GPTとBERT:どちらが優れているのか?
GPT vs BERT Which is superior?
大規模言語モデルの比較:アプローチと例

生成AIの人気が高まるにつれて、大規模言語モデルの数も増加しています。この記事では、OpenAIによって開発されたGPTとGoogleによって開発されたBERTの2つを比較します。GPT(Generative Pre-trained Transformer)は、デコーダーのみのアーキテクチャに基づいています。一方、BERT(Bidirectional Encoder Representations from Transformers)は、エンコーダーのみの事前学習モデルです。
両者は技術的に異なりますが、自然言語処理タスクを実行するために類似した目的を持っています。多くの記事では、技術的な観点から2つを比較しています。しかし、この記事では、自然言語処理の品質に基づいて比較します。
比較アプローチ
完全に異なる2つの技術アーキテクチャをどのように比較しますか? GPTはデコーダーのみのアーキテクチャであり、BERTはエンコーダーのみのアーキテクチャです。したがって、デコーダーのみ対エンコーダーのみのアーキテクチャの技術的比較は、フェラーリとランボルギーニを比較するのと同じです。両方とも素晴らしいですが、シャシーの下には完全に異なる技術があります。
しかしながら、両方ができる共通の自然言語タスクの質に基づいて比較することができます。それは埋め込みの生成です。埋め込みとは、テキストのベクトル表現です。埋め込みは、すべての自然言語処理タスクの基礎となります。したがって、埋め込みの品質を比較できれば、自然言語処理の品質を判断するのに役立ちます。
- DeepMind RoboCat:自己学習ロボットAIモデル
- BITEとは 1枚の画像から立ち姿や寝そべりのようなポーズなど、困難なポーズでも3D犬の形状とポーズを再構築する新しい手法
- 大規模言語モデルに関するより多くの無料コース
以下に、私が取る比較アプローチが示されています。
GPTで始めましょう
コイントスをし、GPTが勝ちました!では、まずGPTから始めましょう。AmazonのFine Food Reviewsデータセットからテキストを取得します。レビューは、自然言語で表現され、非常に自発的です。顧客の気持ちを包括し、あらゆる種類の言語-良い、悪い、醜い言語を含むことができます。さらに、多くのつづり間違い、絵文字、よく使われるスラングが含まれることがあります。
以下は、レビューのテキストの例です。

GPTを使用してテキストの埋め込みを取得するには、OpenAIにAPIコールを行う必要があります。結果は、各テキストのサイズが1540の埋め込みまたはベクトルです。以下は、埋め込みを含むサンプルデータです。

次のステップは、クラスタリングと可視化です。埋め込みベクトルをクラスタリングするためにKMeansを使用し、2つの次元に1540の次元を削減するためにTSNEを使用できます。以下は、クラスタリングと次元削減後の結果です。
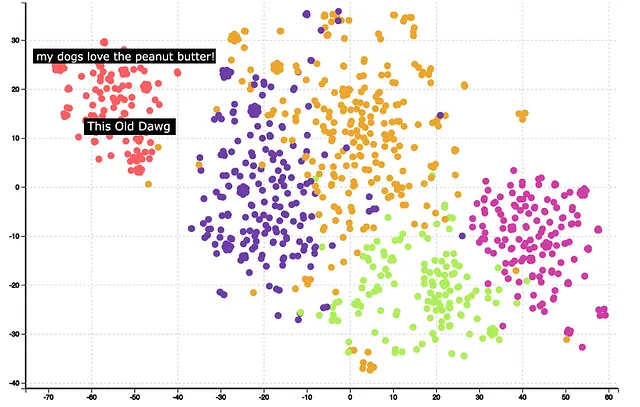
クラスターは非常によく形成されていることが観察できます。クラスターの意味を理解するのに、一部のクラスターにマウスを重ねると役立ちます。例えば、赤いクラスターは犬の食品に関連しています。さらなる分析により、GPTの埋め込みが単語「Dog」と「Dawg」が類似していると正しく識別し、同じクラスターに配置したことがわかります。
全体的に、クラスタリングの質によって示されるように、GPTの埋め込みは良い結果を与えます。
今度はBERTの番です
BERTはより良い結果を出すことができるのでしょうか。複数のBERTモデルがあり、bert-base-case、bert-base-uncasedなどがあります。基本的に、異なる埋め込みベクトルサイズを持っています。ここでは、埋め込みサイズが768のBert baseに基づく結果が示されています。
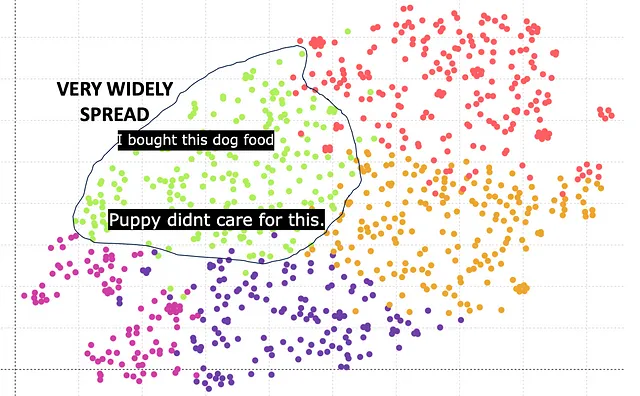
緑色のクラスターは犬の食品に対応しています。しかし、GPTと比較して、クラスターは広がっており、非常にコンパクトではありません。主な理由は、768の埋め込みベクトル長がGPTの1540の埋め込みベクトル長に劣るためです。
幸いにも、BERTは1024のより高い埋め込みサイズも提供しています。以下はその結果です。
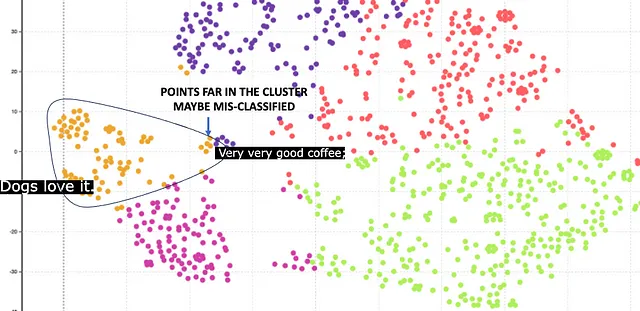
ここでは、オレンジ色のクラスターが犬の食品に対応しています。クラスターは比較的コンパクトであり、768の埋め込みと比較して良い結果が得られています。ただし、中心から遠く離れた点がいくつかあります。これらの点は誤って分類されたものです。例えば、コーヒーのレビューがあり、その中に「Dog」という単語があるため、誤って犬の食品に分類されています。
結論
明らかに、GPTはBERTよりも優れた、より高品質の埋め込みを提供します。ただし、比較には他の側面があるため、GPTにすべてのクレジットを与えたくありません。以下はサマリーテーブルです

