「ハリウッドの自宅:DragNUWAは、制御可能なビデオ生成を実現できるAIモデルです」
Hollywood Home DragNUWA is an AI model capable of controllable video generation.


生成AIは、大規模な拡散モデルの成功的なリリースにより、過去2年間で大きな飛躍を遂げました。これらのモデルは、リアルな画像、テキスト、およびその他のデータを生成するために使用できる生成モデルの一種です。
拡散モデルは、ランダムなノイズ画像やテキストから始まり、時間の経過とともに徐々に詳細を追加していきます。このプロセスは拡散と呼ばれ、実世界のオブジェクトが形成されるにつれて徐々に詳細になる方法に似ています。通常、実際の画像やテキストの大規模なデータセットでトレーニングされます。
一方、ビデオ生成も近年驚くべき進歩を遂げています。これは、リアルな動的なビデオコンテンツを完全に生成するという魅力的な能力を包括しています。この技術は、深層学習と生成モデルを活用して、シュールな夢の光景から現実のシミュレーションまで、さまざまな種類のビデオを生成します。
ディープラーニングの力を使って、ビデオのコンテンツ、空間的な配置、時間的な進化を正確に制御する能力は、エンターテイメントや教育など、さまざまな応用分野に大きな可能性を秘めています。
歴史的には、この領域の研究は主に視覚的な手がかりに焦点を当てており、次のビデオの生成には初期フレーム画像を重要視していました。しかし、このアプローチには制約があり、特にカメラの動きや複雑なオブジェクトの軌跡など、ビデオの複雑な時間的ダイナミクスを予測することにおいて制約がありました。これらの課題を克服するために、最近の研究はテキストの説明と軌跡データを追加の制御メカニズムとして組み込む方向にシフトしています。これらのアプローチは大きな進歩を表していますが、それぞれに制約があります。
それでは、これらの制約に取り組むDragNUWAに会いましょう。
DragNUWAは、細かい制御が可能な軌跡認識型ビデオ生成モデルです。テキスト、画像、および軌跡情報をシームレスに統合し、強力でユーザーフレンドリーな制御性を提供します。

