「勾配降下法:数学を用いた最適化への山岳トレッカーのガイド」
「勾配降下法:数学を活用した最適化を目指す山岳トレッカーのガイドブック」
山岳トレッカーのアナロジー:
想像してください、広大な山岳地帯の斜面のどこかに立っている山岳トレッカーです。あなたの目標は、谷の最も低い地点にたどり着くことですが、注意が必要です:あなたは目隠しをしています。全体の景色を見る能力がない状況では、どのようにして谷底にたどり着くことができるでしょうか?
本能的に、あなたは足で周りの地面を感じ、下りの方向を感じ取るでしょう。そして、最も急な下りの方向に一歩進むでしょう。このプロセスを繰り返し、徐々に谷の最も低い地点に近づいていくのです。
- M42がMed42を導入:医療知識へのアクセス拡大のためのオープンアクセスクリニカル大規模言語モデル(LLM)
- 「Amazon Rekognition Custom LabelsとAWS Step Functionsを使用して、PurinaのPetfinderアプリケーションのペットプロファイルを最適化する」
- 「大規模言語モデルにおける早期割れに打ち勝てるか?Google AIがパフォーマンス向上のためにバッチキャリブレーションを提案」
このアナロジーを勾配降下法に当てはめる
機械学習の世界では、このトレッカーの旅は勾配降下法アルゴリズムに似ています。具体的には以下のようになります:
1) 地形: 山地の地形は、コスト(または損失)関数であるJ(θ)を表しています。
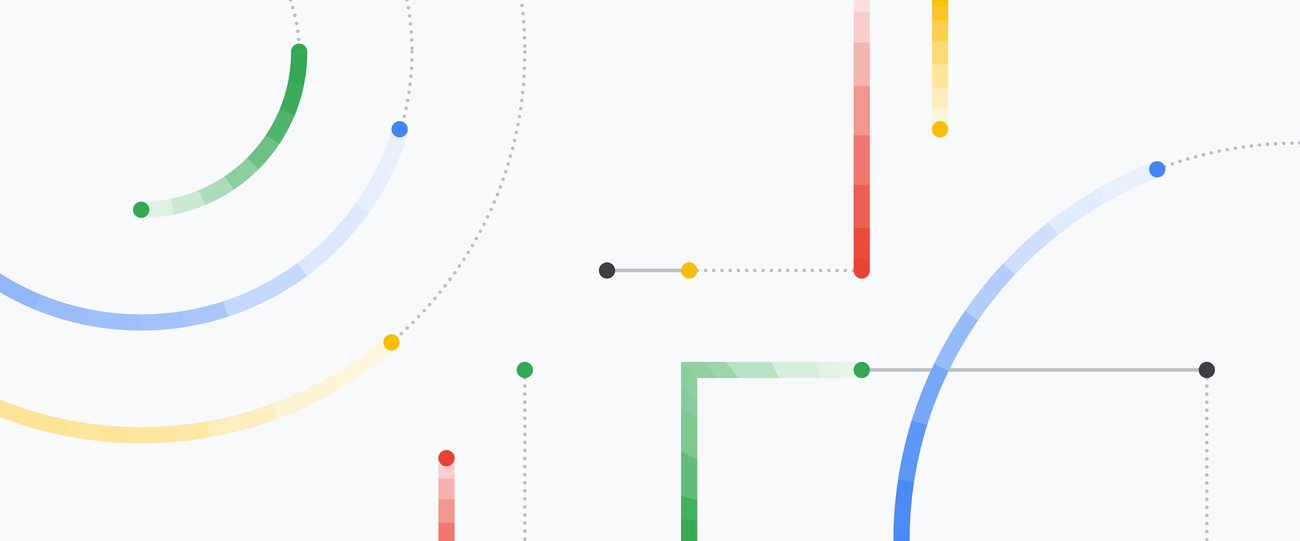
この関数は、モデルの予測と実際のデータとの誤差または不一致を測定します。数学的には以下のように表すことができます: 。ここで、
。ここで、
mはデータポイントの数であり、hθ(x)はモデルの予測、yは実際の値です。
2) トレッカーの位置: 山での現在の位置は、モデルのパラメータθの現在値に対応します。移動するとこれらの値が変化し、モデルの予測も変わります。
3) 地面を感じる: まるであなたが足で最も急な下りを感じ取るのと同様に、勾配降下では勾配∇J(θ)を計算します。この勾配は、コスト関数における最も急な増加の方向を教えてくれます。コストを最小化するためには、逆方向に移動します。勾配は以下のように表されます: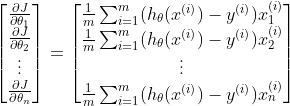 ただし:
ただし:
mは訓練例の数です。
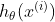
訓練例。
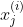
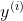
訓練例。
4) ステップ: あなたが踏む歩幅は、勾配降下法における学習率を示すものです。大きな歩幅は速く下降するのに役立ちますが、谷底を通り越してしまう可能性があります。小さな歩幅はより慎重ですが、最小値に到達するまで時間がかかる可能性があります。更新ルールは次のようになります:

5) 底に到達する: この反復的なプロセスは、どの方向にも著しい下降が感じられない地点に到達するまで続きます。勾配降下法では、コスト関数の変化が無視できるほど小さくなったときに、アルゴリズムが(おそらく)最小値を見つけたことを示します。
まとめ
勾配降下法は、盲目のトレッカーが谷底を見つけようとする際の方法論的かつ反復的なプロセスです。直感と数学的な厳密さを組み合わせることで、機械学習モデルが学習し、パラメータを調整し、予測を改善する方法をより良く理解することができます。
バッチ勾配降下法
