「ゲート付き再帰型ユニット(GRU)の詳細な解説:RNNの数学的背後理論の理解」
GRUの詳細な解説:RNNの理論の理解
ゲート付き再帰ユニット(GRU)は、長期記憶(LSTM)の簡略版です。この記事では、それがどのように機能するかを見ていきましょう。
この記事では、ゲート付き再帰ユニット(GRU)の動作について説明します。GRUは、長期記憶(LSTM)の事前知識があると簡単に理解できるため、事前にLSTMについて学ぶことを強くお勧めします。LSTMに関する私の記事をご覧ください。
バニラRNNからLSTMへの実践的なガイド | Shivamshinde著 | 2023年1月 | VoAGI
ゲート付き再帰ユニット(GRU)は、長期記憶(LSTM)ユニットの簡略版です。どちらも再帰ニューラルネットワークにおいて有用な情報を長く保持するために使用されます。どちらも同じくらい優れていますが、使用ケースによってパフォーマンスが異なります。ある使用ケースでは、LSTMの方がより良い結果を出し、別の使用ケースではGRUの方がより良い結果を出すことがあります。実際のモデルトレーニングには、パフォーマンスが高い方を使用する必要があります。
ただし、ネットワークでGRUを使用するといくつかの利点があります。
- この記事で見るように、GRUには2つのゲートがあり、トレーニングがより速くなります。これはメモリと処理能力が少ない場合に役立ちます。
- また、小規模なデータセットで優れた結果を提供します。
それでは、GRUの動作について理解しましょう。
以下の図のシンボルの意味に注意してください:

以下の方程式中の変数の意味
Wxz、Wxr、Wxgは、入力ベクトルx(t)との接続のための3つのゲートの重み行列です。
Whz、Whr、Whgは、直前の状態h(t-1)との接続のための3つのゲートの重み行列です。
bz、br、bgは、3つのゲートのバイアス項です。
GRUに関する基本情報
高レベルでは、GRUは入力と出力の数が同じ単純なRNNユニットの改良版と考えることができます。ただし、GRUの内部構造は若干異なります。
LSTMとは異なり、GRUには1つの状態ベクトルしかありません。GRUの場合、長期および短期ベクトルは1つに組み合わされます。
GRUは3つのブロックで構成されています。それらは次のとおりです。
- 基本RNNブロック、g(t)
- 無駄な情報を忘れ、新しい重要な情報を覚える役割を果たすゲート、z(t)
- 前の状態のどの部分を入力として使用するかを決定するゲート、r(t)
GRUは2つの入力を受け取ります。それらは次のとおりです。
- 前のセルの状態、h(t-1)
- トレーニングデータの入力、x(t)
GRUセルは2つの項を出力します。それらは次のとおりです。
- 現在のセルの状態、h(t)
- 現在のセルの予測、y(t)
それでは、各出力が入力を使用して計算される方法を理解しましょう。
現在のセルの状態の計算
基本的に、セルの状態は2つの量の加算によって求められます。第1の量は、前の状態からどれだけ忘れるかを示します。そして、第2の量は、トレーニングデータの入力からどれだけ覚えるかを示します。
まずは、第1の量について理解しましょう。
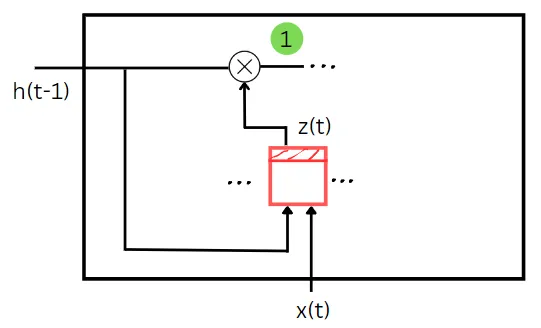
