Amazon SageMakerでTritonを使用してMLモデルをホストする:ONNXモデル
Host ML models using Triton on Amazon SageMaker ONNX models.
ONNX(Open Neural Network Exchange)は、多くのプロバイダーによって広くサポートされているディープラーニングモデルを表現するためのオープンソースの標準です。ONNXは、機械学習(ML)モデルを実行するために必要なメモリと計算を削減するための最適化と量子化モデルのツールを提供します。ONNXの最大の利点の1つは、異なるフレームワークとツール間でMLモデルを表現および交換するための標準化された形式を提供することです。これにより、開発者は1つのフレームワークでモデルをトレーニングし、他のフレームワークに展開するための広範なモデル変換や再トレーニングの必要がなくなります。これらの理由から、ONNXはMLコミュニティで重要な役割を果たしています。
このポストでは、GPUを使用するマルチモデルエンドポイント(MME)に基づくONNXベースのモデルの展開方法を紹介します。これは、PyTorchとTensorRTバージョンのResNet50モデルをNvidiaのTriton Inferenceサーバーに展開する方法を示した記事Run multiple deep learning models on GPU with Amazon SageMaker multi-model endpointsの続きです。このポストでは、ONNX形式の同じResNet50モデルと追加の自然言語処理(NLP)例のモデルを使用して、Tritonでどのように展開できるかを示します。さらに、同じ入力を使用して、ResNet50モデルのベンチマークを行い、ONNXが提供するパフォーマンスの利点をPyTorchおよびTensorRTバージョンの同じモデルと比較します。

ONNXランタイム
ONNX Runtimeは、CPUおよびGPUを含む複数のハードウェアプラットフォーム上でモデルのパフォーマンスを最適化するために設計されたML推論のランタイムエンジンです。PyTorchやTensorFlowなどのMLフレームワークの使用を可能にします。ターゲットハードウェアでモデルをコスト効率よく実行するためのパフォーマンスチューニングを容易にし、量子化やハードウェアアクセラレーションなどの機能に対応しているため、効率的で高性能なMLアプリケーションを展開するための理想的な選択肢の1つです。ONNXモデルをTensorRTを使用してNvidia GPUに最適化する例については、「TensorRT Optimization (ORT-TRT) and ONNX Runtime with TensorRT optimization」を参照してください。
- Amazon SageMakerのHugging Face推定器とモデルパラレルライブラリを使用してGPT-Jを微調整する
- Amazon SageMakerを使用してOpenChatkitモデルを利用したカスタムチャットボットアプリケーションを構築する
- Amazon SageMaker で大規模なモデル推論 DLC を使用して Falcon-40B をデプロイする
Amazon SageMaker Tritonコンテナのフローは、次の図に示されています。
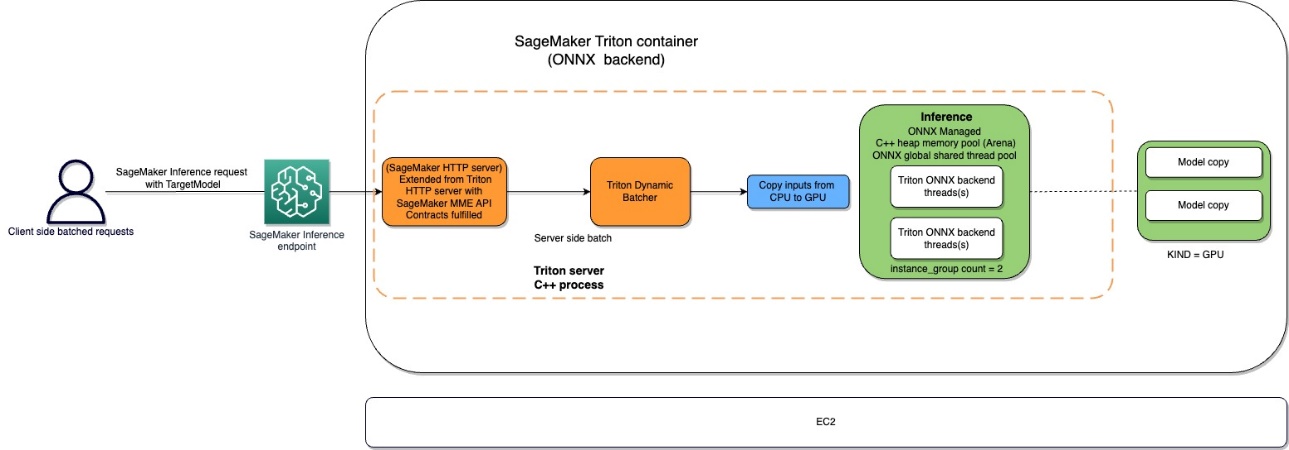
ユーザーは、SageMakerエンドポイントの背後でリアルタイム推論の入力ペイロードをHTTPSリクエストで送信できます。ユーザーは、要求が呼び出される予定のモデルの名前を含むTargetModelヘッダーを指定できます。内部的に、SageMaker Tritonコンテナは、How Containers Serve Requestsで説明されているとおりの契約を持つHTTPサーバーを実装しています。動的バッチ処理をサポートし、Tritonが提供するすべてのバックエンドをサポートしています。構成に基づいて、ONNXランタイムが呼び出され、ユーザーによって提供されるモデル構成でCPUまたはGPUでリクエストが処理されます。
ソリューションの概要
ONNXバックエンドを使用するには、次の手順を完了します:
- モデルをONNX形式にコンパイルします。
- モデルを構成します。
- SageMakerエンドポイントを作成します。
前提条件
ノートブックを作成し、Amazon Simple Storage Service(Amazon S3)バケットにアクセスし、SageMakerエンドポイントにモデルを展開するために十分なAWS Identity and Access Management IAM権限を持つAWSアカウントにアクセスできることを確認してください。詳細については、「Create execution role」を参照してください。