バッチ勾配降下法は、データセット全体を使用して勾配を計算します。この方法は安定した収束と一貫した誤差勾配を提供しますが、大規模なデータセットでは計算コストが高く、遅くなる可能性があります。
確率的勾配降下法(SGD)
SGDは、単一のランダムに選択されたデータポイントを使用して勾配を推定します。これによってより速くなり、ローカルミニマムからの脱出ができますが、その固有のランダム性により、収束パターンがより乱れ、コスト関数において振動を引き起こす可能性があります。
ミニバッチ勾配降下法
ミニバッチ勾配降下法は、前述の2つのメソッドの間のバランスを取ります。データセットのサブセット(または「ミニバッチ」)を使用して勾配を計算します。この方法は、行列演算の計算上の利点を活用し、バッチ勾配降下法の安定性とSGDの速度の折衷案を提供します。
課題と解決策
局所最小値
勾配降下法は、時に局所最小値に収束することがありますが、それは関数全体の最適解ではありません。特に複数の谷がある複雑な地形では問題が発生します。この問題を克服するために、運動量を取り入れることでアルゴリズムは谷を通過する際に立ち往生せずに進むことができます。さらに、Adamなどの高度な最適化アルゴリズムは、運動量と適応的な学習率の利点を組み合わせて、より堅牢なグローバル最小値への収束を保証します。
消失および爆発勾配
ディープニューラルネットワークでは、勾配がバックプロパゲーションするにつれてほぼゼロになる(消失)か指数関数的に増加する(爆発)ことがあります。消失する勾配はトレーニングを遅くし、ネットワークが学習するのが困難になります。一方、爆発する勾配はモデルが発散する原因となります。これらの問題を緩和するために、勾配クリッピングは勾配が大きすぎるのを防ぐための閾値を設定します。一方、HeまたはXavierのような正規化初期化技術は、重みを適切な値に設定することでこれらの課題のリスクを減らします。
勾配降下法アルゴリズムの例コード
import numpy as npdef gradient_descent(X, y, learning_rate=0.01, num_iterations=1000): m, n = X.shape theta = np.zeros(n) # 重み/パラメータの初期化 cost_history = [] # コスト関数の値をイテレーションごとに格納 for _ in range(num_iterations): predictions = X.dot(theta) errors = predictions - y gradient = (1/m) * X.T.dot(errors) theta -= learning_rate * gradient # 現在のイテレーションのコストを計算して格納 cost = (1/(2*m)) * np.sum(errors**2) cost_history.append(cost) return theta, cost_history# 使用例:# Xはm個のサンプルとn個の特徴量を持つ特徴行列とする# yはm個のサンプルを持つターゲットベクトルとする# 注意: モデルにバイアス項を含める場合は、Xにバイアス項の列(1の列)を追加する必要があります。# サンプルデータX = np.array([[1, 1], [1, 2], [1, 3], [1, 4], [1, 5]])y = np.array([2, 4, 5, 4, 5])theta, cost_history = gradient_descent(X, y)print("最適なパラメータ:", theta)print("コスト履歴:", cost_history)
