Light & WonderがAWS上でゲーミングマシンの予測保守ソリューションを構築した方法
How Light & Wonder built a predictive maintenance solution for gaming machines on AWS.
この記事は、Light and Wonder (L&W) の Aruna Abeyakoon と Denisse Colin と共同執筆しました。
ラスベガスに本社を置く Light & Wonder は、ギャンブル製品とサービスを提供する世界的なクロスプラットフォームゲーム会社であり、AWS と協力して、業界初の安全なソリューションである Light & Wonder Connect (LnW Connect) を開発しました。LnW Connect は、LnW Connect が完全稼働すると、世界中のカジノ顧客に配布された約50万台のエレクトロニックゲームマシンからテレメトリおよびマシンヘルスデータをストリーミングすることができます。約500のマシンイベントがほぼリアルタイムで監視され、マシンの状態とその運用環境の全体像を提供します。LnW Connect を通じてストリーミングされたデータを利用して、L&W はエンドユーザーのゲーミング体験を向上させ、カジノ顧客により多くの価値をもたらすことを目指しています。
Light & Wonder は、Amazon ML Solutions Lab とチームを組んで、LnW Connect からストリーミングされたイベントデータを使用して、スロットマシンの機械学習 (ML) を活用した予測メンテナンスを可能にしました。予測メンテナンスは、物理的な設備または機械資産を持つビジネスにとって一般的な ML ユースケースです。予測メンテナンスにより、L&W はマシンの故障の事前警告を受け取り、サービスチームを事前に派遣して問題を検査できます。これにより、マシンのダウンタイムを減らし、カジノにおける重大な収益損失を回避できます。リモート診断システムがない場合、Light & Wonder のサービスチームによるカジノフロアでの問題解決はコストがかかり、効率が悪く、顧客のゲーミング体験が著しく低下します。
このプロジェクトの性質は、ゲーミング産業における予測メンテナンスの初めての試みであり、Amazon ML Solutions Lab と L&W チームは、ML 問題の定式化と評価メトリックの定義から高品質なソリューションの提供まで、エンドツーエンドの旅を開始しました。最終的な ML モデルは、CNN と Transformer を組み合わせたもので、シーケンシャルなマシンログデータのモデリングに対して最先端のニューラルネットワークアーキテクチャです。この記事では、この旅の詳細な説明を行います。お楽しみいただければ幸いです!
- 科学者たちは、AIと迅速な応答EEGを用いて、せん妄の検出を改善しました
- 医薬品探索の革新:機械学習モデルによる可能性のある老化防止化合物の特定と、将来の複雑な疾患治療のための道筋を開拓する
- 音から視覚へ:音声から画像を合成するAudioTokenについて
この記事では、以下について説明します。
- 適切な評価メトリックのセットで、ML 問題として予測メンテナンス問題を定式化する方法
- トレーニングとテストのためのデータの準備方法
- パフォーマンスモデルを取得するために使用したデータ前処理とフィーチャーエンジニアリングの技術
- Amazon SageMaker Automatic Model Tuning を使用したハイパーパラメータ調整ステップの実行
- ベースラインモデルと最終的な CNN+Transformer モデルの比較
- アンサンブリングなど、モデルパフォーマンスを向上させるために使用した追加の技術
背景
このセクションでは、このソリューションが必要とされた問題について説明します。
データセット
スロットマシン環境は高度に規制されており、エアギャップ環境に展開されています。LnW Connect では、データを AWS データレイクに取り込むための安全で信頼性の高い暗号化プロセスが設計されています。集約ファイルは暗号化され、復号キーは AWS Key Management Service (AWS KMS) でのみ利用可能です。セルラーベースのプライベートネットワークを介して、ファイルは Amazon Simple Storage Service (Amazon S3) にアップロードされます。
