勾配消失問題:原因、結果、および解決策
Gradient Vanishing Problem Causes, Consequences, and Solutions.
シグモイド関数は、深層ニューラルネットワークの開発に使用される最も人気のある活性化関数の1つです。シグモイド関数の使用により、勾配消失問題が発生し、深層ニューラルネットワークのトレーニングが制限されました。これにより、ニューラルネットワークが遅いペースで学習するか、あるいは全く学習しない場合があります。このブログ投稿では、勾配消失問題を説明し、シグモイド関数の使用がそれにつながった理由を説明します。
シグモイド関数
シグモイド関数は、ニューラルネットワークで頻繁に使用されるニューロンを活性化するための関数です。特徴的なS字形状を持つ対数関数です。関数の出力値は0から1の間です。シグモイド関数は、2値分類問題での出力層の活性化に使用されます。以下のように計算されます。
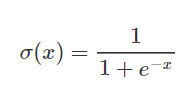
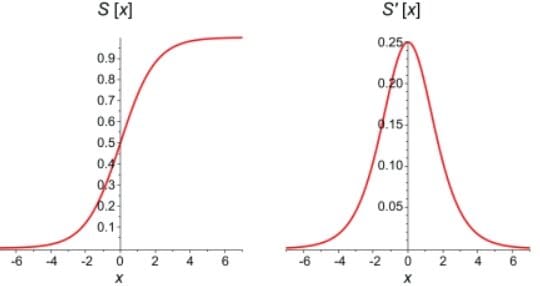
下のグラフでは、シグモイド関数自体とその導関数の比較が示されています。シグモイド関数の1次導関数は、0から0.25の値を持つベル曲線です。
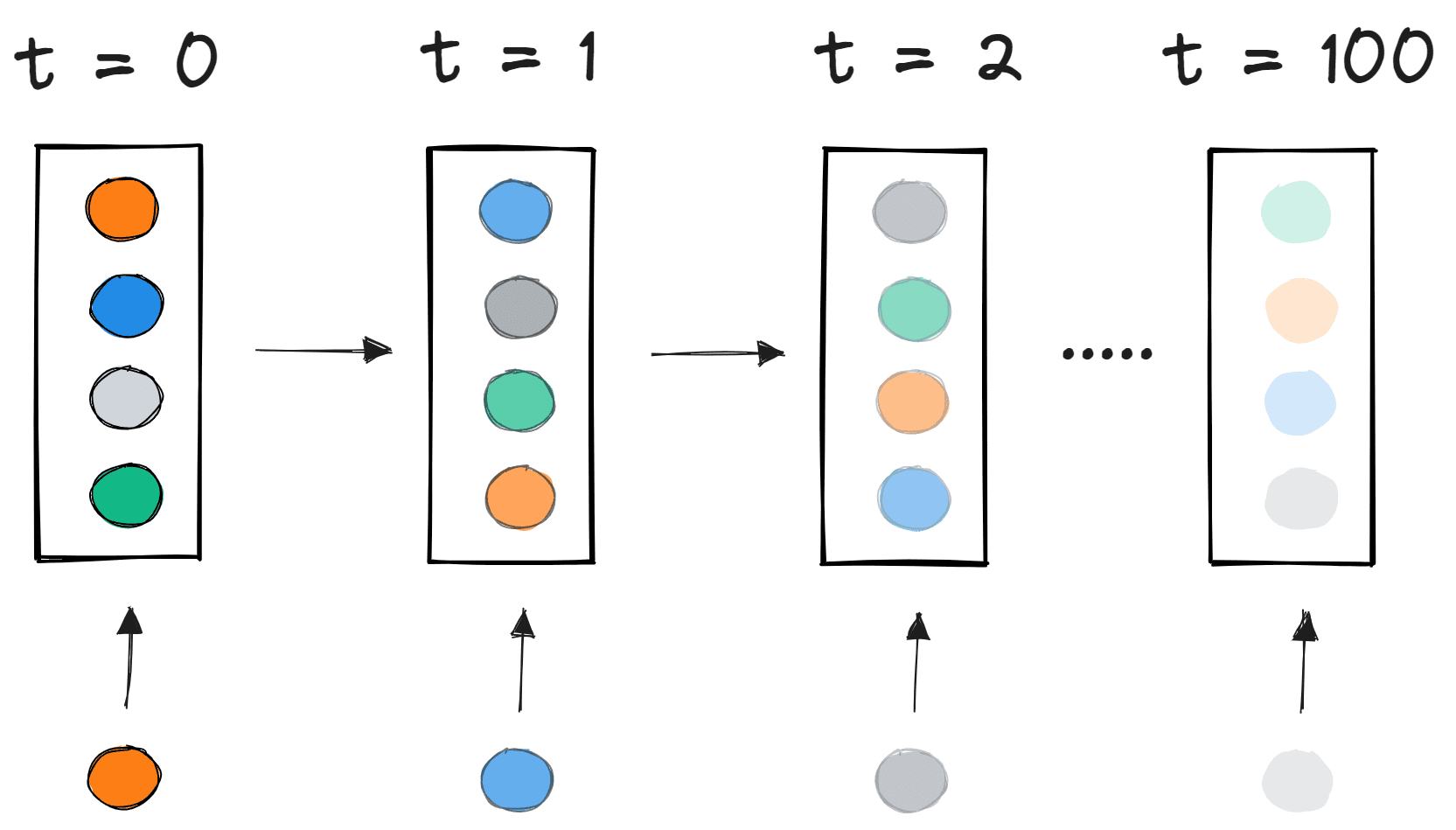
ニューラルネットワークが順方向および逆方向伝播を行う方法についての知識は、勾配消失問題を理解するために不可欠です。
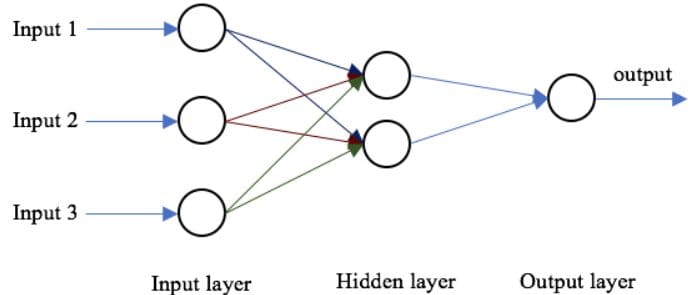
順方向伝播
ニューラルネットワークの基本構造は、入力層、1つ以上の隠れ層、および単一の出力層です。ネットワークの重みは順方向伝播中にランダムに初期化されます。入力特徴量は、隠れ層の各ノードの対応する重みによって乗算され、各ノードのネット和にバイアスが加えられます。この値は、活性化関数を使用してノードの出力に変換されます。ニューラルネットワークの出力を生成するために、隠れ層の出力は重みおよびバイアス値で乗算され、合計は別の活性化関数を使用して変換されます。これが、与えられた入力値に対するニューラルネットワークの予測値になります。
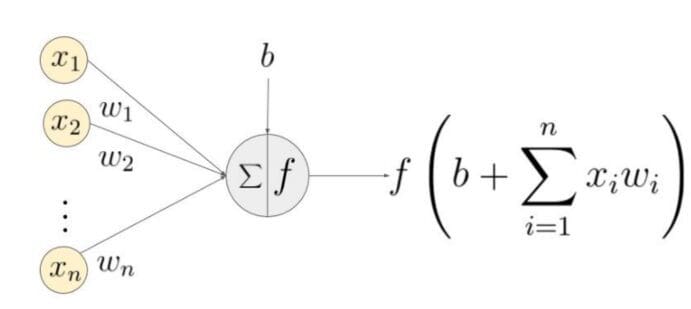