DragNUWAは、リアルな見た目のビデオを生成するためのシンプルな公式を持っています。この公式の3つの柱は、意味論的制御、空間的制御、および時間的制御です。これらの制御は、それぞれテキストの説明、画像、および軌跡を使用して行われます。
テキストによる制御は、テキストの説明という形で行われます。これにより、ビデオ生成に意味と意図を注入することができます。例えば、現実の魚の泳ぎと魚の絵の描写の違いなどがあります。
視覚的な制御には、画像が使用されます。画像は空間的な文脈と詳細を提供し、ビデオでオブジェクトやシーンを正確に表現するのに役立ちます。これらはテキストの説明に重要な補完を提供し、生成されたコンテンツに深さと明瞭さを加えます。
これらは私たちにとってすべて馴染みのあるものであり、本当の違いは最後の要素である軌跡制御に見られます。 DragNUWAは、オープンドメインの軌跡制御を使用します。以前のモデルは軌跡の複雑さに苦しんでいましたが、DragNUWAはTrajectory Sampler (TS)、Multiscale Fusion (MF)、およびAdaptive Training (AT)を使用して、この課題に取り組んでいます。このイノベーションにより、複雑なオープンドメインの軌跡、リアルなカメラの動き、複雑なオブジェクトの相互作用を持つビデオの生成が可能になります。
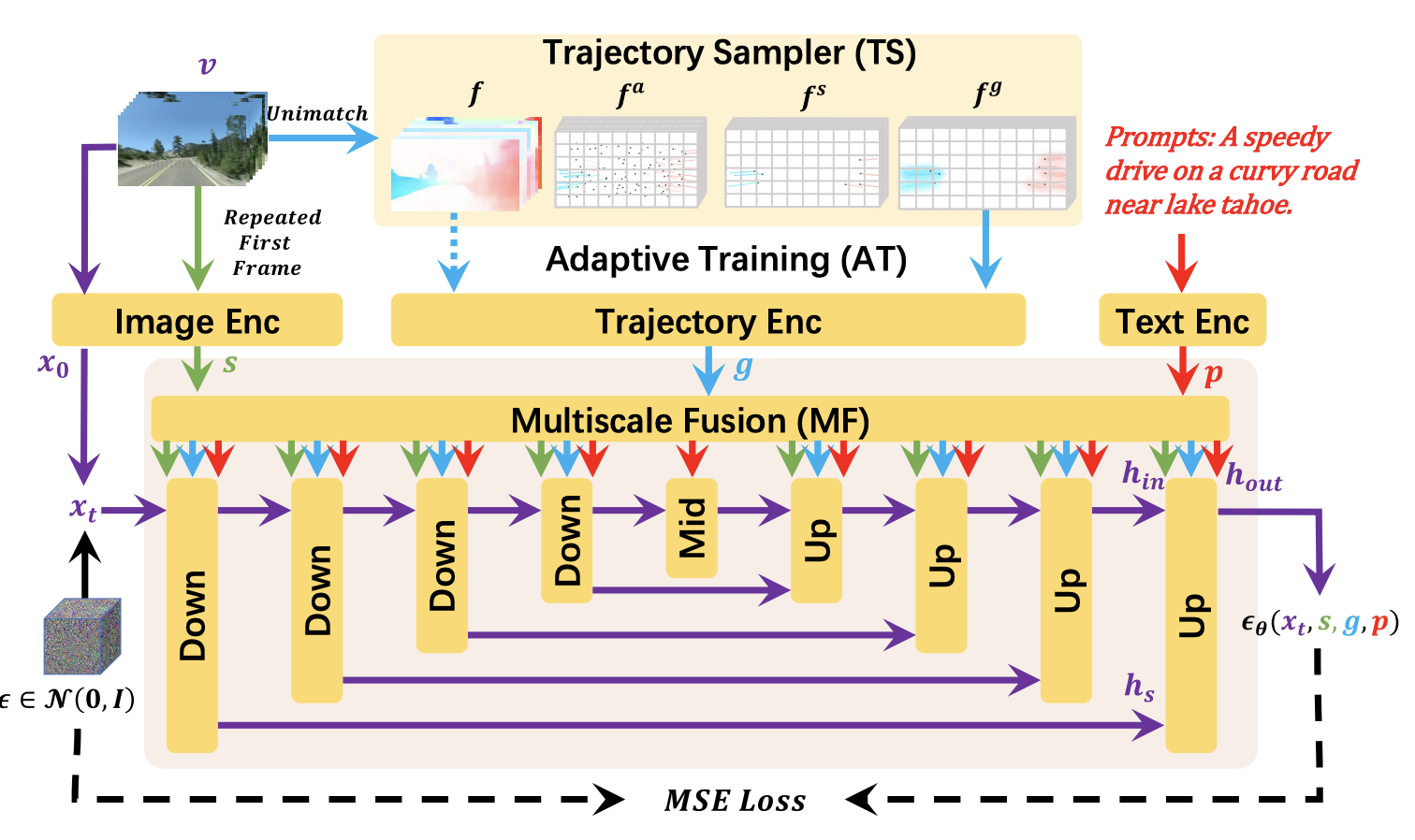
DragNUWA(ドラグヌワ)は、テキスト、画像、軌跡の3つの重要な制御メカニズムを統合したエンドツーエンドのソリューションを提供しています。この統合により、ユーザーはビデオコンテンツに対して正確かつ直感的な制御を行うことができます。ビデオ生成における軌跡制御を新たにイメージし直します。TS、MF、ATの戦略により、任意の軌跡のオープンドメイン制御を実現し、複雑で多様なビデオシナリオに適しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