上記の図でわかるように、z(t)は前の状態とトレーニングデータを入力として受け取ります。これは、忘却ゲートのような役割を果たしています。z(t)ゲートの値は、この時間ステップで前の状態のどの部分を忘れるかを決定します。前の状態とトレーニング入力は、それぞれの重みとバイアスとの積を取り、その合計にバイアスを加えたものです。この合計にシグモイド関数を適用すると、z(t)の値が得られます。前の状態とz(t)の値の要素ごとの積は、現在の時間ステップの状態を計算するために必要な最初の量を与えます。最初の量は、上記の図で緑色で表示されています。
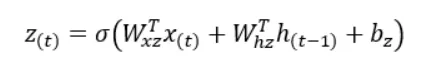
2番目の量を理解しましょう。
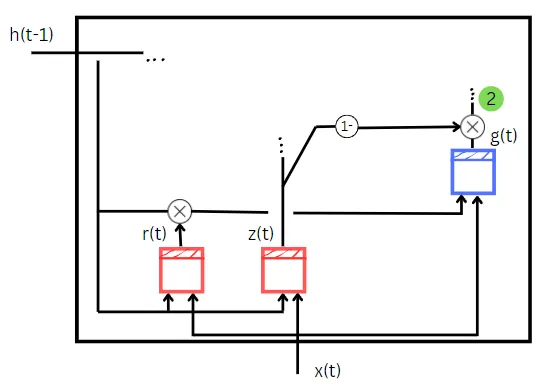
z(t)の値は、最初の量の計算で説明したように計算されます。しかし、ここでは(1-z(t))が入力ゲートとして機能します。基本的なRNNセルg(t)は2つの入力を受け取ります。
- トレーニングデータの入力、x(t)
- r(t)と前の状態h(t-1)の要素ごとの積
r(t)の計算方法は、z(t)と同じですが、計算に使用される重みとバイアスが異なります。r(t)の値は、単純なRNNセルg(t)に入力として与える前の状態のどの部分を与えるべきかを示します。
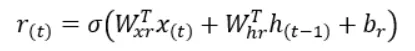
g(t)の両方の入力は、それぞれの重みと乗算され、その合計にバイアス項が加えられます。その後、この最終的な合計値はハイパボリックタンジェント関数に渡され、g(t)の値を得ます。
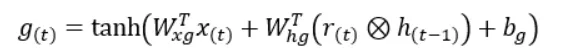
今度は、g(t)と(1-z(t))、または入力ゲートの要素ごとの積が、現在の時間ステップの状態を計算するために必要な2番目の量を与えます。2番目の量は、上記の図で緑色で表示されています。
これで、両方の量を見つけたので、それらを合計することで現在の時間ステップの状態が得られます。
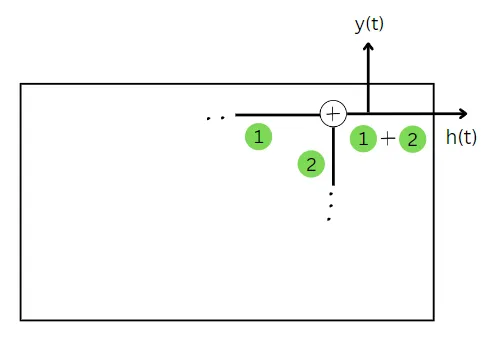
GRUセルでは、現在の状態の値は予測と同じです。したがって、現在の状態を既に計算しているため、現在の時間ステップの予測も計算されています。

これまでに、GRUの全体を理解するために必要なさまざまな部分を見てきました。では、今まで見てきた部分をすべて組み合わせましょう。
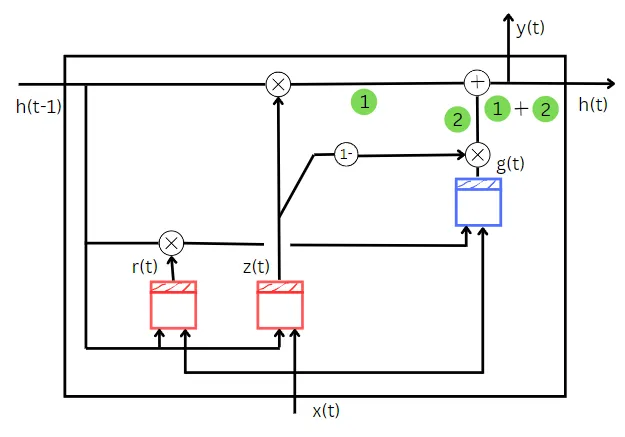
これがGRUネットワーク全体のダイアグラムです。
この記事がお気に召したでしょうか。記事中の図は手書きで描かれました。GRUを理解するために直感的でわかりやすい(そして散らかりすぎていない)と思います。記事についてのご意見があれば、ぜひお知らせください。また、記事がお気に入りの場合は、拍手をお願いします。
私とつながるには
ウェブサイト
[email protected]までメールしてください
素晴らしい一日を!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