モデルをONNX形式にコンパイルする
transformersライブラリは、PyTorchモデルを簡単にONNX形式にコンパイルするための便利な方法を提供します。次のコードは、NLPモデルの変換を実現します:
onnx_inputs, onnx_outputs = transformers.onnx.export(
preprocessor=tokenizer,
model=model,
config=onnx_config,
opset=12,
output=save_path
)モデル(PyTorchまたはTensorFlow)のエクスポートは、Hugging Face transformersリポジトリの一部として提供される変換ツールを介して簡単に実現できます。
以下は、裏側で何が起こっているかです:
- transformers(PyTorchまたはTensorFlow)からモデルを割り当てます。
- ダミー入力をモデルに転送します。これにより、ONNXが実行された操作のセットを記録できます。
- transformersは、モデルをエクスポートするときに動的軸を自動的に処理します。
- ネットワークパラメータと一緒にグラフを保存します。
torchvisionモデルゾーからのコンピュータビジョンユースケースには、同様のメカニズムが従われます:
torch.onnx.export(
resnet50,
dummy_input,
args.save,
export_params=True,
opset_version=11,
do_constant_folding=True,
input_names=["input"],
output_names=["output"],
dynamic_axes={"input": {0: "batch_size"}, "output": {0: "batch_size"}},
)モデルの設定
このセクションでは、コンピュータビジョンモデルとNLPモデルを設定します。Triton Inference Serverモデル設定を利用して、SageMaker MMEに展開するために事前学習されたResNet50およびRoBERTA Largeモデルを作成する方法を示します。ResNet50のノートブックはGitHubで利用できます。RoBERTAのノートブックもGitHubで利用できます。ResNet50では、ONNXモデルをビルドし、この演習に必要なモデルアーティファクトを生成するために必要なすべての依存関係をすでに持っている環境を作成するために、Dockerアプローチを使用します。このアプローチを使用すると、依存関係を共有し、このタスクを実行するために必要な正確な環境を作成することがはるかに簡単になります。
最初のステップは、ONNXモデルパッケージを作成することで、ONNXモデルで指定されたディレクトリ構造に従います。目的は、単一のファイルに含まれるONNXモデルの最小モデルリポジトリを使用することです。以下のようになります:
<model-repository-path> /
Model_name
├── 1
│ └── model.onnx
└── config.pbtxt次に、Triton Serverが適切なカーネルを呼び出すための入力、出力、およびバックエンド構成を記述するモデル構成ファイルを作成します。このファイルはconfig.pbtxtとして知られており、以下のRoBERTAユースケースのコードに示されています。 BATCH次元はconfig.pbtxtから省略されます。ただし、データをモデルに送信するときには、バッチ次元を含めます。次のコードは、モデル構成ファイルで動的バッチングを設定して、実際の推論に対して5の優先バッチサイズで動的バッチャーに最初のリクエストが到達してから100マイクロ秒の遅延時間が経過した場合に、モデルインスタンスがすぐに呼び出されるようにする方法も示しています。
name: "nlp-onnx"
platform: "onnxruntime_onnx"
backend: "onnxruntime"
max_batch_size: 32
input {
name: "input_ids"
data_type: TYPE_INT64
dims: [512]
}
input {
name: "attention_mask"
data_type: TYPE_INT64
dims: [512]
}
output {
name: "last_hidden_state"
data_type: TYPE_FP32
dims: [-1, 768]
}
output {
name: "1550"
data_type: TYPE_FP32
dims: [768]
}
instance_group {
count: 1
