「Hugging Face AutoTrainを使用して、LLM(Language Model)を微調整する方法」
「ハグフェイスのAutoTrainを利用したLLM(ランゲージモデル)の微調整方法」

イントロダクション
近年、大規模言語モデル(LLM)は人々の仕事の仕方を変え、教育、マーケティング、研究などさまざまな分野で使用されてきました。潜在的な性能を考慮すると、LLMはビジネスの問題をより良く解決するために向上させることができます。そのため、LLMのファインチューニングを実行することができるのです。
- このAIの論文は、純粋なゼロショットの設定で、タスクの適応と未知のタスクや環境への一般化に優れたCLIN(Continuous Learning Language Agent)を紹介しています
- このAI論文では、「ビデオ言語計画(VLP)」という新しい人工知能アプローチを提案していますこのアプローチは、ビジョン言語モデルとテキストからビデオへのダイナミクスを組み合わせたツリーサーチ手法で構成されています
- 「LAMPをご紹介します:テキストからイメージ拡散モデルで動作パターンを学ぶためのフューションAIフレームワーク」
特定のドメインのユースケースの採用、精度の改善、データのプライバシーとセキュリティの向上、モデルの偏見の制御など、これらの理由を含め、LLMをファインチューニングしたいと考えています。これらの利点を考慮すると、LLMをファインチューニングして本番環境で使用する方法を学ぶことは非常に重要です。
LLMの自動ファインチューニングを行う方法の一つは、Hugging FaceのAutoTrainを使用することです。HF AutoTrainは、コンピュータビジョン、タブラー、およびNLPタスクなどのさまざまなタスクのための最先端モデルをトレーニングするためのPython APIを使用したノーコードプラットフォームです。LLMのファインチューニングのプロセスについてあまり理解していなくても、AutoTrainの機能を利用することができます。
では、どのように機能するのでしょうか?さらに探ってみましょう。
AutoTrainの始め方
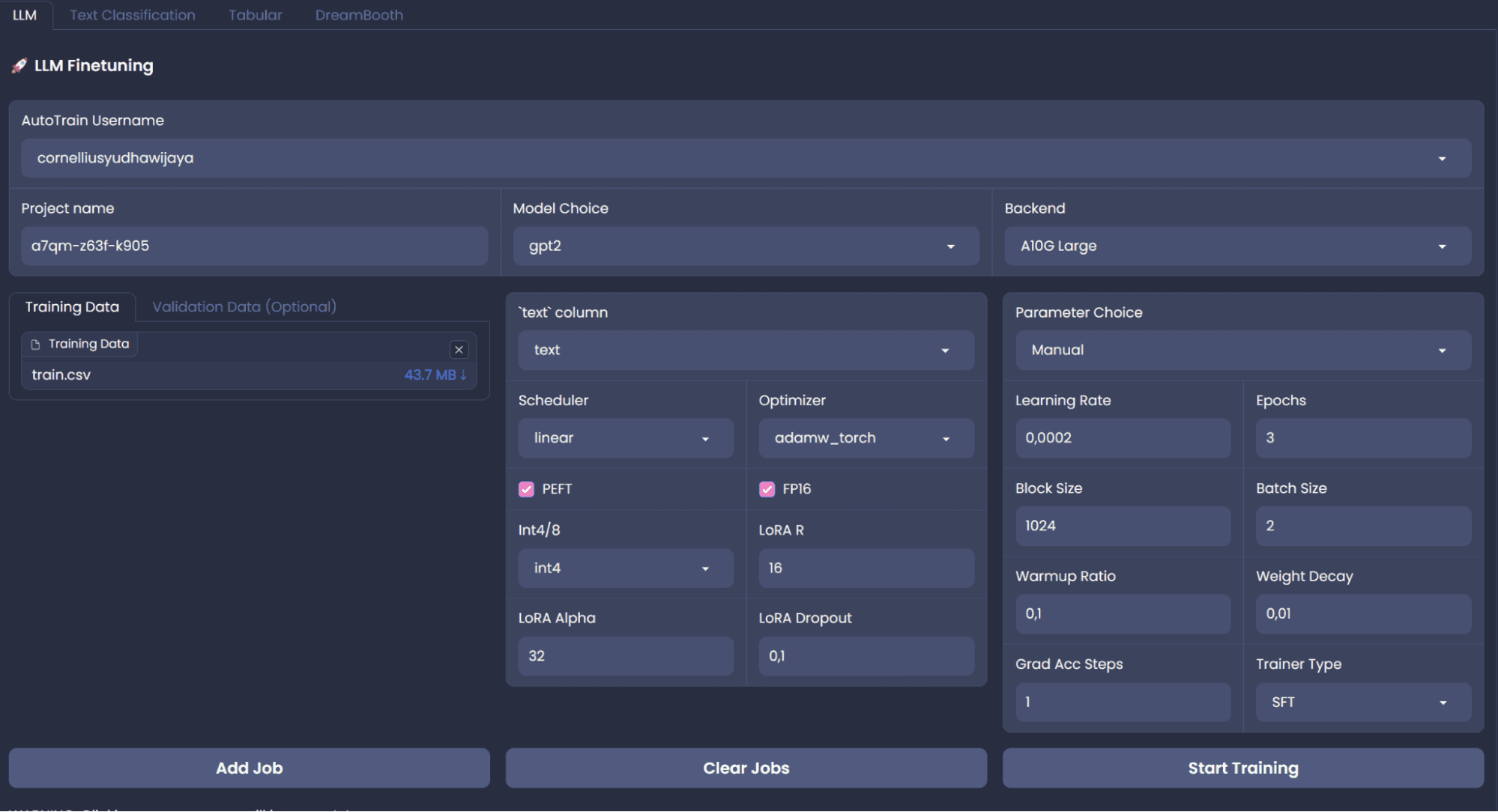
HF AutoTrainはノーコードの解決策ですが、Python APIを使用してAutoTrainの上に開発することができます。トレーニングにはノーコードプラットフォームが安定していないため、コードのルートを試してみます。ただし、ノーコードプラットフォームを使用する場合は、次のページを使用してAutoTrainスペースを作成することができます。全体プラットフォームは以下の画像に表示されます。
Python APIを使用してLLMをファインチューニングするために、次のコードを実行してPythonパッケージをインストールする必要があります。
pip install -U autotrain-advanced
また、HuggingFaceのAlpacaサンプルデータセットを使用しますが、それを取得するためにはdatasetsパッケージが必要です。
pip install datasets
次に、必要なデータを取得するために以下のコードを使用します。
from datasets import load_dataset #データセットを読み込むdataset = load_dataset("tatsu-lab/alpaca") train = dataset['train']
さらに、ファインチューニングに必要なデータをCSV形式で保存します。
train.to_csv('train.csv', index = False)
環境とデータセットの準備ができたら、HuggingFaceのAutoTrainを使用してLLMをファインチューニングしてみましょう。
ファインチューニングの手順と評価
ここでは、AutoTrainの例からファインチューニングのプロセスを適応します。プロセスを開始するには、ファインチューニングに使用するデータをdataというフォルダに配置します。