LnW Connect は、ゲームの開始、終了など、さまざまなマシンイベントをストリーミングします。システムは約500種類のイベントを収集します。以下に示すように、各イベントは、それが発生したタイムスタンプとイベントを記録しているマシンの ID とともに記録されます。LnW Connect はまた、マシンがプレイできない状態に入ったときに記録し、十分に短い時間内にプレイ可能な状態に回復しない場合はマシンの故障または故障としてマークされます。
| マシン ID | イベントタイプ ID | タイムスタンプ |
| 0 | E1 | 2022-01-01 00:17:24 |
| 0 | E3 | 2022-01-01 00:17:29 |
| 1000 | E4 | 2022-01-01 00:17:33 |
| 114 | E234 | 2022-01-01 00:17:34 |
| 222 | E100 | 2022-01-01 00:17:37 |
動的なマシンイベントに加え、各マシンの静的なメタデータも利用可能です。これには、マシンの固有識別子、キャビネットタイプ、場所、オペレーティングシステム、ソフトウェアバージョン、ゲームテーマなどが含まれます。以下の表に示すように、テーブル内のすべての名前は、お客様情報を保護するために匿名化されています。
| マシンID | キャビネットタイプ | OS | 場所 | ゲームテーマ |
| 276 | A | OS_Ver0 | AAリゾート&カジノ | StormMaiden |
| 167 | B | OS_Ver1 | BBカジノ、リゾート&スパ | UHMLIndia |
| 13 | C | OS_Ver0 | CCカジノ&ホテル | TerrificTiger |
| 307 | D | OS_Ver0 | DDカジノリゾート | NeptunesRealm |
| 70 | E | OS_Ver0 | EEリゾート&カジノ | RLPMealTicket |
問題定義
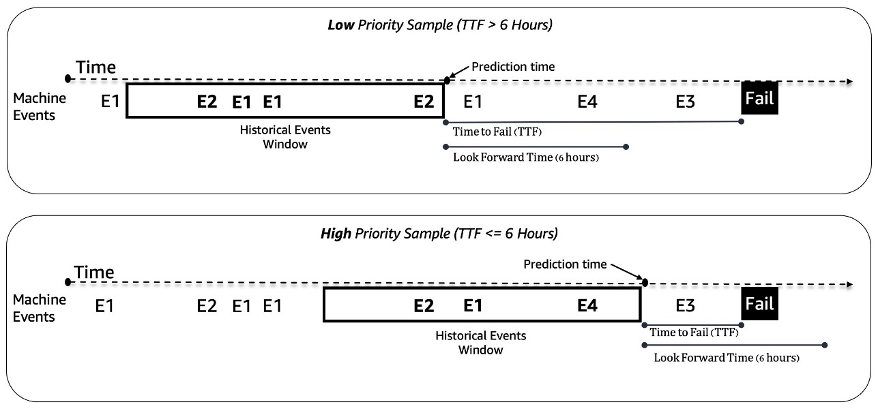
スロットマシンの予防保全問題を二値分類問題として扱います。MLモデルは、機械の過去のイベントシーケンスとその他のメタデータを受け取り、6時間以内に故障するかどうかを予測します。6時間以内にマシンが故障する場合は、メンテナンスの優先度が高いと見なされます。それ以外の場合は優先度が低いです。以下の図は、優先度が低い(上)と優先度が高い(下)のサンプルの例を示しています。予測には、固定長の過去のマシンイベントデータを収集するための時間窓を使用します。実験では、より長い時間窓を使用すると、モデルの性能が著しく向上することがわかっています(後でこの投稿で詳細に説明します)。
モデリングの課題
この問題に取り組むにあたり、次のような課題に直面しました:
- 約1,000のゲームサンプルから約5000万のイベントログがあります。データの抽出と前処理段階で慎重な最適化が必要です。
- 非常に不均一なイベント分布のため、イベントシーケンスモデリングは課題でした。3時間のウィンドウには、10個から数千個のイベントが含まれることがあります。
- マシンはほとんどの場合良好な状態にあり、高優先度のメンテナンスは稀なクラスであり、クラスの不均衡問題が発生しました。
- 新しいマシンがシステムに継続的に追加されるため、トレーニングで見たことのない新しいマシンに対して予測を行うことができるようにする必要がありました。
データの前処理と特徴量エンジニアリング
このセクションでは、データの準備と特徴量エンジニアリングの方法について説明します。
特徴量エンジニアリング
スロットマシンのフィードは、等間隔でないタイムシリーズイベントのストリームであり、たとえば、3時間のウィンドウ内のイベント数は10個から数千個に及ぶことがあります。この不均衡を扱うために、生のシーケンスデータの代わりにイベント頻度を使用しました。直感的なアプローチは、過去のすべてのイベントの頻度を集計し、モデルにフィードすることです。しかし、この表現を使用する場合、時間情報が失われ、イベントの順序が維持されません。代わりに、時間ウィンドウをN個の等しいサブウィンドウに分割し、各サブウィンドウのイベント頻度を計算することによる時間的なビン分割を使用しました。時間ウィンドウの最終的な特徴は、すべてのサブウィンドウの特徴の連結です。ビン数を増やすことで、より多くの時間情報が保存されます。以下の図は、サンプルウィンドウでの時間的なビン分割を示しています。

