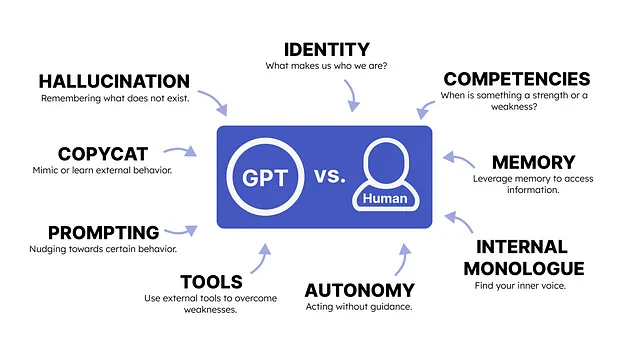
GPTと人間の心理学
GPT and Human Psychology.
人間の思考と推論との類似点
生成型のテキストモデル(ChatGPT、GPT-4など)により、AIの状況は大きく変化しました。
これらのGPT(Generative Pretrained Transformer)モデルは、技術的なバックグラウンドのない人々にとって人工知能に飛び込むためのハードルを取り除いたように思えます。誰でもモデルにいろいろな質問をするだけで、恐ろしく正確な回答が得られます。
少なくともほとんどの場合は…
正しい出力を再現できないということは、それがそれを行う能力がないということではありません。しばしば、私たちは単に私たちがする質問、プロンプトを変える必要があります。それによってモデルを正しい答えに向かわせるためです。
- レコメンダーシステムにおけるPrecision@NとRecall@Nの解説
- データを持っていますか?SMOTEとGANが合成データを作成する方法
- テレグラムで自分自身のChatGPTボットを所有してください
これはしばしば「プロンプトエンジニアリング」と呼ばれます。
プロンプトエンジニアリングの多くのテクニックは、人間の思考方法を模倣しようとします。モデルに「声に出して考えてみる」または「ステップバイステップで考えてみよう」と頼むことは、私たちが考える方法をモデルが模倣する良い例です。
GPTモデルと人間の心理学の間のこれらの類推は重要です。それらはGPTモデルの出力を改善する方法を理解するのに役立ちます。それらが欠けている可能性のある機能を示してくれます。
これは私がどのGPTモデルも一般的な知能として提唱しているわけではありませんが、GPTモデルを「人間のように考える」方法や理由を見ることは興味深いです。
ここで見ることができる多くの類推は、以下のビデオでも話されています。Andrej Karpathy氏が大規模言語モデルについて心理学的な観点から素晴らしい洞察を共有しており、必見です!
興味深い心理学的な類推を用いてGPTの状態を説明する優れたビデオです。
私自身もデータサイエンティストであり心理学者ですので、このテーマは私にとっては非常に興味深いものです。これらのモデルがどのように振る舞うか、どのように振る舞ってほしいか、そしてどのようにこれらのモデルを私たちと同様に振る舞わせているかを見ることは、非常に興味深いです。
以下の記事では、GPTモデルと人間の心理学の間で興味深い洞察を与える多くのトピックが議論されます:
免責事項: GPTモデルと人間の心理学の類推について話す際、人工知能の人間化というリスクがあります。つまり、これらのGPTモデルを人間化することです。これは私の意図ではありません。この投稿は存在的リスクや一般的な知能についてではなく、私とGPTモデルの類似点を楽しく描く演習です。何かしらの価値があれば、適度に受け入れてください!
プロンプティング
プロンプティングとは、例えば「10冊の本のタイトルのリストを作成する」といった、GPTモデルに要求する内容のことです。
モデルのパフォーマンスを改善するために、さまざまな質問を試してみる場合、それは「プロンプトエンジニアリング」の適用です。
心理学では、特定の行動を示すように促すためのさまざまな形式のプロンプティングがあります。これは通常、応用行動分析(ABA)で新しい行動を学ぶために使用されます。
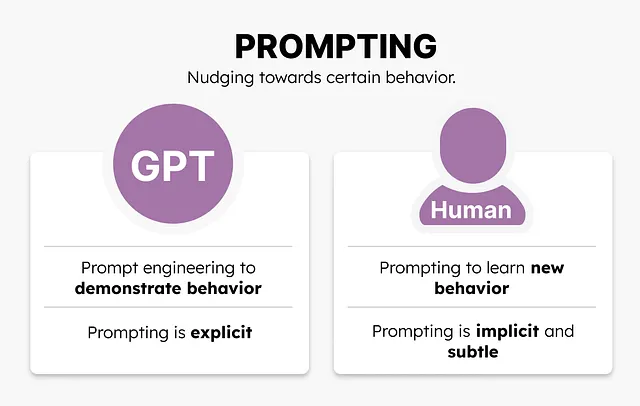
GPTモデルと心理学の間には明確な違いがあります。心理学では、プロンプティングは新しい行動を学ぶことに関わります。つまり、個人が以前にできなかったことを学ぶことです。一方、GPTモデルでは、以前に見られなかった行動を示すことに関わります。
主な違いは、個人が完全に新しいことを学び、ある程度変わるという点です。対照的に、GPTモデルはその行動を既に示すことができましたが、それが状況(つまりプロンプト)のために行わなかったのです。モデルから「適切な」行動を引き出したとしても、モデル自体は変わりませんでした。
GPTモデルでのプロンプティングは、非常に明示的なものです。多くのプロンプティングの技術は、できるだけ明示的なものです(例:「あなたは科学者です。この記事を要約してください。」)。
行動の模倣
GPTモデルは模倣者です。それらは、大量のテキストデータで訓練され、できるだけそれを再現しようとします。