このチュートリアルでは、たった100行のデータサンプルのみを使用するため、トレーニングプロセスははるかに迅速になります。データが準備できたら、Jupyter Notebookを使用してモデルをファインチューニングすることができます。AutoTrainは、text列のデータのみを読み取るため、データに「text」列が含まれていることを確認してください。
まず、次のコマンドを使用してAutoTrainのセットアップを実行しましょう。
!autotrain setup
次に、AutoTrainが実行するのに必要な情報を提供します。次の情報はプロジェクト名と希望する事前学習モデルに関するものです。HuggingFaceで利用可能なモデルのみを選択することができます。
project_name = 'my_autotrain_llm'
model_name = 'tiiuae/falcon-7b'
次に、モデルをリポジトリにプッシュするか、プライベートモデルを使用する場合はHF情報を追加します。
push_to_hub = False
hf_token = "YOUR HF TOKEN"
repo_id = "username/repo_name"
最後に、以下の変数にモデルパラメータ情報を初期化します。結果が良いかどうかを確認するために、必要に応じて変更することができます。
learning_rate = 2e-4
num_epochs = 4
batch_size = 1
block_size = 1024
trainer = "sft"
warmup_ratio = 0.1
weight_decay = 0.01
gradient_accumulation = 4
use_fp16 = True
use_peft = True
use_int4 = True
lora_r = 16
lora_alpha = 32
lora_dropout = 0.045
必要な情報がすべて揃ったら、以前に設定したすべての情報を受け入れるように環境を設定します。
import os
os.environ["PROJECT_NAME"] = project_name
os.environ["MODEL_NAME"] = model_name
os.environ["PUSH_TO_HUB"] = str(push_to_hub)
os.environ["HF_TOKEN"] = hf_token
os.environ["REPO_ID"] = repo_id
os.environ["LEARNING_RATE"] = str(learning_rate)
os.environ["NUM_EPOCHS"] = str(num_epochs)
os.environ["BATCH_SIZE"] = str(batch_size)
os.environ["BLOCK_SIZE"] = str(block_size)
os.environ["WARMUP_RATIO"] = str(warmup_ratio)
os.environ["WEIGHT_DECAY"] = str(weight_decay)
os.environ["GRADIENT_ACCUMULATION"] = str(gradient_accumulation)
os.environ["USE_FP16"] = str(use_fp16)
os.environ["USE_PEFT"] = str(use_peft)
os.environ["USE_INT4"] = str(use_int4)
os.environ["LORA_R"] = str(lora_r)
os.environ["LORA_ALPHA"] = str(lora_alpha)
os.environ["LORA_DROPOUT"] = str(lora_dropout)
ノートブックでAutoTrainを実行するために、次のコマンドを使用します。