GPTは、より高い埋め込みサイズによって提供される埋め込みの品質においてBERTに勝ります。ただし、GPTには有料APIが必要であり、BERTは無料です。さらに、BERTモデルはオープンソースで、ブラックボックスではないため、より詳細な分析が可能です。OpenAIのGPTモデルはブラックボックスです。
結論として、ウェブページや書籍などのキュレーションされたテキストを含むVoAGI複雑なテキストにはBERTを使用することをお勧めします。完全に自然言語でキュレーションされていない顧客レビューなどの非常に複雑なテキストにはGPTを使用できます。
技術的実装
ここに、ストーリーで説明されたプロセスを実行するPythonコードの断片が示されています。例として、GPTのコードを示しています。BERTのものも同様です。
##パッケージのインポートimport openaiimport pandas as pdimport reimport contextlibimport ioimport tiktokenfrom openai.embeddings_utils import get_embeddingfrom sklearn.cluster import KMeansfrom sklearn.manifold import TSNE##データの読み込みfile_name = 'path_to_file'df = pd.read_csv(file_name)##パラメータの設定embedding_model = "text-embedding-ada-002"embedding_encoding = "cl100k_base" # this the encoding for text-embedding-ada-002max_tokens = 8000 # the maximum for text-embedding-ada-002 is 8191top_n = 1000encoding = tiktoken.get_encoding(embedding_encoding)col_embedding = 'embedding'n_tsne=2n_iter = 1000##OpenAIから埋め込みを取得するdef get_embedding(text, model): openai.api_key = "YOUR_OPENAPI_KEY" text = text.replace("\n", " ") return openai.Embedding.create(input = [text], model=model)['data'][0]['embedding']col_txt = 'Review'df["n_tokens"] = df[col_txt].apply(lambda x: len(encoding.encode(x)))df = df[df.n_tokens <= max_tokens].tail(top_n)df = df[df.n_tokens > 0].reset_index(drop=True) ##トークンがない場合は削除する、たとえば空白行の場合df[col_embedding] = df[col_txt].apply(lambda x: get_embedding(x, model='text-embedding-ada-002'))matrix = np.array(df[col_embedding].to_list())##クラスタリングを実行するkmeans_model = KMeans(n_clusters=n_clusters,random_state=0)kmeans = kmeans_model.fit(matrix)kmeans_clusters = kmeans.predict(matrix)#TSNEtsne_model = TSNE(n_components=n_tsne, verbose=0, random_state=42, n_iter=n_iter,init='random')tsne_out = tsne_model.fit_transform(matrix)データセットの引用
このデータセットは、CC0パブリックドメインのライセンスで利用可能です。商用利用と非商用利用の両方が許可されています。
Amazon Fine Food Reviews
Amazonから約50万件のフードレビューを分析する
www.kaggle.com
新しい記事を公開するたびに通知を受け取るには、購読してください。
Pranay Daveが公開するたびにメールを受け取る
Pranay Daveが公開するたびにメールを受け取る。サインアップすると、VoAGIアカウントが作成されます(まだ持っていない場合)…
pranay-dave9.medium.com
私の紹介リンクでVoAGIに参加することもできます
私の紹介リンクでVoAGIに参加する- Pranay Dave
VoAGIメンバーとして、読んだライターに会費の一部が支払われ、すべてのストーリーにフルアクセスできます…
pranay-dave9.medium.com
その他のリソース
ウェブサイト
コーディング不要で分析を行うために私のウェブサイトを訪問することができます。https://experiencedatascience.com
YouTubeチャンネル
デモを使用したデータサイエンスやAIのユースケースを学ぶために私のYouTubeチャンネルを訪問してください
データサイエンスの実演
デモを通じてデータサイエンスを学ぶ。あなたがどの職業であっても、くつろいでビデオを楽しんでください。私の名前は…
www.youtube.com
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- AutoML – 機械学習モデルを構築するための No Code ソリューション
- Paellaを紹介します:安定した拡散よりもはるかに高速に高品質の画像を生成できる新しいAIモデル
- AIのダークサイドを明らかにする:プロンプトハッキングがあなたのAIシステムを妨害する方法
- ChatGPTを使った効率的なデバッグ
- Light & WonderがAWS上でゲーミングマシンの予測保守ソリューションを構築した方法
- 科学者たちは、AIと迅速な応答EEGを用いて、せん妄の検出を改善しました
- 医薬品探索の革新:機械学習モデルによる可能性のある老化防止化合物の特定と、将来の複雑な疾患治療のための道筋を開拓する






