「GPUのマスタリング:PythonでのGPUアクセラレーテッドデータフレームの初心者ガイド」
GPUマスタリング:PythonでのGPUアクセラレーテッドデータフレーム初心者ガイド
パートナーシップ記事
もしPythonで大容量のデータセット(数ギガバイト)を扱っている場合、おそらくCPUベースのpandas DataFrameが操作を行う際に数時間待たされるというストレスを感じていることでしょう。このような状況では、pandasユーザーはRAPIDS cuDFを使用してGPUを活用することを考えるべきです。
cuDFはpandasに似たAPIを持つRAPIDSのGPU上でのデータ処理を可能にするもので、データサイエンティストやエンジニアはわずかなコードの変更でGPU上の並列処理の潜在能力を素早く活用することができます。
もしGPUのアクセラレーションについて詳しくない場合、この記事はRAPIDSエコシステムの簡単な紹介であり、GPUベースのpandas DataFrameの相当するcuDFの最も一般的な機能を紹介しています。
これらのヒントの便利なまとめをご希望ですか?ダウンロード可能なcuDFチートシートに従って進めてください。
cuDF DataFrameを活用する
cuDFはGPUアクセラレータライブラリ群であるRAPIDSのデータサイエンスの基本的な構成要素です。これを使用してデータパイプラインを構築し、データを処理し、新しい特徴を派生させることができます。RAPIDSスイート内の基本的なコンポーネントであるcuDFは他のライブラリを支える役割を果たしており、共通のビルディングブロックとしての役割を確立しています。RAPIDSスイートのすべてのコンポーネントと同様に、cuDFはCUDAバックエンドを使用してGPU計算を行います。
ただし、使い慣れたPythonインターフェースを備えているため、cuDFユーザーは直接そのレイヤーとやり取りする必要はありません。
cuDFでデータサイエンスを高速化する方法
スクリプトが実行される間に時計を見るのに飽きましたか?文字列データを処理するか、時系列データを扱っている場合、cuDFを使用してデータ処理を進めるための方法はさまざまあります。
- 時系列分析:データのリサンプリング、特徴の抽出、または複雑な計算を行う場合、cuDFはpandasに比べて時系列分析で最大880倍高速化することができます。
- リアルタイムの探索的データ分析(EDA):伝統的なツールでは大規模なデータセットを閲覧することは大変ですが、cuDFのGPUアクセラレーション処理能力により、さらに大規模なデータセットのリアルタイム探索が可能になります。
- 機械学習(ML)データの準備:cuDFの高速処理能力を活用して、データの変換タスクを高速化し、回帰、分類、クラスタリングなどの一般的に使用されるMLアルゴリズムにデータを準備します。効率的な処理により、モデルの開発が迅速化され、展開に向けてより早く進むことができます。
- 大規模データの可視化:地理データのヒートマップを作成したり、複雑な金融トレンドを視覚化したりする場合、開発者はcuDFとcuxfilterを使用して高性能かつ高FPSのデータ可視化ライブラリを展開することができます。この統合により、リアルタイムのインタラクティビティが分析サイクルの重要な要素となります。
- 大規模データのフィルタリングと変換:数ギガバイトを超える大規模なデータセットの場合、pandasよりもはるかに短い時間でcuDFを使用してフィルタリングや変換を行うことができます。
- 文字列データの処理:従来、文字列データの処理は複雑なテキストデータの性質により難しく、遅いタスクでした。GPUアクセラレーションにより、これらの操作を簡単に行うことができます。
- GroupBy操作:GroupBy操作はデータ分析の基本ですが、リソースを多く消費することがあります。cuDFはこれらのタスクを大幅に高速化し、データの分割と集計を行う際により早く洞察を得ることができます。

GPU処理のための使い慣れたインターフェース
RAPIDSの基本的な前提は、一般的なデータサイエンスツールに使い慣れたユーザーエクスペリエンスを提供し、NVIDIA GPUのパワーをすべてのプラクティショナーが簡単に利用できるようにすることです。ETLを実行したり、MLモデルを構築したり、グラフを処理したりする場合でも、pandas、NumPy、scikit-learn、またはNetworkXを知っている場合は、お気に入りのツールを使用しながら、RAPIDSを使用すると自宅で感じることができます。
