スピードは必要なすべてです:GPU意識の最適化による大規模拡散モデルのオンデバイス加速化
GPU意識の最適化による大規模拡散モデルのオンデバイス加速化 means On-device acceleration of large-scale diffusion models through optimization with GPU awareness. Speed is everything.
コアシステム&エクスペリエンスのソフトウェアエンジニアであるJuhyun LeeとRaman Sarokinによる投稿
画像生成のための大規模な拡散モデルの普及により、モデルサイズと推論ワークロードは大幅に増加しました。モバイル環境でのオンデバイスML推論には、リソース制約のために緻密なパフォーマンス最適化とトレードオフの考慮が必要です。コスト効率とユーザープライバシーの必要性により、大規模拡散モデル(LDM)のオンデバイスでの実行は、これらのモデルの大幅なメモリ要件と計算要件のために更に大きな課題を提供します。
本稿では、私たちの「速さこそがすべて:GPUによる大規模拡散モデルのオンデバイスアクセラレーションによる最適化」に焦点を当て、モバイルGPU上の基本的なLDMモデルの最適化された実行について述べます。このブログ記事では、Stable Diffusionなどの大規模拡散モデルを高速で実行するために使用した主なテクニックをまとめ、512×512ピクセルのフル解像度で20回イテレーションを行い、蒸留なしでオリジナルモデルの高性能推論速度で12秒未満で実行できるようにしました。前回のブログ記事で述べたように、GPUアクセラレーションされたML推論は、メモリのパフォーマンスに制限されることがよくあります。そして、LDMの実行も例外ではありません。したがって、私たちの最適化の中心テーマは、演算論理ユニットの効率性を優先するものよりも、メモリの入出力(I/O)の効率性であり、ML推論の全体的なレイテンシを減らすことです。
 |
| LDMのサンプル出力。プロンプトテキスト:「周りの花と可愛い子犬の写真リアルな高解像度画像」。 |
メモリ効率のための強化されたアテンションモジュール
ML推論エンジンは通常、最適化されたさまざまなML操作を提供します。しかし、各ニューラルネット演算子を実行するためのオーバーヘッドがあるため、最適なパフォーマンスを達成することは依然として難しい場合があります。このオーバーヘッドを緩和するため、ML推論エンジンは、複数の演算子を1つの演算子に統合する広範な演算子フュージョンルールを組み込んで、テンソル要素を横断するイテレーション数を減らすことで、イテレーションあたりの計算を最大限に増やします。たとえば、TensorFlow Liteは、畳み込みのような計算負荷の高い演算と、後続の活性化関数であるReLUのような演算を組み合わせる演算子フュージョンを利用しています。
- アクセラレータの加速化:科学者がGPUとAIでCERNのHPCを高速化
- Microsoft BingはNVIDIA Tritonを使用して広告配信を高速化
- 魚の養殖スタートアップ、AIを投入して水産養殖をより効率的かつ持続可能にする
最適化の明らかな機会は、LDMのデノイザーモデルで採用された頻繁に使用されるアテンションブロックです。アテンションブロックにより、重要な領域に重みを割り当てることで、モデルは入力の特定の部分に焦点を当てることができます。アテンションモジュールを最適化する方法は複数ありますが、以下に説明する2つの最適化のうち、どちらが優れたパフォーマンスを発揮するかに応じて、選択的に1つを使用します。
第1の最適化である部分的にフュージョンされたsoftmaxは、アテンションモジュール内のsoftmaxと行列乗算の間の詳細なメモリ書き込みと読み取りを省略します。アテンションブロックが単純な行列乗算であると仮定すると、Y = softmax(X)* Wの形式で表されます。ここで、XとWはそれぞれa×bおよびb×cの2D行列です(下図参照)。
数値の安定性のために、T= softmax(X)は、通常、3つのパスで計算されます。
- リストの最大値を決定し、行ごとに行列Xを計算します
- 各リスト項目の指数関数と最大値(パス1から)の差を合計します
- アイテムから最大値を引いた指数関数を、パス2からの合計で除算します
これらのパスを単純に実行すると、中間テンソル T に全体のsoftmax関数の出力が格納されるため、巨大なメモリ書き込みが必要になります。パス1と2の結果のみを保存するテクニックを使用することで、m と s という小さなベクトルをストアするだけで済みます。これらは、T のa・b要素に比べて非常に小さくなります。このテクニックにより、メモリ消費量を数桁にわたって減少させることができます(下半分で示されています)。
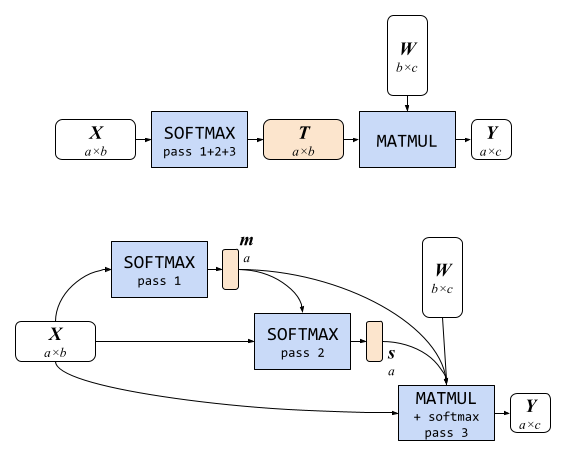 |