つまり、モデルに質問をすると、訓練中に見たものに最も適合する単語のシーケンスを生成しようとします。十分な訓練データがあれば、この単語のシーケンスはますます一貫性を持つようになります。
ただし、このようなモデルは、模倣している行動を真に理解する固有の能力を持っていません。この記事の多くのことと同様に、GPTモデルが本当に推論を行えるかどうかは議論の余地があり、しばしば情熱的な議論を引き起こします。
私たちには行動を模倣する固有の能力がありますが、それは社会的な構築物と生物学的な基盤に根ざしています。私たちはある程度まで模倣された行動を理解し、簡単に一般化することができます。
アイデンティティ
私たちは自分たちが誰であり、どのように経験が私たちを形作り、世界の見方を持っているのかという固定観念を持っています。私たちはアイデンティティを持っています。
GPTモデルにはアイデンティティがありません。それは私たちが生活している世界について多くの知識を持っており、私たちが好むような回答の種類を知っていますが、「自己」の感覚はありません。
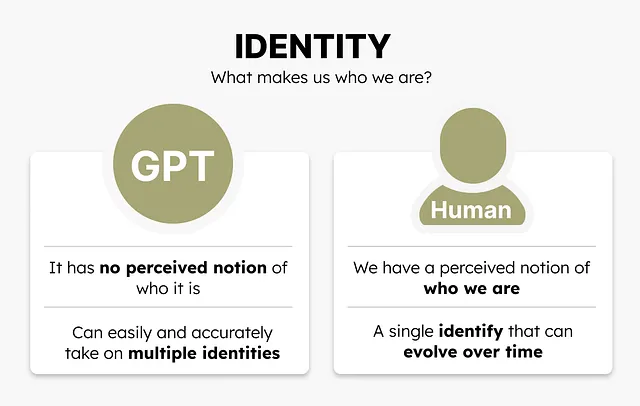
それは私たちのように特定の見解に向かってガイドされるわけではありません。アイデンティティの観点からは、それは白紙の状態です。つまり、GPTモデルは世界について多くの知識を持っているため、要求されたアイデンティティを模倣する能力をいくらか持っています。
しかし、いつも通り、それは単なる模倣行動です。
それには重要な利点があります。私たちはモデルに科学者、作家、編集者などの役割を引き受けるように頼むことができ、それはそれに従おうとします。特定のアイデンティティを模倣するようにプライミングすることで、出力はタスクにより合わせられます。

能力
これは興味深いテーマです。さまざまなテストで大規模言語モデルを評価するための多くのソースがあります。それには、Hugging Face LeaderboardやEloレーティングを使用して大規模言語モデルに挑戦することなどが含まれます。
これらはこれらのモデルの能力を評価するための重要なテストです。しかし、私が特定のモデルの強みと考えるものは、あなたが同意しないかもしれません。

これはモデル自体に関連しています。これらのテストのスコアを教えても、それはどの能力が相対的に強いか弱いかを知りません。たとえば、GPT-4は一般的に大きな強みと考えられている司法試験に合格しました。しかし、モデルは経験豊富な弁護士たちのいる部屋にいるときには、司法試験に合格するだけでは強みではないと気付かないかもしれません。
言い換えれば、一つの能力が強みまたは弱みと見なされるかは、状況の文脈に高度に依存します。私たち自身の能力にも同じことが当てはまります。私は自分自身を大規模言語モデルの熟練者だと思っているかもしれませんが、もし私をAndrew NgやSebastian Raschkaなどの人々に囲まれたら、大規模言語モデルに関する私の知識は以前のような強みではなくなります。
これは重要なことです。モデルは何が強みであり弱みかを本能的に知ることはありませんので、それを教える必要があります。