kind: KIND_GPU
}
dynamic_batching {
max_queue_delay_microseconds: 100
preferred_batch_size:5
}コンピュータビジョンユースケースの同様の構成ファイルは以下のとおりです:
name: "resenet_onnx"
platform: "onnxruntime_onnx"
max_batch_size : 128
input [
{
name: "input"
data_type: TYPE_FP32
format: FORMAT_NCHW
dims: [ 3, 224, 224 ]
}
]
output [
{
name: "output"
data_type: TYPE_FP32
dims: [ 1000 ]
}
]SageMakerエンドポイントの作成
Boto3 APIを使用してSageMakerエンドポイントを作成します。この記事では、RoBERTAノートブックの手順を示しますが、これらは一般的な手順であり、ResNet50モデルでも同じです。
SageMakerモデルの作成
次に、SageMakerモデルを作成します。前のステップからAmazon Elastic Container Registry(Amazon ECR)イメージとモデルアーティファクトを使用してSageMakerモデルを作成します。
コンテナの作成
コンテナを作成するには、Triton Server用の適切なイメージをAmazon ECRからプルします。SageMakerでは、さまざまな環境変数をカスタマイズして注入することができます。主要な機能のいくつかは、BATCH_SIZEを設定できることです。モデルごとにconfig.pbtxtファイルでこれを設定するか、ここでデフォルト値を定義することができます。より大きな共有メモリサイズが有益なモデルには、SHM変数の下にそれらの値を設定できます。ログを有効にするには、ログverboseレベルをtrueに設定します。以下のコードを使用して、エンドポイントで使用するモデルを作成します:
mme_triton_image_uri = (
f"{account_id_map[region]}.dkr.ecr.{region}.{base}" + "/sagemaker-tritonserver:22.12-py3"
)
container = {
"Image": mme_triton_image_uri,
"ModelDataUrl": mme_path,
"Mode": "MultiModel",
"Environment": {
"SAGEMAKER_TRITON_SHM_DEFAULT_BYTE_SIZE": "16777216000", # "16777216", #"16777216000",
"SAGEMAKER_TRITON_SHM_GROWTH_BYTE_SIZE": "10485760",
},
}
from sagemaker.utils import name_from_base
model_name = name_from_base(f"flan-xxl-fastertransformer")
print(model_name)
create_model_response = sm_client.create_model(
ModelName=model_name,
ExecutionRoleArn=role,
PrimaryContainer={
"Image": inference_image_uri,
"ModelDataUrl": s3_code_artifact
},
)
model_arn = create_model_response["ModelArn"]
print(f"Created Model: {model_arn}")SageMakerエンドポイントの作成
テストには複数のGPUを搭載したインスタンスを使用できます。この記事では、g4dn.4xlargeインスタンスを使用します。このインスタンスにはローカルインスタンスストレージが付属しているため、VolumeSizeInGBパラメータを設定する必要はありません。 VolumeSizeInGBパラメータは、Amazon Elastic Block Store(Amazon EBS)ボリュームのアタッチをサポートするGPUインスタンスに適用されます。モデルのダウンロードタイムアウトとコンテナの起動時のヘルスチェックについての詳細は、CreateEndpointConfigを参照してください。
endpoint_config_response = sm_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[{
"VariantName": "AllTraffic",
