「GPT-4を超えて 新機能は何ですか?」
GPT-4を超える新機能は何ですか?
ジェンAIの四つの主要なトレンド:LLMからマルチモーダルへ、ベクトルDBへの接続、エージェントからOSへ、およびプラグインへの微調整
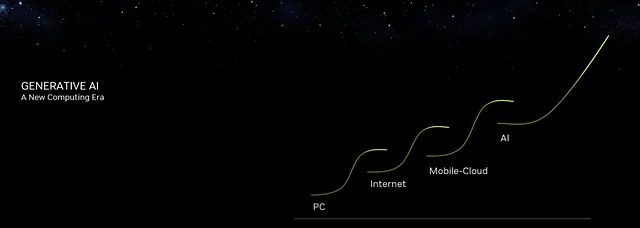
NvidiaのCEOは、ChatGPTをAIの「iPhoneモーメント」と例え、iPhoneのような技術革新と経済的影響のマイルストーンを作り出していることを示しました。これはAIが現在最大の技術エコシステムであるモバイルとクラウドの次の時代を迎えていることを示しています。開始図に示されている四つのコンピューティングの時代を参照してください。
GPT-4はすべてのLLMの限界です。そしてMetaのLlama 2はLLMオープンソースコミュニティでのリーダーです。GPT-4の後には何が新しいのでしょうか?
AIの進化は止まりません。GPT-4の後には、LLMからマルチモーダルへ、接続からベクトルDBへ、エージェントからOSへ、そして微調整からプラグインへという4つのエキサイティングなトレンドがあります。
LLMバリアントとMetaのオープンソース
4つの主要なトレンドを明らかにする前に、最新のMetaのLlama 2とCode Llamaについて共有します。
MetaのLlama 2はLLMの進化を洗練させたものです。このスイートは、7兆から70兆のパラメータスペクトラムにわたって事前学習および微調整されたモデルを網羅しています。専門的な派生物であるLlama 2-Chatは、対話中心のアプリケーションに特化して設計されています。
ベンチマーキングにより、Llama 2は既存のほとんどのオープンソースのチャットモデルよりも優れたパフォーマンスを示しました。安全性と有用性のメトリックに焦点を当てた人間中心の評価では、Llama 2-Chatがプロプライエタリなクローズドソースの競合モデルに対抗する可能性があることが示されました。
Llama 2の開発軌跡は、厳密な微調整手法を重視しています。Metaはこれらのプロセスを透明に明示し、共同のAI開発に対するコミュニティ主導の進展を促進することを目指しています。
Code LlamaはLlama 2の上に構築され、3つのモデルで利用できます:
- Code Llama、基礎となるコードモデル;
- Code Llama – PythonはPythonに特化しています;