逆伝播
ネットワークが出力を生成すると、損失関数(C)は出力の予測精度を示します。ネットワークは損失を最小化するために逆伝播を実行します。逆伝播法は、ニューラルネットワークの重みとバイアスを調整して損失関数を最小化します。この方法では、損失関数の勾配がネットワーク内の各重みに関して計算されます。
逆伝播では、ノードの新しい重み(w new )は、古い重み(w old )と学習率(ƞ)と損失関数の勾配の積を使用して計算されます。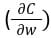
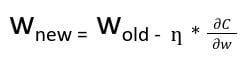
偏微分のチェーンルールを使用することで、各ノードの活性化関数の勾配の積を使用して、損失関数の勾配を表すことができます。したがって、ネットワーク内のノードの更新された重みは、各ノードの活性化関数の勾配に依存します。
シグモイド活性化関数を持つノードについては、シグモイド関数の偏微分の部分は最大値0.25に達することがわかっています。ネットワークに層が増えると、導関数の積の値が減少し、ある時点で損失関数の偏微分が0に近い値になり、偏微分が消失します。これが勾配消失問題と呼ばれます。
浅いネットワークの場合、シグモイド関数を使用することができます。勾配の小さな値が問題にならないためです。深いネットワークの場合、勾配消失は性能に大きな影響を与える可能性があります。勾配が消失するため、ネットワークの重みは変更されません。逆伝播中、ニューラルネットワークは、損失関数を減らすために重みとバイアスを更新して学習します。勾配消失のあるネットワークでは、重みを更新できないため、ネットワークは学習できません。その結果、ネットワークの性能が低下します。
問題を克服する方法
勾配消失問題は、ニューラルネットワークを作成するために使用される活性化関数の導関数によって引き起こされます。問題の最も簡単な解決策は、ネットワークの活性化関数を置き換えることです。シグモイドではなく、ReLUなどの活性化関数を使用します。
Rectified Linear Units (ReLU)は、正の入力値に適用されると正の線形出力を生成する活性化関数です。入力が負の場合、関数はゼロを返します。
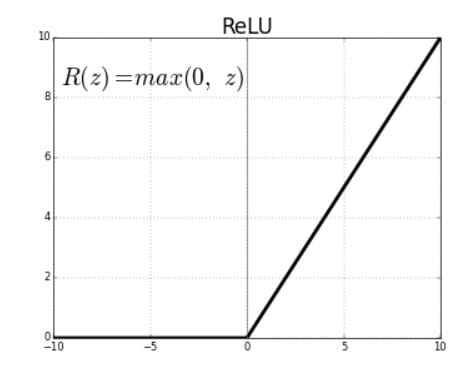
