Python におけるカテゴリカル変数の扱い方ガイド
Guide to Handling Categorical Variables in Python.
機械学習とデータサイエンスの目的におけるカテゴリカル変数のアプローチに関するガイド

データサイエンスや機械学習のプロジェクトにおいて、カテゴリカル変数を扱うことは容易ではありません。この種の作業には、適用分野の深い知識と、利用可能な多数の手法に対する幅広い理解が必要です。
そのため、本記事では以下の概念を説明することに焦点を当てます。
- カテゴリカル変数とは何であり、異なるタイプに分類する方法
- タイプに基づいた数値への変換方法
- 主にSklearnを使用した管理のためのツールや技術
カテゴリカル変数を適切に扱うことは、予測モデルや分析の結果を大幅に改善することができます。実際、データの学習と理解に関連する情報のほとんどは、利用可能なカテゴリカル変数に含まれる可能性があります。
たとえば、genderやあるcolorによって分割された表形式のデータを考えてみてください。これらのスプリットは、カテゴリの数に基づいて、グループ間の重要な違いを明らかにし、分析者や学習アルゴリズムに情報を提供することができます。
まず、カテゴリカル変数が何であるか、どのように表示されるかを定義することから始めましょう。
カテゴリカル変数の定義
カテゴリカル変数は、統計学やデータサイエンスで使用される変数の一種で、定性的または名義的データを表します。これらの変数は、連続的に量化することができず、離散的にしか定義できません。
たとえば、カテゴリカル変数の例としては、人の目の色があります。これはブルー、グリーン、ブラウンのいずれかです。
ほとんどの学習モデルは、カテゴリカル形式のデータを使用しません。情報を保持するために、まず数値形式に変換する必要があります。
カテゴリカル変数は、以下の2つのタイプに分類されます。
- 名義
- 順序
名義変数は、厳密な順序に制約を受けない変数です。性別、色、ブランドなどは、名義変数の例です。
順序変数は、論理的に順序付け可能なレベルに分類されたカテゴリカル変数です。First、Second、Thirdなどのレベルで構成されたデータセットの列は、順序カテゴリカル変数と見なすことができます。
さらに、バイナリ変数と循環変数を考慮することで、カテゴリカル変数の分解をより深く掘り下げることができます。
バイナリ変数は、理解するのが簡単です。2つの値しか取れないカテゴリカル変数です。
循環変数は、その値が繰り返されることを特徴とします。たとえば、曜日や季節が循環的な変数です。
カテゴリカル変数の変換方法
カテゴリカル変数が何であるか、どのように表示されるかを定義したところで、実際の例を使用して変換の方法について説明してみましょう。 Kaggleデータセットのcat-in-the-datというデータセットがあります。
データセット
これは、カテゴリカル変数の管理とモデリングに関する入門的な競技会であるCategorical Feature Encoding Challenge IIの基礎となるオープンソースのデータセットです。以下のリンクからデータを直接ダウンロードできます。
Categorical Feature Encoding Challenge II
Binary classification, with every feature a categorical (and interactions!)