例えば、数学の方程式を解く際にモデルの性能が低いと感じた場合、計算自体を行わずにWolframプラグインを使用するように指示することができます。
一方で、自分自身の強みや弱点についての概念を持っていると主張しているにもかかわらず、それらはしばしば主観的であり、強く偏っています。
ツール
前述のように、GPTモデルは特定の状況で何が得意で何が苦手なのかを知りません。状況の説明をプロンプトに追加することで、モデルはより正確な回答を生成する方向に誘導されます。
これによって、モデルが全てのタスクに対応できるわけではありません。人間と同様に、状況を説明することは役に立ちますが、全ての弱点を克服するわけではありません。
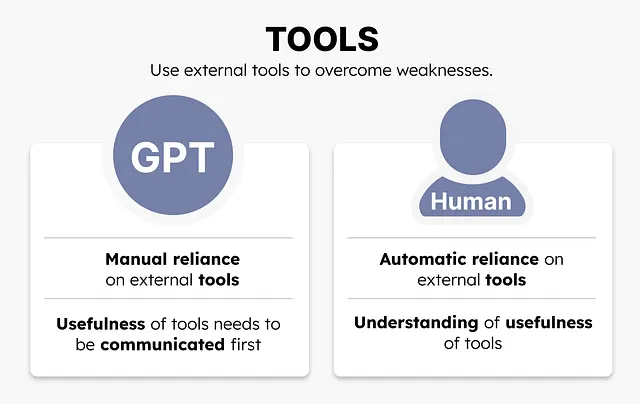
代わりに、私たちが現在の能力では対応できないものに直面した場合、私たちはしばしばツールに頼ります。複雑な方程式を解く際には電卓を使用したり、高速な移動手段として車を使用したりします。
GPTモデルは、外部ツールに自動的に依存するわけではありません。特定のタスクに対してモデルが対応できないと確信した場合に、モデルに特定の外部ツールの使用を指示する必要があります。

重要なのは、私たちは日常的に非常に多くのツールに頼っていることです。携帯電話や鍵、眼鏡などです。同じ能力をGPTモデルに与えることは、そのパフォーマンスに非常に大きな助けとなるでしょう。これらの外部ツールは、OpenAIが提供しているプラグインに似ています。
この方法の主な欠点は、これらのモデルが自動的にツールを使用しないことです。モデルにプラグインの使用が可能であることを明示的に伝える必要があります。
内的対話
私たちは通常、難しい問題を解く際に内なる声と対話をします。「これをすれば結果はこうなるが、あれをすればより良い解が得られるかもしれない」といった具体的な言葉を生成します。
GPTモデルは、これらの行動を自動的に示すわけではありません。質問をすると、最も論理的に続くであろう単語を生成するだけです。もちろん、単語の計算は行いますが、それを利用して内的対話を生成するわけではありません。
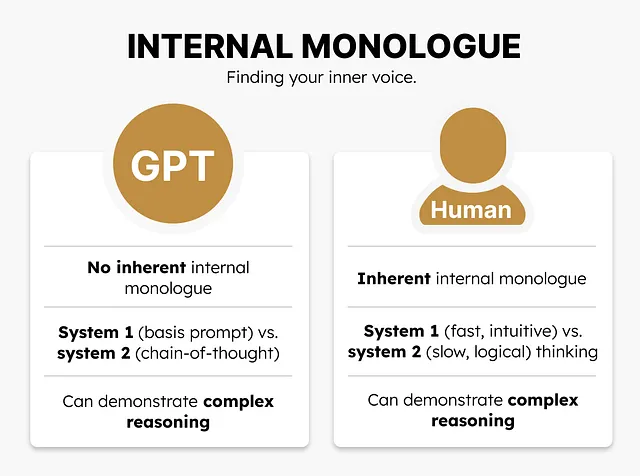
実際、モデルに「ステップバイステップで考えましょう」と言って思考を共有させると、与えられた答えの品質がかなり向上する傾向があります。これは思考の連鎖と呼ばれ、人間の論理的思考過程をエミュレートしようとします。このことはモデルが「推論」を行っているわけではないかもしれませんが、そのパフォーマンスがどれだけ向上するかを見るのは興味深いです。
さらに良いことに、モデルは内的対話を内部で行わないため、モデルの思考に対する驚くべき洞察を得ることができます。