"ModelName": model_name,
"InstanceType": "ml.g4dn.4xlarge",
"InitialInstanceCount": 1,
#"VolumeSizeInGB" : 200,
#"ModelDataDownloadTimeoutInSeconds": 600,
#"ContainerStartupHealthCheckTimeoutInSeconds": 600,
},
],)'最後に、SageMakerエンドポイントを作成します:
create_endpoint_response = sm_client.create_endpoint(
EndpointName=f"{endpoint_name}", EndpointConfigName=endpoint_config_name)モデルエンドポイントの呼び出し
これは生成モデルなので、ペイロードの一部としてinput_idsとattention_maskをモデルに渡します。以下のコードはテンソルの作成方法を示しています:
tokenizer("This is a sample", padding="max_length", max_length=max_seq_len)次に、データ型がconfig.pbtxtで構成したものと一致するように適切なペイロードを作成します。これにより、Tritonが期待するバッチ次元を含むテンソルが得られます。JSON形式を使用してモデルを呼び出します。Tritonはモデルのネイティブバイナリ呼び出し方法も提供しています。
response = runtime_sm_client.invoke_endpoint(
EndpointName=endpoint_name,
ContentType="application/octet-stream",
Body=json.dumps(payload),
TargetModel=f"{tar_file_name}",
# TargetModel=f"roberta-large-v0.tar.gz",
)前述のコードでTargetModelパラメータに注目してください。モデルの名前をリクエストヘッダーとして渡すため、これはマルチモデルエンドポイントであるため、このパラメータを変更することで既にデプロイされた推論エンドポイントでランタイム中に複数のモデルを呼び出すことができます。これはマルチモデルエンドポイントの強力さを示しています!
レスポンスを出力するには、次のコードを使用できます:
import numpy as np
resp_bin = response["Body"].read().decode("utf8")
# -- keys are -- "outputs":[{"name":"1550","datatype":"FP32","shape":[1,768],"data": [0.0013,0,3433...]}]
for data in json.loads(resp_bin)["outputs"]:
shape_1 = list(data["shape"])
dat_1 = np.array(data["data"])
dat_1.resize(shape_1)
print(f"Data Outputs recieved back :Shape:{dat_1.shape}")パフォーマンスチューニングのためのONNX
ONNX バックエンドは、C++ アリーナメモリ割り当てを使用しています。アリーナ割り当ては、メモリ使用量を最適化し、パフォーマンスを向上させるための C++ 専用機能です。メモリ割り当てと解放は、プロトコルバッファコードで消費される CPU 時間の大部分を占めています。デフォルトでは、新しいオブジェクトの作成は、各オブジェクト、各サブオブジェクト、および文字列などのいくつかのフィールドタイプのヒープ割り当てを行います。これらの割り当ては、メッセージを解析したときと、新しいメッセージをメモリ内に構築するときに一括して行われ、関連する解放は、メッセージとそのサブオブジェクトツリーが解放されるときに行われます。
アリーナベースの割り当ては、このパフォーマンスコストを減らすために設計されています。アリーナ割り当てを使用すると、新しいオブジェクトはアリーナと呼ばれる大きな事前割り当てメモリの中から割り当てられます。オブジェクトはすべて一度に解放でき、アリーナ全体を破棄することができます。理想的には、含まれるオブジェクトのデストラクタを実行せずに解放できます(ただし、必要に応じてアリーナはデストラクタリストを維持できます)。これにより、オブジェクトの割り当てが簡単なポインタの増分にまで簡素化され、解放はほとんど無料になります。アリーナ割り当ては、キャッシュ効率も高くなります。メッセージを解析するときに、連続したメモリに割り当てられる可能性が高くなるため、メッセージのトラバースがホットキャッシュラインにヒットする可能性が高くなります。アリーナベースの割り当てのデメリットは、C++ ヒープメモリがオーバーアロケーションされ、オブジェクトが解放された後も割り当てられたままであることです。これにより、メモリ不足や高い CPU メモリ使用量が発生する可能性があります。両方の世界のベストを実現するために、Triton および ONNX が提供する以下の構成を使用します。