このコードは、線形回帰に対する基本的な勾配降下法アルゴリズムを提供します。関数gradient_descentは、特徴行列X、ターゲットベクトルy、学習率、イテレーション数を引数に取ります。最適化されたパラメータ(theta)とイテレーションごとのコスト関数の履歴を返します。
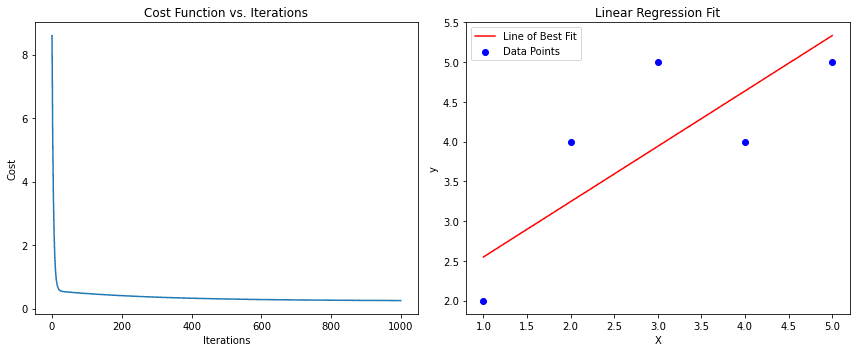
左のサブプロットはイテレーションごとにコスト関数が減少していく様子を示しています。
右のサブプロットは、勾配降下法によって得られたデータポイントと最適なフィットラインを示しています。
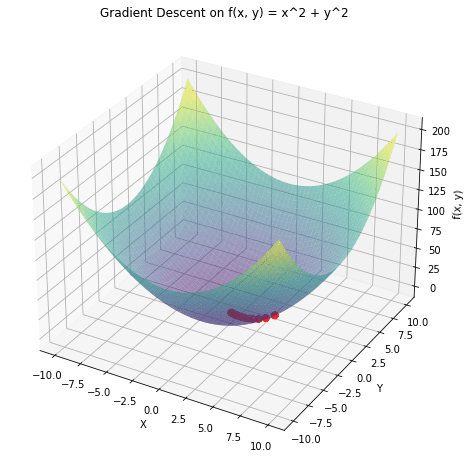
関数 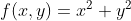 の3Dプロットと、勾配降下法が取ったパスを赤でオーバーレイしたものです。勾配降下法はランダムな点から始まり、関数の最小値に向かって進みます。
の3Dプロットと、勾配降下法が取ったパスを赤でオーバーレイしたものです。勾配降下法はランダムな点から始まり、関数の最小値に向かって進みます。
アプリケーション
株価予測
金融アナリストは、線形回帰などのアルゴリズムとともに勾配降下法を使用して、歴史データに基づいて将来の株価を予測します。予測された株価と実際の株価の誤差を最小化することで、より正確な予測を行うためにモデルを改善することができます。
画像認識
深層学習モデル、特に畳み込みニューラルネットワーク(CNN)は、画像の大規模なデータセットを学習する際に勾配降下法を使用して重みを最適化します。例えば、Facebookのようなプラットフォームでは、顔の特徴を認識することで写真の中の個人を自動的にタグ付けするためにこのようなモデルを使用しています。これらのモデルの最適化により、正確で効率的な顔認識が実現されます。
感情分析
企業は、顧客のフィードバック、レビュー、またはソーシャルメディアの言及を分析するモデルをトレーニングするために勾配降下法を使用します。予測された感情と実際の感情の差を最小化することで、これらのモデルはフィードバックをポジティブ、ネガティブ、またはニュートラルに正確に分類することができます。これにより、ビジネスは顧客の満足度を把握し、戦略を適切に調整することができます。
Arunは経験豊富なシニアデータサイエンティストで、データの力を活用して効果的なビジネスソリューションを実現するために8年以上の経験を持っています。彼は高度な分析、予測モデリング、機械学習を活用して、複雑なデータを実行可能な洞察と戦略的なストーリーに変換することが得意です。有名な機関から得た機械学習と人工知能のPGPを持つArunの専門知識は、技術的および戦略的な領域で幅広いスペクトラムにわたり、データに基づく取り組みにおいて貴重な資産となることでしょう。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「NVIDIAは創造的AIの台頭に対応するため、ロボティクスプラットフォームを拡大する」
- 「AutoGen:次世代の大規模言語モデルアプリケーションの動力源」
- 「大型言語モデル(LLM)のマスターに至る7つのステップ」
- AIテクノロジーを使ってあなたの牛を見守る
- Amazon PersonalizeとAmazon OpenSearch Serviceの統合により、検索結果をパーソナライズします
- 「Amazon PharmacyはAmazon SageMakerを使用して、LLMベースのチャットボットを作成する方法を学びましょう」
- 印象的なパフォーマンス:TensorRT-LLMを使用したRTXで最大4倍高速化された大規模言語モデル(LLM) for Windows