私たちの「内的声」は、私たちのものと比べるとかなり簡略化されています。私たちは、自分自身との「対話」やその「対話」の方法がはるかにダイナミックです。それは象徴的なものであり、運動的なものであり、感情的なものでさえあります。例えば、多くのアスリートは実際の競技の練習の一環として、自分自身が優れているスポーツを行う姿を想像します。これをメンタルイメージと呼びます。
これらの対話は、新しいアイデアを思いついたり、問題を解決したり、問題が現れる文脈を理解したりするために使用します。一方、GPTモデルには、非常に具体的な指示を通じて解決策を出すために対話するように明示的に指示する必要があります。
さらに、これを私たちのシステム1とシステム2の思考プロセスに関連付けることができます。システム1の思考は自動的で直感的でほぼ瞬時のプロセスです。私たちはここでほとんど制御を持ちません。一方、システム2は意識的で遅く、論理的で努力を必要とするプロセスです。
自己反省の能力をGPTモデルに与えることで、私たちは本質的にこのシステム2の思考方法を模倣しようとしています。モデルは回答を生成するためにより多くの時間をかけ、迅速に応答を生成するのではなく、注意深くそれを確認します。
大まかに言えば、プロンプトエンジニアリングなしに、システム1の思考プロセスを可能にし、具体的な指示や思考の連鎖のようなプロセスなしに、システム2の思考方法を可能にします。
もし私たちのシステム1とシステム2の思考について詳しく知りたい場合は、Thinking, Fast and Slowという素晴らしい本がありますので、ぜひ読んでみてください!
メモリ
この記事の冒頭で言及されているAndrej Karpathy氏のビデオで、人間の記憶能力とGPTモデルの記憶能力を比較しています。
私たちの記憶は非常に複雑で、長期記憶、作業記憶、短期記憶、感覚記憶などがあります。
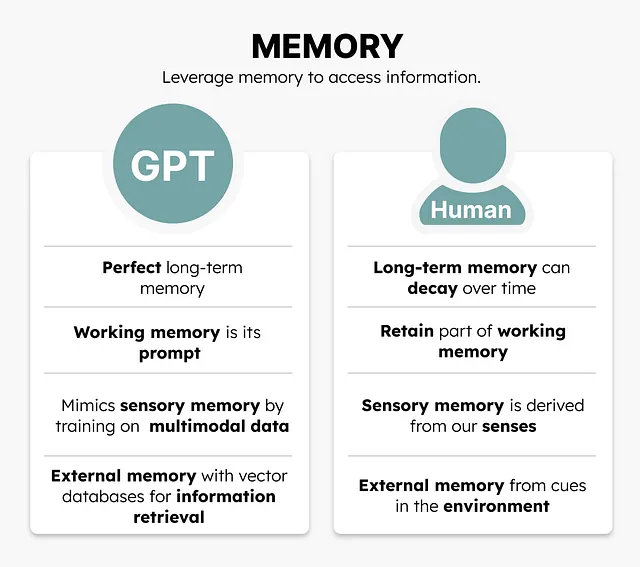
私たちは、GPTモデルのメモリを大まかに言えば4つの要素と見なし、それを私たち自身の記憶システムと比較することができます:
- 長期記憶
- 作業記憶
- 感覚記憶
- 外部メモリ
GPTモデルの長期記憶は、数十億のデータでのトレーニング中に学んだことを表しています。この情報は、モデル内に一定の程度で表現され、必要な時に完璧に再現することができます。この長期記憶は、モデルの存在を通じてモデルと共に存在し続けます。対照的に、私たちの長期記憶は時間の経過とともに減衰することがあり、これは減衰理論としてよく言及されます。
GPTモデルの長期記憶は完璧であり、時間とともに減衰しません
GPTモデルの作業記憶は、それに与えられたプロンプトに収まるすべての情報です。モデルはその情報を完璧に利用して計算を行い、応答を返すことができます。これは私たちの作業記憶と非常によく似ており、一時的に情報を保持するための容量に制限があります。例えば、GPTモデルは応答をした後、そのプロンプトを「忘れます」。会話を覚えているように見える理由は、プロンプトに加えて、会話の履歴がプロンプトに追加されるためです。