まず、サンプル時間ウィンドウを2つの等しいサブウィンドウ(ビン)に分割します。ここでは、説明のためにシンプルに2つのビンを使用しました。次に、各ビンでイベントE1、E2、E3、およびE4のカウントを計算します。最後に、それらを連結して特徴量として使用します。
イベント周波数ベースの特徴量に加えて、ソフトウェアバージョン、キャビネットタイプ、ゲームテーマ、ゲームバージョンなどの機械固有の特徴量を使用しました。加えて、曜日の時間帯や曜日など、タイムスタンプに関連する特徴量も追加し、季節性を捕捉しました。
データの準備
トレーニングとテストのためにデータを効率的に抽出するために、Amazon AthenaとAWS Glue Data Catalogを利用しています。イベントデータは、Parquet形式でAmazon S3に格納され、日/月/時に従ってパーティション分割されます。これにより、指定された時間ウィンドウ内のデータサンプルを効率的に抽出できます。テストには最新の月のすべての機械からデータを使用し、残りのデータはトレーニングに使用して、潜在的なデータ漏えいを回避するのに役立ちます。
ML方法論とモデルトレーニング
このセクションでは、AutoGluonを使用したベースラインモデルと、SageMaker自動モデルチューニングを使用してカスタマイズされたニューラルネットワークモデルを構築した方法について説明します。
AutoGluonを使用したベースラインモデルの構築
どのようなMLユースケースでも、比較と反復に使用するベースラインモデルを確立することが重要です。AutoGluonを使用して、いくつかのクラシックなMLアルゴリズムを探索しました。AutoGluonは、自動データ処理、ハイパーパラメータ調整、およびモデルアンサンブルを使用する使いやすいAutoMLツールです。最高のベースラインは、勾配ブースティング決定木モデルの重み付きアンサンブルで達成されました。AutoGluonの使いやすさは、多数のデータとMLモデリングの方向性を迅速かつ効率的にナビゲートするのに役立ちました。
SageMaker自動モデルチューニングを使用したカスタマイズされたニューラルネットワークモデルの構築とチューニング
異なるニューラルネットワークアーキテクチャを試した後、予測メンテナンスのためのカスタマイズされたディープラーニングモデルを構築しました。当社のモデルは、80%の精度でのリコールで、AutoGluonベースラインモデルを121%上回りました。最終モデルは、過去の機械イベントシーケンスデータ、時間特徴(曜日、時間帯)、および静的機械メタデータを取り込みます。SageMaker自動モデルチューニングジョブを使用して、最適なハイパーパラメータとモデルアーキテクチャを検索します。
以下の図は、モデルアーキテクチャを示しています。まず、トレーニングセットの各イベントの平均周波数でバイナリ化されたイベントシーケンスデータを正規化して、高周波数イベント(ゲームの開始、ゲームの終了など)の圧倒的な影響を除去します。個々のイベントの埋め込みは学習可能であり、時系列特徴の埋め込み(曜日、時間帯)は、パッケージGluonTSを使用して抽出されます。次に、イベントシーケンスデータを時系列特徴の埋め込みと結合して、モデルの入力として使用します。モデルには以下のレイヤーがあります。
- 畳み込み層(CNN)–各CNN層は、2つの1次元畳み込み操作と残差接続から構成されています。各CNN層の出力は、他のモジュールとの簡単なスタッキングを可能にするため、入力と同じシーケンスの長さを持ちます。CNN層の総数は調整可能なハイパーパラメータです。
- トランスフォーマーエンコーダーレイヤー(TRANS)– CNN層の出力は、位置エンコーディングと一緒にマルチヘッドセルフアテンション構造に送られます。TRANSを使用して、リカレントニューラルネットワークを使用する代わりに、直接的に時間依存性を捕捉します。ここで、生のシーケンスデータをビニングすることで(長さを数千から数百に減らすことで)、GPUメモリのボトルネックを緩和することができますが、チューナブルな範囲で時系列情報を保持します(ビンの数は調整可能なハイパーパラメータです)。