www.kaggle.com
このデータセットの特異性は、カテゴリカルデータのみを含んでいることです。そのため、このガイドに最適なユースケースとなります。名義、順序、循環、バイナリ変数が含まれています。
それぞれの変数を学習モデルで使用できる形式に変換するためのテクニックを見ていきましょう。
データセットは以下のようになっています。
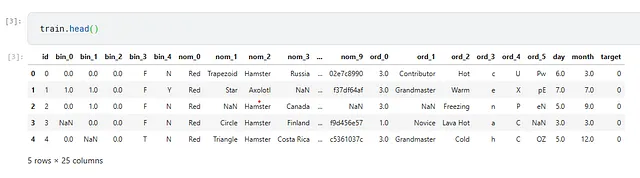
目的変数が2つの値しか取り得ないため、これは二値分類タスクです。モデルを評価するためにAUCメトリックを使用します。
今度は、言及されたデータセットを使用して、カテゴリカル変数を管理するためのテクニックを適用します。
1. ラベルエンコーディング(任意の数にマッピング)
カテゴリを使用可能な形式に変換するための最も単純なテクニックは、各カテゴリに任意の数を割り当てることです。
たとえば、カテゴリを含むord_2列を取り上げます。
array(['Hot', 'Warm', 'Freezing', 'Lava Hot', 'Cold', 'Boiling Hot', nan], dtype=object)このマッピングは、PythonとPandasを使用して次のように行うことができます。
df_train = train.copy()mapping = { "Cold": 0, "Hot": 1, "Lava Hot": 2, "Boiling Hot": 3, "Freezing": 4, "Warm": 5}df_train["ord_2"].map(mapping)>> 0 1.01 5.02 4.03 2.04 0.0 ... 599995 4.0599996 3.0599997 4.0599998 5.0599999 3.0Name: ord_2, Length: 600000, dtype: float64ただし、この方法には問題があります。小規模なカテゴリには問題ありませんが、大規模なカテゴリの場合は手動でマッピングを宣言する必要があります。
そのため、Scikit-LearnとLabelEncoderオブジェクトを使用して、より柔軟な方法で同じ結果を得ることができます。
from sklearn import preprocessing# 欠損値を処理するdf_train["ord_2"].fillna("NONE", inplace=True)# sklearnエンコーダを初期化le = preprocessing.LabelEncoder()# fit + transformdf_train["ord_2"] = le.fit_transform(df_train["ord_2"])df_train["ord_2"]>>0 31 62 23 44 1 ..599995 2599996 0599997 2599998 6599999 0Name: ord_2, Length: 600000, dtype: int64マッピングはSklearnによって制御されます。次のように可視化できます。
mapping = {label: index for index, label in enumerate(le.classes_)}mapping>>{'Boiling Hot': 0, 'Cold': 1, 'Freezing': 2, 'Hot': 3, 'Lava Hot': 4, 'NONE': 5, 'Warm': 6}コードスニペット上の.fillna("NONE")に注目してください。実際、Sklearnのラベルエンコーダは空の値を処理せず、見つかった場合に適用するとエラーが発生します。
カテゴリ変数を正しく処理するための最も重要なことの1つは、常に空の値を処理することです。実際、関連する技術のほとんどはこれに対処しない場合には機能しないので注意が必要です。
ラベルエンコーダは、列内の各カテゴリに任意の数をマッピングすることなく、ラベルエンコーディングを実行します。これは便利ですが、いくつかの予測モデルに問題を導入します。つまり、列がターゲットでない場合には、データをスケーリングする必要があるということです。
実際、機械学習初心者は、ラベルエンコーダとワンホットエンコーダの違いについてよく尋ねます。ワンホットエンコーディングについてはすぐに見ていきます。ラベルエンコーダは、設計上、ラベル、つまり予測したいターゲット変数に適用する必要があります。他の列には適用しないでください。
これにもかかわらず、このタイプのエンコーディングでもうまく機能する非常に重要なモデルもあります。XGBoostやLightGBMなどの決定木モデルが挙げられます。
したがって、木モデルを使用する場合はラベルエンコーダを使用しても問題ありませんが、それ以外の場合はワンホットエンコーディングを使用する必要があります。
2. ワンホットエンコーディング
私が機械学習におけるベクトル表現についての記事ですでに触れたように、ワンホットエンコーディングは非常に一般的で有名なベクトル化技術です(つまり、テキストを数値に変換すること)。
以下のように動作します。各カテゴリに対して、0と1のみが可能な正方行列が作成されます。この行列により、観察された行が1で表される値を持つすべての可能なカテゴリの中で、モデルに情報を提供します。
例:
| | | | | | -------------|---|---|---|---|---|--- Freezing | 0 | 0 | 0 | 0 | 0 | 1 Warm | 0 | 0 | 0 | 0 | 1 | 0 Cold | 0 | 0 | 0 | 1 | 0 | 0 Boiling Hot | 0 | 0 | 1 | 0 | 0 | 0 Hot | 0 | 1 | 0 | 0 | 0 | 0 Lava Hot | 1 | 0 | 0 | 0 | 0 | 0 配列のサイズはn_categoriesです。これは非常に有用な情報です。なぜなら、ワンホットエンコーディングは、変換されたデータの疎な表現を必要とするからです。
それは何を意味するのでしょうか?多数のカテゴリがある場合、行列は同じくらい大きくなる可能性があります。値が0または1のみで構成され、位置の1つだけが1であることから、ワンホット表現は非常に冗長で重くなります。
疎行列はこの問題を解決します – 1の位置だけが保存され、0と等しい値が保存されません。これにより、問題が単純化され、非常に少量のメモリ使用量に対して膨大な情報の配列を保存できるようになります。
Pythonでそのような配列がどのように見えるかを見てみましょう。前述のコードを適用する
from sklearn import preprocessing# we handle missing valuesdf_train["ord_2"].fillna("NONE", inplace=True)# init sklearn's encoderohe = preprocessing.OneHotEncoder()# fit + transformohe.fit_transform(df_train["ord_2"].values.reshape(-1, 1))>><600000x7 sparse matrix of type '<class 'numpy.float64'>' with 600000 stored elements in Compressed Sparse Row format>Pythonはデフォルトでオブジェクトを返します。リストを取得するには、.toarray()を使用する必要があります。
ohe.fit_transform(df_train["ord_2"].values.reshape(-1, 1)).toarray()>>array([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 1.], [0., 0., 1., ..., 0., 0., 0.], ..., [0., 0., 1., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 1.], [1., 0., 0., ..., 0., 0., 0.]])概念が完全に理解できなくても心配しないでください。ラベルエンコーダとワンホットエンコーダをデータセットに適用して予測モデルをトレーニングする方法についてすぐに見ていきます。
ラベルエンコーディングとワンホットエンコーディングは、カテゴリ変数を処理するための最も重要な技術です。これら2つのテクニックを知っていれば、ほとんどのカテゴリ変数を処理できます。
3. 変換と集計
カテゴリから数値形式に変換する別の方法は、変換または集計を行うことです。
.groupby()を使用してグループ化することで、列に存在する値の数を変換の出力として使用することができます。
df_train.groupby(["ord_2"])["id"].count()>>ord_2Boiling Hot 84790Cold 97822Freezing 142726Hot 67508Lava Hot 64840Warm 124239Name: id, dtype: int64.transform()を使用することで、これらの数値を対応するセルに置き換えることができます。
df_train.groupby(["ord_2"])["id"].transform("count")>>0 67508.01 124239.02 142726.03 64840.04 97822.0 ... 599995 142726.0599996 84790.0599997 142726.0599998 124239.0599999 84790.0Name: id, Length: 600000, dtype: float64他の数学的演算でもこのロジックを適用することができます — モデルの性能を最も向上させる方法をテストする必要があります。
4. カテゴリ変数から新しいカテゴリ特徴量を作成する
ord_1 列と ord_2 を一緒に見てみましょう。
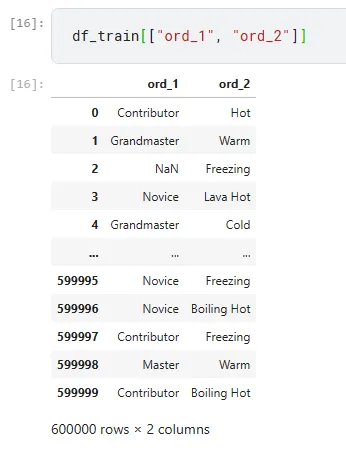
既存の変数をマージして新しいカテゴリ変数を作成することができます。たとえば、ord_1 を ord_2 とマージして新しい特徴量を作成することができます。
df_train["new_1"] = df_train["ord_1"].astype(str) + "_" + df_train["ord_2"].astype(str)df_train["new_1"]>>0 Contributor_Hot1 Grandmaster_Warm2 nan_Freezing3 Novice_Lava Hot4 Grandmaster_Cold ... 599995 Novice_Freezing599996 Novice_Boiling Hot599997 Contributor_Freezing599998 Master_Warm599999 Contributor_Boiling HotName: new_1, Length: 600000, dtype: objectこの技術は、ほとんどの場合に適用することができます。アナリストが導くべきアイデアは、学習モデルに元々理解が困難だった情報を追加して、モデルの性能を向上させることです。
