「GPT-4 8つのモデルを1つに統合、秘密が明かされる」
GPT-4 integrates 8 models into one, secrets revealed.
GPT4モデルはこれまでの画期的なモデルであり、一般の人々には無料で利用することができるか、商業ポータルを通じて利用することができます(パブリックベータ版)。多くの起業家にとって、新しいプロジェクトのアイデアやユースケースを刺激する効果がありましたが、パラメータの数やモデルについての秘密主義は、最初の1兆パラメータモデルから100兆パラメータの主張に賭けていたすべての熱心な支持者を傷つけました!
猫は袋から出た
実は、猫は袋から出た(ある意味では)。6月20日、自動運転スタートアップComma.aiの創設者であるジョージ・ホッツが、GPT-4はGPT-3やGPT-3.5のような単一の巨大なモデルではなく、8つの2200億パラメータモデルの混合物であることをリークしました。
その日の後半、MetaのPyTorch共同創設者であるスーミス・チンタラがこのリークを裏付けました。
前日、Microsoft Bing AIのリードであるミハイル・パラヒンもこれをほのめかしました。
GPT 4:単一の巨大なモデルではない
これらのツイートは何を意味しているのでしょうか?GPT-4は単一の大きなモデルではなく、8つの小さなモデルの結合/アンサンブルであり、それぞれのモデルは2200億のパラメータを持っていると噂されています。

この手法は、専門家のモデルパラダイムの混合と呼ばれています(以下にリンクあり)。これはよく知られた手法であり、モデルのヒドラとも呼ばれます。これはインドの神話のラーヴァナを思い出させます。
これは公式のニュースではないことに注意してくださいが、AIコミュニティの上位メンバーがそれに言及/ほのめかしていることは間違いありません。Microsoftはこれらのどれかを確認していません。
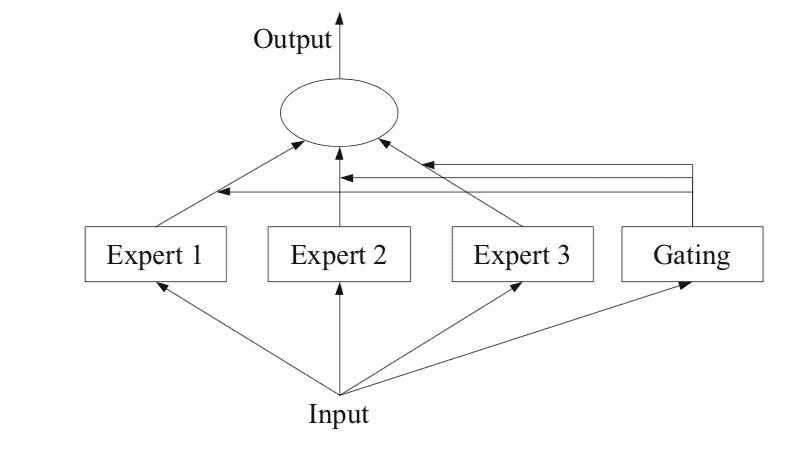
専門家の混合パラダイムとは何ですか?
専門家の混合について話したので、少し掘り下げてみましょう。専門家の混合は、ニューラルネットワークに特化したアンサンブル学習の技術です。これは、従来の機械学習モデリングの一般的なアンサンブル手法とは少し異なります(その形式は一般化された形式です)。つまり、LLMsの専門家の混合はアンサンブル手法の特殊なケースと考えることができます。
簡単に言えば、この方法ではタスクをサブタスクに分割し、各サブタスクの専門家を使用してモデルを解決します。これは、意思決定木を作成する際の分割と征服のアプローチです。それぞれのサブタスクに対して、より小さくて優れたモデルをトレーニングすることができます。メタモデルは、どのモデルが特定のタスクの予測に適しているかを学習します。メタラーナー/モデルは交通警官のような役割を果たします。サブタスクは重複する場合と重複しない場合がありますが、出力の組み合わせをマージして最終的な出力を生成することができます。
MOEからプーリングまでの概念説明については、Jason Brownlee氏の素晴らしいブログ(https://machinelearningmastery.com/mixture-of-experts/)に全てのクレジットがあります。以下の内容が気に入った場合は、ぜひJasonのブログに登録し、彼の素晴らしい仕事をサポートするために本を購入してください!
