ハイカーディナリティのカテゴリカル変数に対する混合効果機械学習-第I部:異なる手法の実証的比較
High-cardinality categorical variable mixed-effects machine learning - Part I Empirical comparison of different methods.
ランダム効果は機械学習モデルにおいてなぜ有用なのか
高基数カテゴリ変数は、データセットのサンプルサイズに対して異なるレベルの数が多い変数であり、つまり、カテゴリ変数の各レベルに対してデータポイントが少ないものを指します。機械学習手法は高基数変数に対して問題を抱えることがあります。本記事では、ランダム効果が機械学習モデルにおいて高基数カテゴリ変数のモデリングに効果的なツールであることを主張します。特に、木ブースティングや深層ニューラルネットワークなど、最も成功している機械学習手法のいくつかのバージョンと、高基数カテゴリ変数を使用した複数の表データセットで、ランダム効果を持つ線形混合効果モデルを経験的に比較します。結果は、まず、ランダム効果を持つ機械学習モデルが、ランダム効果を持たないモデルよりも優れたパフォーマンスを示すこと、そして、ランダム効果を持つ木ブースティングがランダム効果を持つ深層ニューラルネットワークよりも優れたパフォーマンスを示すことを示しています。
目次
・1 イントロダクション ・2 高基数カテゴリ変数のモデリングにおけるランダム効果 ・3 実データセットを用いた異なる手法の比較 ・4 結論 ・参考文献
1 イントロダクション
カテゴリ変数に対処するための簡単な戦略は、ワンホットエンコーディングやダミー変数を使用することです。ただし、このアプローチは高基数カテゴリ変数にはうまく機能しないことがよくあります。ニューラルネットワークの場合、よく採用される解決策はエンティティ埋め込み [Guo and Berkhahn, 2016] を使用することで、カテゴリ変数の各レベルを低次元のユークリッド空間にマッピングします。木ブースティングの場合、カテゴリ変数の各レベルに番号を割り当て、これを1次元の数値変数として扱うというシンプルなアプローチがあります。また、LightGBMブースティングライブラリ [Ke et al., 2017] では、木構築アルゴリズムの分割時に、近似的なアプローチ [Fisher, 1958] を使用してすべてのレベルを2つのサブセットに分割する手法が実装されています。さらに、CatBoostブースティングライブラリ [Prokhorenkova et al., 2018] では、カテゴリ予測変数の処理においてトレーニングデータのランダムパーティションを使用した順序付きターゲット統計に基づくアプローチが実装されています。
2 高基数カテゴリ変数のモデリングにおけるランダム効果
ランダム効果は、高基数カテゴリ変数のモデリングに効果的なツールとして使用することができます。単一の高基数カテゴリ変数の回帰ケースでは、ランダム効果モデルは次のように表されます
- 分子の言語を学び、その特性を予測する
- JourneyDBとは:多様かつ高品質な生成画像が400万枚収録された大規模データセットであり、マルチモーダルな視覚理解のためにキュレーションされています
- Amazon SageMaker Ground Truthのはじめ方
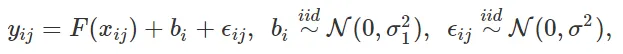
ここで、j=1,…,niはレベルi内のサンプルインデックスであり、niはカテゴリ変数がレベルiを取るサンプル数です。iはカテゴリ変数のレベルを示し、qはカテゴリ変数の総レベル数です。サンプルの総数は、n = n0 + n1 + … + nqとなります。このようなモデルは、固定効果F(xij)とランダム効果biの両方を含むため、混合効果モデルとも呼ばれます。xijは固定効果の予測変数または特徴量です。混合効果モデルは、他の応答変数分布(分類など)や複数のカテゴリ変数にも拡張することができます。
従来、ランダム効果はFが線形関数であると仮定される線形モデルで使用されていました。近年では、ランダム効果は非線形モデルにも拡張されており、ランダムフォレスト [Hajjem et al., 2014]、木ブースティング [Sigrist, 2022 , 2023a ]、そして最近(最初の公開プレプリントの観点で)深層ニューラルネットワーク [Simchoni and Rosset, 2021 , 2023 ] によって使用されています。古典的な独立した機械学習モデルとは異なり、ランダム効果はサンプル間に相関関係を導入します。
高次元のカテゴリ変数において、なぜランダム効果が有用なのでしょうか?