pandasの代わりにcuDFをインポートするだけで、CPUからGPUのデータサイエンススタックへの切り替えはこれまで以上に簡単になります。NVIDIA GPUの膨大なパワーを活用してワークロードを10〜100倍(低い場合)高速化し、より生産性を向上させることができます。
以下は、pandasを使用している人にとってcuDF APIがどれだけ馴染み深いかを示すサンプルコードを確認してください。
import pandas as pd
import cudf
df_cpu = pd.read_csv('/data/sample.csv')
df_gpu = cudf.read_csv('/data/sample.csv')
お気に入りのデータソースからデータを読み込む
cuDFの読み書き機能は、RAPIDSが2018年10月に最初にリリースされて以来、大幅に拡張されています。データはマシン内にあるか、オンプレミスクラスタに保存されているか、クラウドに保存されている場合があります。cuDFは、ファイルシステムに関連するタスクのほとんどを抽象化するfsspecライブラリを使用しているため、重要なのは特徴量の作成とモデルの構築に集中できます。
fsspecのおかげで、ローカルファイルシステムまたはクラウドファイルシステムからデータを読み込むには、後者への認証情報を提供するだけで十分です。以下の例では、同じファイルを2つの異なる場所から読み込んでいます。
import cudf
df_local = cudf.read_csv('/data/sample.csv')
df_remote = cudf.read_csv(
's3://<bucket>/sample.csv'
, storage_options = {'anon': True})
cuDFは、CSV/TSVやJSONなどのテキストベースのフォーマット、ParquetやORCなどの列指向のフォーマット、Avroなどの行指向のフォーマットなど、複数のファイル形式をサポートしています。ファイルシステムのサポートに関しては、cuDFはローカルファイルシステム、AWS S3やGoogle GSなどのクラウドプロバイダ、オンプレミスのHadoopファイルシステム、HTTPまたは(S)FTPウェブサーバー、DropboxやGoogle Drive、Jupyterファイルシステムから直接ファイルを読み込むことができます。
簡単にDataFrameを作成して保存する
ファイルを読み込むだけでなく、cuDFのDataFrameを作成する方法は少なくとも4つあります。
値のリストから1つの列を持つDataFrameを作成する場合は、
cudf.DataFrame([1,2,3,4], columns=['foo'])
複数の列を持つDataFrameを作成する場合は、辞書を渡します。
cudf.DataFrame({
'foo': [1,2,3,4]
, 'bar': ['a','b','c',None]
})
空のDataFrameを作成し、列に割り当てることもできます。
df_sample = cudf.DataFrame()
df_sample['foo'] = [1,2,3,4]
df_sample['bar'] = ['a','b','c',None]
タプルのリストを渡す場合は、
cudf.DataFrame([
(1, 'a')
, (2, 'b')
, (3, 'c')
, (4, None)
], columns=['ints', 'strings'])
また、他のメモリ表現に変換したり、pandasのDataFrameやSeriesに変換したりすることもできます。
- 内部のGPU行列を表すDeviceNDArrayから、
- ディープラーニングフレームワークとApache Arrow形式のテンソル間でテンソルを共有するために使用されるDLPackメモリオブジェクトを介して、さまざまなプログラミング言語からメモリオブジェクトをより便利に操作するための変換、
- pandasのDataFrameやSeriesへの変換。
さらに、cuDFはDataFrameに格納されたデータを複数の形式とファイルシステムに保存することもサポートしています。実際、cuDFは読み込むことができる全ての形式でデータを保存することができます。
これらの機能により、タスクやデータの場所に関係なく、素早く始めることができます。
データの抽出、変換、要約
データサイエンスの基本的なタスクであり、すべてのデータサイエンティストが文句を言っているのは、データセットのクリーニング、フィーチャリング、データセットに慣れる作業です。その作業には80%の時間を費やします。なぜそれほど時間がかかるのでしょうか?