5. NaN をカテゴリ変数として使用する
非常に頻繁に、null 値が削除されます。これは通常、お勧めしない移動です。NaN には、モデルにとって潜在的に有用な情報が含まれているためです。
1つの解決策は、NaN を独自のカテゴリとして扱うことです。
再び ord_2 列を見てみましょう。
df_train["ord_2"].value_counts()>>Freezing 142726Warm 124239Cold 97822Boiling Hot 84790Hot 67508Lava Hot 64840Name: ord_2, dtype: int64今度は、.fillna("NONE") を適用して空のセルがいくつあるかを見てみましょう。
df_train["ord_2"].fillna("NONE").value_counts()>>Freezing 142726Warm 124239Cold 97822Boiling Hot 84790Hot 67508Lava Hot 64840NONE 18075割合で表すと、NONE は列全体の約3%を占めます。かなり目立つ量です。NaN を利用することはさらに意味があり、前に説明した One Hot Encoder を使用することができます。
稀なカテゴリのトラッキング
OneHotEncoder が行うことを思い出しましょう: それは、参照される列内のユニークなカテゴリの数と同じ数の列と行を持つ疎行列を作成します。これは、テストセットに存在する可能性があるカテゴリも考慮する必要があることを意味します。また、LabelEncoder についても同様の状況があります。テストセットにはトレーニングセットに存在しないカテゴリが含まれている場合があり、変換中に問題が発生する可能性があります。
この問題は、データセットを連結することで解決できます。これにより、エンコーダをトレーニングデータだけでなくすべてのデータに適用することができます。
test["target"] = -1data = pd.concat([train, test]).reset_index(drop=True)features = [f for f in train.columns if f not in ["id", "target"]]for feature in features: le = preprocessing.LabelEncoder() temp_col = data[feature].fillna("NONE").astype(str).values data.loc[:, feature] = le.fit_transform(temp_col) train = data[data["target"] != -1].reset_index(drop=True)test = data[data["target"] == -1].reset_index(drop=True)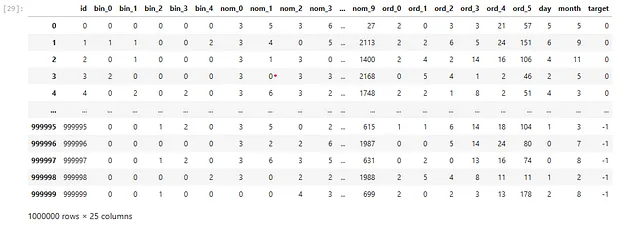
この方法論は、テストセットがある場合に役立ちます。テストセットがない場合は、新しいカテゴリがトレーニングセットの一部になったときに NONE のような値を考慮に入れます。
カテゴリカルデータのモデル化
さて、簡単なモデルのトレーニングに移りましょう。ここでは、以下のリンクの記事に従って、交差検証の設計と実装の手順について説明します👇
機械学習における交差検証とは何か
汎化モデルを構築するための基本的なテクニックである交差検証について学ぶ
towardsdatascience.com
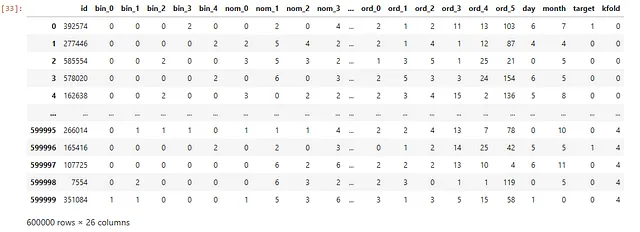
まず、SklearnのStratifiedKFoldを使用して、データをインポートし、フォールドを作成します。
train = pd.read_csv("/kaggle/input/cat-in-the-dat-ii/train.csv")test = pd.read_csv("/kaggle/input/cat-in-the-dat-ii/test.csv")df = train.copy()df["kfold"] = -1df = df.sample(frac=1).reset_index(drop=True)y = df.target.valueskf = model_selection.StratifiedKFold(n_splits=5)for f, (t_, v_) in enumerate(kf.split(X=df, y=y)): df.loc[v_, 'kfold'] = fこのコードのスニペットは、Pandasデータフレームを作成し、モデルをテストするための5つのグループを作成します。
次に、ロジスティック回帰モデルを各グループでテストする関数を定義しましょう。