- 集約層(AGG)–最終層は、優先度レベルの確率予測を生成するためにメタデータ情報(ゲームテーマタイプ、キャビネットタイプ、場所)を組み合わせます。インクリメンタルな次元削減のための複数のプーリング層と完全に接続された層が含まれます。メタデータのマルチホット埋め込みは学習可能であり、シーケンシャル情報を含まないため、CNNおよびTRANSレイヤーを通過しません。

クラス不均衡問題に対応するために、クラスウェイトを調整可能なハイパーパラメータとしてクロスエントロピー損失を使用しています。さらに、CNN層とTRANS層の数は、モデルアーキテクチャに特定の層が常に存在しないことを示す0という可能な値である重要なハイパーパラメータです。これにより、モデルアーキテクチャが通常のハイパーパラメータとともに検索される統一フレームワークが得られます。
私たちは、SageMaker自動モデルチューニング(ハイパーパラメータ最適化とも呼ばれる)を利用して、さまざまなハイパーパラメータのバリエーションと大規模な探索空間を効率的に探索します。自動モデルチューニングは、カスタマイズされたアルゴリズム、トレーニングデータ、およびハイパーパラメータ検索空間の構成を受け取り、ベイジアン、ハイパーバンドなどの異なる戦略を使用して最適なハイパーパラメータを複数のGPUインスタンスで並列に検索します。ホールドアウト検証セットで評価した後、2つのCNN層、4つのヘッドを持つ1つのTRANS層、およびAGG層を持つ最良のモデルアーキテクチャを得ました。
最適なモデルアーキテクチャを検索するために、以下のハイパーパラメータ範囲を使用しました:
hyperparameter_ranges = {
# 学習率
"learning_rate": ContinuousParameter(5e-4, 1e-3, scaling_type="Logarithmic"),
# クラスウェイト
"loss_weight": ContinuousParameter(0.1, 0.9),
# 入力ビンの数
"num_bins": CategoricalParameter([10, 40, 60, 120, 240]),
# ドロップアウト率
"dropout_rate": CategoricalParameter([0.1, 0.2, 0.3, 0.4, 0.5]),
# モデル埋め込み次元
"dim_model": CategoricalParameter([160,320,480,640]),
# CNN層の数
"num_cnn_layers": IntegerParameter(0,10),
# CNNカーネルサイズ
"cnn_kernel": CategoricalParameter([3,5,7,9]),
# Transformer層の数
"num_transformer_layers": IntegerParameter(0,4),
# Transformerアテンションヘッドの数
"num_heads": CategoricalParameter([4,8]),
# RNN層の数
"num_rnn_layers": IntegerParameter(0,10),# 任意の値
# RNN入力次元サイズ
"dim_rnn":CategoricalParameter([128,256])
}モデルの精度をさらに向上させ、モデルの分散を減らすために、複数の独立したランダムな重み初期化でモデルをトレーニングし、平均値を確率予測の最終値として集約しました。より多くのコンピューティングリソースとモデルパフォーマンスとの間にはトレードオフがあり、現在のユースケースでは5-10が適切な数であることが観察されました(後ほどこの投稿で示します)。
モデルのパフォーマンス結果
このセクションでは、モデルのパフォーマンス評価指標と結果を紹介します。
評価指標
