GPT-3:言語モデルの少数ショット学習?
GPT-3:言語モデルの少数ショット学習?
過去数年間、AIとMLの産業は、NLPシステムの開発と応用の分野で際立った成長を見せてきました。研究者たちは、NLPの実践を高い柔軟性とタスク非依存の方法で下流タスクに移植することができました。
最初は、単層表現で単語ベクトルを使用し、タスク固有のアーキテクチャに渡される形式でした。次に、マルチ層表現と文脈状態を使用するRNNアーキテクチャが登場し、より良い表現を形成しました。そして最近では、タスク固有のアーキテクチャを不要にするために、転移言語モデルまたは事前学習された再帰モデルが登場しました。
転移言語モデルは、質問に答えること、文章の読解、文章の含意など、困難なタスクにおいて大きな進歩をもたらすという点で、NLPの産業において重要な転機となりました。
しかし、その利点にもかかわらず、転移言語モデルには重要な制約があります。特定のタスクにおいて望ましいパフォーマンスを達成するために、タスク固有の微調整やタスク固有のデータセットが必要とされます。さらに、転移言語モデルでは、特定のタスクに特化した数十万の例にデータセットを微調整する必要もあります。
タスク固有のデータセットやタスク固有の微調整の要件をなくすことは、NLPの産業にとって非常に望ましく、有益なことであることは言うまでもありません。
既存の事前学習済み転移言語モデルまたは再帰モデルの問題点
- 実用性と適用性の制約
まず最初に、言語モデルの実用性と適用性は、各タスクごとに大量のラベル付きデータを必要とするという要件に制約されます。言語モデルは、短編小説を生成したり、文法エラーを修正したり、概念に関する例を生成したりと、さまざまなタスクに応用されます。個々のタスクごとに大規模な教師付きデータセットを収集することは、特に再現性が必要な場合には困難な課題となることがあります。
- トレーニングデータの偶発的相関の悪用
トレーニングデータの制約とモデルの表現力の組み合わせにより、トレーニングデータの偶発的相関を悪用する潜在能力が大幅に増大する可能性があります。トレーニングデータの悪用の可能性は、転移言語モデルが事前学習中に大量の情報を吸収するように設計されているため、微調整と事前学習のパラダイムで問題が発生する可能性があります。
さらに、以前のモデルに関する研究によれば、大規模なモデルが必ずしも分布外でのパフォーマンス向上につながるわけではありません。また、このようなパラダイムの下で達成される一般化は、モデルがトレーニングデータの範囲外の状況でうまく機能せず、パフォーマンスが低下する可能性があるとも示されています。
- 人間の学習との比較
転移言語モデルと比較すると、人間は言語タスクの大部分を学習する際には大規模なトレーニングデータセットを必要としません。多くの場合、個人の自然言語による簡潔な指示や、言語タスクの小さなデモンストレーションがあれば、人間は一定レベルの競争力を持って言語タスクを理解し、実行することができます。
人間の適応能力は、異なるスキルセットの切り替えやそれらを組み合わせて方言の中でより優れたパフォーマンスを発揮することができるため、数多くの実用的な利点があります。これは現在のNLPシステムの能力を超えたものです。
メタ学習とGPT-3による問題の解決
上記の課題への可能な解決策は、メタ学習の利用です。メタ学習は、モデルがトレーニング中により多くのスキルとパターン認識能力を開発し、それらを推論中に迅速に適応または認識するために使用する、現代のMLの概念です。
メタ学習は、事前学習済み言語モデルのテキスト入力をタスクの指定として使用する「インコンテキスト学習」という技術を通じて、言語モデルアーキテクチャに実装されています。このプロセスでは、モデルは自然言語の指示に基づき、いくつかのデモンストレーションを使用して、タスクの残りの部分を予測することが期待されます。