専門家の混合、MoEまたはMEとは、予測モデリング問題のサブタスクに専門家をトレーニングするアンサンブル学習の技術です。
ニューラルネットワークのコミュニティでは、いくつかの研究者が分解手法を検討しています。[…] 入力空間を分解するMixture-of-Experts(ME)手法。 […] ゲーティングネットワークは、さまざまな専門家を組み合わせる責任があります。
— ページ73、Pattern Classification Using Ensemble Methods、2010年。
この手法には4つの要素があります:
- タスクをサブタスクに分割する。
- 各サブタスクの専門家を開発する。
- どの専門家を使用するかを決定するゲーティングモデルを使用する。
- 予測とゲーティングモデルの出力を組み合わせて予測を行う。
下記の図は、2012年の書籍「アンサンブル方法」の94ページから引用したもので、手法のアーキテクチャ要素の概要を提供しています。
GPT4の8つの小さなモデルはどのように機能するのですか?
秘密の「エキスパートモデル」が明らかになりました、なぜGPT4はとても優れているのでしょうか!
ithinkbot.com
サブタスク
最初のステップは、予測モデリングの問題をサブタスクに分割することです。これには、ドメイン知識を使用することが多いです。例えば、画像は背景、前景、オブジェクト、色、線などの別々の要素に分割されることがよくあります。
… MEは、複雑なタスクをいくつかのより簡単で小さなサブタスクに分割し、個々の学習者(エキスパートと呼ばれる)が異なるサブタスクのためにトレーニングされる分割統治戦略で機能します。
— 94ページ、アンサンブル方法、2012年。
タスクをサブタスクに分割する方法が明らかでない場合、よりシンプルで一般的なアプローチが使用されることもあります。例えば、列のグループによって入力特徴空間を分割するアプローチや、距離尺度、異常値、標準分布のための入力特徴空間の例を分割するアプローチなどが考えられます。
… MEでは、課題の自然な分割を見つける方法と、そのサブソリューションから全体の解を派生させる方法が主要な問題です。
— 94ページ、アンサンブル方法、2012年。
エキスパートモデル
次に、各サブタスクに対してエキスパートが設計されます。
エキスパートの混合アプローチは、元々人工ニューラルネットワークの分野で開発され、探求されたものであり、伝統的には、エキスパート自体が回帰の場合は数値を予測するために使用されるニューラルネットワークモデル、または分類の場合はクラスラベルを予測するために使用されるニューラルネットワークモデルです。
エキスパートには、任意のモデルを「プラグイン」することができることは明らかです。例えば、ゲーティング関数とエキスパートの両方を表すためにニューラルネットワークを使用することができます。その結果は、混合密度ネットワークとして知られています。
— 344ページ、機械学習:確率的な視点、2012年。
各エキスパートは同じ入力パターン(行)を受け取り、予測を行います。
ゲーティングモデル
予測された各エキスパートによる予測を解釈し、特定の入力に対して信頼できるエキスパートを決定するためにモデルが使用されます。これはゲーティングモデル、またはゲーティングネットワークと呼ばれ、伝統的にはニューラルネットワークモデルです。
ゲーティングネットワークは、エキスパートモデルに提供された入力パターンを入力とし、各エキスパートが入力に対して予測を行う際の寄与度を出力します。