高次元のカテゴリ変数では、各レベルごとにデータが少ないです。直感的には、応答変数が多くのレベルに対して異なる(条件付きの)平均を持つ場合、従来の機械学習モデル(例えば、ワンホットエンコーディング、埋め込み、または単純な一次元数値変数)では、このようなデータに対して過剰適合または適合不足の問題が発生する可能性があります。古典的なバイアス-バリアンストレードオフの観点から見ると、独立した機械学習モデルはこのトレードオフをバランスさせ、適切な正則化の量を見つけるのに困難を抱えるかもしれません。例えば、過剰適合が発生すると、モデルは低いバイアスを持ちますが高い分散を持ちます。
一般的に言えば、ランダム効果は事前分布、または正則化項として機能し、関数の難しい部分、すなわち「次元」が全サンプルサイズと同様の部分をモデリングし、これにより過剰適合と適合不足、またはバイアスとバリアンスのバランスを見つける効果的な方法を提供します。例えば、単一のカテゴリ変数の場合、ランダム効果モデルではグループの切片効果の推定値をグローバル平均に収束させます。このプロセスは「情報プーリング」とも呼ばれることがあります。これは、カテゴリ変数を完全に無視する(適合不足/高バイアスおよび低分散)か、カテゴリ変数のすべてのレベルに「完全な自由度」を与える(過剰適合/低バイアスおよび高分散)か、これら2つの極端なケースとランダム効果モデルの収縮係数 σ²_1 / (σ²/ni + σ²_1 and σ²) の違いです(レベル i のサンプル数 ni が大きい場合、これはゼロに近づきます)。これに関連して、ランダム効果モデルは固定効果関数 F(.) のより効率的な(つまり、分散が低い)推定を可能にします [Sigrist, 2022]。
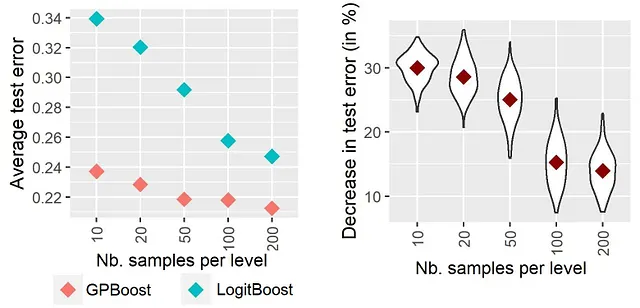
この議論と一致する形で、Sigrist [2023a, セクション 4.1] は実験的な実験において、ランダム効果(”GPBoost”)を組み合わせたツリーブースティングが、伝統的な独立したツリーブースティング(”LogitBoost”)よりも、カテゴリ変数のレベルごとのサンプル数が少ない場合(すなわち、カテゴリ変数の基数が高い場合)により良い結果を示すことを発見しました。これらの結果は、図 1 に示されています。これらの結果は、5000 のサンプル、非線形の予測関数、およびサンプル数が少なくなるように段階的にレベルが増えるカテゴリ変数をシミュレーションして得られました。詳細については、Sigrist [2023a] を参照してください。結果は、GPBoost と LogitBoost のテストエラーの差が、カテゴリ変数のレベルごとのサンプル数が少ないほど大きいことを示しています。
3 実データセットを使用した異なる方法の比較
以下では、高次元のカテゴリ変数を持つ複数の実データセットを使用して、いくつかの方法を比較します。私たちは、Simchoni と Rosset [2021, 2023] の公開されているタブラーデータセットと、Simchoni と Rosset [2021, 2023] と同じ実験設定を使用します。さらに、Sigrist [2022] で分析された Wages データセットも含めます。
以下の方法を考慮します:
- 「Linear」:線形混合効果モデル
- 「NN Embed」:埋め込みを使用した深層ニューラルネットワーク
- 「LMMNN」:深層ニューラルネットワークとランダム効果の組み合わせ [Simchoni と Rosset, 2021, 2023]
- 「LGBM_Num」:カテゴリ変数の各レベルに数値を割り当て、これを一次元の数値変数として考慮したツリーブースティング
- 「LGBM_Cat」:カテゴリ変数に対する
LightGBM[Ke et al., 2017] のアプローチを使用したツリーブースティング - 「CatBoost」:カテゴリ変数に対する
CatBoost[Prokhorenkova et al., 2018] のアプローチを使用したツリーブースティング - 「GPBoost」:ツリーブースティングとランダム効果を組み合わせたモデル [Sigrist, 2022, 2023a]
最近(バージョン1.6以降)XGBoostライブラリ[Chen and Guestrin、2016]もLightGBMと同様のアプローチをカテゴリ変数の処理に実装しました。私たちはこれをここでは別のアプローチとは見なしていません。