メタ学習の唯一の主要な問題は、潜在的な可能性を示しているものの、自然言語アーキテクチャの微調整手法に比べてまだ劣っており、言語タスクを克服するための実用的な手法となるためにはさらなる改善が必要です。
メタ学習に加えて、人気を集めつつある別の手法は、トランスフォーマーランゲージモデルの容量を増やすことです。過去数年間、転移モデルの容量は大幅に増加しており、100億パラメータを持つRNSS18モデル、300億パラメータを持つDCLT18モデル、15億パラメータを持つRWC19モデル、80億パラメータを持つSSP19モデル、110億パラメータを持つRSR19モデル、170億パラメータを持つTUR20モデルなどがあります。
モデルの容量を増やすか、パラメータを増やすことは、テキスト合成の改善につながるという過去の経験から、ダウンストリームタスクと相関するログロスもスムーズな改善傾向に従うことが示されています。
そこで、1750億以上のパラメータを持つGPT-3モデルについて話しましょう。GPT-3モデルは、最も高い容量を持つ転移言語モデルとして2020年にOpenAIによってリリースされました。以下でGPT-3モデルについて詳しく説明します。
GPT-3モデルの紹介
GPT-3は、2020年にOpenAIによってリリースされた、1750億以上のパラメータを持つ自己回帰言語モデルです。GPT-3は、その前任者であるGPT-2モデルと同様に、テキストデータを生成するために畳み込みベースのアーキテクチャを使用したデコーダー専用のディープラーニングトランスフォーマーモデルとして分類されます。
GPT-3モデルは、自身のコンテキスト学習能力を測定し、2ダース以上のNLPデータセットと複数の新しいタスクで評価されます。各個別タスクでは、GPT-3モデルは以下の3つの条件の下で評価されます。
- フューショット学習またはインコンテキスト学習: フューショット学習では、GPT-3モデルはモデルのコンテキストウィンドウに適合するだけの分布を許容します。
- ワンショット学習: ワンショット学習では、モデルはただ1つのデモンストレーションのみを許容します。
- ゼロショット学習: ゼロショット学習では、デモンストレーションはなく、モデルに与えられるのは自然言語の命令だけです。

大まかに言えば、GPT-3モデルはゼロショット、ワンショットの設定で望ましいパフォーマンスを達成し、フューショットの設定では、ほとんどの場合、最先端の転移モデルを上回ります。さらに、GPT-3モデルは、インフラリーニングを必要とする自然言語タスクにおいても、ノベルワードの使用、単語のアンスクランブル、算術演算などのフライリーズニングをテストするために設計されたタスクで、ワンショット、ゼロショットの設定で優れたパフォーマンスを発揮します。一方で、フューショットの設定では、GPT-3モデルは、人間の評価者に通過させると人間の文章に似た合成ニュース記事を生成します。

GPT-3モデルのアプローチ
GPT-3モデルは、モデル、データ、トレーニングからなる従来のプレトレーニングアプローチを使用しており、これはRWC-19転移言語モデルのプレトレーニングプロセスに似ています。GPT-3モデルは、モデルサイズ、データセットサイズ、データセットの多様性、トレーニング期間の長さを拡大しています。
また、GPT-3モデルは、RWC-19モデルのアプローチに似たインコンテキスト学習アプローチも使用していますが、データセットのコンテキスト内でのパターン学習の異なる設定を系統的に探索することで、アプローチを微調整しています。
それでは、これらの設定を探索し、GPT-3モデルが異なる設定でどのようなパフォーマンスを発揮するかを評価してみましょう。
ファインチューニング
