas as pddf_raw = pd.read_csv("Top-Largest-Universities.csv")locメソッドの簡単な紹介
基本的に、Pandasのlocメソッドは、与えられた条件に基づいて対象のDataFrameの部分的な行または列のサブセットを選択することができます。
locに渡すことができるいくつかの異なる入力があります。たとえば、DataFrameのインデックスに基づいてスライスを選択する場合は、Pythonのリストを操作するときと同じ構文を使用できます: [start:stop]。ただし、この記事では、主に条件文とlocを組み合わせて使用することに重点を置きます。SQLを使用したことがある場合、これはデータをフィルタリングするためのクエリのWHERE部分を書くのと似ています。
一般的に、このようにlocを使用すると次のようになります:
df.loc[df["column"] == "condition"]これにより、列が条件と等しいデータのサブセットが返されます。
次に、探索的データ分析中にlocメソッドを使用する実践的な例をいくつか紹介します。
Pandas locメソッドを使用して大学出席に関する質問に答える
どの大学が対面授業のみを提供しているか?
まず、locを使用して分析に使用するデータの一部を選択する方法を見てみましょう。
データがすでにクリーンであれば、対面授業のみを提供している機関の数を数えるために、列をグループ化するだけで済むと考えるかもしれません。Pandasでこれを行うと、次のようになります。
df.groupby("Distance / In-Person")["Institution"].count()
残念ながら、「Distance / In-Person」列の値はあまりクリーンではありません。空白に問題があったり、一部の機関が遠隔教育と対面授業の両方を提供していたりしますが、その記録方法は標準化されていません。
最初に、このカラムに空白や特殊文字がないようにカラム名を変更することができます。
df = df.rename(columns={"Distance / In-Person": "distance_or_in_person"})次に、DataFrame内のすべてのカラムを選択して変更が行われたかどうかを確認できます。
df.columns
今や、すべてのカラムには少なくとも空白や特殊文字がありません。もしその他のカラムも小文字に変更することで、さらに標準化することができますが、今回はスキップします。
前述のように、対象のカラムでグループ化して、各機関の値をカウントしました。同じ結果を得るためには、Pandasのvalue_countsメソッドを使用することもできます。これにより、呼び出された対象カラムのユニークな値のカウントを返すSeriesが返されます。
df["distance_or_in_person"].value_counts()
この場合、今回は「Institutions」カラムを呼び出す必要がなかったことに注意してください。これは、元のDataFrameにおいて、各行が1つの機関を表しているためです。
次に、遠隔と対面両方を提供する機関の値を1つの値にグループ化するために、locカラムを使用してDataFrameをフィルタリングし、distance_or_in_personカラムの値を新しい値「Both」に割り当てることができます。
df.loc[ ~df["distance_or_in_person"].isin(["In-Person", "Distance"]), "distance_or_in_person"] = "Both"ここでは、~演算子を使用して現在のdistance_or_in_personカラムをフィルタリングし、「In-Person」または「Distance」に等しくないものを選択し、distance_or_in_personカラムを選択しています。次に、「Both」に等しくなるように設定することにより、元のDataFrameが更新されます。変更を確認するために、再度DataFrameを確認できます。
df.head()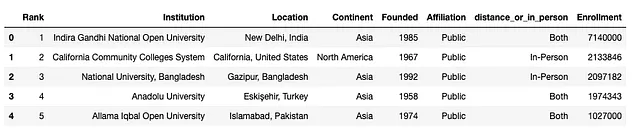
これで、更新されたカラムには3つの値しか含まれておらず、再度value_countsを呼び出すことで元の質問に回答できます。
df["distance_or_in_person"].value_counts()
これにより、クリーンアップされたデータに基づいて、59の大学が対面出席のみを提供していることがわかります。
この新しい条件に基づいて、特定の機関が対面出席を提供しているかどうかを知りたい場合、再度locメソッドを使用してDataFrameをフィルタリングし、tolistメソッドを使用してすべての値をPythonリストに取得できます。
df.loc[df["distance_or_in_person"] == "In-Person"]["Institution"].tolist()
リストは取得できましたが、いくつかの特殊文字を削除できます。「\xa0」はPythonでは改行を表します。これは、Pandasのstripメソッドを使用して取り除くことができます。このメソッドは、文字列値の両端の空白を取り除きます。
最終的な出力をクリーンアップするために、以下のように初期のtolistコードを編集できます。
df.loc[df["distance_or_in_person"] == "In-Person"]["Institution"].str.strip().tolist()
今、対面授業のみ提供している大学の最終リストがあります!
最も古い大学と最新の大学の設立年の範囲は何年ですか?