私たちは次のデータセットを使用します:
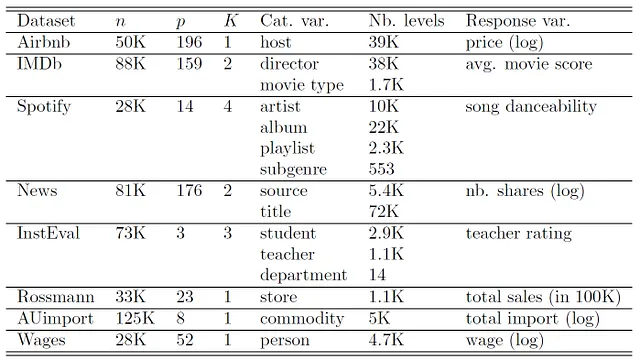
すべてのランダム効果を持つ手法では、Table 1に記載されているすべてのカテゴリ変数にランダム効果を含めますが、ランダム効果間に事前の相関はありません。Rossmann、AUImport、およびWagesのデータセットは縦断的なデータセットです。これらには線形および二次のランダム傾斜も含まれます。このシリーズの(将来の)第III部を参照してください。データセットの詳細については、Simchoni and Rosset [2021, 2023]およびSigrist [2023b]を参照してください。
予測精度を測定するために、すべてのデータセットで5分割交差検証(CV)を実施し、テスト平均二乗誤差(MSE)を使用します。実験設定の詳細については、Sigrist [2023b]を参照してください。データの前処理のためのコードとデータおよび実験の実行手順に関する指示は、ここで見つけることができます。元のソースのライセンスが許可するデータセットのためのモデリングのための前処理済みデータも、上記のウェブページで見つけることができます。
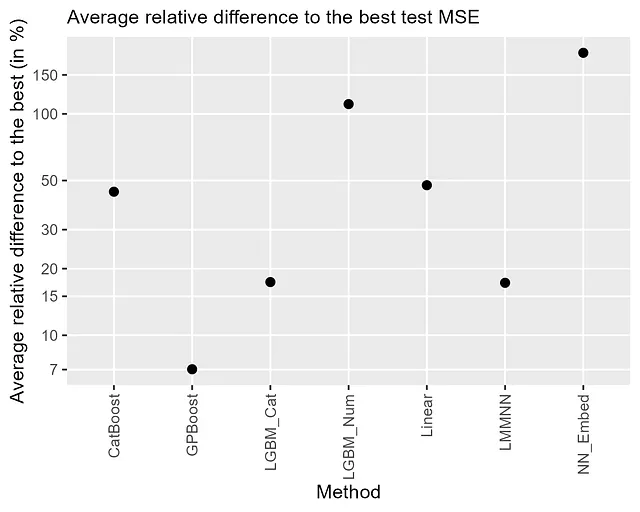
結果は図2にまとめられており、最低テストMSEとの平均相対差を示しています。これは、各データセットのテストMSEと最小MSEとの相対差を計算し、すべてのデータセットにわたって平均を取ることで得られます。詳細な結果については、Sigrist [2023b]を参照してください。結果から、組み合わせた木ブースティングとランダム効果(GPBoost)が最も高い予測精度を持ち、最良の結果との平均相対差は約7%です。2番目に良い結果は、LightGBMのカテゴリ変数アプローチ(LGMB_Cat)およびランダム効果を持つニューラルネットワーク(LMMNN)であり、最良の手法との平均相対差は約17%です。CatBoostと線形混合効果モデルは、最良の手法との平均相対差がほぼ50%でもっとも悪い結果を示します。CatBoostは「カテゴリ特徴量を解決しようとする」(2023年7月6日時点のWikipedia)ものであるため、これはやや慎重な結果です。最も悪い結果は、平均相対差が150%以上の埋め込みを持つニューラルネットワークです。カテゴリ変数を1次元の数値変数に変換した木ブースティング(LGBM_Num)は、最良の結果との平均相対差が約100%でわずかに良い結果を示します。 LightGBMのオンラインドキュメントでは、「高基数のカテゴリ特徴量の場合、数値として扱うのが最も効果的であることがよくある」(2023年7月6日時点)と推奨しています。私たちは明らかに異なる結論に達しています。
4 結論
私たちは高基数のカテゴリ変数を持つ表形式のデータにおいて、いくつかの手法を実証的に比較しました。私たちの結果は、第一に、ランダム効果を持つ機械学習モデルの方がランダム効果を持たないモデルよりも優れたパフォーマンスを示すこと、第二に、ランダム効果を持つ木ブースティングがランダム効果を持つディープニューラルネットワークよりも優れた結果を示すことを示しています。後者の結果にはいくつかの可能な理由があるかもしれませんが、これは高基数のカテゴリ変数を持たない表形式のデータにおいて、Grinsztajnらの最近の研究[2022]にも合致しています。彼らは、木ブースティングがディープニューラルネットワーク(およびランダムフォレスト)を上回ることを発見しています。同様に、Shwartz-ZivとArmon [2022]も、「木ブースティングは表形式のデータでディープモデルよりも優れている」と結論づけています。
このシリーズの第II部では、上記のいずれかの実世界のデータセットを使用したデモを行いながら、GPBoostライブラリの適用方法を紹介します。第III部では、GPBoostライブラリを使用して縦断データ、またはパネルデータをモデル化する方法を紹介します。
参考文献
- T. Chen and C. Guestrin. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, pages 785–794. ACM, 2016.
