GraphStormによる高速グラフ機械学習:企業規模のグラフ問題を解決するための新しい方法
GraphStorm A new method for solving large-scale graph problems in companies through fast graph machine learning.
私たちは、GraphStorm 0.1のオープンソースリリースを発表して、エンタープライズスケールのグラフデータを利用したグラフ機械学習(ML)ソリューションをビルド、トレーニング、展開するための、低コードのフレームワークを提供します。GraphStormを使用すると、詐欺検出シナリオ、レコメンデーション、コミュニティ検出、検索/検索問題など、現実世界のデータに固有の関係や相互作用の構造を直接考慮したソリューションを構築できます。これらの構造は、億を超えるエンティティ間の関係や相互作用に内在するものであり、Amazon.comの製品、製品属性、顧客などをキャプチャするグラフを思い浮かべてみてください。
今まで、数十億のノード、数百億のエッジ、数十の属性を持つ複雑なエンタープライズグラフのためのグラフMLソリューションを構築、トレーニング、展開することは非常に困難でした。ただ、Amazonが内部で使用している大規模なグラフMLソリューションを本番環境に導入するために必要なツールをGraphStormでリリースすることにより、この問題を解決しました。GraphStormはグラフMLの専門知識がなくても使用できます。また、Apache v2.0ライセンスでGitHub上で利用可能です。GraphStormについて詳しく知るには、GitHubリポジトリをご覧ください。
この記事では、GraphStormの概要、アーキテクチャ、使用方法の例を紹介します。
GraphStormの紹介
グラフアルゴリズムとグラフMLは、トランザクションリスクの予測、顧客の嗜好の予測、侵入の検出、サプライチェーンの最適化、ソーシャルネットワーク分析、交通予測など、多くの重要なビジネス問題に対する最新技術ソリューションとして注目されています。たとえば、ネイティブAWS脅威検出サービスであるAmazon GuardDutyは、数十億のエッジを持つグラフを使用して、脅威情報のカバレッジと正確性を向上させています。これにより、GuardDutyは以前に見たことのないドメインを既知の悪意のあるドメインに関連付けて、高度に悪意のあるものかどうかを判断できます。Graph Neural Network(GNN)を使用することで、GuardDutyは顧客にアラートを通知する能力を強化することができます。
しかし、グラフMLソリューションを開発、展開、運用することは数か月かかり、グラフMLの専門知識が必要です。最初に、グラフMLの専門家は、Deep Graph Library(DGL)のようなフレームワークを使用して、特定のユースケースに対するグラフMLモデルを構築する必要があります。トレーニングは、エンタープライズアプリケーションのグラフのサイズと複雑さのために課題があります。これらのアプリケーションは、数十億のノード、数百億のエッジ、異なるノードとエッジのタイプ、および数百のノードとエッジ属性を持つことがほとんどです。エンタープライズグラフはテラバイトのメモリストレージを必要とし、グラフMLの専門家は複雑なトレーニングパイプラインを構築する必要があります。最後に、モデルがトレーニングされた後、推論のためにデプロイする必要があります。これには、トレーニングパイプラインと同じくらい難しい推論パイプラインが必要です。
GraphStorm 0.1は、低コードのエンタープライズグラフMLフレームワークであり、MLの専門家が証明済みの事前定義済みのグラフMLモデルを簡単に選択し、数十億のノードを持つグラフ上で分散トレーニングを実行し、モデルを本番環境に展開できるようにすることができます。GraphStormは、異種グラフのエンタープライズアプリケーションのためのRelational Graph Convolutional Networks(RGCN)、Relational Graph Attention Networks(RGAT)、Heterogeneous Graph Transformer(HGT)などの組み込みグラフMLモデルのコレクションを提供し、グラフMLの専門知識がなくても異なるモデルソリューションを素早く試して選択できます。分散トレーニングと推論パイプラインは、数十億のエンタープライズグラフにスケーリングするためのものであり、トレーニング、展開、推論を簡単に行うことができます。GraphStormは、GNNモデルを開発するために広く利用されているDeep Graph Library(DGL)の上に構築され、Apache v2.0ライセンスのオープンソースコードとして提供されています。
Amazon AI/ML研究のシニアプリンシパルサイエンティストであるGeorge Karypis氏は、「GraphStormは、エンタープライズアプリケーションのためのグラフMLメソッドを実験し、オペレーショナル化することを目的として設計されています。GraphStormがリリースされて以来、グラフMLベースのソリューションの構築作業が最大5倍短縮されました。」と語っています。