ReLU関数の導関数は、0より大きい入力に対しては1と定義され、負の入力に対しては0となります。下記のグラフはReLU関数の導関数を示しています。
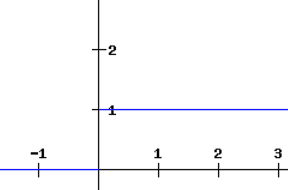
ニューラルネットワークでシグモイド関数の代わりにReLU関数を使用する場合、損失関数の偏微分の値は0または1になり、勾配が消失するのを防ぎます。したがって、ReLU関数の使用により、勾配が消失するのを防ぎます。ただし、ReLUの使用には問題があります。勾配が0の値を持つ場合、古い値と新しい値の重みが同じままであるため、ノードは「デッドノード」と見なされます。この状況は、勾配がゼロ値に落ちるのを防ぐリーキーReLU関数を使用することによって回避できます。
勾配消失問題を回避する別のテクニックは、重みの初期値を割り当てる重みの初期化です。これにより、バックプロパゲーション中に重みが消失しないようになります。
結論として、勾配消失問題は、ニューラルネットワークを作成するために使用される活性化関数の偏微分の性質から生じます。 Sigmoid活性化関数を使用するディープニューラルネットワークでは、問題が悪化する可能性があります。 ReLUやリーキーReLUなどの活性化関数を使用することで、問題を大幅に軽減できます。
Tina Jacobは、データサイエンスに情熱を持ち、人生は学び続けることであり、何が起ころうとも成長することだと信じています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ChatGPT(無料の言語チューター)で素早く言語を学びましょう
- 自然言語処理における転移学習:テキスト分類のための事前学習済みモデルの活用
- govGPT チャットボットによる市民体験の向上
- NLPとAIを利用したPythonにおけるテンプレートベースの文書生成の力
- Amazon Textract による強化されたテーブル抽出の発表
- DeepSpeedを使用してPyTorchを加速し、Intel Habana GaudiベースのDL1 EC2インスタンスを使用して大規模言語モデルをトレーニングします
- Amazon PersonalizeにおけるSimilar-Itemsの人気チューニングを紹介します