モデルのファインチューニングは、転移言語モデルにおける従来のアプローチであり、このアプローチでは、事前にトレーニングされたモデルの重みを、特定のタスクに特化した教師ありデータセットでトレーニングすることによって更新します。このプロセスでは数十万のラベル付きの例が使用されます。
ファインチューニングアプローチは、多数のベンチマークで強力なパフォーマンスを返すため、有益です。一方、ファインチューニングアプローチの主な制限は、個々のタスクごとに新しいかつ大規模なデータセットが必要であり、トレーニングデータセットの偽の特徴を利用する可能性があるため、人間のパフォーマンスとの公平な比較や、分布外の一般化に対して貧弱な結果になる可能性があります。
GPT-3モデルの現在のスコープでは、タスクに依存しないパフォーマンスがあるため、ファインチューニングのアプローチは実装されていませんが、将来的にはGPT-3モデルにファインチューニングを適用することができます。
フューショット
フューショットとは、GPT-3モデルが幾つかのタスクのデモを受け取り、モデルの重みは更新されない設定を指す用語です。フューショットの設定では、データセットには通常、コンテキストとその完了の例(例えば、フランス語の文とその英訳)が含まれています。フューショットの設定では、モデルにK個のコンテキストと完了の例を与え、最後にモデルに1つの最終的なコンテキストを与え、モデルが完了を提供することを期待します。
フューショット設定を使用する主な利点は、タスク固有のデータの必要性を大幅に減らし、また、狭い分布を広くファインチューニングする大規模なデータセットから学習する可能性を減らすことです。一方、フューショット学習を使用する主な欠点は、フューショット設定で提供される結果が他の最先端モデルと比較して十分でなく、著しく劣るということです。
ワンショット
ワンショット設定では、モデルには単一のデモのみが提供され、それ以外はフューショット設定と同様です。ワンショット設定が転移言語モデルで関連する理由は、すべての設定の中で、ワンショットが人間にタスクが伝えられる方法に最も似ているからです。ほとんどのタスクでは、タスクのコンテキストを理解するのが難しい場合があるため、タスクのデモンストレーションを一つ与えることが一般的です。
ゼロショット
ゼロショット設定では、デモンストレーションはなく、モデルにタスクを記述する自然言語の命令が与えられます。ゼロショットの方法は最大の利便性を提供し、頑健性もあり、不適切な相関を回避しますが、3つの設定の中でも最も難しいです。なぜなら、いくつかの場合、私たち人間でもデモンストレーションを見ずにタスクのコンテキストを理解することが困難な場合があるからです。
ただし、一部のタスクにおいては、ゼロショット設定が人間が自然言語のタスクを実行する方法に最も近いものです。

上記の図は、英語の文をフランス語に翻訳する自然言語タスクを実行する際のフューショット、ワンショット、ゼロショットの設定を比較しています。
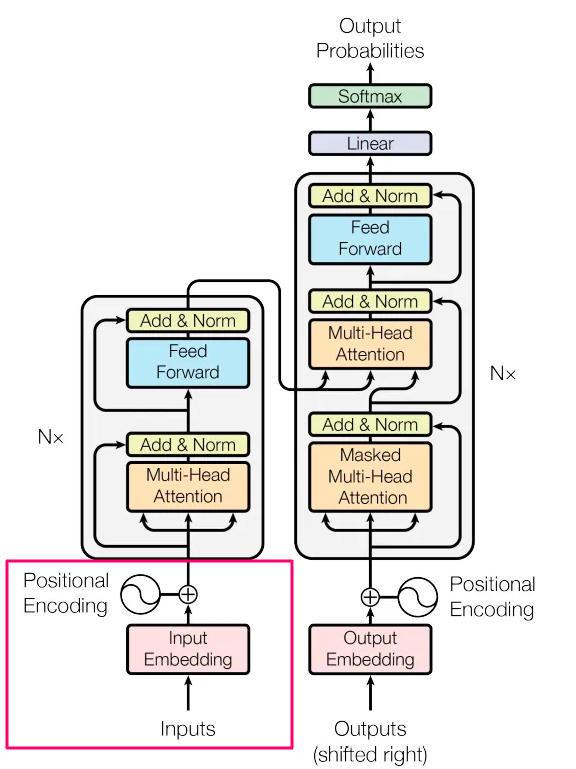
GPT-3:モデルアーキテクチャ
GPT-3モデルは、GPT-2モデルと同じアーキテクチャを使用しており、GPTモデルで使用された事前正規化、変更された初期化、および可逆トークン化の技術を含んでいますが、ローカルバンド付き疎な注意パターンとトランスフォーマーレイヤーでの交互の密なレイヤーに関しては、スパーストランスフォーマーと似た方法を使用しています。
モデルのパフォーマンスがモデルのサイズにどのように依存するかを調査するために、開発者は125百万から1750億パラメータまで3桁の異なる8つのモデルサイズをトレーニングしています。LLMモデルに関連する以前の研究は、十分なトレーニングデータでの検証損失のスケーリングは、サイズの関数として近似的に滑らかなべきであることを示しています。さまざまなサイズのモデルをトレーニングすることにより、開発者はダウンストリームの言語タスクおよび検証損失の両方について仮説をテストすることができます。