… ゲーティングネットワークによって決定される重みは、MoEがアンサンブルメンバーごとにどの特徴空間の一部を学習するかを効果的に学習します
— 16ページ、アンサンブル機械学習、2012年。
ゲーティングネットワークはアプローチの鍵であり、実際にはモデルが特定の入力に対してどのようなサブタスクを選択し、それに応じて強力な予測を行うために信頼するエキスパートを選択する方法を学習します。
エキスパートの分布領域の一部になるように個々の分類器をトレーニングする分類器選択アルゴリズムとしても、エキスパートモデルは見なすことができます。
— 16ページ、アンサンブル機械学習、2012年。
ニューラルネットワークモデルが使用される場合、ゲーティングネットワークとエキスパートは共にトレーニングされ、ゲーティングネットワークはどのエキスパートを信頼して予測を行うかを学習します。このトレーニング手順は、通常、期待最大化(EM)を使用して実装されます。ゲーティングネットワークは、各エキスパートに対して確率的な信頼度スコアを提供するソフトマックス出力を持つ場合もあります。
一般的に、トレーニング手順は2つの目標を達成しようとします:エキスパートが与えられた場合に最適なゲーティング関数を見つけること。ゲーティング関数が与えられた場合に、ゲーティング関数が指定する分布に基づいてエキスパートをトレーニングすること。
— ページ 95、アンサンブルメソッド、2012年。
プーリングメソッド
最後に、エキスパートモデルの混合は予測を行わなければならず、これはプーリングまたは集約メカニズムを使用して達成されます。これは、出力またはゲーティングネットワークによって提供される信頼度が最も高いエキスパートを選択するだけの単純なものである可能性があります。
または、各エキスパートが行った予測とゲーティングネットワークによって推定された信頼度を明示的に組み合わせた加重合計予測が行われるかもしれません。予測とゲーティングネットワークの出力を効果的に使用するための他のアプローチも考えられます。
プール/結合システムは、最も重みの高い単一の分類器を選択するか、各クラスの分類器の出力の加重合計を計算し、最も高い加重合計を受け取るクラスを選択することができます。
— ページ 16、アンサンブル機械学習、2012年。
スイッチルーティング
スイッチルーティングアプローチがMoE論文と異なるかについても簡単に説明しておく必要があります。これは、マイクロソフトが計算の複雑さを軽減するためにMoEモデルではなくスイッチルーティングを使用しているように思われるため、私は間違っているかもしれませんが、証明されることを喜んでいます。複数のエキスパートモデルがある場合、ルーティング関数(いつどのモデルを使用するか)には非自明な勾配があるかもしれません。この決定境界はスイッチレイヤーによって制御されます。
スイッチレイヤーの利点は3つあります。
- トークンが単一のエキスパートモデルにのみルーティングされる場合、ルーティング計算が削減されます
- バッチサイズ(エキスパート容量)は、トークンが単一のモデルにのみ送られるため、少なくとも半分になることができます
- ルーティングの実装が簡素化され、通信が削減されます
同じトークンが1つ以上のエキスパートモデルにオーバーラップすることを容量係数と呼びます。以下は、異なるエキスパート容量係数でのルーティングの概念的な描写です