GPTモデルは新しい情報に関しては忘れっぽいです
感覚記憶は、視覚、聴覚、触覚などの感覚から得られた情報をどのように保持するかに関連しています。私たちはこの情報を使用し、短期記憶または作業記憶に渡して処理します。これは、テキスト、画像、さらには音声などの複数のモーダルを扱うモデル、マルチモーダルGPTモデルに類似しています。
ただし、GPTモデルの場合、むしろマルチモーダルの作業記憶と長期記憶と言った方が適切かもしれません。これらのモデルは、異なる形式の「メモリ」とマルチモーダルデータを密接に結びつけています。したがって、むしろ感覚記憶を模倣していると言えます。
GPTモデルはマルチモーダルなトレーニング手順によって感覚記憶を模倣します
最後に、GPTモデルは外部メモリを持つと非常に強力になります。これは、物理学に関するいくつかの本など、必要な時にアクセスできる情報のデータベースを指します。対照的に、私たちの外部メモリは環境からの手がかりを使用して特定のアイデアや感覚を思い出すのに役立ちます。ある意味では、内部情報を覚えることと、外部情報にアクセスすることの違いです。
注: 短期記憶については触れていません。短期記憶と作業記憶については、実際には同じものではないかという議論が多くあります。よく言及される違いは、作業記憶が情報の短期保管だけでなく、それを操作する能力も持っていることです。また、GPTモデルとの類似性がより高いため、ここでは選りすぐりにしましょう。
自律性
今回の記事を通じて見てきたように、GPTモデルに何かをさせるためには、それに伝える必要があります。
これは自律性と関係がありますので、重要なポイントです。デフォルトでは、私たちはある程度の自律性を持っています。私が飲み物を取ることを決めれば、取ることができます。
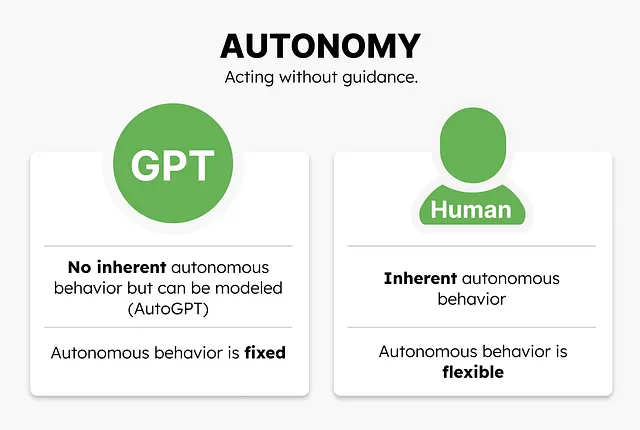
これはGPTモデルにとって異なります。デフォルトでは自律性を持ちません。それには必要なツールと環境を与えなければ独立して動作することはできません。
GPTモデルに自律性を与えるためには、特定の目標を達成するために実行するタスクをいくつか作成させます。各タスクについて、それを完了するための手順を書き留め、それを反省し、必要なツールがあれば実行します。
AutoGPTは、GPTモデルに自律性を与える素晴らしい例です
その結果、モデルができることは、私たちの環境が私たちに与える影響よりも、環境に非常に依存していると言えます。私たちの環境が私たちに与える影響を考えると、これは非常に重要です。
これはまた、GPTモデルが印象的な複雑な自律的な振る舞いを示すことができるということを意味しますが、それは固定されています。私たちにとっては、新しい未知のツールに適応することができます。
幻覚
GPTモデルの一般的な問題は、彼らが自信を持って何かを言うことであり、そのことが単に真実ではないか、または彼らのトレーニングデータでサポートされていないことです。
例えば、Appleの2019年の収益などの事実情報をGPTモデルに生成するように依頼すると、完全に誤った情報が生成されるかもしれません。
これは幻覚と呼ばれます。
この用語は、人間の心理学における幻覚から派生しており、私たちが見たものを真実だと信じているのに実際にはそうではないというものです。ここでの主な違いは、人間の幻覚が知覚に基づいているのに対し、モデルの「幻覚」は間違った事実を思い描いているということです。

むしろ、これは偽の記憶と比較する方が適切かもしれません。人間が実際には起こらなかったことを再現しようとするGPTモデルと似ています。

興味深いことに、私たちは影響力、プライミング、フレーミングなどによってより簡単に偽の記憶を生成することができます。これは、受け取ったプロンプトが非常に影響力を持っているため、GPTモデルが「幻覚」を見せる方法にもっと近いようです。
私たちの記憶も、他の人から受け取ったプロンプト/フレーズに影響を受けることがあります。例えば、人に「この車の色は何色だったか」と尋ねることで、実際には赤ではないにもかかわらず、その車が赤であるという「事実」を暗黙的に提供しています。これは偽の記憶を生成し、前提として言及されます。
読んでいただきありがとうございます!
私と同様に、AIやデータサイエンス、心理学に情熱を持っている方は、ぜひ私をLinkedInで追加したり、Twitterでフォローしたり、ニュースレターを購読したりしてください。また、個人ウェブサイトで私のコンテンツをいくつか見つけることもできます。
ソースクレジットのないすべての画像は著者によって作成されました
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