上記の図は、GPT-3の開発に使用された8つの異なるモデルのサイズとアーキテクチャを比較しています。ここで、n(params)はトレーニング可能なパターンの総数を定義し、n(layers)はモデルの総レイヤー数を定義し、d(model)はボトルネックの各レイヤーのユニット数を定義し、d(head)は各アテンションヘッドの次元を定義します。各モデルのコンテキストウィンドウは、2048トークンです。
さらに、ノード間のデータ転送を最小化するために、モデルは次元の深さと幅にわたってGPU上でパーティション化されます。各モデルのアーキテクチャパラメータは、計算効率とモデルのレイアウトにおける精度を最大化するために選択されています。
トレーニングデータセット
通常、大規模な言語モデルは、最近の開発により大幅に拡張されたデータセットを使用し、それらはCommon Crawlデータセットに集約され、1兆を超える異なる単語で構成されています。データセットのサイズは、同じシーケンスに複数回更新することなく、GPT-3モデルのトレーニングに十分な大きさです。ただし、研究とパフォーマンス分析によると、Common Crawlデータセットの軽くフィルタリングされたバージョンやフィルタリングされていないバージョンは、より慎重に作成されたデータセットと比較して、品質が低いということが示されています。
データセットの平均品質の問題に対処するために、開発者はデータセットの品質を向上させるために3つの手順を踏みました。
- 開発者は、高品質の参照コーパスと同様の範囲に基づいて、Common Crawlデータセットのバージョンをダウンロードしてフィルタリングしました。
- 開発者は、データセット全体でドキュメントレベルでぼかしの複製を行い、ホールドアウトバリデーションセットの整合性を維持し、過学習の効果的な測定と冗長性の防止を図りました。
- 開発者は、高品質の参照コーパスをトレーニングデータに追加し、Common Crawlデータセットを補完し、データセットの多様性をさらに増やしました。
以下の図は、GPT-3モデルのトレーニングに使用されるデータセットの最終的な比率または混合を示しています。Common Crawlデータは、フィルタリング前に45 TBのプレーンテキストで構成されており、フィルタリング後に570 GBのデータに削減されました。これはおよそ4000億のバイトペアエンコードトークンに相当します。トレーニング中には、トレーニング内のより高品質と見なされるデータセットが、サイズに比例してサンプリングされるのではなく、より頻繁にサンプリングされることに注意する価値があります。その結果、Books2とCommon Crawlなどのデータセットは、トレーニング中に1回未満の頻度でサンプリングされ、他のデータセットは複数回サンプリングされます。これにより、モデルはわずかな過学習を受け入れることで、より高品質のトレーニングデータでトレーニングすることができます。

大量のインターネットデータで事前学習され、大量のコンテンツを記憶し学習する能力を持つ大規模な言語モデルの一つの重要な懸念事項は、事前トレーニングプロセスで開発またはテストセットが目にされることによる下流タスクの潜在的な汚染です。このような潜在的な汚染を減らすため、開発者はGPT-3のベンチマークのテストセットと開発セットとの重なりを調べ、これらの重なりを除去しようとしました。

上記の画像は、GPT-3モデルのトレーニング中に使用された合計の計算量を示しています。このモデルは、典型的なトークンよりも少ないトークンではるかに大きなモデルをトレーニングするために、ニューラル言語モデルのスケーリング法を使用しています。その結果、GPT-3モデルよりも10倍小さいRoBERTa-Largeモデルでも、事前トレーニングプロセス中におよそ50ペタフロップ/日の計算が行われました。