-
arena_extend_strategy – このパラメータは、モデルのサイズに関連してメモリアリーナを拡大するために使用される戦略を参照します。値を 1 (
kSameAsRequested) に設定することをお勧めします。理由は次のとおりです。デフォルトのアリーナ拡張戦略 (kNextPowerOfTwo) の欠点は、必要以上にメモリを割り当てる可能性があることです。名前が示すように、kNextPowerOfTwo(デフォルト) は 2 の累乗でアリーナを拡張しますが、kSameAsRequestedは割り当て要求と同じサイズで拡張します。kSameAsRequestedは、事前に予想されるメモリ使用量を知っている高度な構成に適しています。私たちのテストでは、モデルのサイズが一定値であることを知っているため、kSameAsRequestedを安全に選択できます。 -
gpu_mem_limit – CUDA メモリ制限に値を設定します。可能なメモリをすべて使用するには、最大の
size_tを渡します。指定しない場合、デフォルト値はSIZE_MAXです。デフォルトのままにしておくことをお勧めします。 -
enable_cpu_mem_arena – これにより、CPU 上でメモリアリーナが有効になります。アリーナは将来の使用のためにメモリを事前割り当てする場合があります。使用しない場合は、このオプションを
falseに設定します。デフォルトはTrueです。アリーナを無効にすると、ヒープメモリ割り当てに時間がかかるため、推論レイテンシが増加します。私たちのテストでは、デフォルトのままにしました。 -
enable_mem_pattern – このパラメータは、入力形状に基づく内部メモリ割り当て戦略を参照します。形状が一定である場合、このパラメータを有効にして将来のためのメモリパターンを生成し、割り当て時間を短縮して高速化することができます。メモリパターンを有効にするには 1 を使用し、無効にするには 0 を使用します。入力機能が同じであると予想される場合は、これを 1 に設定することをお勧めします。デフォルト値は 1 です。
-
do_copy_in_default_stream – ONNX の CUDA 実行プロバイダーの文脈で、計算ストリームとは、GPU 上で非同期に実行される CUDA 操作のシーケンスです。ONNX ランタイムは、依存関係に基づいて異なるストリームで操作をスケジュールし、GPU のアイドル時間を最小限に抑えて、より良いパフォーマンスを実現します。同じストリームを使用してコピーと計算を行うためのデフォルト設定 1 を使用することをお勧めします。ただし、コピーと計算に別々のストリームを使用する場合は、0 を使用することができ、デバイスが両方のアクティビティをパイプライン化する可能性があります。ResNet50 モデルのテストでは、0 と 1 の両方を使用しましたが、GPU デバイスのパフォーマンスおよびメモリ消費において、両者の間に明らかな違いは見られませんでした。
-
グラフの最適化 – Triton の ONNX バックエンドは、デプロイされたモデルのサイズおよびランタイムパフォーマンスを微調整するために、いくつかのパラメータをサポートしています。モデルが ONNX 表現に変換されるとき(以下の図の IR ステージの最初のボックス)、ONNX ランタイムは、基本、拡張、およびレイアウト最適化の 3 つのレベルでグラフの最適化を提供します。すべてのグラフの最適化レベルをアクティブにするには、モデル構成ファイルに次のパラメータを追加します。
optimization { graph : { level : 1 }} -
cudnn_conv_algo_search – 私たちはテストで CUDA ベースの Nvidia GPU を使用しているため、ResNet50 モデルを使用したコンピュータビジョンのユースケースでは、
cudnn_conv_algo_searchパラメータを使用した CUDA 実行プロバイダーベースの最適化を 4 層目で使用することができます。デフォルトのオプションは網羅的 (0) ですが、この構成を1 – HEURISTICに変更すると、ステディステートでのモデルレイテンシが 160 ミリ秒に短縮されます。これは、ONNX ランタイムが軽量の cudnnGetConvolutionForwardAlgorithm_v7 のフォワードパスを呼び出すためであり、適切なパフォーマンスでレイテンシを低減します。 -