次に、locとその他のPandasのネイティブメソッドを使用して、特定のデータ分析の質問に答えるためにDataFrameをフィルタリングします。
最初に、Founded列を見て、何を扱っているかを確認できます:
df["Founded"]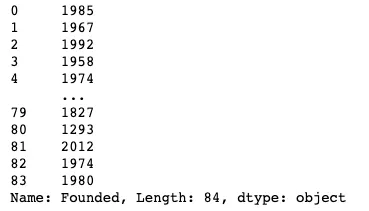
列には年の値が含まれているようです。日付を互いに比較する必要があるため、解析を容易にするために列をdatetimeタイプに変換できます。
pd.to_datetime(df["Founded"])
ただし、列にto_datetimeメソッドを使用すると、ParserErrorが返されます。
初期にFounded列で見たものに一致する値に特定の設立値がある場合、locメソッドを使用してDataFrameをフィルタリングして、行を確認できます:
df.loc[df["Founded"] == "1948 and 2014"]
異なる設立年を持つ大学が1つあるようです。また、行(9)のインデックスを知っているため、インデックス値を指定してDataFrameをフィルタリングするためにlocメソッドを使用する例もあります:
df.loc[9]
これはDataFrameの唯一の行であるようです。 “Founded”列の値に複数の年が含まれています。
データに対して何をするかによって、1年目の設立日を選択するか、この1つの機関に2つの行を作成して、両方の設立日を別々の行にするかもしれません。
この場合、このデータを使用して簡単な質問(データセット内の機関の設立日の範囲は何ですか)に答えるためだけにこのデータを使用するため、この1つの行を次のように削除できます:
df.drop(9).head(10) # 行を削除する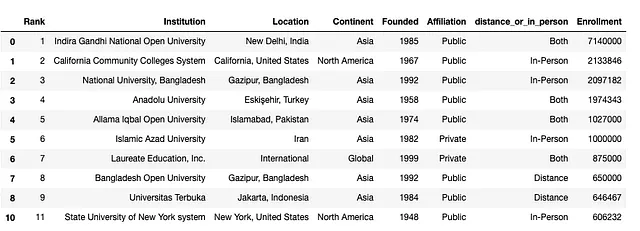
結果のDataFrameを確認すると、Founded列の複数の値を持つインデックス “9”の行がテーブルにないことがわかります。行を削除した後、DataFrameを再割り当てすることでドロップを固定できます:
df = df.drop(9)次に、Founded列に再度to_datetimeメソッドを適用し、何が起こるかを確認できます。
pd.to_datetime(df["Founded"], errors="coerce")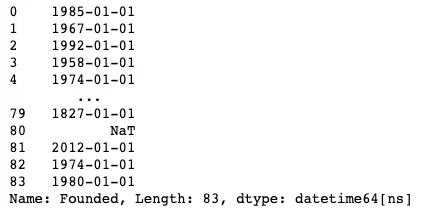
errors = "coerce"を含めることで、文字列をdatetimeタイプに変換する際に問題がある場合、値がnullになることを確認できます。
最後に、Founded列のdatetime型のバージョンを新しい列に割り当てることができます。そして、最も早く設立された機関の設立日を確認するために、Pythonのminメソッドを使用することができます:
df["founded_date"] = pd.to_datetime(df["Founded"], errors="coerce")min(df["founded_date"])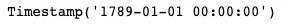
founded_date列の最も早いタイムスタンプと最新のタイムスタンプを取得するために、最小値と最大値を使用して最も古い大学と最新の大学の年の範囲を取得できます。
ここで、私は1つの簡単な質問に答える必要がある場合、これをすべてより早く行うことができることに気付きました。datetime型に変換する代わりに、列を整数型に変換し、最大値と最小値を引いて範囲を取得することができます。
df["Founded"] = df["Founded"].astype("int")max(df["Founded"]) - min(df["Founded"])これは719を出力します。
年の列を整数型に変換するだけで簡単に解決することができる場合でも、常に簡単な方法を取るべきではありません。より複雑な分析を行いたい場合や、時系列データを特に扱う場合は、データを適切にクリーンアップして、日付列をdatetime型にすると付加価値が高くなります。ただし、分析を迅速に行う必要がある場合は、問題を解決する最も迅速な方法を見つけるだけでなく、問題を解決するための「最良」の方法を探すために時間と頭痛を節約することができます。
Pandasの方法を組み合わせて、日付をクリーンアップして分析する方法はさまざまです。 locメソッドは汎用的で、DataFrameをフィルタリング、スライス、更新するために異なる方法を組み合わせて使用できるため、解決したい特定の問題や質問に合わせて機能します。
データのクリーンアップは、データの探索と手を取り合って反復的なプロセスです。 locを使用したこれらの例が、今後の自分自身の分析に役立つことを願っています。
私のコンテンツが気に入ったら、フォローして、以下の紹介リンクを使用してVoAGIメンバーに登録してください。月額$5で、VoAGIのすべてに無制限アクセスできます。私のリンクを使用して登録すると、少額の手数料を得ることができます。フォローしてくれた方には、ありがとうございます!
私の紹介リンクでVoAGIに参加 — バイロン・ドロン
VoAGIメンバーとして、あなたの会員費の一部があなたが読んだライターに支払われ、すべてのストーリーに完全アクセスできます…
byrondolon.medium.com
M ore by me: – 3 Efficient Ways to Filter a Pandas DataFrame Column by Substring – 5 Practical Tips for Aspiring Data Analysts – Improving Your Data Visualizations with Stacked Bar Charts in Python – C onditional Selection and Assignment With .loc in Pandas – 5 (and a half) Lines of Code for Understanding Your Data with Pandas
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