Amazon Measurement、Ad Tech、Data ScienceのプリンシパルアプライドサイエンティストであるHaining Yu氏は、「GraphStormを使用することで、2億のエッジを持つグラフ上でGNN埋め込みを自己監視的にトレーニングすることができます。事前にトレーニングされたGNN埋め込みは、最新のBERTをベースとしたベースラインに比べて、ショッパー活動予測タスクで24%の改善を示し、他の広告アプリケーションでもベンチマークのパフォーマンスを上回っています。」と語っています。
Amazon NeptuneおよびAmazon TimestreamのGMであるBrad Bebee氏は、「GraphStormがなかった場合、顧客は500万エッジのグラフに対応するために垂直方向にスケールするしかありませんでした。GraphStormを使用することで、数十億のエッジを持つAmazon Neptuneグラフ上のGNNモデルトレーニングをスケーリングすることができます。」と語っています。
GraphStormの技術アーキテクチャ
以下の図は、GraphStormの技術アーキテクチャを示しています。

GraphStormはPyTorchの上に構築されており、単一のGPU、複数のGPU、および複数のGPUマシンで実行できます。以下の図で黄色い箱でマークされた3つのレイヤーで構成されています。
- ボトムレイヤー(Dist GraphEngine) – ボトムレイヤーは、分散グラフMLを可能にするための基本的なコンポーネント、分散グラフ、分散テンソル、分散埋め込み、および分散サンプラーを提供します。GraphStormはこれらのコンポーネントの効率的な実装を提供し、10億ノードグラフのグラフMLトレーニングをスケールアップします。
- ミドルレイヤー(GSトレーニング/推論パイプライン) – ミドルレイヤーは、ビルトインモデルとカスタムモデルの両方のモデルトレーニングと推論を簡素化するトレーナー、評価者、および予測子を提供します。このレイヤーのAPIを使用することで、モデルトレーニングのスケーリングについて心配することなく、モデル開発に集中できます。
- トップレイヤー(GS一般モデル動物園) – トップレイヤーは、異種グラフに対するRGCN、RGAT、およびHGT、テキストグラフに対するBERTGNNを含む、人気のあるGNNおよび非GNNモデルのモデル動物園です。この時点では、時間的グラフモデル(時間的グラフのTGAT)および知識グラフのTransEおよびDistMultのサポートを追加する予定です。
GraphStormの使用方法
GraphStormをインストールした後、アプリケーションのためのGMLモデルを構築およびトレーニングするには、3つのステップしか必要ありません。
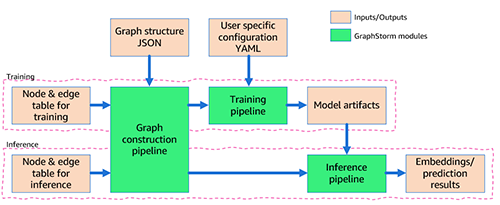
まず、データを前処理(カスタムフィーチャーエンジニアリングを含む場合があります)し、GraphStormに必要なテーブル形式に変換します。ノードタイプごとに、そのタイプのすべてのノードとそのフィーチャーをリストアップしたテーブルを定義し、各ノードに固有のIDを提供します。同様に、各エッジタイプについても、そのタイプのエッジのソースと宛先のノードIDが含まれるテーブルを定義します(詳細については、「自分自身のデータチュートリアルを使用する」を参照してください)。また、全体のグラフ構造を説明するJSONファイルを提供します。
次に、コマンドラインインターフェイス(CLI)を介して、GraphStormのビルトインconstruct_graphコンポーネントを使用して、GraphStorm固有のデータ処理を行います。これにより、効率的な分散トレーニングと推論が可能になります。
3つ目に、YAMLファイル(例)でモデルとトレーニングを構成し、再びCLIを使用して、5つのビルトインコンポーネント(gs_node_classification、gs_node_regression、gs_edge_classification、gs_edge_regression、gs_link_prediction)の1つをトレーニングパイプラインとして呼び出してモデルをトレーニングします。このステップにより、トレーニングされたモデルアーティファクトが生成されます。推論を行うには、同じGraphStormコンポーネント(construct_graph)を使用して、推論データをグラフに変換するために、最初の2つのステップを繰り返す必要があります。
最後に、モデルトレーニングに使用されたものと同じ5つのビルトインコンポーネントの1つを呼び出して、埋め込みまたは予測結果を生成する推論パイプラインを呼び出すことができます。
全体のフローは、以下の図にも示されています。
次のセクションでは、使用例を示します。
生のOAGデータで予測を行う
この記事では、GraphStormが大規模な生データセットでグラフMLトレーニングと推論を簡単に実現できることをデモンストレーションします。Open Academic Graph(OAG)には、論文、著者、会場、所属先、および研究分野の5つのエンティティが含まれています。生データセットは、500GB以上のJSONファイルに格納されています。
私たちのタスクは、論文の研究分野を予測するモデルを構築することです。研究分野を予測するには、マルチラベル分類タスクとして定式化できますが、ラベルをワンホットエンコーディングで格納することは難しいため、研究分野ノードを作成し、この問題をリンク予測タスクとして定式化し、論文ノードが接続するべき研究分野ノードを予測する必要があります。