評価
フューショット学習において、モデルは評価データセット内の各例を、そのタスクのトレーニングデータセットからランダムにK個の例を引いて条件付けし、タスクに応じて1または2つの改行で区切ります。StoryclozeとLAMBADAでは、モデルは開発セットから条件付けの例を引き、テストセットで評価します。Winogradでは、データセットが一つしか存在せず、そのデータセットから直接条件付けのサンプルを引きます。
Kは、モデルのコンテキストウィンドウの最大許容量であるnext = 2048までの任意の値を取ることができます。通常、10から100の例が収まります。Kの値が大きいほど、結果はより良くなりますが、常にではありません。そのため、モデルにテストセットと別個の開発セットがある場合は、モデルは開発セットでいくつかのKの値で実験し、結果に基づいて最良の値をテストセット上で実行します。
さらに、複数のオプションから正しい補完を選択する必要があるタスクでは、開発者は修正プラスコンテキスト補完のK個の例を提供し、それに続いてコンテキストのみの例を提供します。そして、各補完の言語モデルの尤度に基づいてタスクを比較します。バイナリ分類を必要とするタスクでは、モデルはオプションを意味的により多く、より意味のある名前で与え、タスクを多肢選択式として扱い、時にはRSRモデルやアーキテクチャが行うようなタスクフレームを行います。
自由形式の完了を必要とするタスクにおいて、モデルはRSRフレームワークで使用されるのと同じパラメータを用いてビームサーチを使用します。ビームサイズは4で、ペナルティは0.6です。モデルはデータセットの基準に応じて、F1類似度スコア、完全一致、またはBLEUを使用して評価されます。
結果

上記の図は、前のセクションで説明したGPT-3モデルアーキテクチャで使用される8つのモデルのトレーニングカーブを表示しています。KMH言語モデルの結果と同様に、トレーニングコンピュートを効果的に使用すると、GPT-3モデルのパフォーマンスは適切な法則に従います。トレンドを2つの桁で拡張すると、法則からわずかな違いが生じます。トレーニングコーパスの虚偽の詳細をモデリングしてクロスエントロピー損失が改善される可能性があるという考えが人々に浮かぶかもしれませんが、クロスエントロピー損失の改善は、さまざまなNLPタスク全体のパフォーマンスの一貫した向上につながります。
広範なトレーニングデータ上で8つの異なるモデルを評価する前に、データセットは類似したタスクを表す8つの異なるカテゴリにグループ分けされます。
- 伝統的な言語モデリングタスクや言語モデリングに似たタスク、または文/段落の完了タスクの評価。
- 「閉じた本」の質問応答タスクの評価。
- 言語間の翻訳能力の評価(特にワンショットとフューショット)。
- Winograd Schemaのようなタスクのパフォーマンスの評価。
- 常識的な推論や質問応答を含むデータセットの評価。
- 読解タスクの評価。
- SuperGLUEベンチマークスイートの評価。
- NLIの探索。
言語モデリング、完了、およびクローズタスク
このセクションでは、GPT-3モデルのパフォーマンスを、従来の言語モデリングタスクおよび単語の予測、段落または文の完了、テキストの一部の完了を必要とするタスクで評価します。詳細については、以下で説明します。
言語モデリング