def run(fold: int) -> None: features = [ f for f in df.columns if f not in ("id", "target", "kfold") ] for feature in features: df.loc[:, feature] = df[feature].astype(str).fillna("NONE") df_train = df[df["kfold"] != fold].reset_index(drop=True) df_valid = df[df["kfold"] == fold].reset_index(drop=True) ohe = preprocessing.OneHotEncoder() full_data = pd.concat([df_train[features], df_valid[features]], axis=0) print("Fitting OHE on full data...") ohe.fit(full_data[features]) x_train = ohe.transform(df_train[features]) x_valid = ohe.transform(df_valid[features]) print("Training the classifier...") model = linear_model.LogisticRegression() model.fit(x_train, df_train.target.values) valid_preds = model.predict_proba(x_valid)[:, 1] auc = metrics.roc_auc_score(df_valid.target.values, valid_preds) print(f"FOLD: {fold} | AUC = {auc:.3f}")run(0)>>Fitting OHE on full data...Training the classifier...FOLD: 0 | AUC = 0.785コードの詳細については、交差検証の記事を読んで理解することをお勧めします。
次に、LabelEncoderともう1つのツリーモデルであるXGBoostを適用する方法を見てみましょう。
def run(fold: int) -> None: features = [ f for f in df.columns if f not in ("id", "target", "kfold") ] for feature in features: df.loc[:, feature] = df[feature].astype(str).fillna("NONE") print("Fitting the LabelEncoder on the features...") for feature in features: le = preprocessing.LabelEncoder() le.fit(df[feature]) df.loc[:, feature] = le.transform(df[feature]) df_train = df[df["kfold"] != fold].reset_index(drop=True) df_valid = df[df["kfold"] == fold].reset_index(drop=True) x_train = df_train[features].values x_valid = df_valid[features].values print("Training the classifier...") model = xgboost.XGBClassifier(n_jobs=-1, n_estimators=300) model.fit(x_train, df_train.target.values) valid_preds = model.predict_proba(x_valid)[:, 1] auc = metrics.roc_auc_score(df_valid.target.values, valid_preds) print(f"FOLD: {fold} | AUC = {auc:.3f}")# 2つのフォールドで実行for fold in range(2): run(fold)>>Fitting the LabelEncoder on the features...Training the classifier...FOLD: 0 | AUC = 0.768Fitting the LabelEncoder on the features...Training the classifier...FOLD: 1 | AUC = 0.765結論
結論として、カテゴリカル変数を扱うための他の技術もあります:
- ターゲットベースのエンコーディング、カテゴリがそれに対応するターゲット変数によって取りうる平均値に変換される方法
- ニューラルネットワークの埋め込み、テキストエンティティを表すために使用できる方法
要約すると、カテゴリカル変数を正しく管理するための基本的な手順は以下の通りです:
- 常にヌル値を扱う
- 変数のタイプと使用するテンプレートに基づいて、LabelEncoderまたはOneHotEncoderを適用する
- NaNまたはNONEをモデルに情報を提供できるカテゴリカル変数として考え、変数の充実について考える
- データをモデル化する!
お時間いただきありがとうございます、アンドレア
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