- Code Llama – Instructは、自然言語の命令を理解するために微調整されています。
ベンチマークテストにより、Code Llamaはコードタスクで最先端のパブリックリリースされているLLM(GPT-4を除く)を上回りました。
Llama 2、Llama 2-Chat、およびCode LlamaはLLMの開発における重要なステップですが、GPT-4と比較してまだまだ進歩が必要です。Metaのオープンアクセスとこれらのモデルの改善に対する取り組みは、将来のLLMの透明性と迅速な進歩を約束しています。
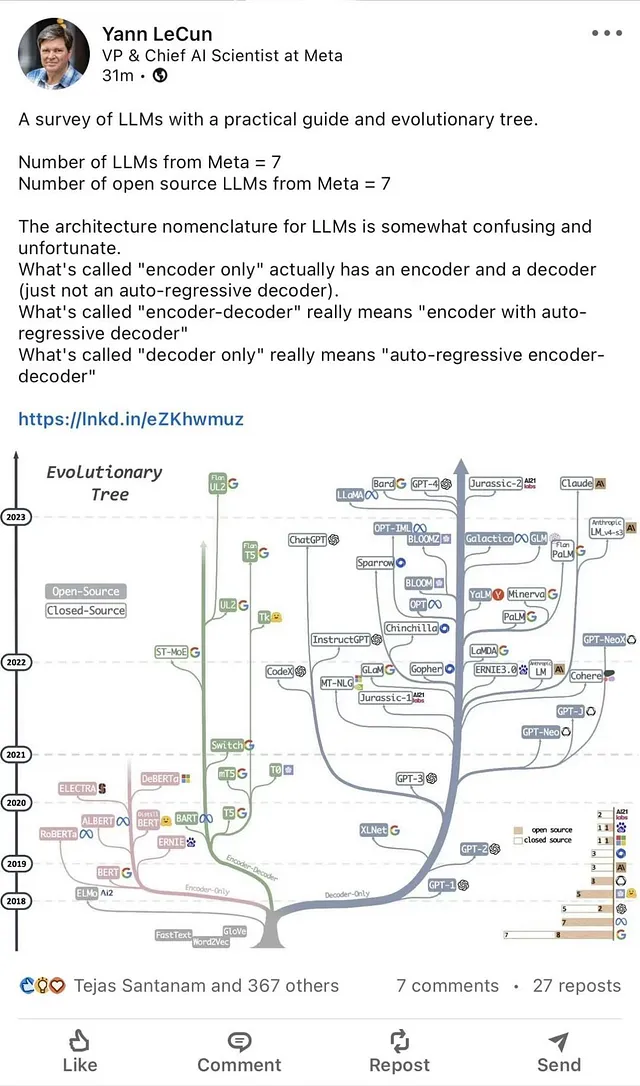
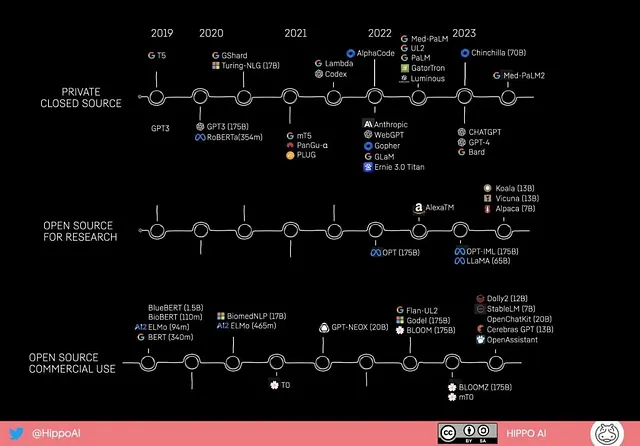
以下のLLMとLlamaバリアントを参照してください:
LLMからマルチモーダルへ
LLM(例:OpenAIのChatGPT(GPT-3.5))は、主に人間の言語の理解と生成に焦点を当てています。テキストの生成、翻訳、創造的な文章作成などのタスクにおいて重要な役割を果たしてきました。ただし、その範囲はテキストに限定されています。
GPT-4のようなマルチモーダルモデルが登場します。これらは、テキストだけでなく、画像や音声、おそらく他の種類のデータも理解し生成できる新しいタイプのAIモデルです。”マルチモーダル”という用語は、複数のモードやデータのタイプを同時に処理できる能力を指します。これは画期的なものです。例えば、ドレスの説明を読むだけでなく、視覚化したり、さらにはデザインすることができるAIを想像してみてください!
マルチモーダルモデルへの移行は、より包括的なAIシステムに向けた動きを示しています。これらのシステムは、さまざまな形式のデータ間のギャップを埋め、より豊かで統合されたソリューションを提供することで、より包括的な方法で私たちの世界を理解する可能性があります。
この新しい時代の開幕を迎えるにあたり、マルチモーダルモデルがもたらすさまざまな応用とイノベーションを想像することは興奮します。AIの未来はこれまで以上に統合され、多目的になるでしょう。
接続からベクトルデータベースへ
AIの風景は興味深い変遷を見ています。言語モデル(LLM)の接続から、LangChainやLlamaIndexのようなツールに代表されるベクトルデータベース(Vector DB)の台頭へと移り変わっています。しかし、この移行を推進しているのは何であり、それが重要なのはなぜでしょうか?