グラフ法を用いてこのデータセットをモデル化するには、最初にデータセットを処理し、エンティティとエッジを抽出する必要があります。JSONファイルからグラフを定義するために5種類のエッジを抽出でき、以下の図に示されています。GraphStormの例題コードのJupyterノートブックを使用して、データセットを処理し、各エンティティタイプに対して5つのエンティティテーブルと各エッジタイプに対して5つのエッジテーブルを生成できます。Jupyterノートブックは、論文などのテキストデータを持つエンティティに対してBERT埋め込みを生成します。

エンティティとエンティティ間のエッジを定義した後、mag_bert.jsonを作成してグラフスキーマを定義し、GraphStormの組み込みグラフ構築パイプラインconstruct_graphを呼び出してグラフを構築できます(以下のコードを参照)。GraphStormのグラフ構築パイプラインは単一のマシンで実行されますが、ノードとエッジの特徴を並列で処理するためのマルチプロセッシング(--num_processes)をサポートし、エンティティとエッジの特徴を外部メモリ(--ext-mem-workspace)に保存して大規模なデータセットにスケーリングできます。
python3 -m graphstorm.gconstruct.construct_graph \
--num-processes 16 \
--output-dir /data/oagv2.1/mag_bert_constructed \
--graph-name mag --num-partitions 4 \
--skip-nonexist-edges \
--ext-mem-workspace /mnt/raid0/tmp_oag \
--ext-mem-feat-size 16 --conf-file mag_bert.jsonこのような大規模なグラフを処理するには、グラフを構築するための大容量メモリCPUインスタンスが必要です。Amazon Elastic Compute Cloud(Amazon EC2)r6id.32xlargeインスタンス(128 vCPUと1 TB RAM)またはr6a.48xlargeインスタンス(192 vCPUと1.5 TB RAM)を使用してOAGグラフを構築できます。
グラフを構築した後、gs_link_predictionを使用して4つのg5.48xlargeインスタンスでリンク予測モデルをトレーニングできます。組み込みモデルを使用する場合、分散トレーニングジョブを起動するために1つのコマンドラインを呼び出すだけで済みます。次のコードを参照してください。
python3 -m graphstorm.run.gs_link_prediction \
--num-trainers 8 \
--part-config /data/oagv2.1/mag_bert_constructed/mag.json \
--ip-config ip_list.txt \
--cf ml_lp.yaml \
--num-epochs 1 \
--save-model-path /data/mag_lp_modelモデルトレーニング後、モデルアーティファクトはフォルダ/data/mag_lp_modelに保存されます。
これで、リンク予測推論を実行してGNN埋め込みを生成し、モデルのパフォーマンスを評価できます。 GraphStormは、モデルパフォーマンスを評価するための複数の組み込み評価メトリックを提供します。たとえば、リンク予測問題の場合、GraphStormは自動的に平均相互順位(MRR)というメトリックを出力します。MRRは、予測されたリンクの中で実際のリンクがどの程度上位にランク付けされたかを評価するための貴重なメトリックです。これは、予測の品質を捉え、真の接続を正しく優先することを確認するため、私たちの目的を達成するために重要です。
次のコードに示すように、1つのコマンドラインで推論を実行できます。この場合、モデルは構築されたグラフのテストセットでMRR 0.31に達します。
python3 -m graphstorm.run.gs_link_prediction \
--inference --num_trainers 8 \
--part-config /data/oagv2.1/mag_bert_constructed/mag.json \
--ip-config ip_list.txt \
--cf ml_lp.yaml \
--num-epochs 3 \
--save-embed-path /data/mag_lp_model/emb \
--restore-model-path /data/mag_lp_model/epoch-0/推論パイプラインは、リンク予測モデルから埋め込みを生成します。任意の論文の研究分野を見つける問題を解決するには、埋め込みに対してk最近傍探索を実行するだけです。
結論
GraphStormは、業界グラフ上でグラフMLモデルを構築、トレーニング、デプロイすることが容易になる新しいグラフMLフレームワークです。拡張性と使いやすさを含むグラフMLのいくつかの主要な課題に対処します。生の入力データからモデルトレーニングとモデル推論までの10億スケールのグラフを処理するための組み込みコンポーネントを提供し、複数のAmazonチームが様々なアプリケーションで最先端のグラフMLモデルをトレーニングできるようにしました。詳細については、GitHubリポジトリをご覧ください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