| Attention modules. Top :単純なアテンションブロックは、SOFTMAX(全ての3つのパスを含む)とMATMULで構成されており、大きな中間テンソルTのために大量のメモリ書き込みが必要です。Bottom : 一部融合されたsoftmaxを持つメモリ効率の良いアテンションブロックでは、mとsの2つの小さな中間テンソルのみを保存する必要があります。 |
もう一つの最適化は、I/Oに意識を向けた正確なアテンションアルゴリズムである FlashAttention を採用することです。このアルゴリズムは、GPUの高帯域幅メモリアクセスの数を減らし、メモリ帯域幅に制限のある使用例に適しています。ただし、この技術は特定のサイズのSRAMでのみ機能し、多数のレジスタが必要になるため、一部のGPUでのみこの技術を利用しています。
Winogradによる3×3畳み込み層の高速畳み込み
一般的なLDMのバックボーンは、3×3畳み込み層(フィルタサイズが3×3の畳み込み)に強く依存しており、デコーダーのレイヤーの90%以上を占めています。メモリ消費量と数値誤差が増加しているにもかかわらず、Winogradによる高速畳み込みは、畳み込みを高速化するのに効果的だとわかりました。畳み込みで使用される3×3のフィルタサイズとは異なり、タイルサイズとは、一度に処理される入力テンソルのサブ領域のサイズを指します。タイルサイズを増やすと、算術演算ユニット(ALU)の使用効率が向上します。ただし、この改善にはメモリ消費量の増加が伴います。私たちのテストでは、タイルサイズ4×4が、計算効率とメモリ利用の最適なトレードオフを実現できることが示されています。
| メモリ使用量 | |||
| タイルサイズ | FLOPSの削減 | 中間テンソル | 重み |
| 2×2 | 2.25× | 4.00× | 1.77× |
| 4×4 | 4.00× | 2.25× | 4.00× |
| 6×6 | 5.06× | 1.80× | 7.12× |
| 8×8 | 5.76× | 1.56× | 11.1× |
| Winogradのタイルサイズが3×3の畳み込みに与える影響。 |
メモリ効率のための専門のオペレータフュージョン
オンデバイスのGPUアクセラレートされたML推論エンジンが提供する現在のオフシェルフに比べて、モバイルGPU上でLDMを実行することがパフォーマンス上要求されるため、LDMで一般的に使用されるレイヤーやユニットに対しては、より大きなフュージョンウィンドウが必要であることがわかりました。そのため、通常のフュージョンルールが許容するよりも多くのニューラルオペレータを実行できる専門実装を開発しました。具体的には、Gaussian Error Linear Unit(GELU)とグループ正規化レイヤに焦点を当てました。
下の図でライトオレンジの角丸矩形として表示される7つの補助中間テンソルに書き込み、読み込みを行い、入力テンソルxから3回読み込み、出力テンソルyに書き込みを行う必要があるGELUの近似には、8つのGPUプログラムが必要です。ラベル付けされた操作を実行するそれぞれのプログラムにつき、カスタムGELU実装を使用すると、すべての中間テンソルのメモリI/Oをバイパスできます。
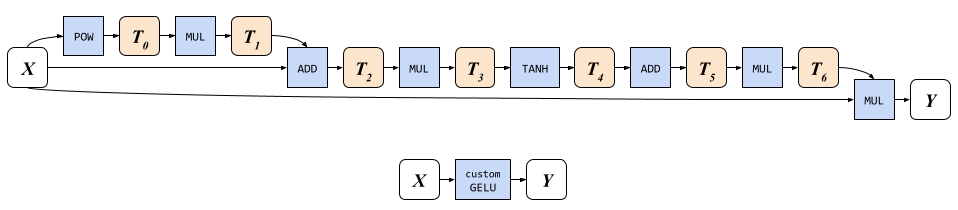 |
| GELU実装。 上 : 組み込みの操作があるナイーブな実装では、8回のメモリ書き込みと10回の読み込みが必要です。 下 : カスタムGELUは、1回のメモリ読み取り(x用)と1回の書き込み(y用)のみが必要です。 |
結果
これらの最適化をすべて適用した後、高性能なモバイルデバイスでStable Diffusion 1.5(画像解像度512×512、20回の反復)のテストを実施しました。GPUアクセラレートされたML推論モデルを使用したStable Diffusionの実行には、重みが2,093MB、中間テンソルが84MB必要です。最新の高性能スマートフォンでは、Stable Diffusionを12秒未満で実行できます。
 |
| Stable Diffusionは、現代のスマートフォンで12秒未満で実行できます。このアニメーションGIFでは、各反復後にデコーダを実行して中間出力を表示するために実行されるため、約2倍の処理時間がかかります。 |
結論
大規模なモデルのオンデバイスML推論を実行することは、モデルファイルサイズの制限、ランタイムメモリ要件の拡大、および推論レイテンシの延長を含む、重大な課題であることが証明されています。メモリ帯域幅の使用を主要なボトルネックとして認識し、ALU効率とメモリ効率の微妙なバランスをとるための努力を向けた結果、大規模な拡散モデルの推論レイテンシで最新の状態を達成しました。この作業について詳しくは、論文を参照してください。
謝辞
私たちは、Yu-Hui Chen、Jiuqiang Tang、Frank Barchard、Yang Zhao、Joe Zou、Khanh LeViet、Chuo-Ling Chang、Andrei Kulik、Lu Wang、Matthias Grundmannに感謝したいと思います。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