- W. D. Fisher. On grouping for maximum homogeneity. Journal of the American statistical Association, 53(284):789–798, 1958.
- L. Grinsztajn, E. Oyallon, and G. Varoquaux. Why do tree-based models still outperform deep learning on typical tabular data? In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 507–520. Curran Associates, Inc., 2022.
- C. Guo and F. Berkhahn. Entity embeddings of categorical variables. arXiv preprint arXiv:1604.06737, 2016.
- A. Hajjem, F. Bellavance, and D. Larocque. Mixed-effects random forest for clustered data. Journal of Statistical Computation and Simulation, 84(6):1313–1328, 2014.
- G. Ke, Q. Meng, T. Finley, T. Wang, W. Chen, W. Ma, Q. Ye, and T.-Y. Liu. LightGBM: A highly efficient gradient boosting decision tree. In Advances in Neural Information Processing Systems, pages 3149–3157, 2017.
- L. Prokhorenkova, G. Gusev, A. Vorobev, A. V. Dorogush, and A. Gulin. CatBoost: unbiased boosting with categorical features. In Advances in Neural Information Processing Systems, pages 6638–6648, 2018.
- R. Shwartz-Ziv and A. Armon. Tabular data: Deep learning is not all you need. Information Fusion, 81:84–90, 2022.
- F. Sigrist. Gaussian Process Boosting. The Journal of Machine Learning Research, 23(1):10565–10610, 2022.
- F. Sigrist. Latent Gaussian Model Boosting. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(2):1894–1905, 2023a.
- F. Sigrist. A Comparison of Machine Learning Methods for Data with High-Cardinality Categorical Variables. arXiv preprint arXiv::2307.02071 2023b.
- G. Simchoni and S. Rosset. Using random effects to account for high-cardinality categorical features and repeated measures in deep neural networks. Advances in Neural Information Processing Systems, 34:25111–25122, 2021.
- G. Simchoni and S. Rosset. Integrating Random Effects in Deep Neural Networks. Journal of Machine Learning Research, 24(156):1–57, 2023.
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