!autotrain llm \--train \--model ${MODEL_NAME} \--project-name ${PROJECT_NAME} \--data-path data/ \--text-column text \--lr ${LEARNING_RATE} \--batch-size ${BATCH_SIZE} \--epochs ${NUM_EPOCHS} \--block-size ${BLOCK_SIZE} \--warmup-ratio ${WARMUP_RATIO} \--lora-r ${LORA_R} \--lora-alpha ${LORA_ALPHA} \--lora-dropout ${LORA_DROPOUT} \--weight-decay ${WEIGHT_DECAY} \--gradient-accumulation ${GRADIENT_ACCUMULATION} \$( [[ "$USE_FP16" == "True" ]] && echo "--fp16" ) \$( [[ "$USE_PEFT" == "True" ]] && echo "--use-peft" ) \$( [[ "$USE_INT4" == "True" ]] && echo "--use-int4" ) \$( [[ "$PUSH_TO_HUB" == "True" ]] && echo "--push-to-hub --token ${HF_TOKEN} --repo-id ${REPO_ID}" )
AutoTrainが正常に実行された場合、ディレクトリに以下のフォルダがあり、AutoTrainによって生成されたすべてのモデルとトークナイザが含まれているはずです。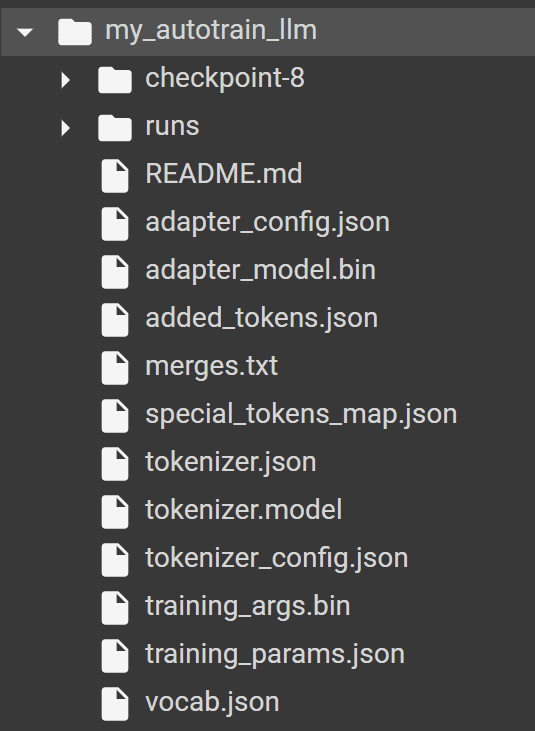
モデルをテストするために、次のコードでHuggingFace transformersパッケージを使用します。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "my_autotrain_llm"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path)
次に、トレーニング入力に基づいてモデルを評価してみましょう。例えば、入力として「定期的な運動の健康上の利点」を使用します。
input_text = "Health benefits of regular exercise"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
output = model.generate(input_ids)
predicted_text = tokenizer.decode(output[0], skip_special_tokens=False)
print(predicted_text)

結果は確かにまだ改善の余地がありますが、少なくとも私たちが提供したサンプルデータに近づいています。事前学習モデルとパラメータを調整して微調整を改善することができます。
成功する微調整のためのヒント
微調整プロセスを改善するために知っておきたいいくつかのベストプラクティスがあります。以下に示すようなものです:
- 代表的なタスクにマッチする品質のデータセットを準備すること、
- 使用した事前学習モデルを研究すること、
- オーバーフィッティングを避けるために適切な正則化技術を使用すること、
- 学習率を小さく始めて徐々に大きくしてみること、
- LLMは通常新しいデータを非常に速く学習するため、訓練には少ないエポックを使用すること、
- データ、パラメータ、モデルが大きくなるにつれて計算コストが高くなるため、計算コストを無視しないこと、
- 使用するデータに関する倫理的な考慮事項を確保すること。
結論
大規模言語モデルの微調整は、特定の要件が必要な場合にはビジネスプロセスにとって有益です。HuggingFace AutoTrainを使用することで、トレーニングプロセスを高速化し、利用可能な事前学習モデルを簡単に微調整することができます。
[Cornellius Yudha Wijaya](https://www.linkedin.com/in/cornellius-yudha-wijaya/)氏は、データサイエンスアシスタントマネージャーであり、データライターです。Allianz Indonesiaでフルタイムで働きながら、ソーシャルメディアや執筆メディアを通じてPythonとデータのヒントを共有することが大好きです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