この予測メンテナンスユースケースでは、精度が非常に重要です。低い精度は、必要のないメンテナンスによりコストが上昇することを意味します。平均精度(AP)は高精度の目的と完全に一致しないため、高精度での平均リコール(ARHP)という新しいメトリックを導入しました。ARHPは、60%、70%、および80%の精度ポイントでのリコールの平均値と等しいです。また、追加のメトリックとして、K%トップの精度(K=1、10)、AUPR、およびAUROCを使用しました。
結果
以下の表は、ベースラインとカスタマイズされたニューラルネットワークモデルを使用した結果を、2022年7月1日をトレイン/テストの分割点としてまとめたものです。実験では、ウィンドウ長とサンプルデータサイズを増やすことで、モデルのパフォーマンスが向上することが示されました。データの設定に関係なく、ニューラルネットワークモデルはすべてのメトリックでAutoGluonを上回ります。たとえば、固定された80%の精度でのリコールは121%増加し、ニューラルネットワークモデルを使用するとより多くの故障したマシンを素早く特定できます。
| モデル | ウィンドウ長/データサイズ | AUROC | AUPR | ARHP | [email protected] | [email protected] | [email protected] | Prec@top1% | Prec@top10% |
| AutoGluonベースライン | 12時間/500k | 66.5 | 36.1 | 9.5 | 12.7 | 9.3 | 6.5 | 85 | 42 |
| ニューラルネットワーク | 12時間/500k | 74.7 | 46.5 | 18.5 | 25 | 18.1 | 12.3 | 89 | 55 |
| AutoGluonベースライン | 48時間/1mm | 70.2 | 44.9 | 18.8 | 26.5 | 18.4 | 11.5 | 92 | 55 |
| ニューラルネットワーク | 48時間/1mm | 75.2 | 53.1 | 32.4 | 39.3 | 32.6 | 25.4 | 94 | 65 |
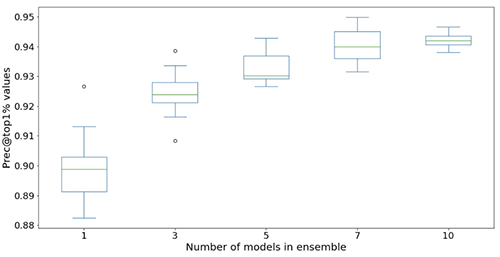
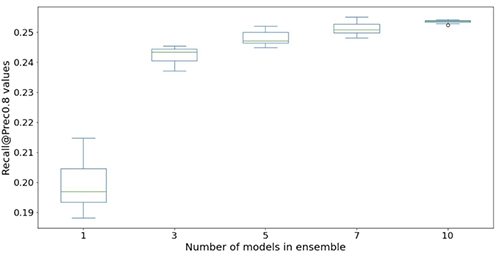
以下の図は、アンサンブルを使用してニューラルネットワークモデルのパフォーマンスを向上させる効果を示しています。x軸に表示されるすべての評価メトリックが改善され、平均値が高く(より正確)、分散が低く(より安定)、12回の繰り返し実験から得られた各ボックスプロットが、アンサンブルのなしから10モデルのアンサンブルまで(x軸)を示しています。 Prec@top1%とRecall@Prec80%を除くすべてのメトリックで同様の傾向が続いています。
計算コストを考慮すると、アンサンブルで5〜10モデルを使用することが、Light & Wonderデータセットに適していることがわかります。
結論
当社の協力により、ゲーミング業界に画期的な予測メンテナンスソリューションが作成され、様々な予測メンテナンスシナリオで利用可能な再利用可能なフレームワークが作成されました。 SageMaker自動モデルチューニングなどのAWSテクノロジーの採用により、Light & Wonderは、リアルタイムデータストリームを使用して新しい機会に対処することができます。 Light & WonderはAWSでの展開を開始しています。
製品やサービスでMLの利用を加速するための支援が必要な場合は、Amazon ML Solutions Labプログラムにお問い合わせください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- AWSにおけるマルチモデルエンドポイントのためのCI/CD
- 2023年5月のVoAGIトップ記事:Mojo Lang:新しいプログラミング言語
- 新たな能力が明らかに:GPT-4のような成熟したAIのみが自己改善できるのか?言語モデルの自律的成長の影響を探る
- 赤い猫&アテナAIは夜間視認能力を備えた知能化軍用ドローンを製造する
- CapPaに会ってください:DeepMindの画像キャプション戦略は、ビジョンプレトレーニングを革新し、スケーラビリティと学習性能でCLIPに匹敵しています
- 最初のLLMアプリを構築するために知っておく必要があるすべて
- 再帰型ニューラルネットワークの基礎からの説明と視覚化