LlamaIndexなどのLLM接続は、主に膨大なテキストデータのリンクおよび理解に焦点を当てています。これらは意味的な関連を作り出し、より直感的な検索体験を可能にし、データのアクセシビリティを向上させることで重要な役割を果たしてきました。しかし、データの量と種類が増えるにつれて、より高度なストレージと検索メカニズムの必要性が明らかになってきます。
ここでベクトルデータベースが登場します。従来のデータベースがデータを行と列に格納するのに対して、ベクトルデータベースはデータを高次元空間に格納するため、より効率的かつ正確な類似検索が可能になります。WeaviateやMilvusなどのツールは、大規模なデータセットを処理するために設計されており、画像認識、推薦システムなどのタスクに理想的です。
ベクトルデータベースへの移行は、AIにおけるより効率的でスケーラブル、多目的なデータ処理のソリューションを求める広範なトレンドを表しています。この進化を進める中で、LLMとベクトルデータベースの組み合わせが、AI駆動の未来においてデータの格納、アクセス、理解の方法を再定義することは明白です。
エージェントからOSへ
AIの世界は革新的な技術で持ちきりであり、私たちが目撃している最も興味深い変化の一つは、LLMエージェントからLLMをオペレーティングシステム(OS)として使用することへの移行です。この進化とその影響について深堀りしてみましょう。
AutoGPT、AgentGPT、BabyAGI、HuggingGPTなどのLLMエージェントは、ユーザーの要求に基づいてタスクを自動化する上で画期的な役割を果たしてきました。これらのエージェントは、言語モデル(LLM)の力を活用してコマンドを理解し実行することで、コンテンツ生成からデータ分析までのさまざまなタスクで貴重な存在です。その適応性と知能は、多くのAIツールキットで重要な役割を果たしています。
しかし、AIのビジョンはそこで止まりません。LLMをOSとして使用するという概念が次の大きなトレンドとして浮上しています。言語モデルを中核としたオペレーティングシステムを想像してみてください。そのようなシステムは単なるタスクの実行だけでなく、文脈を理解し、ニーズを予測し、リアルタイムでソリューションを提供することができます。それはまるでLLMをデジタルエコシステムの脳に変えるようなものであり、デバイスやアプリケーションをこれまで以上に直感的でレスポンシブにします。
LLMをOSとして使用する方向への移行は、AIの認識と利用方法におけるパラダイムシフトを示しています。これは単なる自動化に留まらず、人間とテクノロジーの間にシームレスで知的なインターフェースを作り出すことです。この変革の瀬戸際に立つ私たちにとって、LLM駆動のOSが私たちのデジタルインタラクションを革命化する可能性は非常に大きいです。
微調整からプラグインへ
LLMの世界は、精巧な微調整プロセスからより動的なプラグインの領域への変化を遂げています。この進化について見てみましょう。
歴史的に、LLMの最適化には微調整が中心でした。LLMの微調整には、リアルタイムでデータをLLMに入力する方法と、LLM上で直接微調整する方法の2つの主要な方法があります。技術的な観点からは、次の3つの方法があります。
- 転移学習:事前に訓練されたモデルを新しいタスクに適応させること。
- 順次微調整:特定のタスクに向けてモデルを段階的に洗練すること。
- タスク固有の微調整:特定の機能に合わせてモデルを調整すること。
さらに、インコンテキスト学習、フューショット学習、ゼロショット学習などのLLMの技術は、モデルの適応性をさらに高め、最小限のデータでコンテンツを理解し生成することが可能になりました。
しかし、LLMの未来はプラグインに向かっています。GPT-4 Pluginsなどのツールの導入により、LLMの拡張に焦点が当てられています。LLMをサービスとして実行するのではなく、プラットフォームとして展開されることを想定しています。つまり、さまざまなツールとLLMを統合し、その能力を向上させ、AIアプリケーションによりモジュール化できるより拡張性のあるアプローチを提供します。
ファインチューニングからプラグインへの移行は、静的最適化から動的適応性への移行を表しており、LLM(Large Language Models)がAIのイノベーションの最前線にとどまることを保証しています。
要約すると
AIの領域は急速な変化を目撃しており、LLMは中心的な役割を果たしています。最初に、LLMからマルチモーダルモデルへの移行があり、テキストに加えて画像や音声も含むように拡大しています。同時に、LLMの接続は外部データをリンクするものから、効率的な高次元ストレージのためのベクトルデータベースへとシフトしました。
また、LLMエージェントがタスクを自動化するという進化があり、より直感的で文脈に敏感なデバイスやアプリケーションを目指して、LLMはオペレーティングシステムとしての役割を果たすようになりました。さらに、LLMの従来のファインチューニングプロセスは、動的プラグインによって置き換えられつつあり、様々なツールと統合されたプラットフォームとなっています。
このLLMの革命を牽引しているのは、OpenAIのGPT-4とMetaのLLaMA2です。彼らの先駆的な取り組みは、より統合され、反応性があり、人間の相互作用に適応したAIの未来の舞台を作り上げています。
さらに読む
- 実践におけるLLMの力を引き出す:ChatGPTとそれを超えるものに関する調査:https://arxiv.org/abs/2304.13712
- 人工汎用知能の火花:GPT-4の初期実験:https://arxiv.org/abs/2303.12712
- https://huggingface.co/nomic-ai/gpt4all-j
- https://generativeai.pub/gpt4all-j-the-knowledge-of-humankind-that-fits-on-a-usb-stick-415bdab11ab4
- 最先端のコーディングのためのCode Llamaの紹介:https://ai.meta.com/blog/code-llama-large-language-model-coding/
- Llama 2:オープンファンデーションとファインチューニングされたチャットモデル:https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