1つの理由は、データセットに対して行う質問に答えるのに時間がかかるからです。CPUで2GBのデータセットを読み込んで処理したことがある人なら、何を言っているかわかるでしょう。
さらに、私たちは人間であり、ミスをするため、パイプラインを再実行するとすぐにフルデイの練習になる場合があります。これは生産性の低下と、おそらく下のチャートを見ると、コーヒー中毒につながる可能性があります。
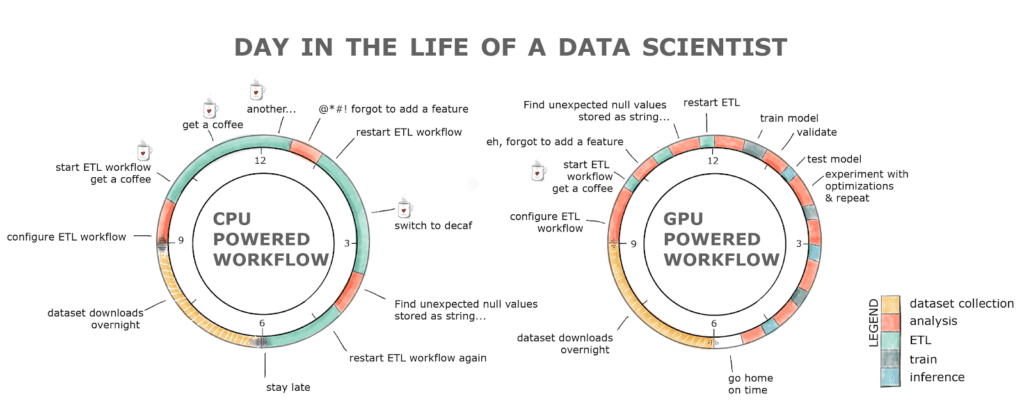
GPUパワードのワークフローであるRAPIDSは、これらすべての障壁を取り除きます。ETLステージは通常、CPUに比べて8〜20倍高速ですので、2GBのデータセットをロードするのに数秒かかります。データのクリーニングや変換も桁違いに高速です!これらすべてを、おなじみのインターフェースで、コードの変更を最小限に抑えて実現します。
GPU上での文字列と日付の処理
5年前までは、GPU上での文字列と日付の処理はほぼ不可能で、CUDAのような低レベルプログラミング言語では到底実現できないと考えられていました。なぜなら、GPUはグラフィックスを処理するために設計されており、つまり、大きな配列や行列の整数や浮動小数点数を操作するためであり、文字列や日付ではありません。
RAPIDSを使用すると、GPUメモリに文字列を読み込むだけでなく、特徴量を抽出し、処理、操作することもできます。正規表現に詳しい場合、cuDFのおかげでGPU上のドキュメントから有用な情報を抽出することは、今では簡単なタスクです。たとえば、ドキュメントから[a-z]*flowパターン(dataflow、workflow、またはflowのような)に一致するすべての単語を見つけて抽出したい場合、次のようにすればよいです。
df['string'].str.findall('([a-z]*flow)')
日付から有用な特徴量を抽出したり、特定の期間のデータをクエリすることも、RAPIDSのおかげでより簡単かつ高速になりました。
dt_to = dt.datetime.strptime("2020-10-03", "%Y-%m-%d")
df.query('dttm <= @dt_to')
GPUアクセラレーションでPandasユーザーを強化する
RAPIDSを使用することで、CPUからGPUデータサイエンススタックへの移行は簡単です。pandasの代わりにcuDFをインポートするだけの小さな変更で、莫大な利益をもたらすことができます。ローカルのGPUボックスで作業している場合でも、フルフレッジのデータセンターにスケーリングアップしている場合でも、RAPIDSのGPUアクセラレーションのパワーにより、10〜100倍の高速化が実現されます(低い場合でも)。これにより、生産性が向上するだけでなく、要求の厳しい大規模なシナリオでもお気に入りのツールを効率的に利用することができます。
RAPIDSは、データ処理の景観を真に革新し、かつて数時間または数日かかっていたタスクを数分で完了できるようにし、生産性を向上させ、総合的なコストを削減することができました。
これらの技術をデータセットに適用するための詳細は、NVIDIA Technical Blogの加速データ分析シリーズを読んでください。
編集者注:この記事は、NVIDIA Technical Blogからの許可を得て更新され、元の記事を改変して掲載しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