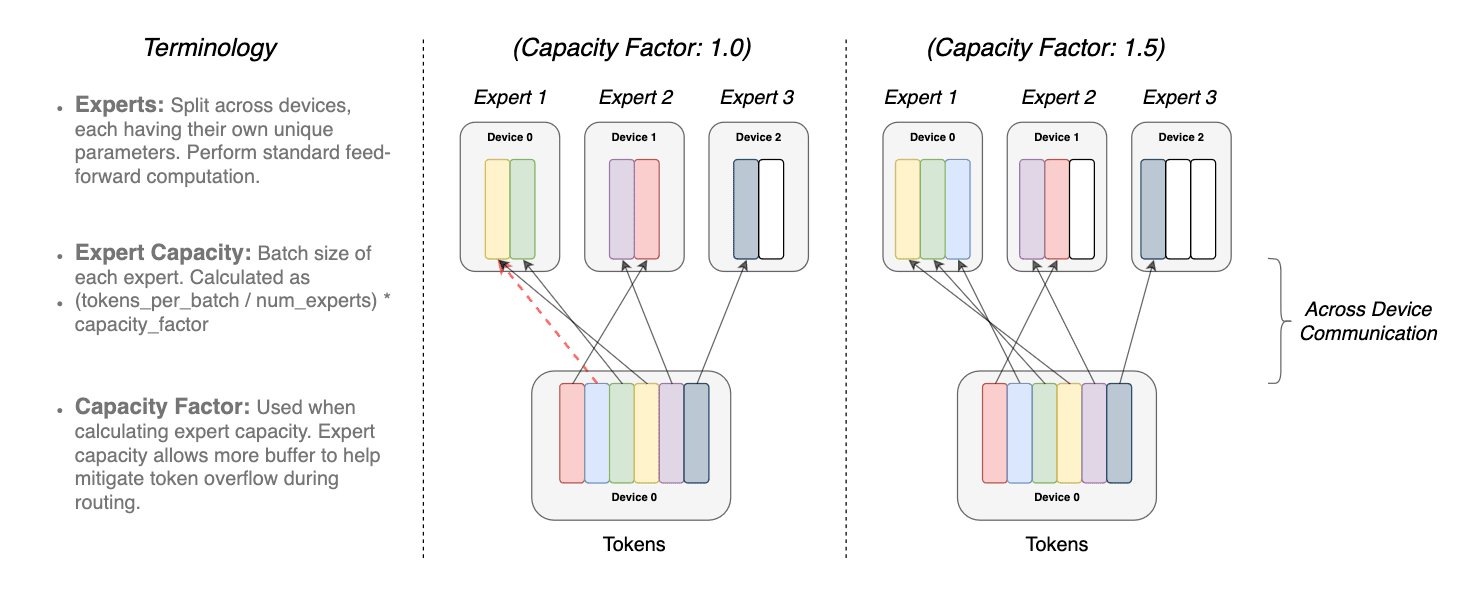
容量係数によって調整されたトークンのオーバーラップ。各トークンはエキスパートにルーティングされます
最も高いルーター確率を持つが、各エキスパートには固定のバッチサイズがあります
(総トークン数/エキスパート数) × 容量係数。トークンが均等に配分されない場合、特定のエキスパートはオーバーフローします(点線の赤い線で示されます)、結果としてこの層で処理されないトークンがあります。容量係数が大きいほど、このオーバーフローの問題は軽減されますが、計算および通信コストも増加します
(パデッドされた白い/空のスロットで示されます)。 (出典:https://arxiv.org/pdf/2101.03961.pdf)
MoEと比較した場合、MoEとスイッチ論文からの知見は、以下のことを示唆しています。
- スイッチトランスフォーマーは、速度と品質の観点で丁寧に調整された密なモデルとMoEトランスフォーマーよりも優れています。
- スイッチトランスフォーマーの計算コストはMoEよりも小さいです
- スイッチトランスフォーマーは、容量係数が低い(1-1.25)場合により優れたパフォーマンスを発揮します。

結論
注意点は2つあります。まず、これはすべて噂からの情報です。そして二つ目は、これらの概念に対する私の理解力がかなり乏しいため、読者にはそれを信じるように強く勧めます。
しかし、マイクロソフトはこのアーキテクチャを隠したことで何を達成したのでしょうか?まあ、彼らは騒ぎを引き起こし、それについてのサスペンスを作り出しました。これは彼らが自分たちにイノベーションを保ち、他の人々が彼らに追いつくのを避けるのに役立ったかもしれません。全体のアイデアはおそらく、彼らが10億ドルを企業に投資する間に競争を阻止するという、通常のマイクロソフトのゲームプランであったでしょう。
GPT-4のパフォーマンスは素晴らしいですが、それは画期的なデザインではありませんでした。エンジニアと研究者によって開発された方法の驚くべき巧妙な実装によって、エンタープライズ/資本主義の展開が追加されました。OpenAIはこれらの主張を否定したり同意したりしていません(https://thealgorithmicbridge.substack.com/p/gpt-4s-secret-has-been-revealed)。これにより、GPT-4のこのアーキテクチャがおそらく現実である可能性が高いと思われます(それは素晴らしいことです!)。ただし、クールではありません!私たちはみんな知りたいし学びたいのです。
このニュースを表面化させ、OpenAIに連絡を取り、さらに調査を進めてくれたアルベルト・ロメロには大きな感謝の意を表します(最新情報によるとOpenAIは応答しなかったとのことです)。彼の記事はLinkedInで見ましたが、同じものがVoAGIでも公開されています。
Dr. Mandar Karhade, MD. PhD. Avalere Healthの上級アナリティクス&データ戦略ディレクター。Mandarは、10年以上にわたり、AIを生命科学やヘルスケア業界に導入する最先端の実装に取り組んできた経験豊富な医師科学者です。Mandarはまた、AFDO/RAPSの一員でもあり、ヘルスケアへのAIの導入を規制するための支援もしています。
オリジナル。許可を得て再掲載。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