実行モード – 次のステップは、以下の図のレイヤー 5 で正しい実行モードを選択することです。このパラメータは、グラフ内のオペレータを順番に実行するか
ONNXにおけるパフォーマンスチューニングの機会については、以下の図を参照してください。

出典: https://static.linaro.org/connect/san19/presentations/san19-211.pdf
ベンチマークの数値とパフォーマンスチューニング
ResNet50モデルのテストにおいて、グラフ最適化、
cudnn_conv_algo_search、および並列実行モードパラメータをオンにすることにより、ONNXモデルグラフのコールドスタート時間が4.4秒から1.61秒に短縮されました。完全なモデル構成ファイルの例は、以下のノートブックのONNX構成セクションで提供されています。テストベンチマークの結果は以下の通りです:
- PyTorch – 176ミリ秒、コールドスタート6秒
- TensorRT – 174ミリ秒、コールドスタート4.5秒
- ONNX – 168ミリ秒、コールドスタート4.4秒
以下のグラフはこれらのメトリックを視覚化しています。



さらに、コンピュータビジョンユースケースのテストでは、Tritonが提供するHTTPクライアントを使用してバイナリ形式でリクエストペイロードを送信することを検討すると、モデルの呼び出しレイテンシが大幅に改善されます。
SageMakerがTriton上のONNXで公開する他のパラメータは以下のとおりです。
- 動的バッチ処理 – 動的バッチ処理は、Tritonの機能であり、推論リクエストをサーバー側で組み合わせ、動的にバッチを作成することができます。リクエストのバッチ処理を作成すると、通常はスループットが向上します。動的バッチャーは状態を持たないモデルに使用する必要があります。動的に作成されたバッチは、モデルに構成されたすべてのモデルインスタンスに配布されます。
- 最大バッチサイズ –
max_batch_sizeプロパティは、Tritonが利用可能なバッチ処理のタイプに対してモデルがサポートする最大バッチサイズを示します。モデルのバッチ次元が最初の次元であり、モデルのすべての入力と出力がこのバッチ次元を持つ場合、Tritonは動的バッチャーまたはシーケンスバッチャーを使用してモデルをバッチ処理することができます。この場合、max_batch_sizeは1以上の値に設定する必要があります。Tritonがモデルと一緒に使用する最大バッチサイズを示します。 - デフォルトの最大バッチサイズ – default-max-batch-size値は、他の値が見つからない場合のautocomplete時に
max_batch_sizeに使用されます。onnxruntimeバックエンドは、autocompleteがモデルがリクエストをバッチ処理できることを判断し、モデルの構成でmax_batch_sizeが0であるか、max_batch_sizeがモデル構成から省略されている場合、モデルのmax_batch_sizeをこのデフォルト値に設定します。max_batch_sizeが1以上でスケジューラが提供されていない場合、動的バッチスケジューラが使用されます。デフォルトの最大バッチサイズは、以下のとおりです。
クリーンアップ
ノートブックを実行した後は、モデル、モデル構成、およびモデルエンドポイントを削除してください。これについては、GitHubリポジトリのサンプルノートブックの最後に手順が記載されています。
結論
この記事では、SageMakerでサポートされているTriton Inference ServerのONNXバックエンドについて詳しく説明しました。このバックエンドにより、ONNXモデルをGPUで高速化することができます。推論の最適なパフォーマンスを得るためには、バッチサイズ、データ入力形式、その他の調整可能な要因など、多数のオプションがあります。SageMakerを使用すると、シングルモデルエンドポイントとマルチモデルエンドポイントの両方を使用できます。マルチモデルエンドポイントを使用することで、パフォーマンスとコストのバランスをより良くすることができます。GPUに対するMMEサポートを開始するには、Host multiple models in one container behind one endpointを参照してください。
Triton Inference ServerコンテナをSageMakerでお試しください。ご意見やご質問があれば、コメントでお知らせください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