GPT-3モデルは、PTB(Penn Tree Bank)データセット上でゼロショットの困惑度を計算します。モデルはWikipedia関連のタスクを省略します。なぜなら、それは既にモデルのトレーニングデータに含まれているためです。また、10億語ベンチマークも省略されます。なぜなら、トレーニングデータ内のデータセットの摩擦を引き起こすからです。しかし、PTBデータセットはこれらの問題に対処します。なぜなら、それがモダンなインターネットよりも前の時代のデータであるためです。GPT-3モデルアーキテクチャの最大モデルは、PTBデータセットで15ポイントという注目すべき差で新たなSOTAを達成し、困惑度は20.50となります。
LAMBADA
LAMBADAデータセットは、パラグラフやテキスト内の長距離の依存関係のモデリングをテストするために使用されます。つまり、文脈を読んだ後に文の最後の単語を予測するようにモデルに要求されます。さらに、言語モデルの連続スケーリングはベンチマークで収益が減少していることを意味します。

GPT-3モデルはLAMBADAで76%の正確性を達成し、以前のベストモデルよりも8%以上の改善があります。さらに、LAMBADAモデルは、クラシックな問題をデータセットで取り組む方法で少数のショット学習の柔軟性を示しています。LAMBADAでの文の完了は通常、文の最後の単語ですが、言語モデルはそれを知ることができないため、正しい終了だけでなく、段落内の他の継続にも確率を割り当てます。
さらに、GPT-3モデルに供給される例がある方法で修正されると、モデルは86%以上の正確性を返し、以前のモデルよりも18%以上の増加があります。さらに、結果は、少数のショット設定でのモデルのパフォーマンスがモデルサイズの増加に比例して増加することを示しています。この戦略は、GPT-3アーキテクチャ内の最小モデルを20%削減しますが、1750億パラメータを持つ主要なGPT-3モデルの正確性を10%向上させます。
クローズドブック質問応答
クローズドブック質問応答は、GPT-3モデルが広範な事実知識に基づいて質問に答える能力を測定する試みです。このような質問は通常、モデルが関連するテキストを見つけるための情報検索システムを使用して達成されます。モデルは取得したテキストと質問に対して応答を生成するために学習することができます。

上記の画像は、GPT-3モデルの結果を異なるモデルとデータセットで比較したものです。TriviaQAデータセットでは、ゼロショットの設定では正答率64.3%を達成し、ワンショットとフューショットの設定ではそれぞれ正答率68%と71.2%を達成します。
明らかに、ゼロショットの設定ではGPT-3モデルが微調整されたT5-11Bモデルを14%以上上回ることがわかります。

上記の図は、GPT-3モデルのパフォーマンスがモデルサイズの増加とともにスムーズに成長していることを示しています。このパフォーマンスから、言語モデルは容量が増えるにつれてデータセットから学習を続けていることが示唆されます。
最終的な考察
GPT-3は、言語モデルができることの限界を押し広げるのに役立ったLLM業界の革命的なフェーズであったと言えるでしょう。GPT-3が克服した開発と障害が、現在までに存在する最も高度で正確な大規模言語モデルであるGPT-4の道を開いたのです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「言葉から世界へ:AIマルチモーダルによる微細なビデオ説明を用いたビデオナレーションの探求」
- 「リリに会ってください:マッキンゼーの内部生成AIツール、洞察力を解き放ち、コンサルティングの効率を向上させる」
- 「シームレスM4Tに出会ってください:Meta AIの新しいスピーチ翻訳の基盤モデル」
- 「LoRAとQLoRAを用いた大規模言語モデルのパラメータ効率的なファインチューニング」
- AutoGPTQをご紹介します:GPTQアルゴリズムに基づく使いやすいLLMs量子化パッケージで、ユーザーフレンドリーなAPIを提供します
- あなたのリスニングプレイリストに追加するためのトップ8のAIポッドキャスト
- 「LoRAアダプターにダイブ」